













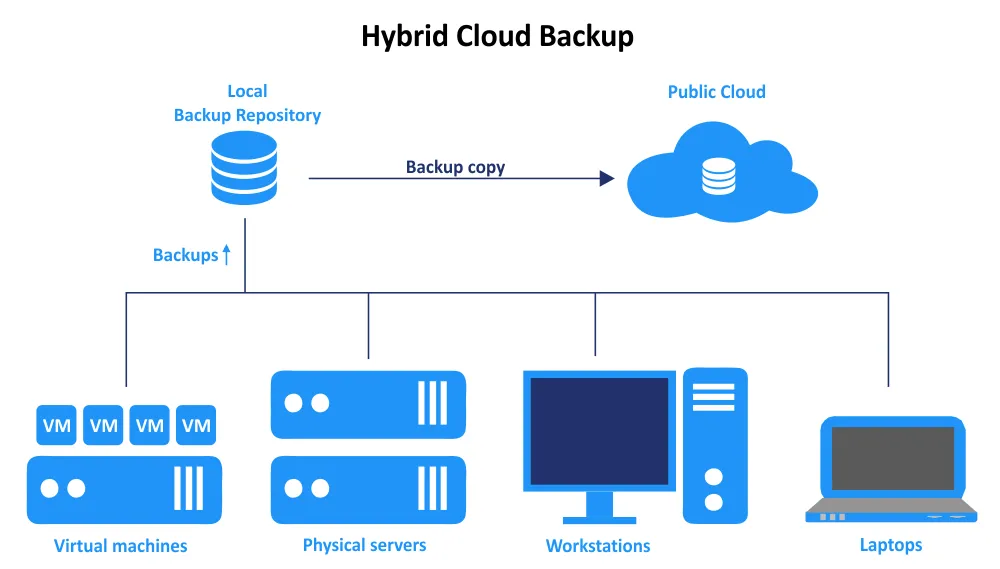
Il backup ibrido cloud è una strategia di protezione dei dati che combina sia lo storage in locale che quello basato su cloud per i dati di backup. Questo approccio si distingue dalle altre strategie di backup includendo un componente cloud per migliorare la ridondanza, la disponibilità, la resilienza e l’efficienza dei costi.
In questo articolo, non ci concentreremo sul backup di un’infrastruttura cloud ibrida, ma piuttosto sul backup verso configurazioni cloud ibride, includendo principi di base e configurazione delle soluzioni di protezione dei dati da integrare con i servizi cloud.
Strategia di backup ibrido cloud
Guardiamo ora cosa include una strategia di cloud ibrido per il backup e il ripristino:
- Backup locale (infrastruttura in locale)
- Un’organizzazione mantiene la propria infrastruttura di backup come parte del proprio data center in loco. Questo include server di backup, dispositivi di archiviazione (ad esempio, NAS) o altri apparecchi.
- Vengono creati backup regolari a intervalli specifici, catturando i cambiamenti ai dati nel tempo. Sono creati punti di ripristino frequenti per fornire un accesso rapido ai dati e garantire la continuità operativa.
- Questa infrastruttura locale consente tempi di backup e ripristino più rapidi per le operazioni quotidiane ed è adatta a scenari in cui l’accesso immediato ai dati è essenziale e l’obiettivo di tempo di ripristino (RTO) è breve.
- Infrastruttura basata su cloud
- Oltre alla configurazione locale, un’organizzazione utilizza un fornitore di servizi cloud come Amazon Web Services (AWS), Microsoft Azure o un altro provider di piattaforma cloud per memorizzare le copie di backup nel centro dati remoto del fornitore del servizio.
- Lo storage su cloud fornisce una ridondanza esterna alla sede, che è fondamentale per il recupero dei dati in caso di disastri locali, guasti hardware o altri problemi locali che possono rendere indisponibili anche i backup locali. I backup su cloud possono essere accessibili da qualsiasi posizione con una connessione internet, consentendo il recupero dei dati da remoto.
- Le risorse cloud sono inoltre facilmente scalabili, consentendo a un’organizzazione di adattarsi a requisiti di capacità mutevoli senza investimenti hardware importanti in anticipo.
- Implementazione
- Il software di gestione dei backup viene utilizzato per pianificare, gestire e avviare i backup sia in ambienti in loco che cloud.
- Inizialmente, i dati dai sistemi in loco vengono eseguiti il backup localmente, garantendo un rapido backup e recupero per le esigenze operative.
- I dati di backup archiviati in loco vengono quindi copiati periodicamente nello storage cloud, creando copie ridondanti nell’ambiente remoto.
- Le organizzazioni stabiliscono politiche di conservazione per determinare per quanto tempo sono conservate le copie di backup sia in loco che nel cloud. Questo aiuta a gestire i costi di archiviazione e i requisiti di conformità.
- Recupero dati e macchine
- La combinazione di backup locali e nel cloud migliora le capacità di continuità aziendale e di ripristino da disastri della vostra organizzazione e la resilienza IT. In caso di perdita di dati, corruzione, guasto hardware o altre emergenze, avete due opzioni per il recupero dei dati: backup locali e nel cloud.
- I backup locali affrontano le esigenze di ripristino immediato, mentre i backup nel cloud forniscono una rete di sicurezza in caso di disastri su larga scala che interessano il vostro ambiente in loco.
- I backup locali offrono tempi di ripristino più veloci per le operazioni quotidiane, poiché i dati possono essere ripristinati dall’infrastruttura in loco senza dover fare affidamento su Internet. La velocità di una rete locale è anche più veloce delle velocità di Internet.
- Il componente cloud del backup ibrido serve come elemento cruciale nella pianificazione del ripristino da disastri, poiché fornisce ridondanza dei dati in posizioni geograficamente separate. In caso di un disastro che colpisce l’infrastruttura locale, le organizzazioni possono ripristinare i dati dal cloud per garantire la continuità aziendale.
Vantaggi del Backup a Hybrid Cloud
Il backup a hybrid cloud offre diversi benefici che lo rendono una strategia di protezione dati convincente per le organizzazioni. La resistenza operativa migliorata dipende da vari fattori:
- Redundanza e ripristino di emergenza. Il backup ibrido su cloud fornisce ridondanza memorizzando i dati sia nell’ambiente locale che nel cloud. Questa ridondanza garantisce la disponibilità e il ripristino dei dati anche in caso di guasti hardware, corruzione dei dati o disastri locali.
- Flessibilità e scalabilità. Il backup ibrido su cloud offre scalabilità utilizzando risorse cloud per una capacità di archiviazione aggiuntiva durante i periodi di picco della domanda o mentre i volumi dei dati crescono. Questa scalabilità elimina la necessità di aggiornamenti hardware costanti.
- Accessibilità remota. I backup su cloud consentono agli utenti autorizzati di accedere ai dati da qualsiasi luogo con una connessione internet. Questa accessibilità remota è cruciale per le aziende con team remoti o distribuiti e in scenari di ripristino di emergenza.
- Ripristino rapido. I backup locali consentono un ripristino rapido dei dati per le operazioni di routine, mentre i backup su cloud offrono una opzione secondaria per il ripristino di emergenza. Questa combinazione consente alle organizzazioni di rispettare gli obiettivi di tempo di ripristino (RTO) variabili per scenari diversi.
- Protezione esterna. I backup su cloud forniscono protezione esterna, proteggendo i dati da minacce fisiche come furto, inondazioni, incendi, tifoni o altri disastri naturali che potrebbero influenzare l’infrastruttura in loco. Lo storage cloud serve come posizione remota per memorizzare i dati di backup. In caso di perdita di dati in loco, guasto hardware o disastri naturali, i dati memorizzati nel cloud rimangono accessibili e recuperabili.
- Potenziamento della sicurezza. I fornitori di cloud spesso offrono funzionalità avanzate di sicurezza, crittografia e certificazioni di conformità. Questo migliora la sicurezza dei dati rispetto ai metodi tradizionali di backup locale che potrebbero mancare di queste misure. Molti fornitori di storage cloud offrono anche l’immutabilità per proteggere i dati archiviati nel cloud da modifiche, corruzione e crittografia da parte di malware.
- Mobilità dei dati e gestione del carico di lavoro. Il backup ibrido del cloud consente un movimento fluido dei dati tra ambienti on-premises e cloud, supportando strategie flessibili di gestione del carico di lavoro e migrazione dei dati.
- Distribuzione geografica. Le organizzazioni con più sedi possono gestire centralmente i backup consentendo contemporaneamente a siti diversi di accedere ai dati dal cloud. Ciò migliora la disponibilità dei dati, la collaborazione e le capacità di ripristino da disastri. I fornitori di cloud spesso hanno data center in diverse regioni geografiche. Questa distribuzione geografica aggiunge uno strato aggiuntivo di ridondanza, garantendo che i dati rimangano disponibili anche se un data center riscontra problemi.
- OTTIMIZZAZIONE DEI COSTI. Le organizzazioni possono ottimizzare i costi utilizzando l’infrastruttura on-premises per i backup di routine e affidandosi alle risorse cloud solo quando necessario. Le risorse cloud spesso utilizzano il modello di pagamento pay-as-you-go, riducendo gli investimenti iniziali e i costi di manutenzione. Il backup ibrido del cloud aiuta a ottimizzare i costi utilizzando l’infrastruttura on-premises per i backup di routine e le risorse cloud per capacità aggiuntive durante i picchi di domanda o le emergenze.
Svantaggi del backup ibrido del cloud
- Complessità e overhead di gestione
- L’implementazione e la gestione di una soluzione di backup ibrido su cloud possono essere complesse, richiedendo competenze sia nelle tecnologie on-premises che cloud.
- Gli amministratori devono gestire la sincronizzazione, il trasferimento dati e la gestione delle politiche di backup in ambienti diversi. Ciò può aggiungere ulteriori difficoltà se vengono utilizzati più fornitori di cloud pubblico diversi.
- Trasferimento dati e latenza
- Il trasferimento di grandi volumi di dati tra on-premises e cloud può richiedere tempo e dipendere dalla larghezza di banda internet.
