













Scikit Learn
 Scikit-learnはPython向けの機械学習ライブラリです。SVM、勾配ブースティング、k-means、ランダムフォレスト、DBSCANなどの回帰、分類、クラスタリングアルゴリズムを含んでいます。PythonのNumpyとSciPyとの連携が設計されています。scikit-learnプロジェクトは、David CournapeauによるGoogle Summer of Code(またはGSoC)プロジェクトとしてscikits.learnとしてスタートしました。その名前は、「Scikit」というSciPyの別のサードパーティー拡張機能から取られています。
Scikit-learnはPython向けの機械学習ライブラリです。SVM、勾配ブースティング、k-means、ランダムフォレスト、DBSCANなどの回帰、分類、クラスタリングアルゴリズムを含んでいます。PythonのNumpyとSciPyとの連携が設計されています。scikit-learnプロジェクトは、David CournapeauによるGoogle Summer of Code(またはGSoC)プロジェクトとしてscikits.learnとしてスタートしました。その名前は、「Scikit」というSciPyの別のサードパーティー拡張機能から取られています。
Python Scikit-learn
ScikitはPythonで書かれており(そのほとんど)、一部のコアアルゴリズムはさらなるパフォーマンス向上のためにCythonで書かれています。Scikit-learnはモデルの構築に使用されますが、データの読み取り、操作、要約には他に適したフレームワークがあるため、それらの目的で使用することは推奨されません。BSDライセンスの下でオープンソースでリリースされています。
Scikit Learnのインストール
Scikitは、お使いのデバイスにNumPY(1.8.2以降)とSciPY(0.13.3以降)パッケージがインストールされた、Python 2.7以上の実行環境があることを前提としています。これらのパッケージがインストールされている場合は、インストールを進めることができます。 pipインストールの場合、ターミナルで次のコマンドを実行します:
pip install scikit-learn
もしcondaを好まれる場合は、パッケージのインストールにcondaを使用することもできます。次のコマンドを実行してください:
conda install scikit-learn
Scikit-Learnの使用
インストールが完了したら、Pythonコードでscikit-learnを簡単に使用できます。以下のようにインポートします:
import sklearn
Scikit Learnのデータセットの読み込み
データセットを読み込んでみましょう。簡単なIrisという名前のデータセットを読み込んでみましょう。これは花のデータセットで、花のさまざまな測定に関する150の観測値が含まれています。scikit-learnを使用してデータセットを読み込む方法を見てみましょう。
\# scikit learnをインポートします
from sklearn import datasets
\# データをロードします
iris= datasets.load_iris()
\# データの形状を印刷して、データがロードされていることを確認します
print(iris.data.shape)
便宜のためにデータの形状を印刷していますが、必要に応じてデータ全体を印刷することもできます。コードを実行すると、次のような出力が得られます: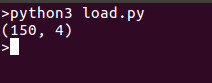
Scikit Learn SVM – 学習と予測
これでデータをロードしたので、それから学習して新しいデータに対して予測してみましょう。そのためには、推定器を作成してからそのfitメソッドを呼び出す必要があります。
from sklearn import svm
from sklearn import datasets
\# データセットをロードします
iris = datasets.load_iris()
clf = svm.LinearSVC()
\# データから学習します
clf.fit(iris.data, iris.target)
\# 見えないデータのために予測します
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
\# モデルのパラメータは、アンダースコアで終わる属性を使用して変更できます
print(clf.coef_ )
このスクリプトを実行すると、次のような結果が得られます: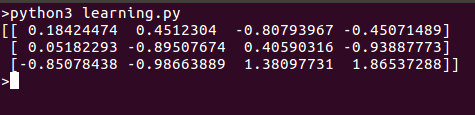
Scikit Learn線形回帰
scikit-learnを使用してさまざまなモデルを作成することはかなり簡単です。線形回帰のシンプルな例から始めましょう。
#import the model
from sklearn import linear_model
reg = linear_model.LinearRegression()
# データを適合させるために使用します
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# 適合したデータを見てみましょう
print(reg.coef_)
モデルを実行すると、同じ直線上にプロットできる点が返されるはずです: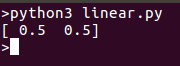
k-Nearest neighbour classifier
簡単な分類アルゴリズムを試してみましょう。この分類器は、トレーニングサンプルを表すためにボールツリーに基づいたアルゴリズムを使用します。
from sklearn import datasets
# データセットを読み込む
iris = datasets.load_iris()
# 最近傍分類器を作成して適合させる
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# 予測して結果を表示
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
分類器を実行して結果を確認しましょう。分類器は0を返すはずです。例を試してみましょう:
K-means clustering
これは最も単純なクラスタリングアルゴリズムです。集合は ‘k’ クラスタに分割され、各観測値がクラスタに割り当てられます。クラスタが収束するまでこれが反復的に行われます。次のプログラムでそのようなクラスタリングモデルを作成します:
from sklearn import cluster, datasets
# データを読み込む
iris = datasets.load_iris()
# k=3 のクラスタを作成
k=3
k_means = cluster.KMeans(k)
# データを適合させる
k_means.fit(iris.data)
# 結果を表示
print( k_means.labels_[::10])
print( iris.target[::10])
プログラムを実行すると、リスト内に別々のクラスタが表示されます。上記のコードスニペットの出力は次のとおりです: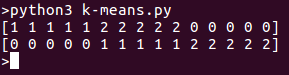
結論
{
“error”: “Upstream error…”
}
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial