













Introduzione
Nell’informatica e soprattutto nella Processamento del Linguaggio Naturale, la sintesi è sempre stato un argomento di interesse intenso. Sebbene metodi di sintesi testuale siano stati disponibili da tempo, gli ultimi anni hanno visto sviluppi significativi nel Processamento del Linguaggio Naturale e nell’apprendimento profondo. Vi è una serie di pubblicazioni sul tema da parte di giganti internet, come il recente ChatGPT. Mentre viene svolto molto lavoro su questo argomento di studio, vi è molto poco scritto sulle implementazioni pratiche di sintesi guidata da AI. La difficoltà di analizzare dichiarazioni ampie e generali è un ostacolo alla sintesi efficace.
Sintetizzare un articolo di notizie e un rapporto finanziario sulle profite sono due compiti diversi. Quando si trattano di caratteristiche testuali che variano in lunghezza o argomento (tecnologia, sport, finanza, viaggio, ecc.), la sintesi diventa un compito di scienze dati impegnativo. È essenziale coprire alcune basi nella teoria della sintesi prima di approfondire un riepilogo delle applicazioni.
Sintesi Estrattiva
Il processo di riassunto estratto comprende la selezione delle frasi più rilevanti da un articolo e la loro sistematica organizzazione. Le frasi che compongono il riassunto sono prese letteralmente dalla fonte.
I sistemi di riassunto estratto, come li conosciamo ora, si basano su tre operazioni fondamentali:
Costruzione di una rappresentazione intermedia del testo in input
Le rappresentazioni basate su temi e indicatori sono esempi di metodi basati sulla rappresentazione. Per capire gli argomenti menzionati nel testo, la rappresentazione basata su temi converte il testo in una rappresentazione intermedia.
Puntamento delle frasi in base alla rappresentazione
All’epoca della generazione della rappresentazione intermedia, ogni frase viene assegnato un punteggio di rilevanza. Quando si utilizza un metodo che dipende dalla rappresentazione basata su temi, il punteggio di una frase riflette l’efficacia con cui illustra i concetti chiave del testo. Nella rappresentazione basata su indicatori, il punteggio è calcolato aggregando le evidenze da indicatori differenti con pesi variabili.
Selezione di un riepilogo composto da più frasi
Per generare un riepilogo, il software per la riassunzione sceglie le migliori k frasi. Ad esempio, alcuni metodi usano algoritmi ottimizzatori per scegliere e selezionare quali frasi sono più rilevanti, mentre altri potrebbero trasformare la selezione delle frasi in un problema di ottimizzazione in cui viene selezionato un insieme di frasi sotto il pretesto che deve massimizzare l’importanza e la coerenza complessive mentre minimizza l’informazione ridondante.
Ora ci immergeremo più a fondo nei metodi che abbiamo citato:
Approcci di rappresentazione del tema
Parole del tema: Usando questo metodo, è possibile trovare termini relazionati al tema presenti nel documento di input. La rilevanza di una frase può essere calcolata in due modi: prima come una funzione del numero di firme del tema che include, secondariamente come una frazione delle firme del tema che contiene.
Mentre il primo metodo assegna punteggi più alti alle frasi più lunghe con più parole, il secondo misura la densità delle parole del tema.
Approccio guidato dalla frequenza: Attraverso questo metodo, le parole vengono assegnate una importanza relativa. Se il termine si adatta al topic, riceve 1 punto; altrimenti, raggiunge zero. A seconda di come vengono implementati, i pesi possono essere continui. Le rappresentazioni del topic possono essere ottenute utilizzando una delle due metodologie:
Probabilità delle Parole: Esso considera soltanto la frequenza di una parola per indicare la sua importanza. Per calcolare la probabilità di una parola w, dividiamo la sua frequenza di occorrenza, f(w), dalla somma totale delle parole, N.
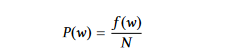
La media dell’importanza delle parole in una frase dà l’importanza della frase quando si utilizzano le probabilità delle parole.
TFIDF (Term Frequency Inverse Document Frequency): Questo metodo è un miglioramento rispetto alla probabilità delle parole. Qui, i pesi sono determinati utilizzando l’approcio TF-IDF. La tecnica Term Frequency Inverse Document Frequency (TFIDF) dà meno importanza ai termini che appaiono spesso in molti documenti. Il peso di ogni parola w nel documento d viene calcolato come segue:
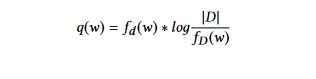
dove fd (w) è la frequenza del termine w nel documento d,
fD (w) è il numero di documenti che contengono la parola w, e |D| è il numero di documenti nella collezione D.
Analisi Semantica Latente: L’analisi semantica latente (LSA) è un metodo non supervisionato per estrarre una rappresentazione della semantica del testo in base alle parole osservate. Il processo dell’LSA inizia costruendo una matrice termine-frase (n per m), dove ogni riga rappresenta una parola dall’input (n-parole) e ogni colonna rappresenta una frase (m frasi). Nel matrice, il peso della parola i nella frase j è definito dalla entry aij. Secondo la tecnica TFIDF, ogni parola in una frase viene assegnato un certo peso, con zero che viene assegnato ai termini che non compaiono nella frase.
Approcci di rappresentazione indicatori
Metodi basati su grafi
I metodi grafici, influenzati dall’algoritmo PageRank, rappresentano i documenti come un grafo connesso. Le frasi formano i vertici del grafo, mentre le connessioni tra le frasi mostrano il grado di relazione tra due frasi l’una con l’altra. Uno dei metodi comunemente usati per collegare due vertici è valutare il grado di similitudine tra due frasi, e se il grado di similitudine è maggiore di una certa soglia, i vertici sono collegati. Entrambi i risultati sono possibili con questa rappresentazione grafica. Primo, le partizioni del grafo (sotto-grafi) definiscono Categorie individuali di informazione coperti dai documenti. Il secondo risultato è che le frasi chiave del documento sono state evidenziate. Le frasi collegate a molte altre frasi nella partizione sono probabilmente il centro del grafo e sono più probabili da includere nel riepilogo. Entrambi i Summarization di singolo documento e multi-documento possono trarre beneficio dall’uso di tecniche basate su grafi.
Machine Learning
Le tecniche di apprendimento automatico considerano il problema di riepilogo come una sfida di classificazione. I modelli cercano di classificare le frasi in categorie di riepilogo e non riepilogo in base ai loro特征. Abbiamo un set di addestramento costituito da documenti e riepiloghi estratti da essi e revisionati da esperti umani, da cui addestrare i nostri algoritmi. Di solito viene fatto usando Naive Bayes, Decision Tree o Support Vector Machine.
Riepilogo sintattico
Al contrario dell’estratto riassumendo, il riepilogo sintattico è un metodo più efficace. La capacità di creare frasi uniche che trasmettono informazioni chiave dai font testuali ha contribuito a questo incremento di popolarità.
Un riepilogatore sintattico presenta il materiale in una forma logica, ben organizzata e grammaticalmente corretta. La qualità di un riepilogo può essere significativamente migliorata rendendolo più leggibile o migliorando la sua qualità linguistica. (include immagine).
Ci sono due approcchi: quello basato sulla struttura e quello basato sulla semantica.
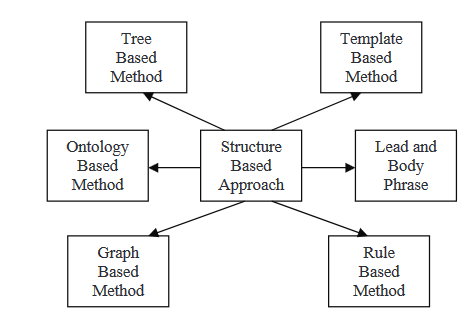
APPROCCIO BASATO SULLA STRUTTURA
In un approcio strutturato prima di tutto, le informazioni più importanti del documento (o documenti) sono codificate usando schemi di caratteristiche psicologiche come template, regole di estrazione e strutture alternative, comprese la struttura a albero, l’ontologia, la testa e il corpo, la regola e la struttura a grafo. Più avanti, leggeremo qualche metodo integrato in questa strategia.
Metodi basati su alberi
In questo metodo, il contenuto di un documento è rappresentato come un albero di dipendenze. La selezione del contenuto per un riepilogo può essere eseguita attraverso diverse tecniche, come un programma algoritmico di intersezione di argomenti o uno che utilizza l’allineamento naturale diretto attraverso le frasi parse. Questo approcio utilizza sia un generatore di linguaggio che un algoritmo associato per la generazione del riepilogo. In questo papiro, gli autori offrono un metodo di fusione di frasi che utilizza l’allineamento multiplo di sequenze locali in basso per trovare le frasi con informazione comune. I sistemi di sintesi multiplo di geni utilizzano una tecnica chiamata fusione di frasi.
In questo metodo, un insieme di documenti viene utilizzato come input, processato utilizzando un algoritmo di selezione dell’argomento per estrarre il tema centrale, e poi utilizzando un algoritmo di clustering per ordinare le frasi per importanza. Dopo aver disposto le frasi, vengono fuse utilizzando la fusione di frasi, e viene generato un riepilogo statistico. Il metodo strutturato codifica le informazioni più importanti dal documento utilizzando schemi mentali come modelli, regole di estrazione e strutture alternative come albero, ontologia, introduzione e corpo, regola e struttura a grafo.
Metodi basati su template
In questo metodo viene utilizzato un foglio di riferimento per rappresentare l’intero documento. I modelli linguistici o i criteri di estrazione vengono confrontati per identificare i pezzi di testo che possono essere mappati nelle schede del foglio di riferimento. questi pezzi di testo sono indicatori dell’area dell’indicatore del contenuto del riassunto. Questo papiro ha proposto due metodi (riassunto singolo e riassunto multiplo) per il riassunto del documento. Per creare estratti e riassunti da documenti, hanno seguito i metodi descritti in GISTEXTER.
Implementato per l’estrazione di informazioni, GISTEXTER è un sistema di riassunto che identifica informazioni relative al topic nel testo in input e le converte in voci di database; le frasi vengono poi aggiunte al riassunto in base alle richieste dell’utente.

Metodi basati sull’ontologia
Molti ricercatori hanno cercato di migliorare l’efficacia delle schede di riepilogo utilizzando l’ontologia (base di conoscenza). La maggior parte dei documenti in rete ha un dominio comune, cioè si occupano tutti dello stesso argomento generale. L’ontologia è una potente rappresentazione dell’unica struttura informativa unica di ciascun dominio.
Questo articolo propone l’uso dell’ontologia模糊, che modella l’incertezza e descrive accuratemente il sapere del dominio, per riepilogare le notizie cinesi. In questo metodo, gli esperti del dominio definiscono prima l’ontologia del dominio per gli eventi delle notizie, poi la fase di preparazione del documento estrae le parole semantiche dal corpus delle notizie e dal dizionario delle notizie cinesi.
Metodo delle frasi iniziali e centrali
Questo approcio coinvolge la riscrittura della frase iniziale attraverso operazioni su frasi con lo stesso blocco di testo con testo iniziale e centrale. Utilizzando l’analisi sintattica dei frammenti di frase, Tanaka ha suggerito una tecnica per riepilogare le notizie radio. I metodi di fusione delle frasi sono usati per inferire il concetto di base di questo approcio.
Riassumere le notizie in onda comporta la ricerca di frasi in comune tra il lead e i paragrafi del corpo, quindi inserirle e sostituirle per produrre un riassunto tramite la revisione di frasi. Prima di tutto, viene applicato un parser sintattico ai lead e ai paragrafi del corpo. Poi vengono identificate le coppie di ricerca trigger, e infine le frasi vengono allineate utilizzando diversi criteri di similitudine e allineamento. L’ultima fase può essere sia un’inserzione che una sostituzione o entrambe.
Il processo di inserzione comporta la scelta di un punto di inserzione, il controllo dell’eccesso di informazioni e il controllo del discorso per garantire coerenza e eliminare l’eccesso di informazioni. Il passo di sostituzione fornisce informazioni aggiuntive sostituendo la frase del corpo nel lead.
Metodo basato su regole
In questa tecnica, i documenti da riassumere sono descritti in termini di classi e di elenchi di aspetti. Il modulo di scelta del contenuto seleziona il candidato più efficace tra quelli generati dalle regole di estrazione dati per rispondere ad uno o a molti aspetti di una categoria. Infine, vengono usati i modelli di generazione per la generazione di frasi di outline.
Per identificare sostantivi e verbi semanticamente correlati, Pierre-Etienne et al. hanno proposto una serie di criteri per l’estrazione dell’informazione. Una volta estratti, i dati vengono inviati al passo di selezione del contenuto, che cerca di filtrare i candidati mix. Viene utilizzato per la struttura della frase e per le parole in un modello di generazione diretto. Dopo la generazione, viene eseguita la sintesi guidata dal contenuto.
Metodi basati su grafi
Molti ricercatori utilizzano una struttura dati a grafo per rappresentare documenti linguistici. I grafi sono una scelta popolare per rappresentare i documenti nella comunità di studio linguistica. Ognuno dei nodi nel sistema rappresenta una unità lessicale, insieme alle edge direzionate, che definiscono la struttura di una frase. Per migliorare le prestazioni dell’estratto Dingding Wang et al. hanno proposto sistemi di estratto multi-documento che utilizzano una vasta gamma di strategie, come il metodo basato sul centroide, il metodo basato sul grafo, ecc., per valutare varie combinazioni di metodi di base, come la media punteggio, la media posizione, il conteggio borda, l’aggregazione mediana, ecc. È stata sviluppata una metodologia di consenso pesata unica per raccogliere i risultati di differenti strategie di estratto. In un approcio basato sulla semantica, un’illustrazione linguistica di un documento o di documenti è utilizzata per alimentare un sistema di generazione della lingua naturale (NLG). Questa tecnica si specializza nel identificare i nomi di proposito e i verbi di proposito attraverso i dati linguistici.
APPROCCIO BASATO SULLA SEMANTICA
Approcci basati sulla semantica utilizzano l’illustrazione linguistica di un documento per alimentare un sistema di generazione naturale della lingua (NLG). Questo metodo processa i dati linguistici per l’identificazione di frasi nominali e frasi verbali.
- Modello semantico multimodale: In questo metodo, viene creato un modello linguistico che cattura concetti e relazioni tra idee per descrivere il contenuto di documenti multimodali come testo e immagini. Le idee chiave sono valutate utilizzando diversi criteri, e i concetti selezionati vengono quindi espressi come frasi per formare un riepilogo.
- Metodo basato su elementi informativi: In questo approcio, invece di usare frasi dai documenti di input, viene utilizzata una rappresentazione astratta di questi documenti per generare il contenuto del riepilogo. L’illustrazione astratta è un elemento informativo, la parte più piccola di informazione coerente in un testo.
- Modello Grafo Semantico: Questa tecnica si propone di riepilogare un documento costruendo un grafo semantico ricco (RSG) per il documento iniziale, quindi riducendo il grafo linguistico creato e generando l’ outline estratto dal grafo linguistico ridotto.
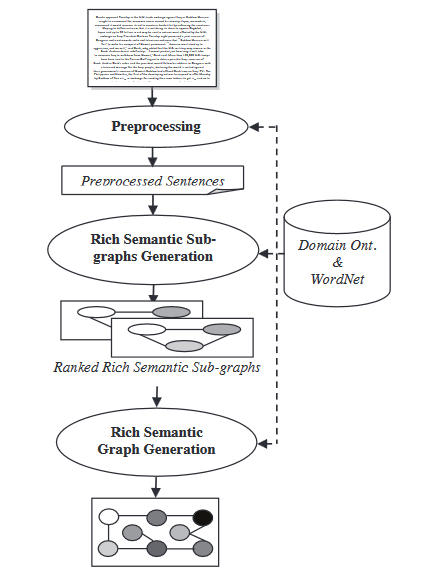
Durante il modulo di generazione del grafo semantico ricco, viene applicato un insieme di regoleuristiche al grafo semantico ricco generato per ridurnlo tramite la fusione, l’eliminazione o la consolidazione dei nodi del grafo.
- Modello rappresentazione testuale semantica: Questa tecnica analizza il testo in input utilizzando la semantica delle parole invece della sintassi/struttura del testo.
Casi di studio in ambito commerciale
- Programmazione del linguaggio informatico: Sono state fatte numerose attività per sviluppare tecnologie AI in grado di scrivere autonomamente codice e sviluppare siti web. Nel futuro, i programmatori potrebbero affidarsi a “riconciliatori di codice” specializzati per estrarre le informazioni fondamentali da progetti nuovi.
- Aiutare le persone con disabilità fisiche: Le persone con problemi alla vista potrebbero scoprire che la riassunzione li aiuta a seguire meglio il contenuto grazie all’avanzamento della tecnologia vocale-testo.
- Conferenze e altri meeting video: Con l’espansione del lavoro a distanza, è sempre più richiesta la capacità di registrare idee e contenuti chiave dalle interazioni. Sarebbe fantastico se i tuoi sessi di team potessero essere riassunti usando un metodo vocale-testo.
- La ricerca di brevetti: Trovare informazioni relative ai brevetti può essere tempo-consumante. Un generatore di riassunti di brevetto potrebbe risparmiarti tempo sia se state facendo ricerche di mercato che quando state preparando a registrare un nuovo brevetto.
- Libri e letteratura: I riassunti sono utili perché forniscono ai lettori un’overview concisa del contenuto che potrebbero aspettarsi da un libro prima di decidere se acquistarlo.
- Publicità sui social media: Le organizzazioni che creano white paper, e-book e blog aziendali potrebbero usare la riassunzione per renderli più digeribili e condivisibili su piattaforme come Twitter e Facebook.
- Ricerca economica: L’industria dell’investment banking investe ingenti somme di denaro nell’acquisizione di dati per usarli nelle decisioni, come nel trading automatico di azioni. Qualsiasi analista finanziario che passa tutto il giorno a scrutare i dati di mercato e le notizie arriverà eventualmente all’sovraccarico di informazioni. Documenti finanziari, come i resoconti delle entrate e le notizie finanziarie, potrebbero trarre beneficio da sistemi di riepilogo che consentano agli analisti di estrarre i segnali di mercato dal contenuto rapidamente.
- Promuovere il tuo business usando la motorizzazione per motori di ricerca: Le valutazioni di motorizzazione per motori di ricerca (SEO) richiedono una profonda familiarità con i topic trattati nel contenuto dei concorrenti. È d’importanza primaria considerando le recenti modifiche all’algoritmo di Google e l’enfasi successiva sull’autorità del soggetto. La capacità di riepilogare rapidamente diversi documenti, identificare corrispondenze, e cercare informazioni cruciali può essere uno strumento di ricerca potente.
Conclusione
Anche se l’estrazione sintetica è meno affidabile rispetto agli approcchi estrattivi, offre un promettente futuro per la produzione di riepiloghi che si allineano con il modo in cui le persone li scriverebbero. Pertanto, è probabile che emergano una serie di tecniche computazionali, cognitive e linguistiche nuove in questo settore.
Riferimenti
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques