













Configurazione di Amazon Polly
Ora, mettiamoci all’opera e configuriamo Amazon Polly! Questa sezione fornisce una panoramica su come farlo.
Passaggio 1: Creare un account AWS
Per utilizzare Amazon Polly, è innanzitutto necessario disporre di un account AWS. Se non ne hai già uno, vai alla pagina di registrazione AWS e segui i passaggi per crearne uno. Assicurati di fornire informazioni di fatturazione valide, poiché i servizi AWS, inclusi Polly, vengono fatturati in base all’utilizzo.
Configurazione IAM per le autorizzazioni
Consiglio di configurare un utente IAM (Identity and Access Management) con le autorizzazioni necessarie per gestire le risorse di Amazon Polly. Assegna la policy AmazonPollyFullAccess per garantire che l’utente possa accedere a tutte le funzionalità di Polly.
Passaggio 2: Navigare su Amazon Polly
Dopo esserti autenticato nella Console di Gestione AWS, cerca Polly nella barra di ricerca in alto.
Il menu di ricerca nella console AWS.
Clicca sul servizio Amazon Polly per accedere all’interfaccia di Polly.
Utilizzo di Amazon Polly per la conversione testo-voce
Normalmente, gli sviluppatori utilizzano l’API di Amazon Polly per integrare direttamente la funzionalità di text-to-speech nelle loro applicazioni. Tuttavia, è anche possibile utilizzare l’interfaccia di AWS Polly per provare rapidamente voci e impostazioni diverse senza scrivere codice. Per farlo, fare clic sul Prova Polly pulsante nell’interfaccia di Polly. Questo pulsante ti consente di sperimentare con vari input di testo, tipi di voce e formati di output dalla Console AWS, facilitando l’esplorazione delle capacità di Polly prima di implementarle in modo programmato.
Conversione di base da testo a voce
Per effettuare una conversione di base da testo a voce, inserisci una frase come “Ciao, benvenuto in Amazon Polly!” nella casella di input. Puoi anche scegliere il tipo di motore (ad esempio, generativo, a lungo termine, neurale o standard), la lingua e la voce. Clicca su Ascolta per ascoltare immediatamente l’output o clicca su Scarica per scaricarlo come file .mp3.
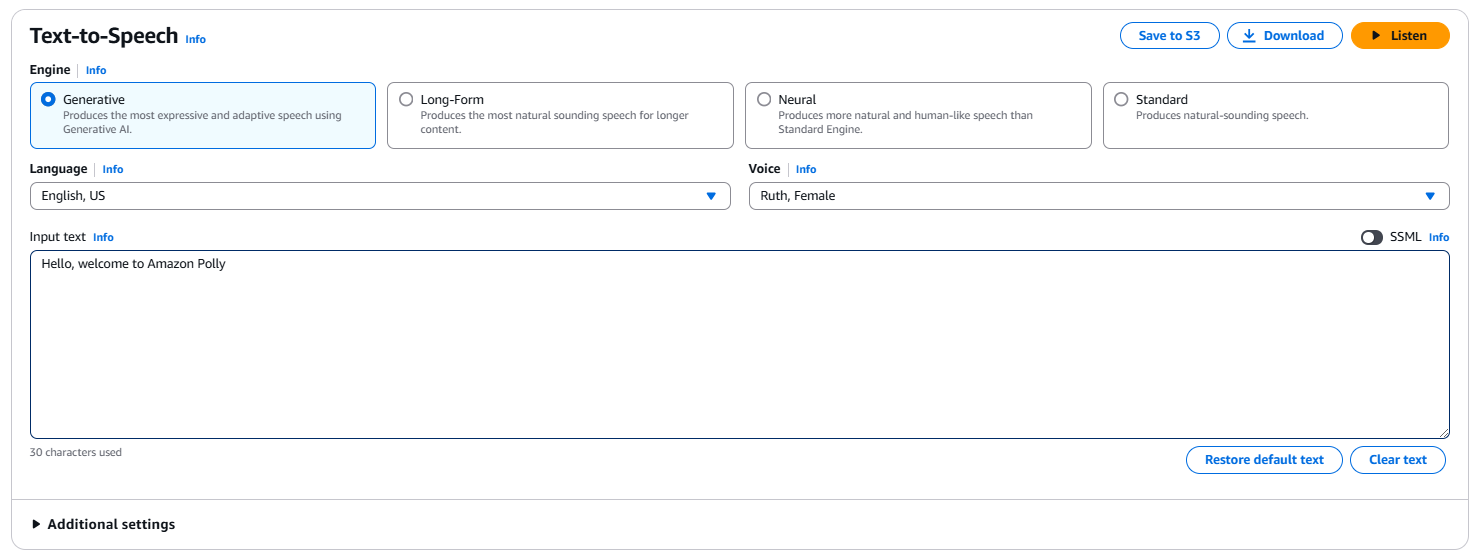
L’interfaccia di Amazon Polly nella console AWS.
Configurazione dell’SDK AWS per la sintesi vocale.
È necessario configurare l’SDK di AWS per integrare Amazon Polly nelle tue applicazioni in modo programmato. Questo ti consente di interagire direttamente con Amazon Polly dal tuo codice, abilitando funzionalità di text-to-speech più dinamiche e personalizzabili.
In questo tutorial, utilizzeremo il SDK Python (boto3). Installa boto3 tramite pip:
pip install boto3
Successivamente, configura le tue credenziali AWS utilizzando l’AWS CLI:
aws configure
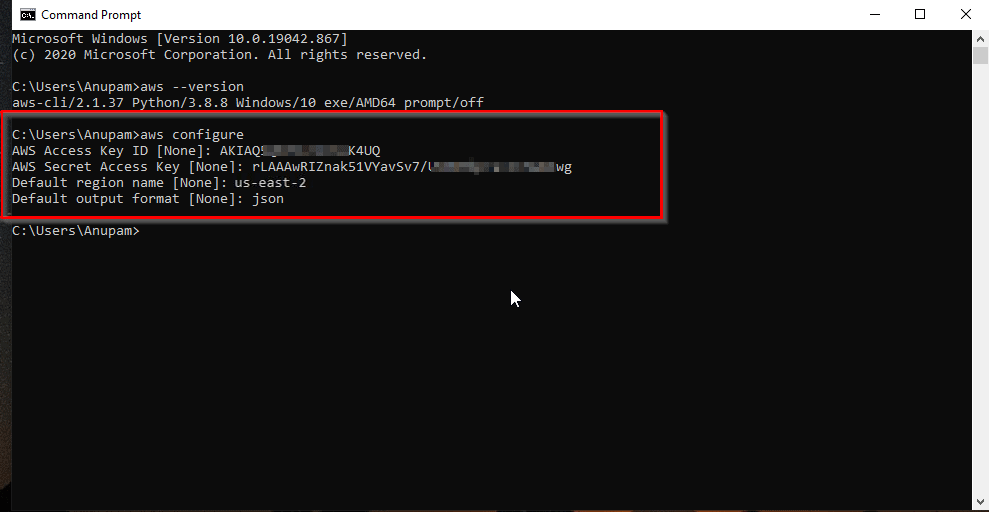
Il comando aws configure sulla CLI.
Generazione del parlato tramite SDK
Ecco uno script Python semplice per convertire testo in parlato usando Amazon Polly:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Questo script genera parlato da testo e lo salva come file mp3.
Funzionalità avanzate di Amazon Polly
Pur essendo ampiamente conosciuto per la sua funzionalità di base di testo in parlato, Amazon Polly offre anche una serie di funzionalità avanzate che consentono agli sviluppatori di creare esperienze vocali più sofisticate e interattive.
Utilizzando SSML (Speech Synthesis Markup Language)
SSML (Speech Synthesis Markup Language) consente agli sviluppatori di controllare vari aspetti della voce, come tono, velocità, volume e enfasi, rendendo l’output audio più espressivo e naturale.
Utilizzando i tag SSML, è possibile aggiungere pause, regolare stili di lettura e persino comporre acronimi lettera per lettera. Questa flessibilità è particolarmente utile per scenari come la narrazione, le piattaforme di e-learning e le applicazioni di assistenza clienti, dove il tono e lo stile di consegna influiscono significativamente sull’interazione dell’utente.
