













Modulo Pandas di Python
- Pandas è una libreria open source in Python. Fornisce strutture dati ad alte prestazioni pronte all’uso e strumenti di analisi dei dati.
- Il modulo Pandas funziona sopra a NumPy ed è ampiamente utilizzato per la scienza dei dati e l’analisi dei dati.
- NumPy è una struttura dati di basso livello che supporta array multidimensionali e una vasta gamma di operazioni matematiche sugli array. Pandas ha un’interfaccia di livello superiore. Fornisce anche un allineamento ottimizzato dei dati tabellari e una potente funzionalità di serie temporali.
- DataFrame è la principale struttura dati in Pandas. Ci permette di memorizzare e manipolare dati tabellari come una struttura dati 2-D.
- Pandas fornisce un ricco set di funzionalità sul DataFrame. Ad esempio, allineamento dei dati, statistiche dei dati, slicing, raggruppamento, unione, concatenazione dei dati, ecc.
Installazione e Iniziare con Pandas
È necessario avere Python 2.7 o versioni successive per installare il modulo Pandas. Se si sta utilizzando conda, allora è possibile installarlo utilizzando il comando seguente.
conda install pandas
Se stai utilizzando il modulo PIP, esegui il seguente comando per installare il modulo pandas.
pip3.7 install pandas
Per importare Pandas e NumPy nel tuo script Python, aggiungi il seguente codice:
import pandas as pd
import numpy as np
Poiché Pandas dipende dalla libreria NumPy, dobbiamo importare questa dipendenza.
Strutture dati nel modulo Pandas
Il modulo Pandas fornisce 3 strutture dati, che sono le seguenti:
- Serie: È una struttura dati 1-D, di dimensione immutabile, simile ad un array con dati omogenei.
- DataFrames: È una struttura tabulare 2-D, di dimensione mutabile, con colonne di tipo eterogeneo.
- Panel: È un array 3-D, di dimensione mutabile.
DataFrame di Pandas
Il DataFrame è la struttura dati più importante e ampiamente utilizzata ed è un modo standard per memorizzare i dati. Il DataFrame ha i dati allineati in righe e colonne, simile ad una tabella SQL o un database di fogli di calcolo. Possiamo inserire i dati direttamente nel DataFrame oppure importare un file CSV, un file tsv, un file Excel, una tabella SQL, ecc. Possiamo utilizzare il seguente costruttore per creare un oggetto DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
Ecco una breve descrizione dei parametri:
- – crea un oggetto DataFrame dai dati in input. Può essere una lista, un dizionario, una serie, ndarrays Numpy o anche qualsiasi altro DataFrame.
- indice – ha le etichette di riga
- colonne – utilizzato per creare etichette di colonna
- dtype – utilizzato per specificare il tipo di dati di ciascuna colonna, parametro opzionale
- copia – utilizzato per copiare i dati, se presenti
Esistono molti modi per creare un DataFrame. Possiamo creare un oggetto DataFrame da dizionari o lista di dizionari. Possiamo anche crearlo da una lista di tuple, file CSV, Excel, ecc. Eseguiamo un semplice codice per creare un DataFrame dalla lista di dizionari.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Output:  Il primo passo è creare un dizionario. Il secondo passo è passare il dizionario come argomento nel metodo DataFrame(). Il passo finale è stampare il DataFrame. Come puoi vedere, il DataFrame può essere paragonato a una tabella con valori eterogenei. Inoltre, le dimensioni del DataFrame possono essere modificate. Abbiamo fornito i dati sotto forma di mappa e le chiavi della mappa sono considerate da Pandas come etichette di riga. L’indice è visualizzato nella colonna più a sinistra e ha le etichette di riga. L’intestazione della colonna e i dati sono visualizzati in forma tabellare. È anche possibile creare DataFrame indicizzati. Ciò può essere fatto configurando il parametro di indice nel metodo
Il primo passo è creare un dizionario. Il secondo passo è passare il dizionario come argomento nel metodo DataFrame(). Il passo finale è stampare il DataFrame. Come puoi vedere, il DataFrame può essere paragonato a una tabella con valori eterogenei. Inoltre, le dimensioni del DataFrame possono essere modificate. Abbiamo fornito i dati sotto forma di mappa e le chiavi della mappa sono considerate da Pandas come etichette di riga. L’indice è visualizzato nella colonna più a sinistra e ha le etichette di riga. L’intestazione della colonna e i dati sono visualizzati in forma tabellare. È anche possibile creare DataFrame indicizzati. Ciò può essere fatto configurando il parametro di indice nel metodo DataFrame().
Importazione dei dati da CSV a DataFrame
È anche possibile creare un DataFrame importando un file CSV. Un file CSV è un file di testo con un record di dati per riga. I valori all’interno del record sono separati usando il carattere “virgola”. Pandas fornisce un metodo utile, chiamato read_csv(), per leggere i contenuti del file CSV in un DataFrame. Ad esempio, possiamo creare un file chiamato ‘città.csv’ contenente dettagli delle città indiane. Il file CSV è memorizzato nella stessa directory che contiene gli script Python. Questo file può essere importato usando:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Il nostro obiettivo è caricare i dati e analizzarli per trarre conclusioni. Quindi, possiamo utilizzare qualsiasi metodo comodo per caricare i dati. In questo tutorial, stiamo codificando manualmente i dati del DataFrame.
Ispezione dei dati nel DataFrame
Eseguendo il DataFrame utilizzando il suo nome visualizzerà l’intera tabella. In tempo reale, i dataset da analizzare avranno migliaia di righe. Per analizzare i dati, è necessario ispezionare dati provenienti da enormi volumi di dataset. Pandas fornisce molte funzioni utili per ispezionare solo i dati di cui abbiamo bisogno. Possiamo utilizzare `df.head(n)` per ottenere le prime n righe o `df.tail(n)` per stampare le ultime n righe. Ad esempio, il codice sottostante stampa le prime 2 righe e l’ultima riga dal DataFrame.
print(df.head(2))
Output: 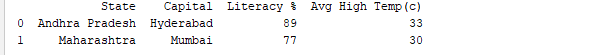
print(df.tail(1))
Output: 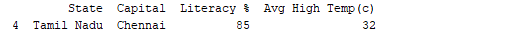 Allo stesso modo, `
Allo stesso modo, `print(df.dtypes)` stampa i tipi di dati. Output: 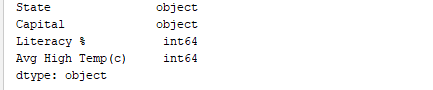 `
`print(df.index)` stampa l’indice. Output:  `
`print(df.columns)` stampa le colonne del DataFrame. Output: 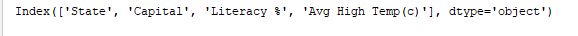 `
`print(df.values)` visualizza i valori della tabella. Output: 
1. Ottenere il riepilogo statistico dei record
Possiamo ottenere un riepilogo statistico (conteggio, media, deviazione standard, minimo, massimo, ecc.) dei dati utilizzando la funzione df.describe(). Ora, utilizziamo questa funzione per visualizzare il riepilogo statistico della colonna “Percentuale di Alfabetizzazione”. Per fare ciò, possiamo aggiungere il seguente pezzo di codice:
print(df['Literacy %'].describe())
Output: 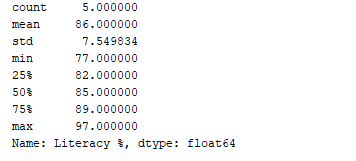 La funzione
La funzione df.describe() visualizza il riepilogo statistico, insieme al tipo di dati.
2. Ordinamento dei record
Possiamo ordinare i record per qualsiasi colonna utilizzando la funzione df.sort_values(). Ad esempio, ordiniamo la colonna “Percentuale di Alfabetizzazione” in ordine decrescente.
print(df.sort_values('Literacy %', ascending=False))
Output: 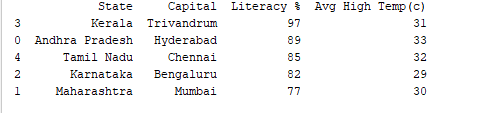
3. Taglio dei record
È possibile estrarre i dati di una colonna particolare utilizzando il nome della colonna. Ad esempio, per estrarre la colonna ‘Capitale’, utilizziamo:
df['Capital']
o
(df.Capital)
Produzione:  È anche possibile suddividere più colonne. Questo viene fatto racchiudendo i nomi delle colonne multipli tra 2 parentesi quadre, con i nomi delle colonne separati da virgole. Il seguente codice suddivide le colonne ‘Stato’ e ‘Capitale’ del DataFrame.
È anche possibile suddividere più colonne. Questo viene fatto racchiudendo i nomi delle colonne multipli tra 2 parentesi quadre, con i nomi delle colonne separati da virgole. Il seguente codice suddivide le colonne ‘Stato’ e ‘Capitale’ del DataFrame.
print(df[['State', 'Capital']])
Produzione:  È anche possibile suddividere le righe. Più righe possono essere selezionate usando l’operatore “:”. Il codice seguente restituisce le prime 3 righe.
È anche possibile suddividere le righe. Più righe possono essere selezionate usando l’operatore “:”. Il codice seguente restituisce le prime 3 righe.
df[0:3]
Produzione:  Una caratteristica interessante della libreria Pandas è selezionare i dati in base alle etichette di riga e colonna utilizzando la funzione
Una caratteristica interessante della libreria Pandas è selezionare i dati in base alle etichette di riga e colonna utilizzando la funzione iloc[0]. Molte volte, potremmo aver bisogno solo di poche colonne da analizzare. Possiamo anche selezionare per indice utilizzando loc['indice_uno']). Ad esempio, per selezionare la seconda riga, possiamo usare df.iloc[1,:]. Diciamo, dobbiamo selezionare il secondo elemento della seconda colonna. Questo può essere fatto utilizzando la funzione df.iloc[1,1]. In questo esempio, la funzione df.iloc[1,1] visualizza “Mumbai” come output.
4. Filtraggio dei dati
È anche possibile filtrare i valori delle colonne. Ad esempio, il codice seguente filtra le colonne con un tasso di alfabetizzazione superiore al 90%.
print(df[df['Literacy %']>90])
Qualsiasi operatore di confronto può essere utilizzato per filtrare, basandosi su una condizione. Output:  Un altro modo per filtrare i dati è usando il
Un altro modo per filtrare i dati è usando il isin. Di seguito il codice per filtrare solo 2 stati, ‘Karnataka’ e ‘Tamil Nadu’.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Output: 
5. Rinomina la colonna
È possibile utilizzare la funzione df.rename() per rinominare una colonna. La funzione prende il vecchio nome della colonna e il nuovo nome della colonna come argomenti. Ad esempio, rinominiamo la colonna ‘Literacy %’ in ‘Percentuale di alfabetizzazione’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
L’argomento `inplace=True` rende le modifiche al DataFrame. Output: 
6. Manipolazione dei dati
La Data Science coinvolge l’elaborazione dei dati in modo che possano funzionare bene con gli algoritmi dati. Il Data Wrangling è il processo di elaborazione dei dati, come fusione, raggruppamento e concatenazione. La libreria Pandas fornisce funzioni utili come merge(), groupby() e concat() per supportare le attività di Data Wrangling. Creiamo 2 DataFrame e mostriamo le funzioni di Data Wrangling per capirle meglio.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Output:  Creiamo ora il secondo DataFrame utilizzando il seguente codice:
Creiamo ora il secondo DataFrame utilizzando il seguente codice:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Output: 
a. Merging
Ora, eseguiamo la fusione dei 2 DataFrame creati, lungo i valori di ‘Employee_id’ utilizzando la funzione merge():
print(pd.merge(df1, df2, on='Employee_id'))
Output:  Possiamo vedere che la funzione merge() restituisce le righe da entrambi i DataFrame che hanno lo stesso valore di colonna utilizzato durante la fusione.
Possiamo vedere che la funzione merge() restituisce le righe da entrambi i DataFrame che hanno lo stesso valore di colonna utilizzato durante la fusione.
b. Grouping
Il raggruppamento è un processo di raccolta di dati in diverse categorie. Ad esempio, nell’esempio seguente, il campo “Employee_Name” ha il nome “Meera” due volte. Quindi, raggruppiamolo per la colonna “Employee_name”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Il campo ‘Employee_name’ con valore ‘Meera’ è raggruppato per la colonna “Employee_name”. L’output di esempio è il seguente: Output: 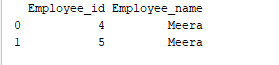
c. Concatenating
Concatenare i dati comporta aggiungere un insieme di dati a un altro. Pandas fornisce una funzione chiamata concat() per concatenare i DataFrame. Ad esempio, concateniamo i DataFrame df1 e df2, utilizzando:
print(pd.concat([df1, df2]))
Output: 
Crea un DataFrame passando un dizionario di Serie
Per creare una Serie, possiamo utilizzare il metodo pd.Series() e passargli un array. Creiamo una semplice Serie come segue:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Output:  Abbiamo creato una Serie. Puoi vedere che vengono visualizzate 2 colonne. La prima colonna contiene i valori degli indici a partire da 0. La seconda colonna contiene gli elementi passati come serie. È possibile creare un DataFrame passando un dizionario di `Serie`. Creiamo un DataFrame che è formato unendo e passando gli indici delle serie. Esempio
Abbiamo creato una Serie. Puoi vedere che vengono visualizzate 2 colonne. La prima colonna contiene i valori degli indici a partire da 0. La seconda colonna contiene gli elementi passati come serie. È possibile creare un DataFrame passando un dizionario di `Serie`. Creiamo un DataFrame che è formato unendo e passando gli indici delle serie. Esempio
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Output di esempio 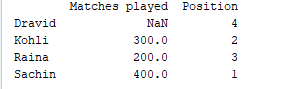 Per la prima serie, poiché non abbiamo specificato l’etichetta ‘d’, viene restituito NaN.
Per la prima serie, poiché non abbiamo specificato l’etichetta ‘d’, viene restituito NaN.
Selezione, Aggiunta, Cancellazione delle Colonne
È possibile selezionare una specifica colonna dal DataFrame. Ad esempio, per visualizzare solo la prima colonna, possiamo riscrivere il codice sopra come segue:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
Il codice sopra stampa solo la colonna “Partite giocate” del DataFrame. Output 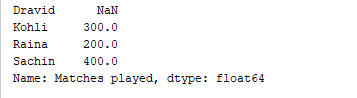 È anche possibile aggiungere colonne a un DataFrame esistente. Ad esempio, il codice seguente aggiunge una nuova colonna chiamata “Runrate” al DataFrame sopra:
È anche possibile aggiungere colonne a un DataFrame esistente. Ad esempio, il codice seguente aggiunge una nuova colonna chiamata “Runrate” al DataFrame sopra:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Output:  Possiamo eliminare colonne utilizzando le funzioni `delete` e `pop`. Ad esempio, per eliminare la colonna ‘Partite giocate’ nell’esempio precedente, possiamo farlo in uno dei seguenti modi:
Possiamo eliminare colonne utilizzando le funzioni `delete` e `pop`. Ad esempio, per eliminare la colonna ‘Partite giocate’ nell’esempio precedente, possiamo farlo in uno dei seguenti modi:
del df['Matches played']
oppure
df.pop('Matches played')
Output: 
Conclusioni
Nel presente tutorial, abbiamo avuto una breve introduzione alla libreria Python Pandas. Abbiamo anche eseguito esempi pratici per sfruttare il potere della libreria Pandas utilizzata nel campo della scienza dei dati. Abbiamo inoltre esaminato le diverse strutture dati nella libreria Python. Riferimento: Sito Web Ufficiale di Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial