













Introduzione
In questo articolo, creeriamo una delle prime reti neurali convoluzionali mai introdotte, la LeNet5. Costruiamo questa CNN da zero in PyTorch e vedremo come funziona su un dataset reale.
Inizieremo esplorando l’architettura di LeNet5. Poi caricheremo e analizzeremo il nostro dataset, MNIST, utilizzando la classe fornita da torchvision. Utilizzando PyTorch, costruiremo la nostra LeNet5 da zero e la addestreremo sul nostro dataset. Infine, vedremo come il modello si comporta sui dati di test non visti.
Prerequisiti
La conoscenza delle reti neurali sarà utile per capire questo articolo. Questo significa essere familiarizzati con le diverse layer delle reti neurali (layer di input, layer nascosti, layer di output), le funzioni di attivazione, gli algoritmi di ottimizzazione (varie varianti del discendimento del gradiente), le funzioni di perdita, ecc. Inoltre, la familiarità con la sintassi di Python e la libreria PyTorch è essenziale per capire i fragmenti di codice presenti in questo articolo.
Un’introduzione alle CNN è anche raccomandata. Questo include il possesso di conoscenze riguardanti le layer convoluzionali, le layer di pooling e il loro ruolo nell’estrazione di caratteristiche dai dati di input. La comprensione di concetti come la stride, il padding e l’impatto della dimensione del kernel/filtro è benefico.
LeNet5
LeNet5 è stato utilizzato per la riconoscenza di caratteri scritti a mano ed è stato proposto da Yann LeCun e altri nel 1998 con il documento,Gradient-Based Learning Applied to Document Recognition.
Consentiamo di comprendere l’architettura di LeNet5 come mostrato nella figura sottostante:
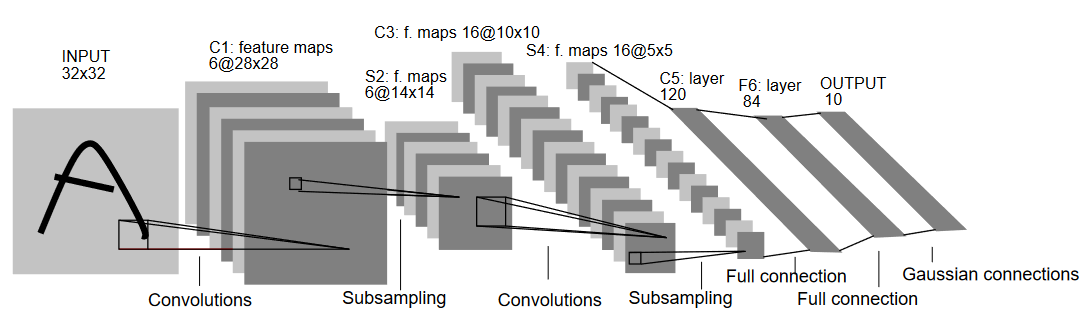
Come suggerisce il nome, LeNet5 ha 5 layer, due convoluzionali e tre completamente connessi. Iniziamo dall’input. LeNet5 accetta come input un’immagine in scala di grigio di 32×32, indicando che l’architettura non è adatta alle immagini RGB (multiple channels). Quindi l’immagine di input dovrebbe contenere solo un canale. Dopo questo, iniziamo con le nostre layer convoluzionali
La prima layer convoluzionale ha una dimensione del filtro di 5×5 con 6 filtri simili. Questo riduce la larghezza e l’altezza dell’immagine mentre aumenta la profondità (numero di canali). L’output sarà 28x28x6. Dopo questo, si applica il pooling per dividire il mapping delle caratteristiche per metà, cioè 14x14x6. Lo stesso filtro di dimensione (5×5) con 16 filtri è ora applicato all’output seguito da una layer di pooling. Questo riduce il mapping delle caratteristiche di output a 5x5x16.
Dopo questo, viene applicata una layer convoluzionale da 5×5 con 120 filtri per raddrizzare la mappa delle caratteristiche in 120 valori. Segue la prima layer completamente connessa, con 84 neuroni. Infine, abbiamo la layer di output che ha 10 neuroni di output, poiché i dati MNIST hanno 10 classi per ciascuno degli 10 numeri cifrario rappresentati.
Caricamento dati
Cominciamo caricando e analizzando i dati. Utilizzeremo il dataset MNIST. Il dataset MNIST contiene immagini di cifre numeriche scritte a mano. Le immagini sono in scala grigia, tutte di dimensione 28×28 e composta da 60.000 immagini di addestramento e 10.000 immagini di test.
Potete vedere alcuni esempi di immagini qui sotto:

Importazione delle Librerie
Cominciamo importando le librerie necessarie e definendo alcune variabili (i parametri hyperparameters e la device sono anche dettagliati per aiutare il pacchetto a determinare se allenare su GPU o CPU):
# Carica le librerie relative e dai alias se appropriato
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Defini le variabili relative per il compito di ML
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# La device determinera se eseguire l'addestramento su GPU o CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Caricamento e Trasformazione dei Dati
Usando torchvision, caricheremo il dataset in quanto ci permetterà di eseguire facilmente qualunque passo di pre-elaborazione.
#Caricamento del dataset e preelaborazione
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
Ora spiegheremo il codice:
- Prima di tutto, i dati MNIST non possono essere utilizzati così com’è per l’architettura LeNet5. L’architettura LeNet5 accetta l’input come se fosse univoco da 32×32, mentre le immagini MNIST sono invece 28×28. Possiamo risolvere questo problema reindirizzando le immagini, normalizzandole utilizzando la media e la deviazione standard pre-calcolate (disponibili online) e infine memorizzandole come tensori.
- Impostiamo
download=Truenel caso i dati non siano già stati scaricati. - Successivamente, facciamo uso di loader di dati. Questo potrebbe non influenzare il rendimento del dataset MNIST piccolo, ma può davvero ostacolare il rendimento dei dataset grandi e viene considerato di solito una buona pratica. I loader di dati ci consentono di iterare sui dati in batch, e i dati vengono caricati durante l’iterazione e non tutti insieme all’inizio.
- Specifichiamo la dimensione del batch e impostiamo a mescolare il dataset durante il caricamento in modo da avere varianza nella tipologia delle etichette nei vari batch. Questo aumenterà l’efficacia del nostro modello finale.
LeNet5 da zero
Iniziamo prima ad osservare il codice:
#Definizione della rete convoluzionale
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
Definizione del modello LeNet5
Spiegherò il codice in modo lineare:
- In PyTorch, definiamo una rete neurale creando una classe che eredita da
nn.Modulepoiché contiene molti metodi che utilizzeremo. - Dopo questo, ci sono due passaggi principali. Il primo è l’inizializzazione delle layer che useranno nella nostra CNN all’interno di
__init__, e l’altro è la definizione della sequenza in cui queste layer processeranno l’immagine. Questo è definito nella funzioneforward. - Per l’architettura stessa, prima definiamo le layer convoluzionali usando la funzione
nn.Conv2Dcon la dimensione del kernel e i canali di input/output corretti. Appliciamo anche il pooling massimo usando la funzionenn.MaxPool2D. Una cosa interessante su PyTorch è che possiamo combinare la layer convoluzionale, la funzione di attivazione e il pooling massimo in una singola layer (verranno applicati separatamente, ma aiuta con l’organizzazione) usando la funzionenn.Sequential. - Definiamo quindi le layer completamente connessi. Notate che possiamo usare anche
nn.Sequentialqui e combinare le funzioni di attivazione e le layer lineari, ma volevo mostrare che sia una possibilità. - Alla fine, l’ultimo layer produce 10 neuroni che sono le nostre predizioni finali per i numeri.
Impostazione degli iperparametri
Prima dell’allenamento, dobbiamo impostare alcuni iperparametri, come la funzione di perdita e l’ottimizzatore da utilizzare.
model = LeNet5(num_classes).to(device)
#Impostazione della funzione di perdita
cost = nn.CrossEntropyLoss()
#Impostazione dell'ottimizzatore con i parametri del modello e la velocità di apprendimento
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#questo è definito per stampare quanti passi mancano durante l'allenamento
total_step = len(train_loader)
Cominciamo inizializzando il nostro modello usando il numero di classi come argomento, che in questo caso è 10. Poi definiamo la nostra funzione di costo come la perdita di entropia incrociata e l’ottimizzatore come Adam. Esistono molte scelte per questi, ma tendono a dare buoni risultati con il modello e i dati dati. Infine, definiamo total_step per tenere meglio traccia dei passi durante l’allenamento.
Allenamento del modello
Ora, possiamo allenare il nostro modello:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#Passaggio in avanti
outputs = model(images)
loss = cost(outputs, labels)
#Retrocesso e ottimizzazione
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
Vediamo cosa fa il codice:
- Comenziamo iterando attraverso il numero di epoche, poi i batch nel nostro dataset di addestramento.
- Convertiamo le immagini e le etichette in base al dispositivo che stiamo utilizzando, cioè GPU o CPU.
- Nel passo in avanti, facciamo delle previsioni usando il nostro modello e calcoliamo la perdita in base a queste previsioni e alle nostre etichette reali.
- Successivamente, facciamo il passo indietro dove aggiorniamo realmente i nostri pesi per migliorare il nostro modello
- Impostiamo poi i gradienti a zero prima di ogni aggiornamento usando la funzione
optimizer.zero_grad(). - Calcoliamo poi i nuovi gradienti usando la funzione
loss.backward(). - E infine, aggiorniamo i pesi con la funzione
optimizer.step().
Possiamo vedere l’output come segue:
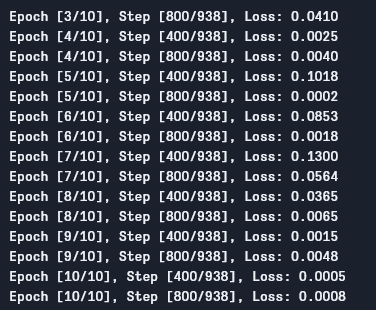
Come vediamo, la perdita si sta diminuendo con ogni epoca, il che dimostra che il nostro modello sta imparando. Notare che questa perdita è sul set di addestramento, e se la perdita è troppo piccola (come nel nostro caso), può indicare l’overfitting. Ci sono molti modi per risolvere questo problema, come la regolarizzazione, l’augmentazione dati, e così via, ma non ci occuperemo di questo in questo articolo. Ora testiamo il nostro modello per vedere come si comporta.
Test del Modello
Ora testiamo il nostro modello:
# Testa il modello
# In fase di test, non è necessario calcolare i gradienti (per ragioni di efficienza della memoria)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
Come potete vedere, il codice non è così diverso da quello utilizzato per l’addestramento. L’unica differenza è che non stiamo calcolando i gradienti (utilizzando with torch.no_grad()), e non stiamo calcolando la perdita perché non dobbiamo fare backpropagation qui. Per calcolare l’accuratezza finale del modello, possiamo semplicemente calcolare il numero totale di predizioni corrette su tutte le immagini totali.
Utilizzando questo modello, otteniamo un’accuratezza di circa il 98,8%, che è piuttosto buona:

Accuratezza del Test
Nota che il dataset MNIST è piuttosto semplice e piccolo secondo gli standard di oggi, e risultati simili sono difficili da ottenere per altri dataset. Comunque, è un buon punto di partenza quando si impara il deep learning e le CNN.
Conclusione
Ora concludiamo ciò che abbiamo fatto in questo articolo:
- Abbiamo iniziato imparando l’architettura di LeNet5 e i diversi tipi di layer in essa.
- Successivamente, abbiamo esplorato il dataset MNIST e caricato i dati utilizzando
torchvision. - Poi, abbiamo creato LeNet5 da zero insieme alle definizioni dei parametri del modello.
- Infine, abbiamo addestrato e testato il nostro modello sul dataset MNIST, e il modello sembrava essere performante sul set di test.
Lavoro futuro
Anche se questo sembra un ottimo approcio all’apprendimento profondo in PyTorch, è possibile estendere questo lavoro per imparare di più:
- Potete provare a utilizzare diversi dataset, ma per questo modello avrete bisogno di dataset a scala grezza. Uno di questi è FashionMNIST.
- Potete sperimentare con diversi hyperparameter e vedere la migliore combinazione di loro per il modello.
- Infine, potete provare ad aggiungere o rimuovere layer dal dataset per vedere il loro impatto sulla capacità del modello.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python