Ad esempio, è possibile enfatizzare determinate parole per trasmettere l’importanza o modificare la velocità di lettura per i contenuti istruzionali al fine di garantire chiarezza.
Ecco come utilizzare SSML con il SDK Polly:
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # Salva il file audio with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
Questo esempio enfatizza la parola “Importante” per farla risaltare nel messaggio parlato, potenziando l’impatto emotivo sull’ascoltatore. SSML supporta anche funzionalità avanzate come la pronuncia dei fonemi, il sussurro e l’aggiunta di effetti sonori, offrendo ai programmatori pieno controllo sull’esperienza vocale.
Segni di interpunzione per la sincronizzazione labiale
I segni di interpunzione forniscono metadati allineati temporalmente, consentendo ai programmatori di sincronizzare il parlato con le animazioni, l’evidenziazione del testo o i movimenti labiali dei personaggi.
Questa funzionalità è particolarmente preziosa per le applicazioni interattive come personaggi virtuali, giochi educativi o l’evidenziazione del testo in stile karaoke.
Richiedendo i segni di interpunzione insieme alla sintesi del parlato, si ottengono informazioni dettagliate sui tempi per ciascuna parola o frase, consentendo di creare esperienze multimediali dinamiche e sincronizzate.
Ad esempio, è possibile animare i movimenti della bocca di un personaggio in sincronia con le parole pronunciate o evidenziare il testo in tempo reale mentre viene narrato. Ecco come richiedere i segni di interpunzione:
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # Salva i segni di interpunzione in un file JSON with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
Output JSON:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
Nell’esempio sopra vengono richiesti i segni di interpunzione per ogni parola, restituendo un oggetto JSON con timestamp e dati di testo. Gli sviluppatori possono quindi utilizzare queste informazioni per sincronizzare le animazioni frame per frame, rendendo l’esperienza audio-visiva più coinvolgente e realistica.
Streaming in tempo reale con Amazon Polly
Per applicazioni in tempo reale come assistenti vocali, commenti live o chatbot interattivi, Amazon Polly supporta lo streaming utilizzando il protocollo WebSocket o lettori multimediali che supportano HLS (HTTP Live Streaming).
Questo consente alle applicazioni di iniziare a riprodurre audio mentre viene sintetizzato, riducendo la latenza e creando un’esperienza utente più reattiva. Lo streaming in tempo reale è ideale per scenari in cui l’immediatezza è fondamentale, come il supporto clienti in tempo reale o l’IA conversazionale.
Gli sviluppatori possono sfruttare questa funzionalità per creare dispositivi attivati vocalmente, lettori di notizie o applicazioni di narrazione interattiva che rispondono agli input dell’utente al volo.
Gestione delle risorse di Amazon Polly
Una gestione efficace delle risorse di Amazon Polly è cruciale per ottimizzare le prestazioni, i costi e la scalabilità. Memorizzando strategicamente i file audio e monitorando l’utilizzo, è possibile garantire un utilizzo efficiente delle risorse mantenendo un’esperienza utente di alta qualità.
Amazon Polly si integra facilmente con altri servizi AWS, come Amazon S3 per lo storage e il Pannello di controllo della fatturazione AWS per il monitoraggio dei costi, rendendo la gestione delle risorse più semplice.
Creazione e gestione dei file audio
Amazon Polly ti consente di archiviare il parlato sintetizzato in Amazon S3 per uno storage scalabile e un facile recupero. Questo approccio è particolarmente utile per le applicazioni con requisiti audio ricorrenti, come piattaforme di e-learning, audiolibri o bot di supporto clienti, dove puoi riutilizzare i file audio anziché sintetizzare il parlato ogni volta.
Archiviando gli output audio frequentemente utilizzati in S3, puoi ridurre i costi e migliorare le prestazioni servendo i file audio memorizzati nella cache direttamente dal cloud.
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
Monitoraggio dell’utilizzo e dei costi
Sfrutta il cruscotto di AWS Billing e Cost Management per monitorare in modo efficiente l’utilizzo e i costi. Questo cruscotto fornisce dettagliati scomposizioni dei costi, report sull’utilizzo e la possibilità di impostare budget e allarmi per evitare addebiti inaspettati.
