













Il 11 dicembre 2024, i servizi di OpenAI hanno riscontrato un’interruzione significativa a causa di un problema derivante dalla distribuzione di un nuovo servizio di telemetria. Questo incidente ha avuto un impatto sui servizi API, ChatGPT e Sora, causando interruzioni che sono durate per diverse ore. Come azienda che mira a fornire soluzioni AI accurate ed efficienti, OpenAI ha condiviso un dettagliato rapporto post-mortem per discutere in modo trasparente ciò che è andato storto e come intendono prevenire situazioni simili in futuro.
In questo articolo, descriverò gli aspetti tecnici dell’incidente, analizzerò le cause principali ed esplorerò le lezioni fondamentali che i programmatori e le organizzazioni che gestiscono sistemi distribuiti possono trarre da questo evento.
Cronologia dell’Incidente
Ecco un riassunto di come gli eventi si sono svolti l’11 dicembre 2024:
| Time (PST) | Event |
|---|---|
| 15:16 | Inizio dell’impatto minore sui clienti; osservata degradazione del servizio |
| 15:27 | Gli ingegneri hanno iniziato a reindirizzare il traffico dai cluster interessati |
| 15:40 | Registrato l’impatto massimo sui clienti; gravi interruzioni su tutti i servizi |
| 16:36 | Il primo cluster Kubernetes ha iniziato a riprendersi |
| 17:36 | È iniziata una ripresa sostanziale per i servizi API |
| 17:45 | Osservata una ripresa sostanziale per ChatGPT |
| 19:38 | Tutti i servizi sono stati completamente ripristinati su tutti i cluster |
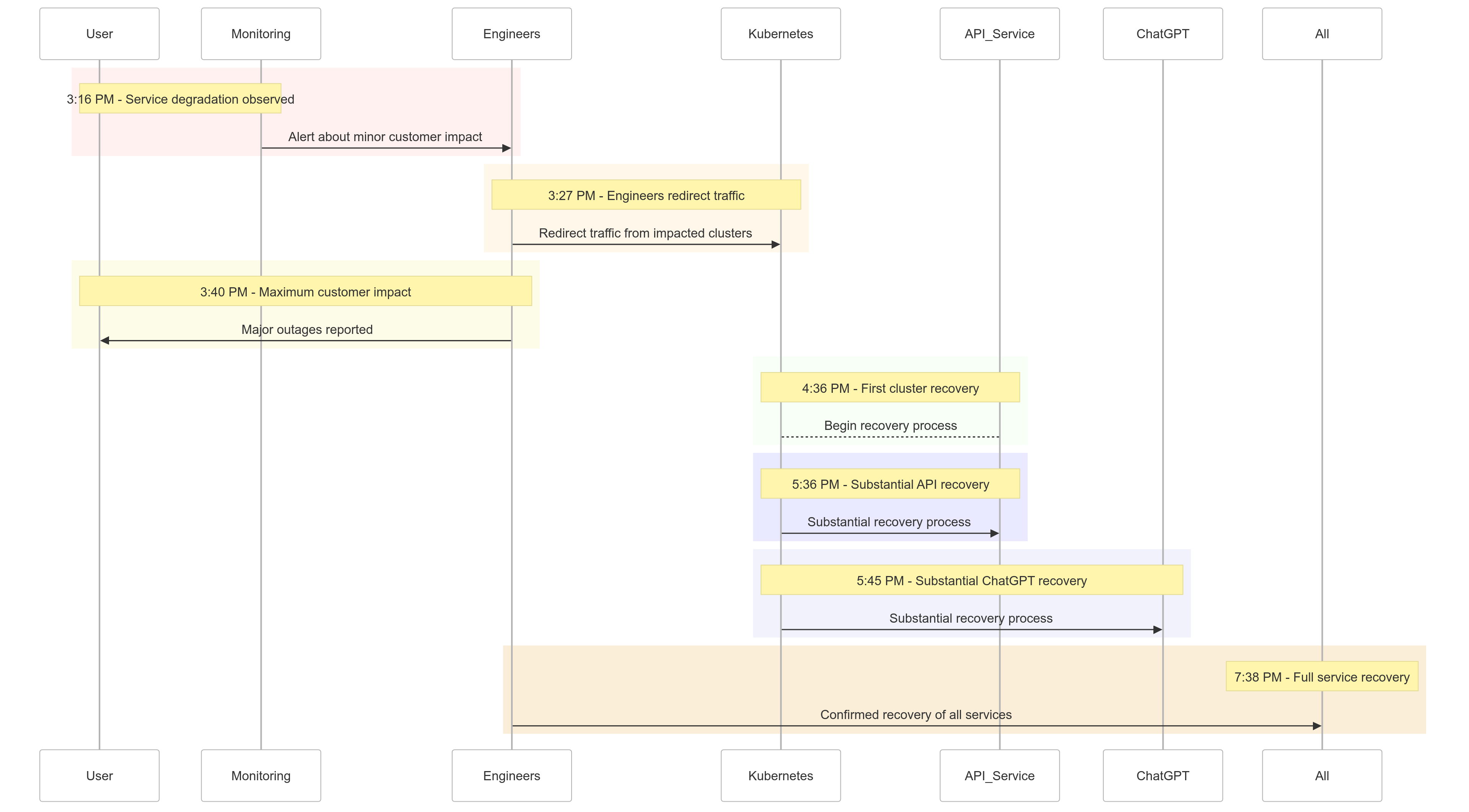
Figura 1: Cronologia dell’incidente OpenAI – Dalla degradazione del servizio al completo recupero.
Analisi della causa principale
La radice dell’incidente risiedeva in un nuovo servizio di telemetria implementato alle 15:12 PST per migliorare l’osservabilità dei piani di controllo di Kubernetes. Questo servizio ha involontariamente sopraffatto i server API di Kubernetes in più cluster, portando a guasti a cascata.
Analizzando il problema
Implementazione del servizio di telemetria
Il servizio di telemetria era progettato per raccogliere metriche dettagliate del piano di controllo di Kubernetes, ma la sua configurazione ha inavvertitamente attivato operazioni API di Kubernetes ad alta intensità di risorse su migliaia di nodi contemporaneamente.
Piano di controllo sovraccarico
Il piano di controllo di Kubernetes, responsabile dell’amministrazione del cluster, è diventato sovraccarico. Sebbene il piano dati (che gestisce le richieste degli utenti) rimanesse parzialmente funzionale, dipendeva dal piano di controllo per la risoluzione DNS. Man mano che i record DNS memorizzati nella cache scadevano, i servizi che si basavano sulla risoluzione DNS in tempo reale cominciarono a fallire.
Test Insufficienti
L’implementazione è stata testata in un ambiente di staging, ma i cluster di staging non rispecchiavano la scala dei cluster di produzione. Di conseguenza, il problema del carico del server API è passato inosservato durante i test.
Come è stato mitigato il problema
Quando è iniziato l’incidente, gli ingegneri di OpenAI hanno rapidamente identificato la causa principale ma hanno affrontato difficoltà nell’implementare una soluzione poiché il piano di controllo di Kubernetes sovraccaricato impediva l’accesso ai server API. È stato adottato un approccio a più livelli:
- Riduzione della dimensione del cluster: Ridurre il numero di nodi in ciascun cluster ha abbassato il carico del server API.
- Blocco dell’accesso di rete alle API di amministrazione di Kubernetes: Ha impedito ulteriori richieste API, consentendo ai server di recuperare.
- Aumento dei server API di Kubernetes: La fornitura di risorse aggiuntive ha aiutato a chiarire le richieste in sospeso.
Queste misure hanno consentito agli ingegneri di riacquistare l’accesso ai piani di controllo e rimuovere il servizio di telemetria problematico, ripristinando la funzionalità del servizio.
Lezioni Apprese
Questo incidente evidenzia la criticità di test solidi, monitoraggio e meccanismi di sicurezza nei sistemi distribuiti. Ecco cosa ha appreso (e implementato) OpenAI dall’interruzione:
1. Rollout Fase Robusti
Tutte le modifiche infrastrutturali seguiranno ora rollout a fasi con monitoraggio continuo. Questo assicura che i problemi vengano rilevati precocemente e mitigati prima di essere estesi all’intera flotta.
2. Test di Iniezione di Guasti
Simulando guasti (ad es., disabilitando il piano di controllo o implementando modifiche errate), OpenAI verificherà che i loro sistemi possano recuperare automaticamente e rilevare problemi prima che impattino sui clienti.
3. Accesso di emergenza al piano di controllo
Un meccanismo “rompere il vetro” garantirà agli ingegneri di poter accedere ai server API di Kubernetes anche sotto carichi pesanti.
4. Svincolare i Piani di Controllo e Dati
Per ridurre le dipendenze, OpenAI separerà il piano dati di Kubernetes (gestione dei carichi di lavoro) dal piano di controllo (responsabile dell’orchestrazione), garantendo che i servizi critici possano continuare a funzionare anche durante le interruzioni del piano di controllo.
5. Meccanismi di Ripristino più Veloci
Le nuove strategie di caching e limitazione della velocità miglioreranno i tempi di avvio del cluster, garantendo un ripristino più rapido durante i guasti.
Esempio di Codice: Esempio di Distribuzione Graduale
Ecco un esempio di implementazione di una distribuzione graduale per Kubernetes utilizzando Helm e Prometheus per l’osservabilità.
Distribuzione di Helm con rollout graduale:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Interrogazione di Prometheus per il monitoraggio del carico del server API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Questa interrogazione aiuta a tracciare i tempi di risposta per le richieste al server API, garantendo il rilevamento precoce di picchi di carico.
Esempio di Iniezione di Fallimenti
Utilizzando chaos-mesh, OpenAI potrebbe simulare guasti nel piano di controllo di Kubernetes.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Questa configurazione uccide intenzionalmente un pod del server API per verificare la resilienza del sistema.
Cosa Significa per Te
Questo incidente sottolinea l’importanza di progettare sistemi resilienti e adottare metodologie di testing rigorose. Che tu gestisca sistemi distribuiti su larga scala o stia implementando Kubernetes per i tuoi carichi di lavoro, ecco alcuni punti chiave:
- Simula i guasti regolarmente: Utilizza strumenti di ingegneria della caos come Chaos Mesh per testare la robustezza del sistema in condizioni reali.
- Monitora a più livelli: Assicurati che il tuo stack di osservabilità tracci sia le metriche a livello di servizio che le metriche di salute del cluster.
- Decoupla le dipendenze critiche: Riduci la dipendenza da singoli punti di guasto, come la scoperta dei servizi basata su DNS.
Conclusione
Anche se nessun sistema è immune ai guasti, incidenti come questo ci ricordano il valore della trasparenza, della rapida rimediazione e dell’apprendimento continuo. L’approccio proattivo di OpenAI nella condivisione di questo post-mortem fornisce un modello per altre organizzazioni per migliorare le loro pratiche operative e l’affidabilità.
Prioritizzando roll-out robusti e graduali, test di iniezione dei guasti e progettazione di sistemi resilienti, OpenAI sta dando un forte esempio di come gestire e apprendere da interruzioni su larga scala.
Per i team che gestiscono sistemi distribuiti, questo incidente è un ottimo caso studio su come affrontare la gestione del rischio e minimizzare i tempi di inattività per i processi aziendali core.
Utilizziamo questa opportunità per costruire insieme sistemi migliori e più resilienti.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident