













Se hai creato un Azure DevOps Pipeline come soluzione per un pipeline CI/CD, sicuramente ti sei imbattuto in situazioni che richiedono la gestione dinamica dei valori di configurazione in build e release. Che si tratti di fornire una versione di build a uno script PowerShell, passare parametri dinamici ai task di build o utilizzare stringhe in build e release, hai bisogno di variabili.
Se ti sei mai chiesto:
- Come posso utilizzare le variabili di Azure DevOps build Pipeline in uno script PowerShell?
- Come posso condividere variabili tra build e release?
- In cosa differiscono le variabili predefinite, definite dall’utente e segrete?
- Come funzionano i gruppi di variabili?
…allora sei fortunato! In questo articolo risponderemo a ciascuna di queste domande e altre ancora.
Alla fine di questo articolo, comprenderai come funzionano le variabili di build di Azure DevOps in Azure Pipelines!
Cosa sono le variabili di Azure DevOps Pipeline?
Prima di approfondire i dettagli delle variabili, cosa sono e come ti aiutano a creare e automatizzare pipeline di build e release efficienti?
Le variabili ti permettono di passare dati in varie parti delle tue pipeline. Le variabili sono ottime per memorizzare testo e numeri che possono cambiare all’interno del flusso di lavoro di una pipeline. In una pipeline, puoi impostare e leggere variabili quasi ovunque anziché codificare i valori negli script e nelle definizioni YAML.
Nota: questo articolo si concentrerà solo sulle pipeline YAML. Non verrà coperta alcuna informazione sulle pipeline classiche legacy. Inoltre, ad eccezione di alcune piccole eccezioni, non imparerai come lavorare con le variabili tramite l’interfaccia utente web. Ci atteniamo strettamente a YAML.
Le variabili vengono referenziate e alcune definite (vedi variabili definite dall’utente) durante l’esecuzione. Quando una pipeline avvia un job, vari processi gestiscono queste variabili e passano i loro valori ad altre parti del sistema. Questo sistema offre un modo per eseguire dinamicamente i job della pipeline senza preoccuparsi di modificare le definizioni di build e gli script ogni volta.
Non preoccuparti se non comprendi il concetto di variabili in questo momento. Il resto di questo articolo ti insegnerà tutto ciò che devi sapere.
Ambienti delle variabili
Prima di entrare nel dettaglio delle variabili stesse, è importante comprendere i “variabili environment” delle pipeline di Azure. Vedrai varie referenze a questo termine nell’articolo.
All’interno di una pipeline, ci sono due luoghi chiamati informalmene ambienti in cui puoi interagire con le variabili. Puoi lavorare con le variabili all’interno di una definizione di build YAML chiamata ambiente pipeline o all’interno di uno script eseguito tramite un task chiamato ambiente script.
L’ambiente di pipeline
Quando si definiscono o leggono le variabili di compilazione all’interno di una definizione YAML di compilazione, ciò viene chiamato ambiente di pipeline. Ad esempio, di seguito è possibile vedere la sezione variabili definita in una definizione YAML di compilazione che imposta una variabile chiamata foo su bar. In questo contesto, la variabile viene definita all’interno dell’ambiente di pipeline
L’ambiente di script
È anche possibile lavorare con le variabili all’interno del codice definito nella stessa definizione YAML o negli script. Quando non si dispone di uno script esistente già creato, è possibile definire e leggere le variabili all’interno della definizione YAML come mostrato di seguito. Imparerai la sintassi su come lavorare con queste variabili in questo contesto più avanti.
È anche possibile rimanere nell’ambiente di script aggiungendo questa stessa sintassi a uno script Bash ed eseguendolo. È lo stesso concetto generale.
Variabili di ambiente
All’interno dell’ambiente di script, quando una variabile di pipeline viene resa disponibile, viene creata una variabile di ambiente. Queste variabili di ambiente possono quindi essere accessibili tramite i metodi tipici del linguaggio di scelta.
Le variabili di pipeline esposte come variabili di ambiente saranno sempre in maiuscolo e i punti sostituiti con underscore. Ad esempio, si vedrà di seguito come ogni linguaggio di scripting può accedere alla variabile di pipeline foo come mostrato di seguito.
- Batch –
%FOO% - PowerShell –
$env:FOO - Script Bash –
$FOO
Pipeline “Fasi di Esecuzione”
Quando una pipeline “viene eseguita”, non si limita a “correre”. Come le fasi che contiene, anche una pipeline attraversa diverse fasi quando viene eseguita. A causa della mancanza di un termine ufficiale nella documentazione Microsoft, chiamo questo “fasi di esecuzione”.
Quando viene attivata una pipeline, passa attraverso tre fasi approssimative – Coda, Compilazione e Esecuzione. È importante capire questi contesti perché se stai navigando nella documentazione Microsoft, vedrai riferimenti a questi termini.
Tempo di Coda
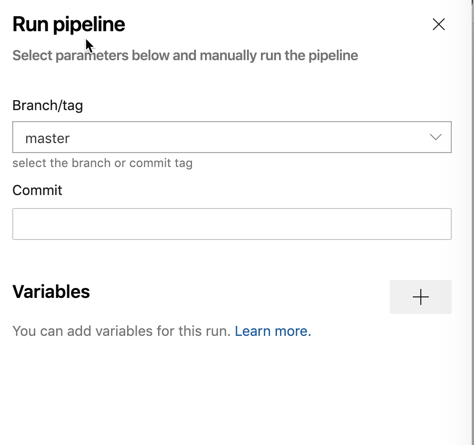
La prima fase che una pipeline attraversa quando viene attivata è la coda. In questa fase, la pipeline non è ancora iniziata ma è in coda e pronta ad andare quando l’agente è disponibile. Quando si definiscono variabili, è possibile impostarle per essere rese disponibili al momento della messa in coda non definendole nel file YAML.
Sarai in grado di definire le variabili al momento della messa in coda quando la pipeline viene inizialmente messa in coda come mostrato di seguito. Quando questa variabile viene aggiunta, verrà quindi resa disponibile come variabile globale nella pipeline e può essere sovrascritta dalla stessa variabile nome nel file YAML.
Compilazione
Infine, quando un pipeline elabora un file YAML e arriva alle fasi che richiedono l’esecuzione di script, la pipeline si trova nella “fase di compilazione”. In questo contesto, l’agente esegue il codice definito nei passaggi dello script.
Esecuzione
La fase successiva è l’esecuzione. Questa è la fase in cui il file YAML viene elaborato. Durante questa fase, ogni stage, job e passaggio vengono elaborati ma non eseguono alcuno script.
Espansione delle Variabili
Un altro argomento importante da capire è l’espansione delle variabili. L’espansione delle variabili, in termini semplici, avviene quando la variabile restituisce un valore statico. La variabile si espande per rivelare il valore che contiene. Questo avviene automaticamente quando si legge una variabile, ma questa espansione può avvenire in momenti diversi durante l’esecuzione di una pipeline e potrebbe creare confusione.
Questo concetto di espansione delle variabili e compilazione vs. esecuzione verrà affrontato molto spesso quando si imparerà la sintassi delle variabili.
Come hai imparato in precedenza, la pipeline copre diverse “fasi” durante l’esecuzione. Dovrai essere consapevole di queste fasi, molto probabilmente, quando risolvi problemi di espansione delle variabili.
Puoi vedere un esempio qui sotto. Il concetto di queste “fasi” è strettamente legato agli ambienti delle variabili.
Le variabili vengono espandute una volta quando viene avviata l’esecuzione della pipeline e di nuovo, all’inizio di ogni passaggio. Di seguito puoi vedere un esempio semplice di questo comportamento.
Sintassi delle variabili
Come hai imparato, puoi impostare o leggere variabili in due “ambienti” – l’ambiente della pipeline e l’ambiente dello script. Mentre sei in ogni ambiente, il modo in cui fai riferimento alle variabili è leggermente diverso. Ci sono alcune sfumature che dovrai tenere d’occhio.
Variabili di pipeline
Le variabili di pipeline vengono citate nelle definizioni della pipeline YAML e possono essere citate tramite tre diversi metodi di sintassi: macro, espressione di modello ed espressione di runtime.
Sintassi macro
La sintassi più comune che troverai è la sintassi delle macro. La sintassi delle macro fa riferimento a un valore per una variabile nella forma di $(foo). Le parentesi rappresentano un’espressione che viene valutata al runtime.
Quando Azure Pipelines elabora una variabile definita come un’espressione di macro, sostituirà l’espressione con il contenuto della variabile. Quando si definiscono variabili con la sintassi delle macro, seguono il pattern <nome variabile>: $(<valore variabile>) ad esempio foo: $(bar).
Se si tenta di fare riferimento a una variabile con la sintassi delle macro e un valore non esiste, la variabile semplicemente non esisterà. Questo comportamento differisce un po ‘tra i tipi di sintassi.
Sintassi dell’espressione del modello
Un’altra tipologia di sintassi per le variabili è chiamata espressione di template. La definizione delle variabili del flusso di lavoro in questo modo ha la forma di ${{ variables.foo }} : ${{ variables.bar }}. Come puoi vedere, è un po’ più lunga rispetto alla sintassi delle macro.
La sintassi delle espressioni di template ha anche una caratteristica aggiuntiva. Utilizzando questa sintassi, puoi anche espandere parametri di template. Se una variabile definita con la sintassi delle espressioni di template viene referenziata, il flusso di lavoro restituirà una stringa vuota invece di un valore nullo come avviene con la sintassi delle macro.
Le variabili definite con la sintassi delle espressioni di template vengono elaborate durante la compilazione e sovrascritte (se definite) durante l’esecuzione.
Sintassi delle Espressioni in Esecuzione
Come tipo di sintassi suggerito, le variabili di espressione in esecuzione vengono espandete solo durante l’esecuzione. Questo tipo di variabili è rappresentato nel formato $[variables.foo]. Come le variabili della sintassi delle espressioni di template, anche queste variabili restituiranno una stringa vuota se non vengono sostituite.
Come la sintassi delle macro, la sintassi delle espressioni in esecuzione richiede il nome della variabile sul lato sinistro della definizione, ad esempio foo: $[variables.bar].
Variabili di Script
Lavorare con le variabili all’interno degli script è leggermente diverso rispetto alle variabili del flusso di lavoro. La definizione e il riferimento delle variabili del flusso di lavoro esposte negli script delle attività possono essere fatti in due modi: utilizzando la sintassi del comando di registrazione o le variabili d’ambiente.
Comandi di registrazione
Un modo per definire e fare riferimento alle variabili del pipeline negli script è utilizzare la sintassi dei comandi di registrazione. Questa sintassi è un po’ complicata ma imparerai che è necessaria in determinate situazioni. Le variabili definite in questo modo devono essere definite come stringhe nello script.
Per impostare una variabile chiamata foo con un valore di bar utilizzando la sintassi del comando di registrazione, l’aspetto sarebbe il seguente:
I could not find a way to get the value of variables using logging commands. If this exists, let me know!
Variabili di ambiente
Quando le variabili del pipeline vengono convertite in variabili di ambiente negli script, i nomi delle variabili vengono leggermente modificati. Noterai che i nomi delle variabili diventano maiuscoli e i punti si trasformano in trattini bassi. Molte variabili predefinite o di sistema contengono punti.
Ad esempio, se fosse stata definita una variabile del pipeline chiamata [foo.bar](<http://foo.bar>), fare riferimento a tale variabile tramite il metodo di riferimento delle variabili di ambiente nativo dello script, come $env:FOO_BAR in PowerShell o $FOO_BAR in Bash.
Abbiamo trattato ulteriori informazioni sulle variabili di ambiente nella sezione Ambiente di script sopra.
Ambito delle variabili
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
In sostanza, ci sono tre diversi ambiti delle variabili in una gerarchia. Le variabili vengono definite a:
- livello radice, rendendo le variabili disponibili per tutti i lavori nel pipeline
- livello dello stage, rendendo le variabili disponibili per uno stage specifico
- livello del lavoro, rendendo le variabili disponibili per un lavoro specifico
Le variabili definite ai livelli “inferiori”, come un lavoro, sovrascriveranno le stesse variabili definite ai livelli stage e root, ad esempio. Le variabili definite al livello stage sovrascriveranno le variabili definite al livello “root”, ma saranno a loro volta sovrascritte dalle variabili definite al livello job.
Di seguito puoi vedere un esempio di definizione di compilazione YAML in cui viene utilizzato ogni ambito.
Precedenza delle variabili
A volte potresti trovarsi in una situazione in cui una variabile con lo stesso nome viene impostata in vari ambiti. Quando ciò accade, il valore di quella variabile verrà sovrascritto secondo una sequenza specifica che dà la precedenza all'”azione” più vicina.
Di seguito vedrai l’ordine in cui le variabili verranno sovrascritte a partire da una variabile impostata all’interno di un job. Questa avrà la massima precedenza.
- Variabile impostata al livello job (impostata nel file YAML)
- Variabile impostata al livello stage (impostata nel file YAML)
- Variabile impostata al livello pipeline (globale) (impostata nel file YAML)
- Variabile impostata al momento della coda
- Variabile di pipeline impostata nell’interfaccia delle impostazioni di pipeline
Ad esempio, prendi in considerazione la definizione YAML di seguito. In questo esempio, la stessa variabile viene impostata in molte aree diverse ma alla fine finisce con il valore definito nel lavoro. Con ogni azione, il valore della variabile viene sovrascritto fino a quando il flusso di lavoro arriva al lavoro.
Tipi di variabili
Hai imparato cosa sono le variabili, come si presentano, i contesti in cui possono essere eseguite e altro ancora fino ad ora in questo articolo. Ma ciò che non abbiamo ancora trattato è che non tutte le variabili sono uguali. Alcune variabili esistono già quando un flusso di lavoro inizia e non possono essere modificate, mentre altre puoi crearle, modificarle ed eliminarle a tuo piacimento.
Ci sono quattro tipi generali di variabili: variabili predefinite o di sistema, variabili definite dall’utente, variabili di output e variabili segrete. Vediamo ora ognuno di questi tipi di variabili.
Variabili predefinite
All’interno di tutte le build e le release, troverai molte variabili diverse che esistono per impostazione predefinita. Queste variabili vengono chiamate variabili predefinite o di sistema. Le variabili predefinite sono tutte in sola lettura e, come gli altri tipi di variabili, rappresentano semplici stringhe e numeri.
Una pipeline di Azure è composta da molti componenti, dall’agente software che esegue la build, ai lavori che vengono avviati quando viene eseguito un rilascio, e altre informazioni varie. Per rappresentare tutte queste aree, le variabili predefinite o di sistema vengono informalmente suddivise in cinque categorie distinte:
- Agente
- Build
- Pipeline
- Lavoro di distribuzione
- Sistema
Ci sono decine di variabili distribuite in ciascuna di queste cinque categorie. Non le imparerai tutte in questo articolo. Se desideri un elenco di tutte le variabili predefinite, dai un’occhiata alla documentazione di Microsoft.
Variabili definite dall’utente
Quando crei una variabile in una definizione YAML o tramite uno script, stai creando una variabile definita dall’utente. Le variabili definite dall’utente sono semplicemente tutte le variabili che tu, l’utente, definisci e usi in un flusso di lavoro. Puoi utilizzare praticamente qualsiasi nome desideri per queste variabili con alcune eccezioni.
Non puoi definire variabili che iniziano con la parola endpoint, input, secret o securefile. Queste etichette sono off-limits perché sono riservate per l’uso di sistema e sono case-insensitive.
Inoltre, qualsiasi variabile che definisci deve essere composta solo da lettere, numeri, punti o caratteri di sottolineatura. Se provi a definire una variabile che non segue questo formato, la definizione della build YAML non funzionerà.
Variabili di output
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
Le variabili di output vengono utilizzate per condividere informazioni tra i componenti del flusso di lavoro. Ad esempio, se un’attività richiede un valore da un database e le attività successive hanno bisogno del risultato restituito, è possibile utilizzare una variabile di output. In questo modo, non è necessario interrogare il database ogni volta. Invece, è possibile fare riferimento alla variabile.
Nota: le variabili di output sono limitate a uno specifico stage. Non aspettarti che una variabile di output sia disponibile sia nello stage “build” che nello stage “testing”, ad esempio.
Variabili Segrete
Il tipo finale di variabile è la variabile segreta. Tecnicamente, questa non è un tipo indipendente perché può essere una variabile di sistema o definita dall’utente. Ma le variabili segrete devono essere categorizzate a parte perché vengono trattate in modo diverso rispetto alle altre variabili.
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– NON definire variabili segrete all’interno dei file YAML
– NON restituire segreti come variabili di output o informazioni di registrazione
Le variabili segrete dovrebbero essere definite nell’editor della pipeline. Questo limita le variabili segrete a livello globale, rendendole disponibili per le attività nella pipeline.
I valori segreti sono mascherati nei registri ma non completamente. Questo è il motivo per cui è importante non includerli in un file YAML. Dovresti anche sapere di non includere dati “strutturati” come segreti. Ad esempio, se viene impostato { "foo": "bar" } come segreto, bar non sarà mascherato dai registri.
Le segrete non vengono automaticamente decriptate e mappate in variabili d’ambiente. Se si definisce una variabile segreta, non aspettarsi che sia disponibile tramite
$env:FOOin uno script di PowerShell, ad esempio.
Gruppi di Variabili
Infine, arriviamo ai gruppi di variabili. I gruppi di variabili, come ci si potrebbe aspettare, sono “gruppi” di variabili che possono essere referenziate come una sola. Lo scopo principale di un gruppo di variabili è quello di memorizzare valori che si desidera rendere disponibili su più pipeline.
A differenza delle variabili, i gruppi di variabili non vengono definiti nel file YAML. Invece, vengono definiti nella pagina Libreria sotto Pipelines nell’interfaccia utente.
Utilizza un gruppo di variabili per memorizzare valori che desideri controllare e rendere disponibili in più pipeline. Puoi anche utilizzare i gruppi di variabili per memorizzare segreti e altri valori che potrebbero essere necessari per passare a una pipeline YAML. I gruppi di variabili vengono definiti e gestiti nella pagina Libreria sotto Pipelines come mostrato di seguito.
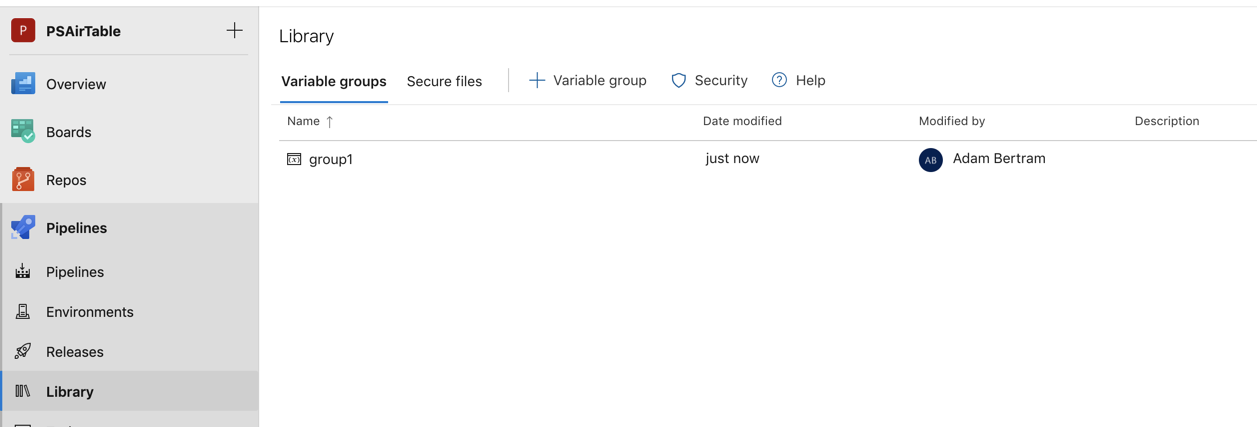
Una volta definito nella libreria di pipeline, puoi quindi accedere a quel gruppo di variabili nel file YAML utilizzando la sintassi di seguito.
I gruppi di variabili non sono disponibili, per impostazione predefinita, per tutte le pipeline. Questa impostazione viene resa disponibile durante la creazione del gruppo. Le pipeline devono essere autorizzate a utilizzare un gruppo di variabili.
Una volta che un gruppo di variabili è accessibile nel file YAML, puoi quindi accedere alle variabili all’interno del gruppo esattamente come faresti con qualsiasi altra variabile. Il nome del gruppo di variabili non viene utilizzato quando si fa riferimento alle variabili nel gruppo.
Ad esempio, se hai definito un gruppo di variabili chiamato group1 con una variabile chiamata foo al suo interno, puoi fare riferimento alla variabile foo come qualsiasi altra, ad esempio $(foo).
Le variabili segrete definite in un gruppo di variabili non possono essere accessibili direttamente tramite script. Invece, devono essere passate come argomenti al task.
Se viene apportata una modifica a una variabile all’interno di un gruppo di variabili, tale modifica sarà automaticamente disponibile per tutte le pipeline autorizzate a utilizzare quel gruppo.
Sommario
Dovresti ora avere una solida conoscenza delle variabili di Azure Pipelines. Hai imparato praticamente tutti i concetti relativi alle variabili in questo articolo! Ora metti in pratica questa conoscenza nelle tue Azure DevOps Pipelines e automatizza tutto ciò che puoi!
Source:
https://adamtheautomator.com/azure-devops-variables/