













Avere usato Amazon Aurora per un po’ di tempo presso varie aziende, ho visto di persona quanto eccelle come motore di database relazionale completamente gestito, offrendo elevate prestazioni, scalabilità e affidabilità.
Come soluzione nativa per il cloud che supporta MySQL e PostgreSQL, Aurora è una scelta eccellente per le aziende che richiedono alta disponibilità e scalabilità automatica. Poiché AWS gestisce automaticamente i backup, il failover e la replica, utilizzare Aurora consente di aumentare l’efficienza del database riducendo i costi di manutenzione.
In questo tutorial, ti guiderò attraverso la configurazione di un’istanza Aurora, la gestione efficiente, l’ottimizzazione delle prestazioni e garantirò la sicurezza e l’efficienza dei costi.
Cos’è AWS Aurora?
Amazon Aurora è un database relazionale basato su cloud che supera i tradizionali MySQL e PostgreSQL ridimensionando dinamicamente risorse di archiviazione e di calcolo.
Secondo AWS, Aurora può offrire fino a cinque volte il throughput di MySQL standard e tre volte le prestazioni di PostgreSQL standard – grazie alla sua architettura distribuita e altamente disponibile.
Aurora è dotato di funzionalità come backup automatici, repliche di lettura per lo scaling orizzontale e meccanismi di failover che garantiscono un downtime minimo.
Il livello di archiviazione di Aurora è progettato per essere tollerante agli errori e autoguaribile.
Inoltre, i dati vengono replicati automaticamente su più Zone di Disponibilità (AZs) per garantire la durabilità.
L’immagine sottostante fornisce una panoramica ad alto livello dell’architettura e delle caratteristiche principali di Amazon Aurora.
La relazione tra il volume del cluster, l’istanza DB scrittore e le istanze DB lettrici in un cluster Aurora.Fonte: Documentazione AWS
Il motore del database monitora continuamente le query e ottimizza i piani di esecuzione, portando a significativi miglioramenti di efficienza.
Uno dei principali vantaggi di Aurora è la sua compatibilità con i database MySQL e PostgreSQL esistenti, che facilita la migrazione delle aziende senza la necessità di modificare ampiamente le loro applicazioni.
La struttura dei costi di Aurora è anche attraente. Addebita in base all’uso effettivo delle risorse di calcolo e di archiviazione. Questo modello di costo elimina la necessità di sovraprovisionare l’infrastruttura, il che a sua volta fa risparmiare denaro.
> Se sei interessato a una comprensione più ampia delle opzioni di archiviazione AWS, dai unocchiata a questo Tutorial di Archiviazione AWS.
Impostazione di AWS Aurora
Impostare AWS Aurora implica la creazione di un cluster di database, la configurazione delle impostazioni di sicurezza e l’assicurazione di un accesso di rete adeguato. Facciamo questo in questa sezione!
> Se sei nuovo su AWS, considera di rivedere argomenti fondamentali con il corso di Introduzione ad AWS prima di immergerti in Aurora.
Creazione di un cluster di database Aurora
Impostare un cluster di database Aurora richiede alcuni passaggi chiave, inclusa la selezione del motore di database appropriato, la configurazione delle impostazioni di sicurezza e la definizione delle specifiche dell’istanza.
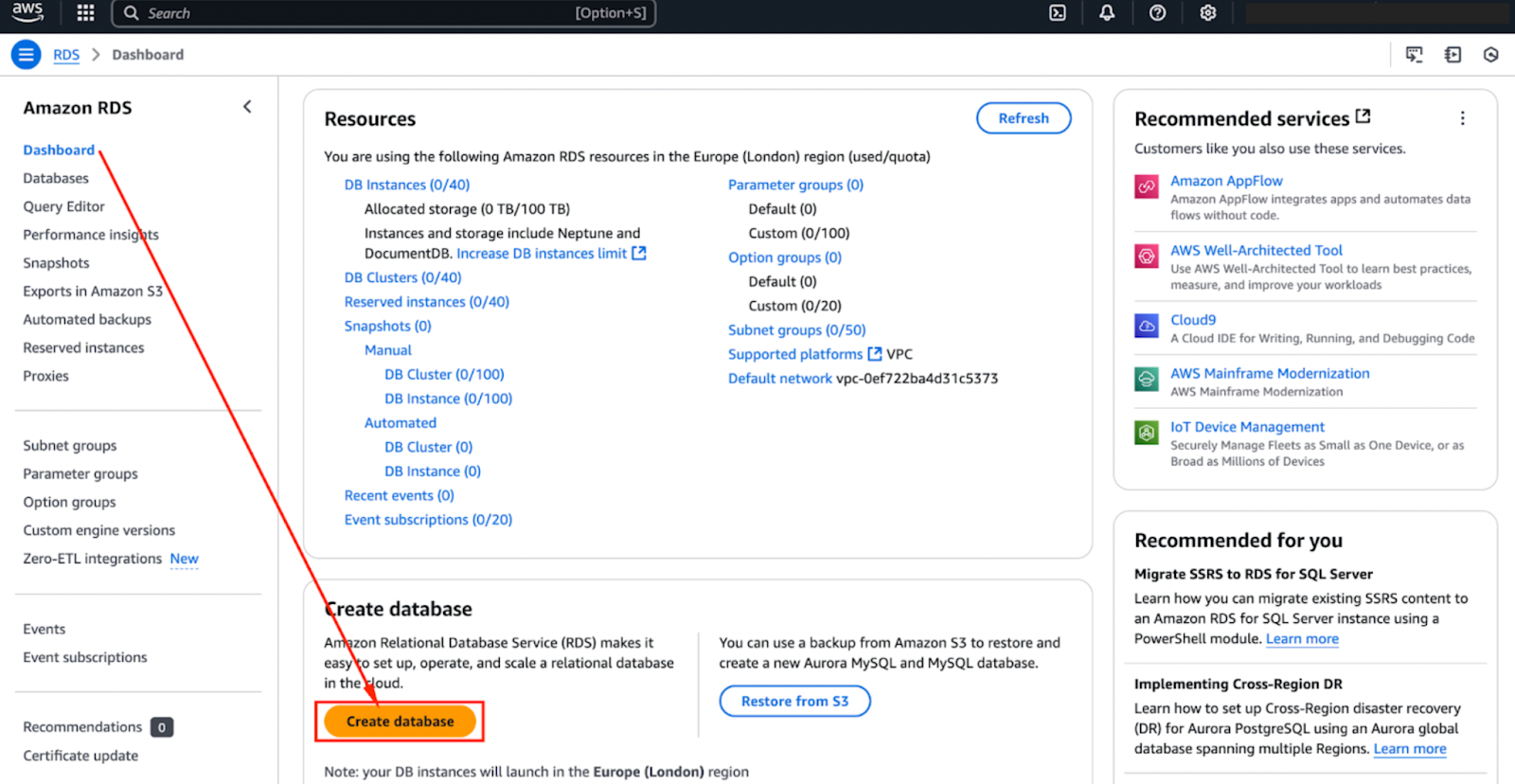
- Per iniziare, accedi alla Console di gestione AWS e naviga verso il cruscotto RDS (Relational Database Service).
- Puoi farlo cercando “Aurora” nel pannello di ricerca della console di gestione AWS – come mostrato nell’immagine qui sotto.
- Una volta lì, fai clic su “Crea Database” – come mostrato nell’immagine qui sotto.
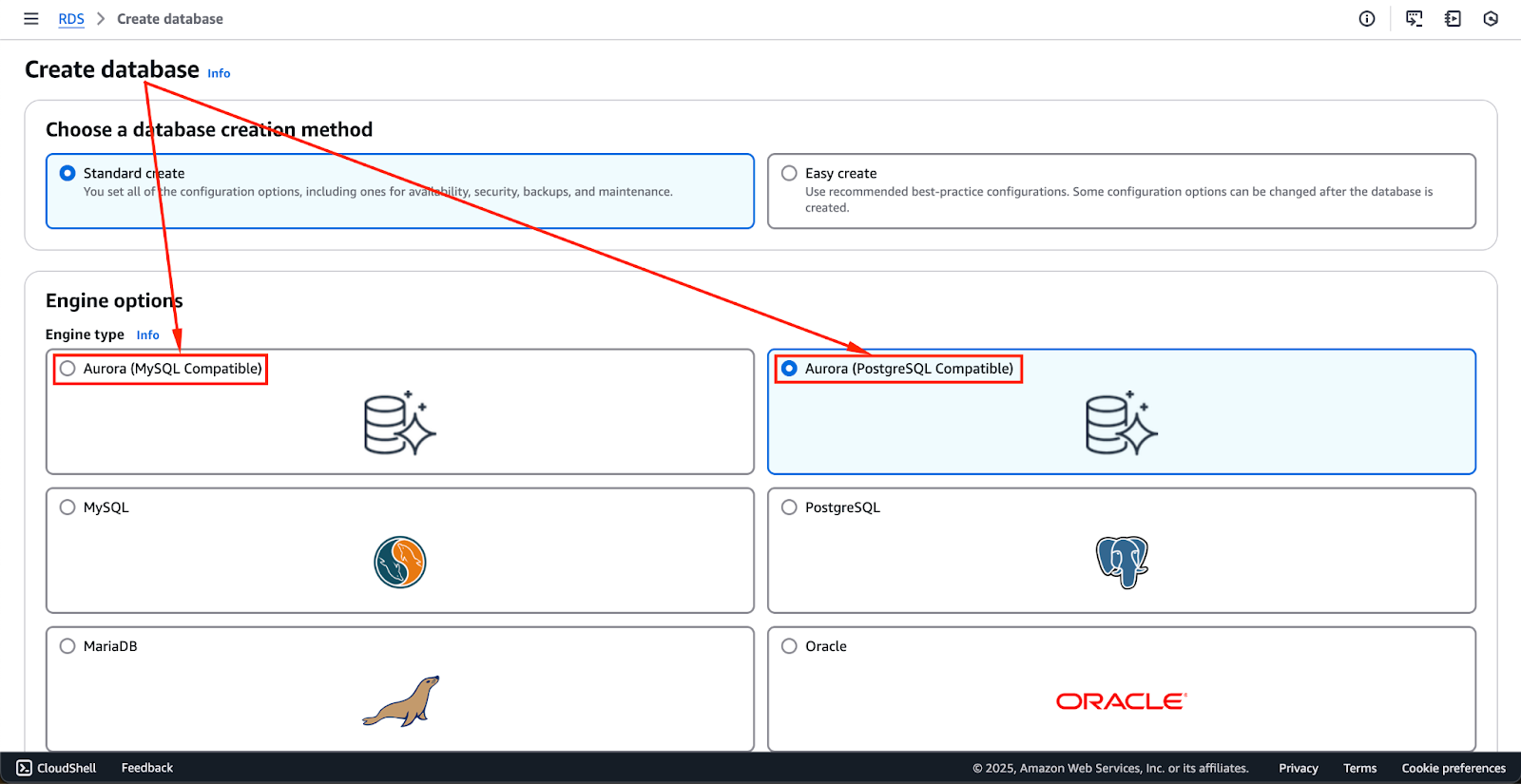
- Avrai quindi l’opzione di scegliere “Amazon Aurora” come motore di database.
- Ricorda che Aurora supporta sia MySQL che PostgreSQL, quindi è importante selezionare la versione che meglio soddisfa i requisiti della tua applicazione.
L’immagine qui sotto mostra le motore di database attualmente disponibili. Questi potrebbero cambiare in futuro, ma le prime due opzioni – Aurora (compatibile con MySQL) e Aurora (compatibile con PostgreSQL) – sono i motori di Aurora.
- Dopo aver selezionato il motore, è necessario specificare il tipo di istanza e le configurazioni dello storage.
- Aurora fornisce la flessibilità di aumentare automaticamente lo storage fino a 128TB, garantendo che i carichi di lavoro in crescita siano gestiti in modo efficiente senza richiedere intervento manuale.
- Il passo successivo è definire le impostazioni di replica. Puoi optare per un’implementazione a singola istanza o abilitare le repliche di lettura per distribuire il traffico del database in modo più efficace.
- L’utilizzo delle repliche di lettura migliora anche la disponibilità e la tolleranza ai guasti, garantendo una maggiore durabilità in caso di fallimenti.
L’immagine sottostante evidenzia la “Disponibilità & durabilità” sezione, dove puoi configurare queste impostazioni.
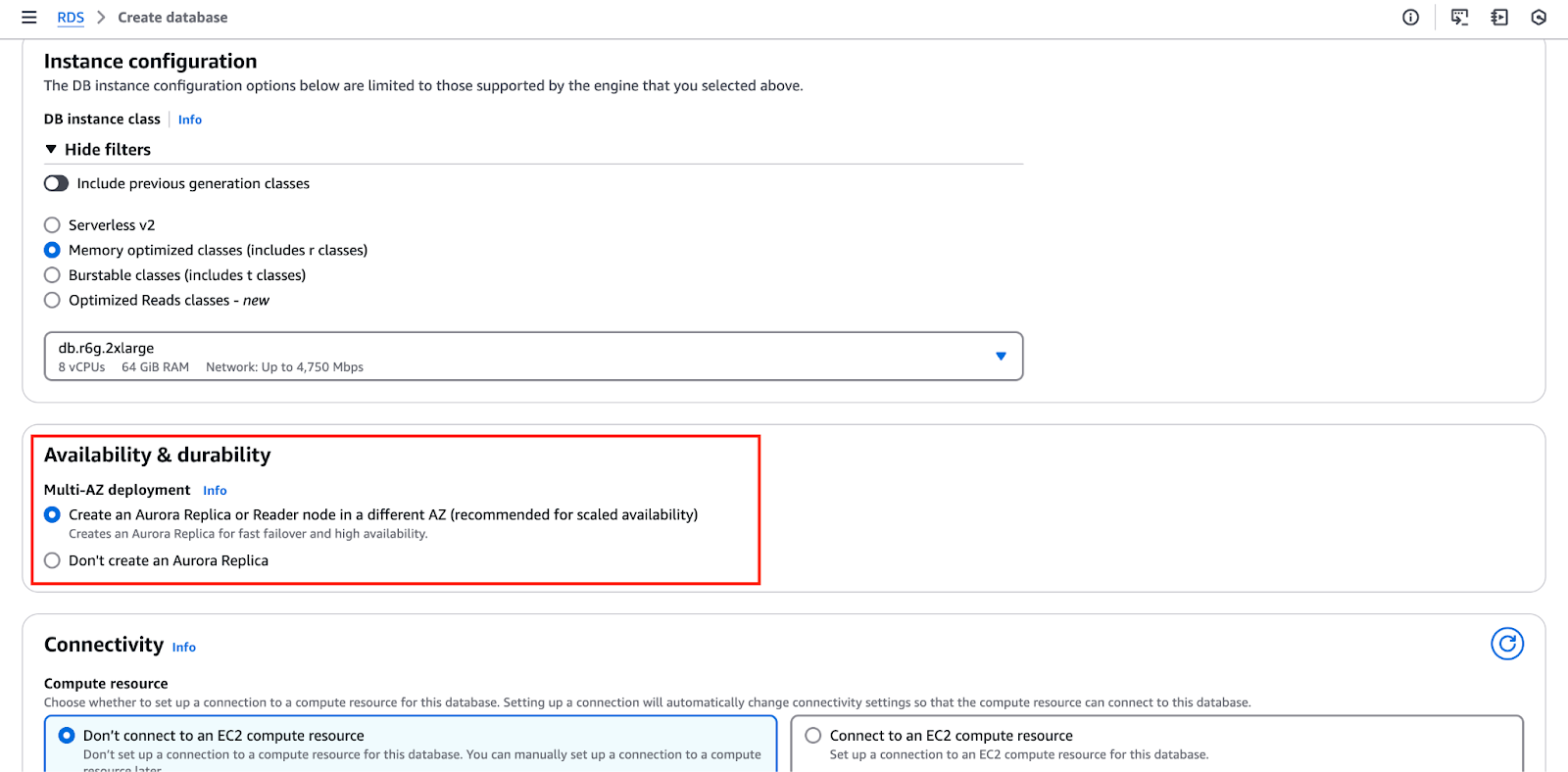
- La fase di configurazione della rete è fondamentale, in quanto implica la configurazione del Cloud Privato Virtuale (VPC), la selezione di un gruppo di sicurezza e la definizione dei controlli di accesso.
- Un gruppo di sicurezza funge da firewall che regola il traffico del database in entrata e in uscita. Per migliorare la sicurezza, si consiglia di consentire l’accesso solo da indirizzi IP e applicazioni fidate.
L’immagine sottostante evidenzia la “Connettività” sezione, dove puoi configurare e personalizzare queste impostazioni.
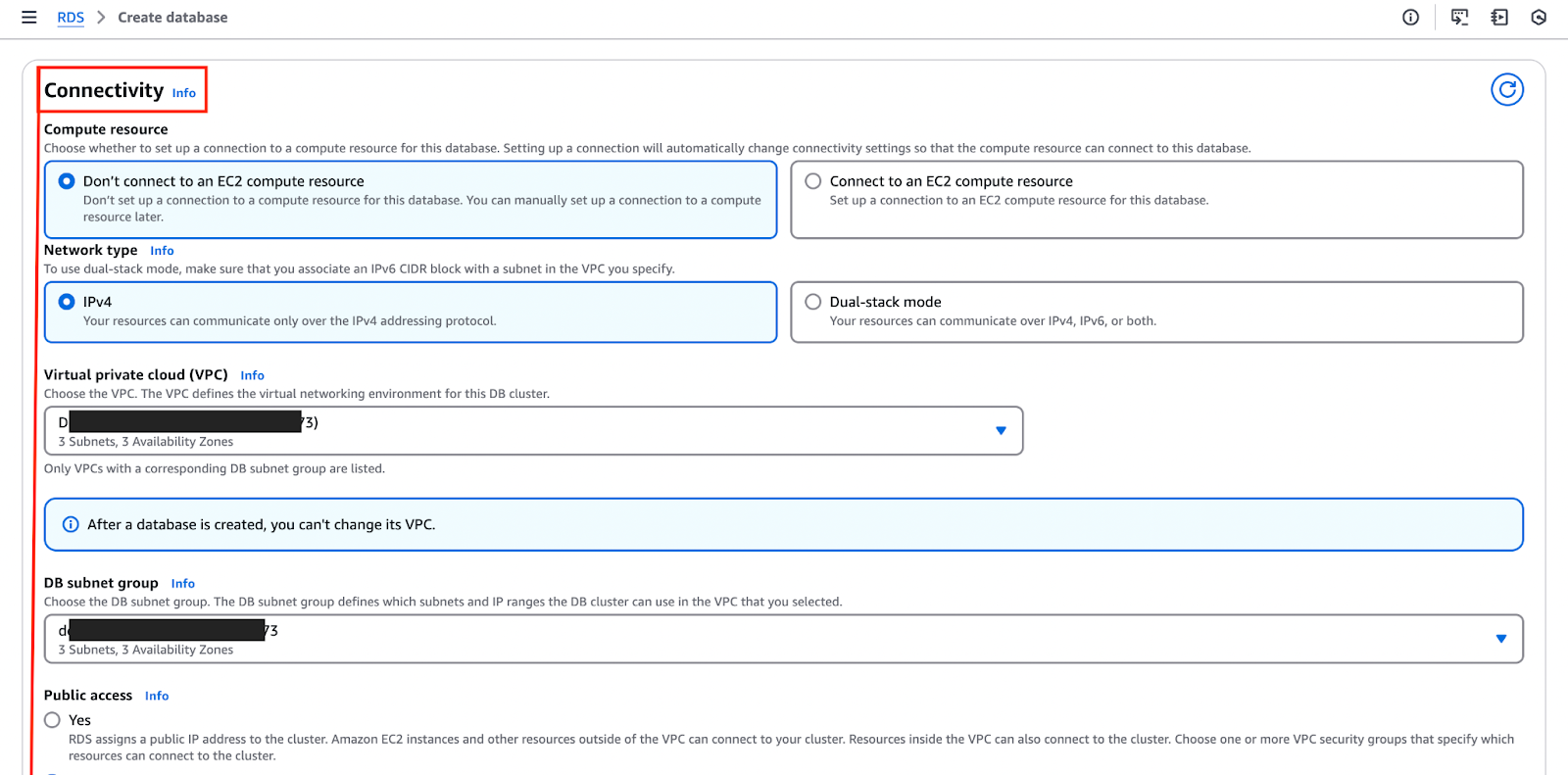
- Le credenziali del database devono essere configurate anche durante la configurazione – dove assegni un nome utente principale e una password che verranno utilizzati per autenticare le connessioni.
- Aurora consente di abilitare backup automatici e opzioni di ripristino fino a un determinato punto nel tempo. Ciò garantisce che gli snapshot del database vengano creati in modo coerente per prevenire la perdita di dati.
Dopo aver esaminato tutte le configurazioni, è possibile procedere con la creazione del cluster di Aurora. L’immagine qui sotto mostra il pulsante “Crea Database” su cui è possibile fare clic per avviare il processo di creazione.
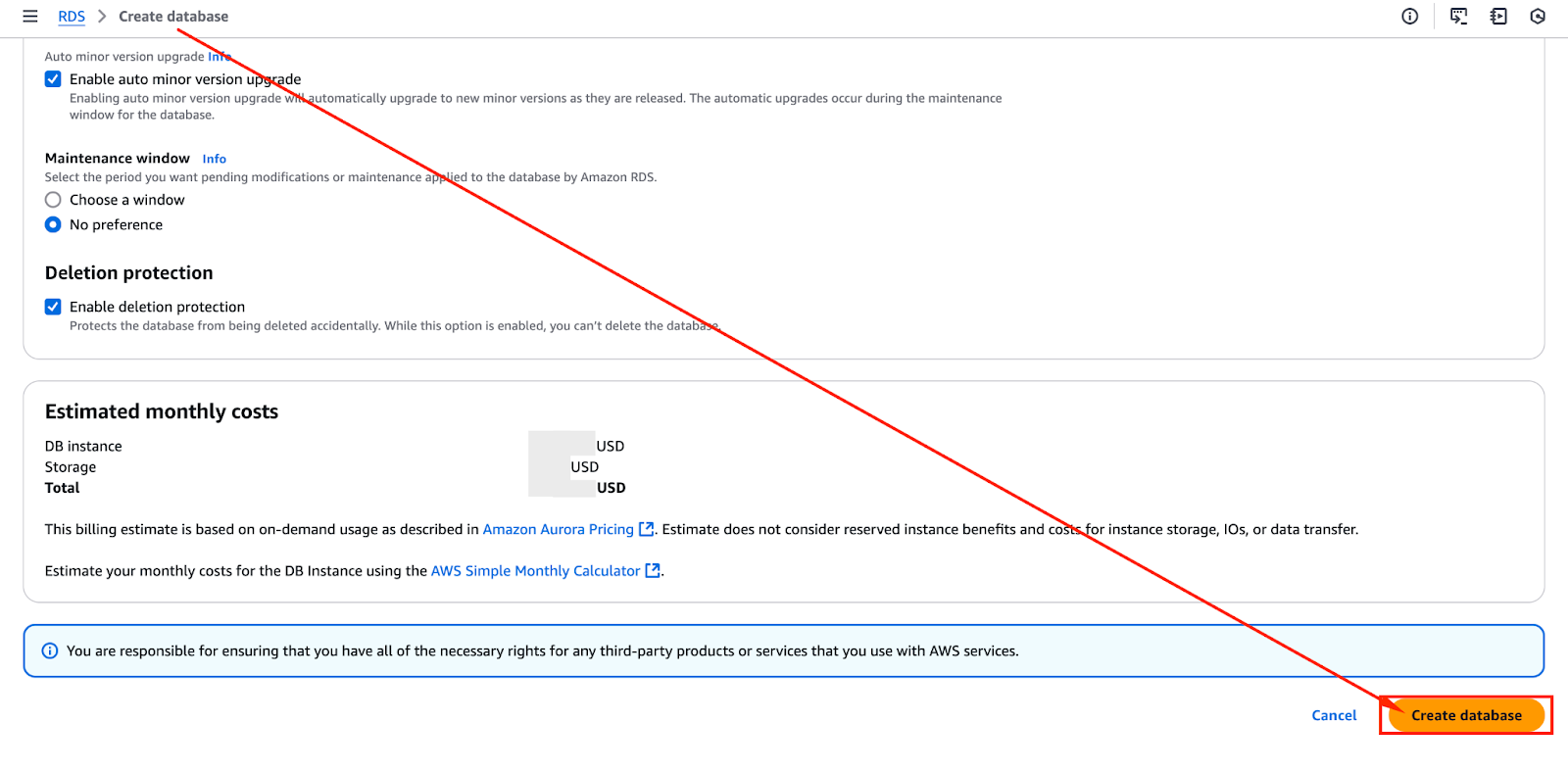
Il processo di provisioning potrebbe richiedere diversi minuti, a seconda della dimensione dell’istanza selezionata e delle impostazioni di rete.
> Se sei nuovo nei servizi AWS, la revisione del corso Tecnologia e Servizi Cloud AWS può aiutarti a comprendere i concetti chiave di AWS rilevanti per la configurazione di Aurora.
Configurazione della rete e della sicurezza
La sicurezza è fondamentale per la gestione di un database Aurora e AWS fornisce diversi strumenti per applicare controlli di accesso robusti.
- Il primo passo per proteggere un’istanza di Aurora è configurare i gruppi di sicurezza VPC. Questi gruppi determinano quali indirizzi IP e servizi possono interagire con il database.
- Dovresti limitare l’accesso a server di applicazioni specifici e amministratori per evitare connessioni non autorizzate.
- Identity and Access Management (IAM) di AWS può anche essere utilizzato per definire autorizzazioni dettagliate per le operazioni sul database.
- L’integrazione dei ruoli IAM consente di adattare l’accesso al database in base ai ruoli e alle responsabilità specifiche degli utenti.
- Ad esempio, agli sviluppatori di applicazioni potrebbe essere concesso solo l’accesso in lettura, mentre gli amministratori avranno pieno controllo sulle modifiche al database.
- La crittografia dovrebbe essere attivata per proteggere i dati sensibili. AWS Aurora supporta la crittografia a riposo e in transito utilizzando il servizio di gestione delle chiavi AWS (KMS).
- Crittografare i dati a riposo assicura che anche se i supporti di memorizzazione vengono compromessi, i dati rimangono inaccessibili senza la corretta chiave di decrittazione.
- Allo stesso modo, abilitare la crittografia Secure Sockets Layer (SSL) per i dati in transito previene l’intercettazione non autorizzata delle comunicazioni del database.
> Per approfondire la sicurezza degli ambienti AWS, dai un’occhiata al corso di Sicurezza e Gestione dei Costi AWS. Se vuoi saperne di più su come funziona IAM e come implementarlo in modo efficace, dai un’occhiata a questa guida su Gestione dell’Identità e Accesso di AWS (IAM).
Connessione ad AWS Aurora
La connessione ad AWS Aurora è essenziale per interagire con il database. Puoi farlo sia tramite strumenti client che applicazioni. Scopriamo come in questa sezione!
Connessione ad Aurora MySQL
Una volta che il database di Aurora è attivo e in esecuzione, devi stabilire una connessione per iniziare a interagire con il database.
Per Aurora MySQL, è possibile utilizzare client di database comuni come MySQL Workbench e HeidiSQL per connettersi. In alternativa, è possibile utilizzare interfacce a riga di comando.
La connessione richiede di specificare l’endpoint del database, che può essere trovato nella AWS Management Console.
Utilizzando il MySQL CLI, la connessione può essere stabilita con il seguente comando:
mysql -h your-cluster-endpoint -u admin -p
Dopo aver inserito la password master, dovresti essere in grado di eseguire query SQL, creare tabelle e gestire i dati.
Collegarsi a Aurora PostgreSQL
Per Aurora PostgreSQL, puoi connetterti utilizzando strumenti come pgAdmin o l’interfaccia a riga di comando di PostgreSQL (psql).
Il comando di connessione in psql segue questo formato:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Proprio come con MySQL, devono essere inserite le credenziali corrette per accedere al database.
Una volta ottenuto l’accesso, dovresti essere in grado di eseguire query SQL, creare tabelle e gestire i dati.
Configurare la connettività dell’applicazione
Le applicazioni che devono interagire con Aurora devono essere configurate con stringhe di connessione al database appropriate. Di solito, queste stringhe di connessione consistono nel nome utente, nella password, nel numero di porta e nell’endpoint.
Si raccomanda di utilizzare il pooling delle connessioni per ottimizzare le prestazioni e ridurre il sovraccarico di stabilire nuove connessioni per ogni richiesta.
Biblioteche popolari come SQLAlchemy per Python o JDBC per Java offrono modi efficienti per gestire le connessioni in un ambiente applicativo.
Gestire AWS Aurora
Gestire efficacemente AWS Aurora implica garantire la protezione dei dati, monitorare le prestazioni e scalare le risorse secondo necessità. In questa sezione, esamineremo queste pratiche.
Backup e snapshot
AWS Aurora offre backup automatici che catturano e memorizzano continuamente le modifiche al database in Amazon S3. Questi backup sono conservati in base alle impostazioni definite dall’utente, consentendo il ripristino a qualsiasi punto all’interno del periodo di conservazione.
Oltre ai backup automatici, puoi anche creare snapshot manuali che persistono oltre la finestra di conservazione. Gli snapshot manuali sono particolarmente utili per l’archiviazione a lungo termine o prima di eseguire importanti aggiornamenti del database.
Quando ho lavorato a un progetto con un’applicazione critica, abbiamo programmato backup automatici ogni due ore. Tuttavia, prima di apportare modifiche o aggiornamenti all’applicazione, creavamo manualmente un backup per assicurarci di poter tornare indietro se necessario. Questo dimostra come i backup automatici e manuali possano essere utilizzati efficacemente insieme.
L’immagine qui sotto mostra come AWS Backup può essere utilizzato per il ripristino di emergenza con Amazon Aurora.
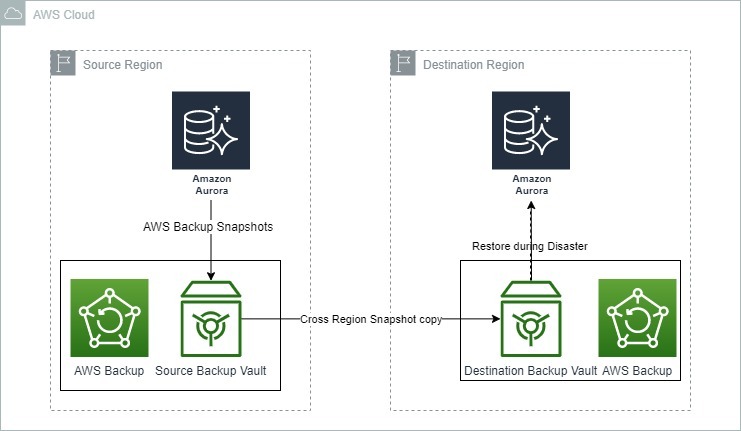
Opzioni di backup e ripristino per Amazon Aurora. Fonte: Blog di AWS
Monitoraggio di Aurora con CloudWatch
Il monitoraggio delle prestazioni è essenziale per mantenere un database sano.
AWS CloudWatch fornisce metriche in tempo reale che tracciano l’utilizzo della CPU, l’uso della memoria, l’I/O del disco e il traffico di rete.
Configurare gli allarmi di CloudWatch può aiutare gli amministratori a essere notificati quando i limiti delle prestazioni vengono superati, consentendo una gestione proattiva del database.
Inoltre, AWS Performance Insights offre un’analisi dettagliata delle query per identificare e ottimizzare le query lente.
L’immagine qui sotto illustra come AWS Performance Insights fornisce informazioni sulle prestazioni del database.
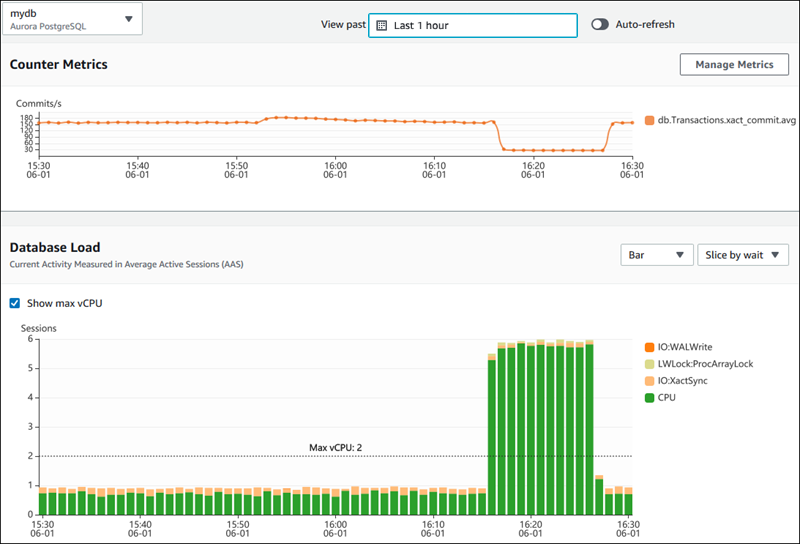
Dashboard di AWS Performance Insights che mostra le metriche delle prestazioni del database. Fonte: Documentazione di AWS
Scaling di Aurora
Aurora è progettato per scalare automaticamente regolando la capacità di archiviazione secondo necessità. Tuttavia, le risorse di calcolo come CPU e memoria potrebbero dover essere regolate manualmente a seconda del carico di lavoro.
Aurora offre opzioni per scalare la capacità di lettura aggiungendo repliche di lettura, che distribuiscono il traffico di lettura e migliorano le prestazioni.
Quando l’alta disponibilità è critica, un cluster Aurora può essere configurato con più repliche in diverse Zone di Disponibilità per garantire ridondanza in caso di failover.
Ottimizzazione delle prestazioni in AWS Aurora
Ottimizzare le prestazioni in Amazon Aurora garantisce un’esecuzione delle query efficiente e scalabilità. Vediamo alcune best practice in questa sezione.
Indicizzazione e ottimizzazione delle query
Ottimizzare le prestazioni delle query in Amazon Aurora è fondamentale per mantenere un database ad alte prestazioni.
- L’indicizzazione è uno dei modi più efficaci per ridurre il tempo di esecuzione delle query e migliorare l’efficienza del database.
- Creare indici su colonne frequentemente interrogate può aiutare a localizzare rapidamente i dati, riducendo al minimo la necessità di scansioni complete della tabella.
- Dovresti utilizzare strategicamente indici primari e secondari per allinearti ai modelli di query e alle richieste di carico di lavoro.
- Oltre a quanto sopra, puoi impiegare indici compositi per le query che coinvolgono più colonne per migliorare ulteriormente i tempi di ricerca.
- L’ottimizzazione delle query gioca anche un ruolo significativo nelle prestazioni del database. Scrivere query SQL efficienti garantisce che Aurora elabori le richieste più rapidamente con un consumo minimo di risorse.
- L’utilizzo di
EXPLAIN o EXPLAIN ANALYZEnelle query SQL aiuta a identificare i collo di bottiglia e fornisce un’idea sui piani di esecuzione. - Tecniche come evitare
SELECT *(che recupera dati non necessari), normalizzare lo schema del database per ridurre la ridondanza e sfruttare strategie di partizionamento possono portare a miglioramenti delle prestazioni. - L’ottimizzatore del piano di query di Aurora raffina continuamente i piani di esecuzione, apportando aggiustamenti in base ai modelli di carico di lavoro del database, migliorando così l’efficienza complessiva.
Utilizzando le repliche di lettura di Aurora
Per gestire carichi di lavoro ad alta intensità, Amazon Aurora supporta repliche di lettura che aiutano a distribuire query ad alta intensità di lettura su più istanze.
Le repliche di lettura riducono il carico sull’istanza principale del database elaborando le richieste di lettura separatamente, il che migliora la reattività e riduce la latenza.
Per impostare una replica di lettura di Aurora, è necessario selezionare un cluster Aurora esistente e abilitare la replica con una configurazione minima. Aurora sincronizza automaticamente i dati tra l’istanza principale e le sue repliche, garantendo la coerenza dei dati senza intervento manuale.
Il meccanismo di replica di Aurora è altamente efficiente, consentendo la sincronizzazione dei dati quasi in tempo reale con un ritardo di replica inferiore a un secondo.
Le applicazioni che eseguono operazioni di lettura frequenti, come cruscotti di reporting o servizi di analisi, possono beneficiare notevolmente delle repliche di lettura indirizzando le query ad alta intensità di lettura a queste istanze.
In caso di guasto dell’istanza primaria, una replica di lettura può essere promossa a diventare la nuova istanza primaria con un’interruzione minima, garantendo alta disponibilità e continuità aziendale.
L’immagine sottostante mostra come le repliche Aurora tra regioni possano aiutare con il recupero da disastri e l’alta disponibilità.
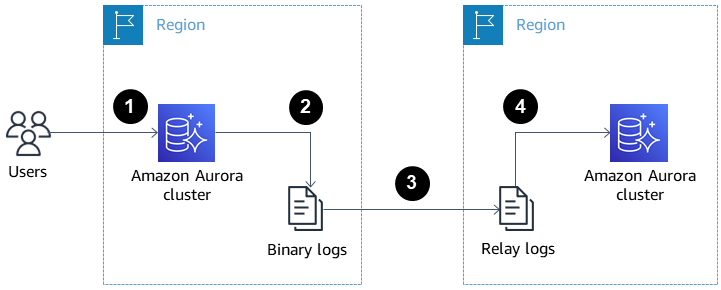
Repliche di lettura Aurora tra regioni per il recupero da disastri e l’alta disponibilità. Fonte: AWS Docs
Strategie di caching per Aurora
Il caching è una tecnica potente per migliorare le prestazioni del database riducendo il carico delle query dirette su Aurora. Uno strato di caching può accelerare significativamente il recupero dei dati per le query frequentemente accessibili.
Amazon ElastiCache, che supporta Redis e Memcached, è comunemente utilizzato insieme ad Aurora per memorizzare i risultati delle query e prevenire query ridondanti al database.
L’integrazione della cache in un’architettura applicativa può aiutare a migliorare i tempi di risposta preservando le risorse di calcolo del database.
Strategie di caching come il caching write-through (dove i dati vengono scritti sia nella cache che in Aurora simultaneamente) e il lazy loading (dove i dati vengono memorizzati nella cache solo quando richiesti) aiutano a ottimizzare le prestazioni in base ai modelli di utilizzo.
Configurare un appropriato tempo di vita (TTL) per i dati memorizzati nella cache garantisce che la cache rimanga fresca e previene il recupero di dati obsoleti.
Security and Compliance in AWS Aurora
Proteggere il tuo database Aurora è cruciale per proteggere i dati sensibili e garantire la conformità. Vediamo le migliori pratiche in questa sezione.
Crittografia dei dati
La sicurezza dei dati è fondamentale per la gestione del database, e AWS Aurora fornisce robusti meccanismi di crittografia per proteggere i dati sensibili.
- Aurora crittografa i dati a riposo utilizzando il servizio di gestione chiavi AWS (KMS), che garantisce che le informazioni archiviate rimangano sicure anche se lo storage sottostante viene compromesso.
- Abilitare la crittografia durante la creazione del database assicura che tutti i backup automatici, gli snapshot e le repliche ereditino le stesse impostazioni di crittografia.
- Per dati in transito, Aurora supporta la crittografia SSL/TLS, che garantisce connessioni sicure al database e previene accessi non autorizzati o intercettazioni delle trasmissioni di dati.
- Le applicazioni che si connettono ad Aurora dovrebbero essere configurate per utilizzare certificati SSL per mantenere una comunicazione sicura.
Queste misure di crittografia possono aiutarti a rispettare le migliori pratiche di sicurezza e i requisiti normativi.
L’immagine qui sotto dimostra come AWS KMS si integra con Amazon Aurora per crittografare il tuo database.
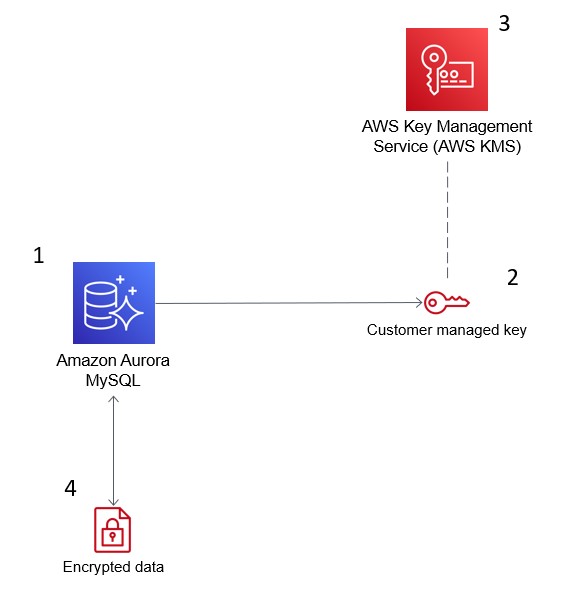
AWS Key Management Service (KMS) crittografa i dati in Amazon Aurora per conformità alla sicurezza. Fonte: Blog AWS
Integrazione IAM per il controllo degli accessi
Il controllo degli accessi in Aurora è gestito tramite AWS IAM, che consente agli amministratori di definire autorizzazioni dettagliate basate sui ruoli dell’utente.
- Le policy IAM possono essere utilizzate per limitare l’accesso alle istanze del database, impedendo agli utenti non autorizzati di eseguire operazioni critiche come modifiche ai dati o attività amministrative.
- L’autenticazione IAM fornisce un’alternativa più sicura all’autenticazione basata su password tradizionale. Consente alle applicazioni di connettersi utilizzando credenziali di sicurezza temporanee. Ciò elimina la necessità di memorizzare e gestire le password del database, riducendo il rischio di esposizione delle credenziali.
Dovresti applicare i principi di accesso con privilegi minimi, che riducono i rischi per la sicurezza e mantengono un controllo rigoroso sull’accesso al database.
L’immagine qui sotto mostra come l’autenticazione IAM può essere configurata per proteggere l’accesso al database Amazon Aurora PostgreSQL.
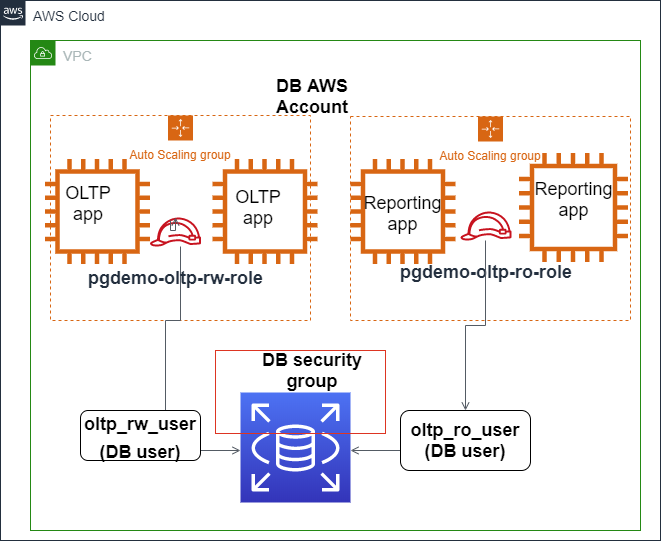
L’autenticazione IAM si integra con Amazon Aurora PostgreSQL. Fonte: Blog AWS
Auditare con i log di Aurora
Il monitoraggio e l’audit delle attività del database sono essenziali per la conformità alla sicurezza e per la risoluzione dei problemi.
Aurora fornisce diversi meccanismi di registrazione, tra cui log degli errori, log delle query lente e log generali, che aiutano gli amministratori a tenere traccia delle attività del database e a identificare potenziali problemi. Questi log possono essere attivati tramite la Console di gestione AWS e archiviati in Amazon CloudWatch per un’analisi centralizzata.
- Log degli errori catturano errori e avvisi del motore di database.
- Log delle query lente aiutano a identificare query inefficaci che possono influenzare le prestazioni.
L’analisi di questi log può aiutare gli amministratori a ottimizzare l’esecuzione delle query, rilevare tentativi di accesso non autorizzati e garantire la stabilità del database.
Gestione dei costi e ottimizzazione in AWS Aurora
Per gestire ed ottimizzare efficacemente i costi in Amazon Aurora, è necessario comprendere la sua struttura dei prezzi. Vediamola insieme!
Comprensione della struttura dei prezzi di Aurora
Il modello di prezzi di Amazon Aurora si basa su diversi fattori, tra cui le ore di istanza, il consumo di storage, le richieste di I/O e il trasferimento di dati.
A differenza dei database tradizionali che richiedono la fornitura anticipata di infrastrutture, il modello pay-as-you-go di Aurora consente alle aziende di pagare solo per le risorse consumate.
Le istanze di calcolo vengono addebitate in base alla classe dell’istanza e al tempo di attività, mentre lo storage è scalato dinamicamente, eliminando la necessità di aggiustamenti manuali.
L’immagine sottostante fornisce una suddivisione dei diversi componenti di prezzo per Amazon Aurora. Tuttavia, tieni presente che i prezzi possono cambiare, quindi è sempre meglio fare riferimento alla pagina dei prezzi di Aurora per le informazioni più aggiornate.
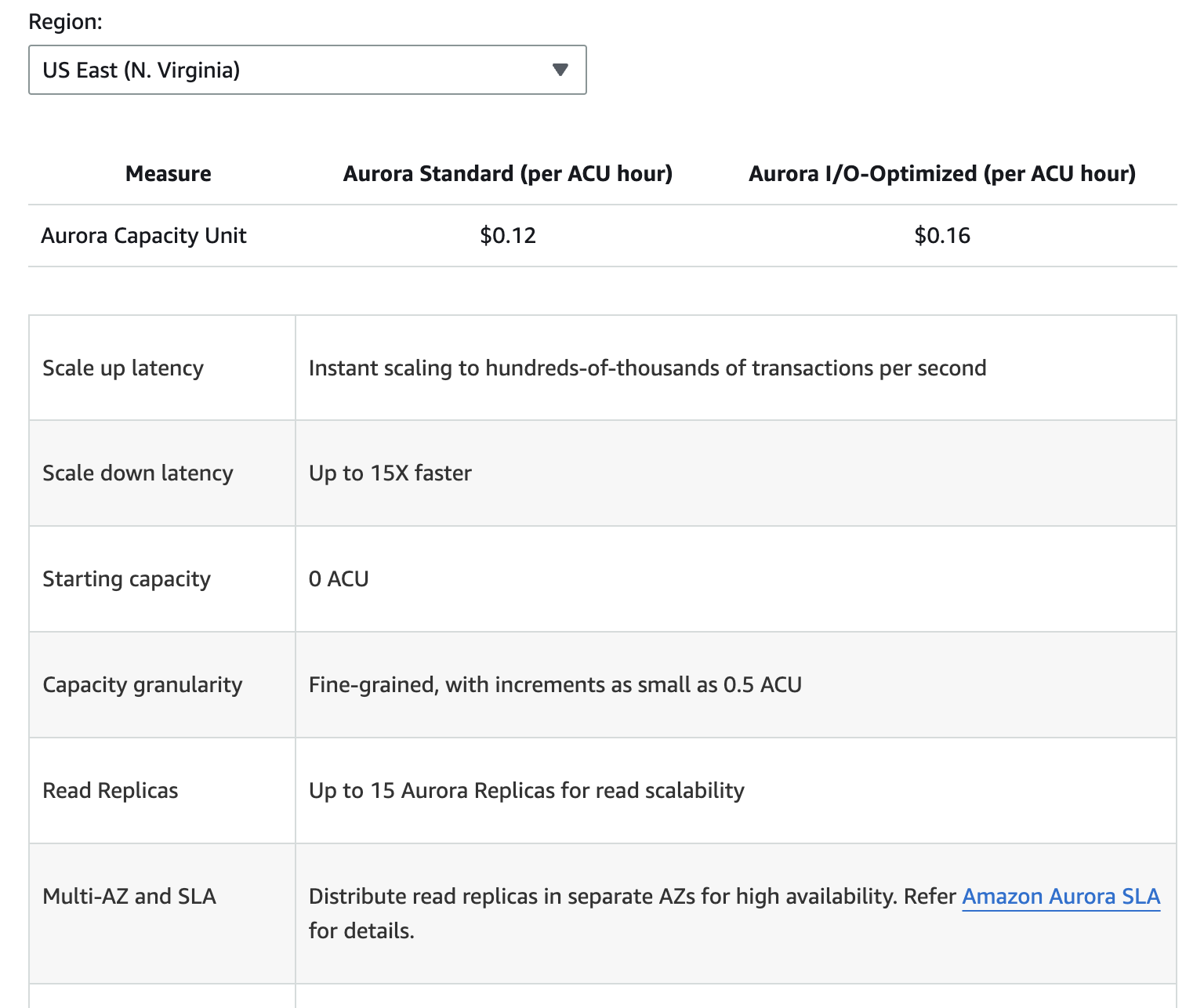
I costi aggiuntivi includono lo storage di backup oltre il livello gratuito allocato, le richieste di I/O di lettura e scrittura, e le spese per il trasferimento dati per la replicazione tra regioni.
Comprendere questi componenti di prezzo può aiutarti a prevedere le spese e prendere decisioni informate riguardo all’utilizzo del database.
L’ottimizzazione dei costi con Aurora
Per gestire i costi in modo efficace, le organizzazioni possono implementare diverse strategie di ottimizzazione.
La scelta della dimensione dell’istanza appropriata garantirà che le risorse del database siano allineate alle esigenze del carico di lavoro senza sovradimensionamento.
- Se si dispone di un carico di lavoro prevedibile, utilizzare le Istanze Riservate poiché offrono significativi risparmi sui costi rispetto alla tariffazione On-Demand.
- Tecniche di ottimizzazione dello storage, come monitorare risorse inutilizzate o sottoutilizzate, aiutano a ridurre i costi.
- La funzionalità di auto-scaling di Aurora regola dinamicamente lo storage, evitando spese di storage non necessarie.
- Inoltre, implementare repliche di lettura può alleggerire le query dall’istanza primaria, riducendo potenzialmente la necessità di istanze di livello superiore.
- Sfruttare Aurora Serverless, poiché è un’altra opzione economica per le applicazioni con carichi di lavoro variabili. Aurora Serverless ridimensiona automaticamente le risorse di calcolo in base alla domanda, garantendo che le imprese paghino solo per l’utilizzo effettivo anziché mantenere costantemente una istanza in esecuzione.
> Se desideri approfondire la gestione dei costi, consulta il corso AWS Security and Cost Management.
Conclusion
Dopo aver lavorato con Amazon Aurora in diverse aziende per un po’ di tempo, posso affermare con sicurezza che si tratta di una soluzione di database potente e scalabile che semplifica la gestione senza compromettere le prestazioni; probabilmente sarai d’accordo dopo aver seguito questo tutorial.
Aurora merita di essere presa in considerazione se stai cercando un database relazionale nativo del cloud che supporta MySQL e PostgreSQL riducendo al contempo l’onere operativo. È stata rivoluzionaria in alcuni dei miei progetti e consiglio vivamente di esplorarne le potenzialità se stai lavorando con i database AWS.
Se sei nuovo nei database AWS, imparare i concetti fondamentali attraverso corsi come AWS Cloud Practitioner (CLF-C02) può essere utile!