Monitorare i costi è particolarmente importante quando si utilizzano voci neurali, che sono più costose delle voci standard. È inoltre possibile tracciare metriche sull’utilizzo come il numero di caratteri sintetizzati e la frequenza delle chiamate API, che possono aiutare a ottimizzare l’utilizzo delle risorse.
Esempio di un cruscotto dei costi di AWS.
Best Practices per l’utilizzo di Amazon Polly
Quando si utilizza Amazon Polly, l’adozione delle best practices garantisce prestazioni ottimali, efficienza dei costi e esperienza utente. Ecco alcune linee guida chiave:
Scegliere la voce giusta
Scegliere la voce giusta dipende dall’obiettivo dell’applicazione e dal pubblico di riferimento. Amazon Polly offre una varietà di voci, inclusi voci standard e voci neurali, ognuna con toni e caratteristiche uniche.
- Le voci neurali forniscono un suono più naturale ed espressivo ma sono più costose. Pertanto, sono ideali per applicazioni che richiedono un alto coinvolgimento emotivo, come audiolibri o storytelling.
- Le voci standard offrono una soluzione economica per applicazioni basate sull’utilità come i chatbot di supporto clienti. Testare diverse voci con il feedback degli utenti aiuta a selezionare la voce più adatta alle esigenze dell’applicazione.
Optimizzazione dell’output vocale
Sfrutta SSML (Speech Synthesis Markup Language) per migliorare la qualità della voce regolando i parametri di tono, velocità e volume. Puoi creare un’esperienza audio più dinamica e coinvolgente affinando queste impostazioni.
Ad esempio, rallentare la velocità di lettura migliora la chiarezza dei contenuti didattici, mentre enfatizzare le frasi chiave migliora la narrazione. Sperimentare con diversi tag SSML ti aiuta a ottenere una voce più naturale.
Riduzione dei costi
Strategie come gestire la frequenza di generazione della voce e archiviare file audio frequentemente utilizzati in S3 per il riutilizzo dovrebbero essere considerate per ottimizzare i costi nell’utilizzo di Amazon Polly. Questo approccio riduce le chiamate API ripetitive e abbassa i costi di sintesi.
Inoltre, utilizzare strategicamente una combinazione di voci standard e neurali può bilanciare costo e qualità.
Ad esempio, utilizzare voci neurali solo per punti critici come i messaggi di benvenuto, mentre voci standard gestiscono i contenuti informativi. Impostare limiti di utilizzo e avvisi di costo nel Pannello di controllo della fatturazione AWS aiuta a mantenere il controllo del budget e evitare spese inaspettate.
Conclusione
Amazon Polly è un potente servizio di text-to-speech che sfrutta avanzate tecnologie di deep learning per convertire il testo in un discorso realistico, migliorando le esperienze utente e l’accessibilità.
In questo tutorial, abbiamo esplorato le funzionalità fondamentali di Amazon Polly, dall’impostazione dell’SDK AWS alla generazione del discorso in modo programmato. Abbiamo anche esaminato le capacità avanzate, come l’utilizzo di SSML per un’uscita vocale personalizzata, il sfruttamento dei segni del discorso per la sincronizzazione labiale e le animazioni e l’implementazione dello streaming in tempo reale per applicazioni vocali dinamiche.
Integrare Amazon Polly nelle tue applicazioni ti consente di creare esperienze vocali altamente interattive e personalizzate che si rivolgono a un pubblico globale. Che tu stia costruendo assistenti virtuali, audiolibri, piattaforme educative o strumenti di accessibilità, Amazon Polly fornisce la flessibilità, la scalabilità e le funzionalità avanzate necessarie per dare vita alle tue idee.
Se sei nuovo di AWS e desideri potenziare le tue competenze cloud, considera di esplorare questi corsi correlati:
- Concetti AWS – Apprendi i concetti fondamentali dietro il cloud computing di AWS.
- Tecnologia e Servizi Cloud AWS – Mettiti alla prova con i principali servizi AWS e le loro applicazioni pratiche.
- Sicurezza e Gestione dei Costi AWS – Comprendi le best practice per proteggere le risorse AWS e ottimizzare i costi.
- Percorso di Certificazione AWS Cloud Practitioner – Preparati per l’esame AWS Cloud Practitioner CLF-C02 con un percorso di apprendimento strutturato.