- La latenza potrebbe influenzare l’accesso ai dati e i tempi di ripristino, in particolare per i ripristini basati su cloud.
- Preoccupazioni per la sicurezza dei dati
- Anche se i fornitori di cloud implementano misure di sicurezza avanzate, alcune organizzazioni potrebbero ancora avere preoccupazioni nel affidare dati sensibili a fornitori terzi.
- Violazioni dei dati o accessi non autorizzati ai backup memorizzati su cloud potrebbero rappresentare un rischio se non gestiti correttamente.
- Lock-in del fornitore. Adottare un provider cloud specifico per i servizi di backup potrebbe comportare un lock-in del fornitore, rendendo difficile passare a un altro fornitore o migrare i dati in un altro ambiente.
- Dipendenze di rete. Il backup cloud ibrido dipende pesantemente dalla connettività di rete. Se si verificano problemi di rete, potrebbero influire sulla capacità di trasferire i backup nel cloud o accedere ai backup memorizzati nel cloud.
- Conformità e regolamenti sui dati. Alcune industrie hanno rigide normative sulla conformità e la residenza dei dati. Assicurarsi che i fornitori di servizi cloud rispettino tali regolamenti potrebbe richiedere sforzi aggiuntivi.
- Controllo limitato sull’infrastruttura cloud. I servizi cloud astraggono l’infrastruttura sottostante, limitando il livello di controllo che un’organizzazione ha sull’hardware e sulle configurazioni rispetto alle soluzioni on-premises.
- Dipendenza dal recupero dei dati. Fare affidamento esclusivamente sui backup cloud potrebbe creare una dipendenza dai servizi esterni per il recupero dei dati. Se il fornitore cloud incontra problemi, potrebbe essere compromesso il recupero dei dati.
- Proprietà e conservazione dei dati. Chiarire le politiche di proprietà e conservazione dei dati quando si utilizzano servizi cloud è importante per garantire che le organizzazioni mantengano il controllo dei propri dati.
- Dipendenze operative. Le organizzazioni potrebbero diventare dipendenti operativamente dai servizi cloud per il backup e il ripristino. Questa dipendenza potrebbe rappresentare delle sfide se il fornitore cloud dovesse subire interruzioni.
- Sfide iniziali di configurazione e migrazione. Il passaggio dai metodi di backup tradizionali a un modello di backup cloud ibrido potrebbe richiedere tempo e risorse per la configurazione, la migrazione dei backup esistenti e la formazione degli utenti.
- Complessità della gestione dei costi
- Anche se le risorse cloud possono offrire risparmi sui costi attraverso modelli di pagamento in base al consumo, gestire e prevedere i costi sia nell’ambiente locale che in quello cloud può essere impegnativo.
- Una cattiva gestione dei costi potrebbe portare a spese impreviste.
Costi potenziali dello storage cloud
I costi potenziali associati allo storage cloud possono essere considerati uno svantaggio del backup cloud ibrido. Questi costi possono includere:
- Costi di storage. I fornitori cloud tipicamente addebitano in base alla quantità di storage utilizzata. Con l’aumentare dei volumi di dati, i costi di storage possono aumentare. Le organizzazioni devono stimare accuratamente le loro esigenze di storage per evitare spese impreviste.
- Costi di trasferimento dati. Caricare dati nel cloud e recuperarli dal cloud può comportare costi di trasferimento dati. Questi costi possono accumularsi, specialmente se vi è un movimento frequente di grandi quantità di dati.
- Costi di accesso e diuscita. Alcuni fornitori di cloud applicano costi per l’accesso e il recupero dei dati. A seconda della frequenza con cui si effettuano ripristini o recupero di dati, questi costi possono accumularsi nel tempo. Costi di uscita. Spostare i dati all’esterno dell’ambiente cloud, specialmente se verso un altro fornitore di cloud o verso infrastrutture on-premises, può comportare costi di uscita.
- Costi della ridondanza e della replicazione dati. La replicazione dati su molteplici regioni o centri dati a scopo di ridondanza può generare costi aggiuntivi. Questo è particolarmente rilevante per organizzazioni con elevate richieste di disponibilità dati.
- Costi per inattività. Alcuni fornitori di cloud potrebbero applicare tariffe se i dati rimangono inattivi (cioè non accessibili o modificati) per periodi prolungati.
- Variabilità dei costi. Sebbene il modello a consumo pagato del cloud storage possa essere economico, la previsione dei costi potrebbe essere una preoccupazione a causa delle fluttuazioni nelle necessità di archiviazione dati e nei modelli di utilizzo.
È essenziale valutare attentamente questi svantaggi nel contesto specifico delle necessità, degli obiettivi e dei risorse dell’organizzazione. Strategie di mitigazione e pianificazione adeguata possono aiutare a risolvere questi挑战 e garantire un’implementazione riuscita della copia di backup in un setup di cloud ibrido.
Come mitigare i problemi legati ai costi
Esistono diversi passi che puoi intraprendere per mitigare i costi elevati dell’archiviazione cloud in un’impostazione di backup cloud ibrido:
- Utilizza un approccio di backup incrementale (opzionalmente con backup completi sintetici periodici) e tecnologie di deduplicazione.
- Utilizza il cloud come archivio di backup secondario e usa i backup locali come backup primari per ridurre le spese di accesso e di recupero imposte dai fornitori di cloud (come le spese di uscita). Puoi anche scegliere fornitori senza spese di uscita, ad esempio, Wasabi.
- Scegli livelli di archiviazione cloud (come archiviazione standard, accesso non frequente o archiviazione di archivio) che corrispondano ai modelli di accesso dei tuoi dati.
- Utilizza supporti più economici per l’archiviazione a lungo termine e l’archiviazione, ad esempio, unità a nastro.
- Monitora l’utilizzo dei dati e valuta regolarmente l’efficacia economica della tua strategia di archiviazione.
Tipi di Backup Cloud Ibrido
Il backup cloud ibrido può comprendere approcci diversi, con benefici specifici e allineandosi con diverse esigenze organizzative. La scelta del tipo di backup dipende da fattori come gli obiettivi di ripristino dei dati, i requisiti di archiviazione, le considerazioni di budget e l’infrastruttura IT complessiva. I principali tipi di backup cloud ibrido sono i seguenti:
- Copia di backup in locale + copia di backup su cloud
I backup vengono creati in locale, nello storage in loco. Il backup viene poi utilizzato per creare una copia di backup nel cloud per la ridondanza esterna. Questo approccio fornisce un ripristino locale veloce e utilizza il cloud per scenari di ripristino più gravi. Inoltre, minimizza l’impatto sull’ambiente di produzione.
La pianificazione e la politica di conservazione per le copie di backup nel cloud possono differire da quelle utilizzate per il backup locale. In questo modo, il cloud viene utilizzato per il tiering dove i punti di ripristino più vecchi vengono spostati nel cloud man mano che diventano meno frequentemente accessibili. Questo approccio ottimizza i costi utilizzando lo storage cloud per i dati meno attivi, mantenendo i dati frequentemente accessibili in locale per un rapido recupero.
- Backup basato su cloud con cache locale
In questo modello, i backup vengono inizialmente effettuati direttamente sul cloud. Una cache locale potrebbe essere mantenuta per i dati frequentemente accessati, consentendo ripristini più rapidi.
Questo approccio è pratico quando le esigenze di ripristino dei dati sono principalmente orientate al cloud ma richiedono accesso locale per dati specifici.
- Replicazione bidirezionale del cloud
I dati vengono continuamente sincronizzati tra l’infrastruttura in loco e il cloud. Le modifiche apportate nell’ambiente locale o cloud vengono replicate nell’altra posizione.
Questo approccio è intensivo in termini di risorse. Tuttavia, garantisce che i dati rimangano consistenti in entrambi gli ambienti, consentendo un accesso e un ripristino flessibili dei dati.
- Archiviazione a livelli di backup
Con questa strategia, diversi livelli di dati vengono archiviati in posizioni diverse in base alla frequenza di accesso. I dati frequentemente accessi potrebbero essere archiviati localmente, mentre i dati meno frequentemente accessi sono archiviati nel cloud per ottimizzare i costi.
L’archiviazione basata su cloud coinvolge il trasferimento dei dati meno frequentemente accessi o più vecchi nello storage cloud per liberare spazio nei sistemi di archiviazione on-premises. I dati archiviati vengono conservati per archiviazione a lungo termine e scopi di conformità, ma sono meno accessibili rispetto ai dati frequentemente utilizzati.
- Gestione della rotazione e del ciclo di vita del backup
Questo approccio prevede la rotazione delle copie di backup tra ambienti locali e cloud in base alle politiche di conservazione. I backup più vecchi potrebbero essere spostati nel cloud per la conservazione a lungo termine, mentre i backup recenti vengono mantenuti localmente per ripristini più rapidi.
- Ripristino dei disastri basato su cloud
Il cloud è principalmente utilizzato per scopi di ripristino dei disastri. Memorizzando copie di backup e immagini di macchine virtuali nel cloud, è possibile ripristinare rapidamente interi sistemi in caso di un disastro che colpisce l’ambiente locale, inclusa l’infrastruttura di backup locale.
- Apparecchiature di backup ibride
Le apparecchiature ibride combinano hardware di backup locale con integrazione cloud. Queste apparecchiature gestiscono la deduplicazione dei dati, la crittografia e la sincronizzazione tra backup locali e cloud.
Questi concetti evidenziano i vari modi in cui le organizzazioni possono utilizzare sia lo storage in loco che il cloud per ottenere protezione dei dati, ripristino dei disastri, ottimizzazione dei costi e gestione efficiente dei dati. L’approccio di un’organizzazione dipende da molteplici fattori, come le politiche di conservazione dei dati, gli obiettivi di tempo di ripristino, i modelli di accesso ai dati e le considerazioni di bilancio.
Configurazione del backup ibrido del cloud con NAKIVO
NAKIVO Backup & Replication è una soluzione di protezione dei dati progettata per diverse infrastrutture:
- On-premise, sia server fisici che virtualizzati
- Cloud, comprese configurazioni multi-cloud
- Cloud ibrido
La soluzione supporta il backup dei carichi di lavoro nei data center locali e nel cloud, nonché il backup verso data center locali e cloud pubblici/privati. La soluzione NAKIVO offre un modo conveniente per implementare una strategia di backup cloud ibrido creando un backup locale e quindi creando un job di backup verso un’ubicazione di archiviazione cloud. Inoltre, questi job possono essere automatizzati per essere eseguiti uno dopo l’altro con la funzione Job Chaining. Scopriamo come configurare un backup cloud ibrido con NAKIVO Backup & Replication.
Aggiunta di elementi all’inventario
È possibile aggiungere sia piattaforme locali che cloud all’inventario della soluzione NAKIVO per iniziare a proteggerli. È inoltre necessario aggiungere l’archiviazione cloud di destinazione all’inventario.
Per aggiungere elementi all’inventario:
- Vai a Impostazioni > Inventario e fai clic sull’icona +.
- Seleziona la piattaforma necessaria e completa il wizard Aggiungi Elemento Inventario.
Leggi la spiegazione dettagliata su come aggiungere diversi elementi all’inventario.
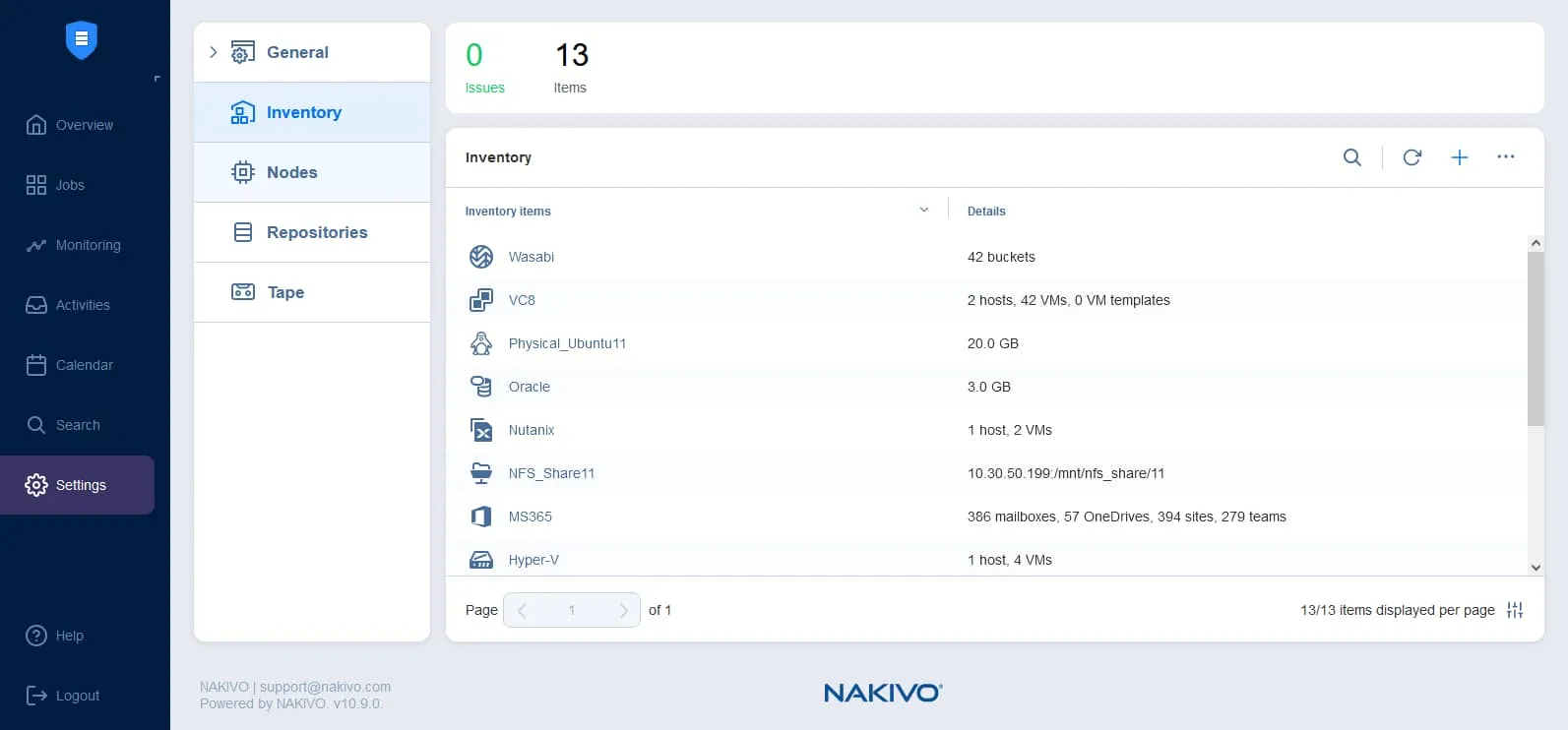
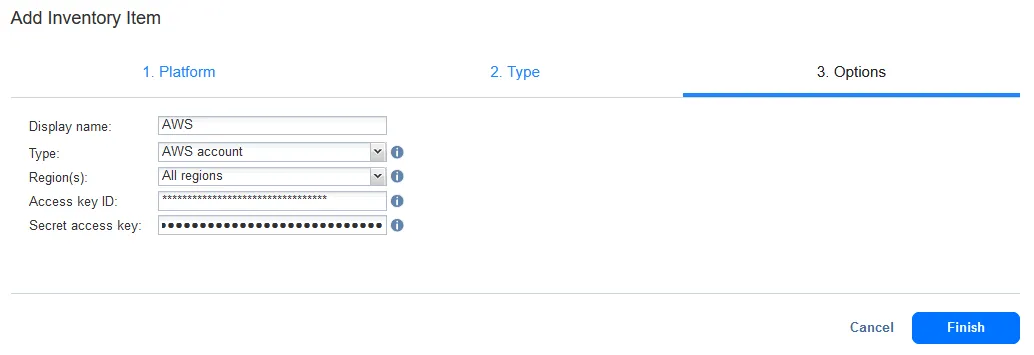
Nel nostro esempio, aggiungiamo host ESXi, che fanno parte di VMware vSphere, come piattaforma sorgente e archiviazione Amazon S3 per creare una copia di backup nel cloud.
Per aggiungere Amazon S3 o altre destinazioni cloud:
- Selezionare Archiviazione al primo passo del wizard Aggiungi elemento inventario per aggiungere l’archiviazione cloud.
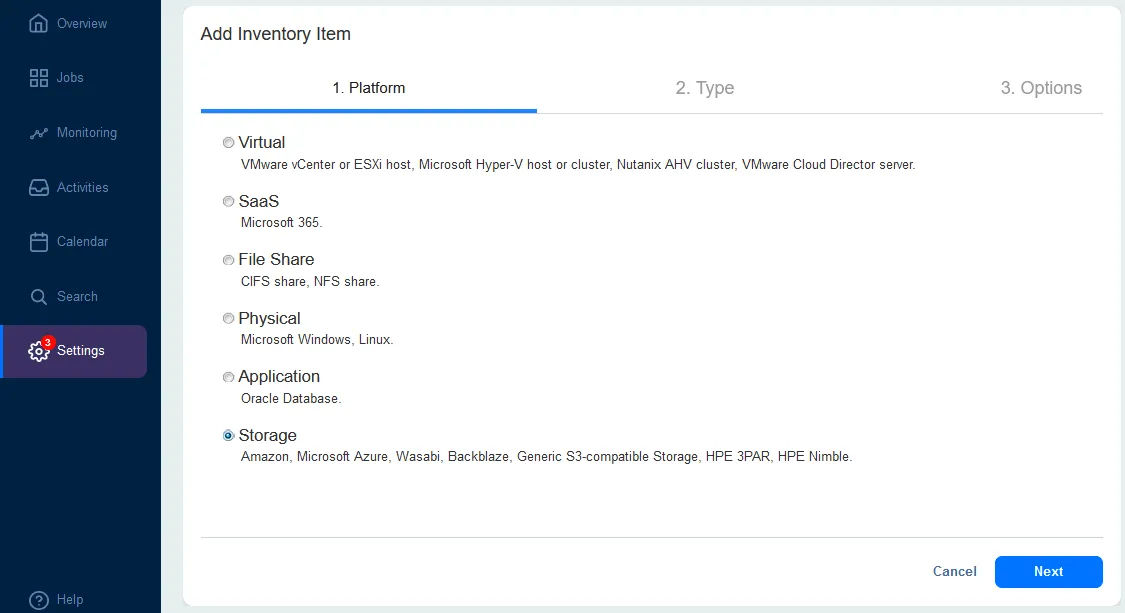
- Per Tipo, selezionare Amazon S3 o un altro cloud platform. È possibile aggiungere uno dei cloud storage accounts supportati:
- Amazon S3
- Generico archiviazione oggetti compatibile con S3 nel cloud
- Microsoft Azure Storage
- Wasabi
- BackBlaze B2
- Per Opzioni, inserire le opzioni di connessione necessarie.
Creazione di un repository in locale
Crea un repository di backup nella tua infrastruttura locale o usa il Repository di Backup Onboard. Vai a Impostazioni > Repository e fai clic su + per creare un nuovo repository di backup.

Puoi creare un repository di backup utilizzando una cartella locale su una macchina con un Transporter installato, che può essere un dispositivo NAS o un apparecchio di deduplicazione. Puoi anche utilizzare posizioni alternative del repository nell’infrastruttura on-premises e creare un repository di backup su una condivisione SMB o NFS.
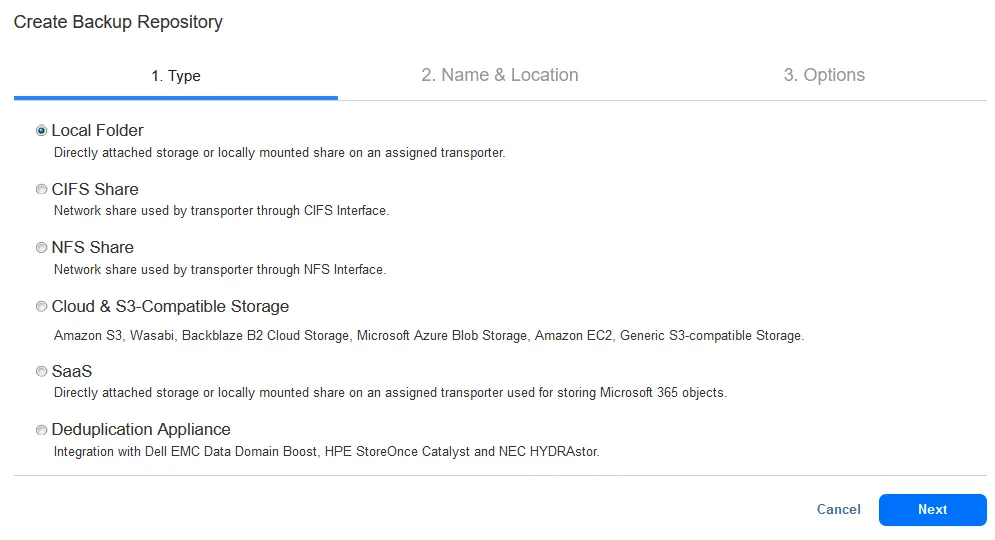
Segui i passaggi della procedura guidata per completare la creazione di un repository di backup del tipo appropriato. Puoi abilitare la crittografia dei dati durante la creazione di un repository di backup.
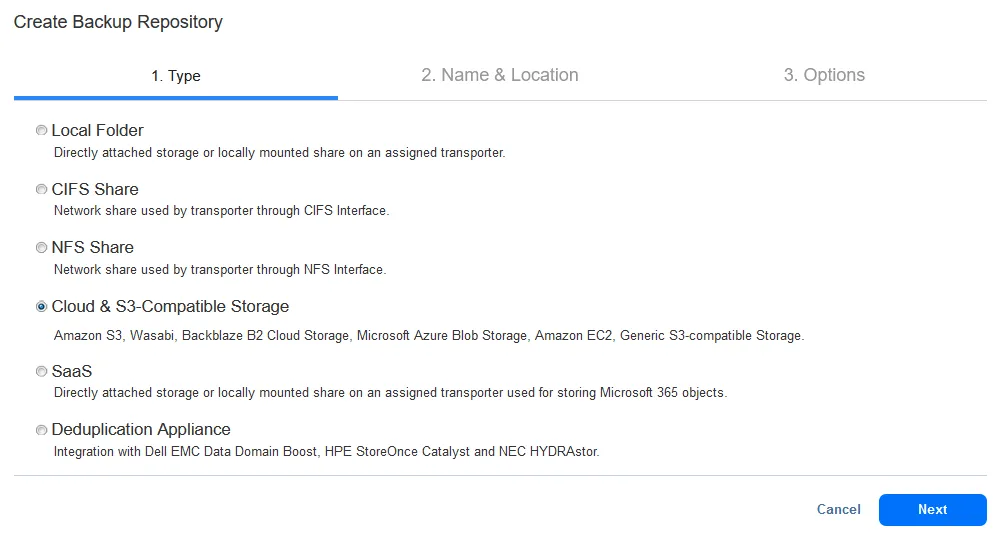
Creazione di un repository in un cloud pubblico
Crea un repository di backup nel cloud. Vai su Impostazioni > Repository e clicca su + per creare un nuovo repository di backup. Segui le istruzioni per creare un repository di backup nel cloud pubblico:
- Creare un repository in Amazon S3
- Creare un repository in Archiviazione BLOB di Azure
- Creare un repository in Amazon EC2
- Creare un repository in Archiviazione cloud BackBlaze B2
- Creare un repository in Archiviazione cloud Wasabi Hot Cloud
Poiché utilizziamo Amazon S3 in questo esempio, selezioniamo Cloud & Archiviazione compatibile con S3 come tipo di repository e quindi Amazon S3 nella procedura guidata Crea Repository di Backup.
È necessario disporre almeno di un repository di backup locale e quindi creare un repository di backup in una nube pubblica. I nostri repository di backup sono visualizzati nello screenshot qui sotto. È possibile avere più di un repository locale e nella nube pubblica per maggiore flessibilità e scalabilità.
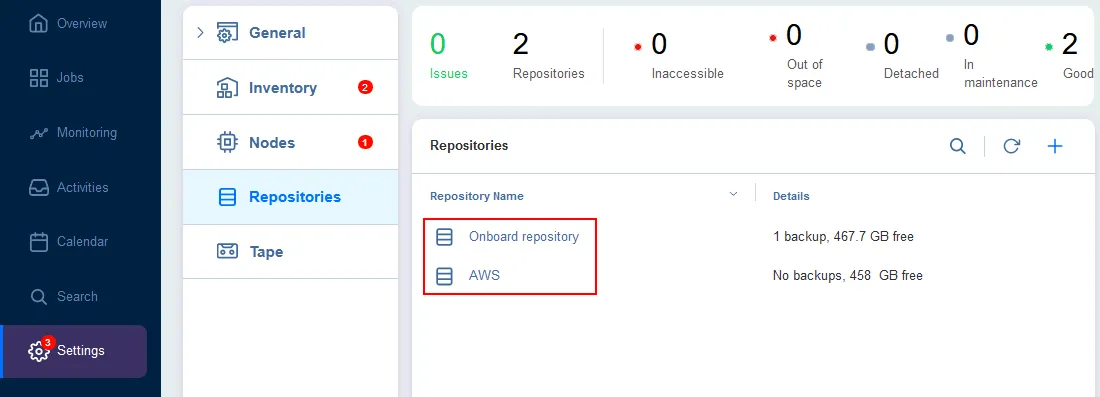
Configurazione di un lavoro di backup locale
Nel nostro esempio, creiamo 2 processi di backup: un processo di backup a un archivio di storage locale per una rapida ripristino operativo e un processo di backup di copia a un bucket Amazon S3 da utilizzare quando la nostra infrastruttura di backup locale non è disponibile.
Configuriamo un processo di backup per il backup dei dati nel repository di backup locale.
Clicca su Jobs nel pannello a sinistra, clicca su + e seleziona VMware vSphere backup job o altro tipo di processo di backup, a seconda di ciò che desideri eseguire il backup.
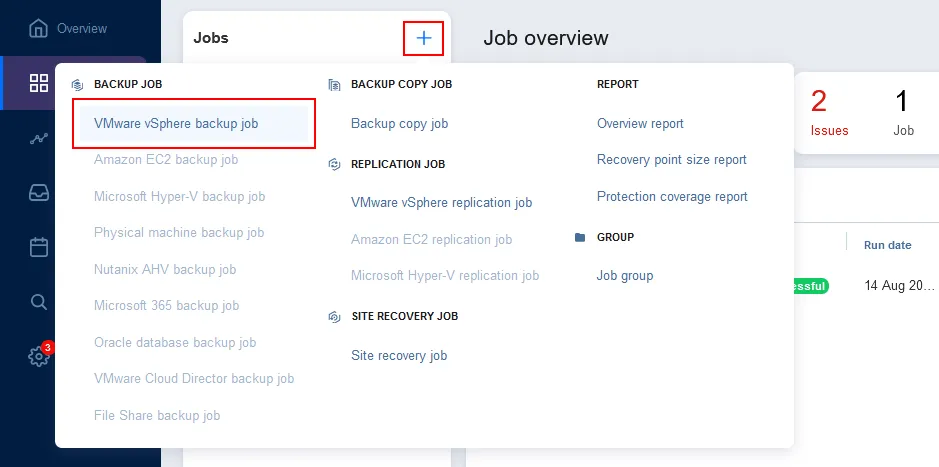
Segui le istruzioni per creare un nuovo processo di backup per la fonte dei dati appropriata.
Poiché stiamo eseguendo il backup di macchine virtuali VMware in questa procedura dettagliata, seguiamo le istruzioni per creare un processo di backup VMware vSphere. Devi completare il wizard per creare un processo di backup:
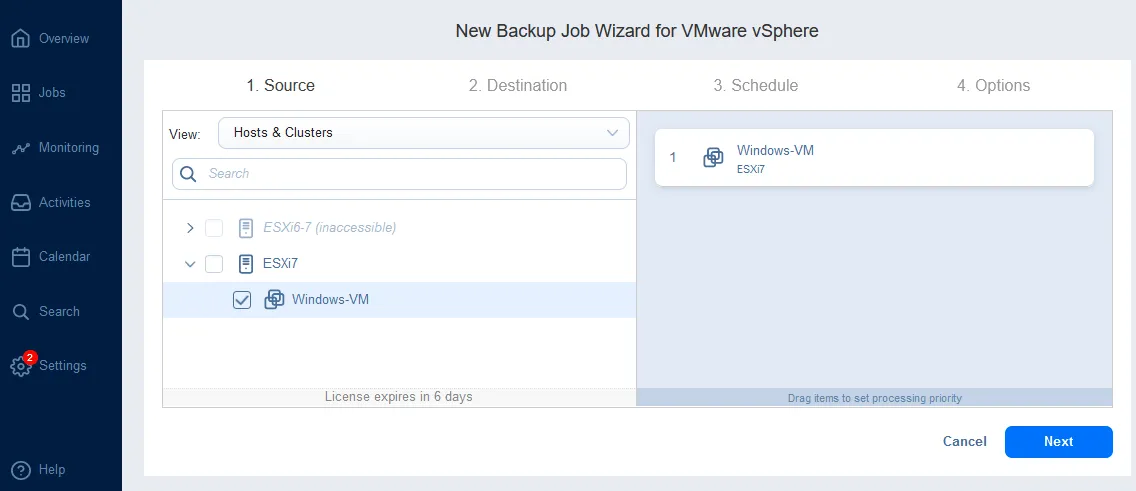
- Source. Seleziona gli elementi che desideri eseguire il backup. Noi selezioniamo una VM Windows residente su un host ESXi.
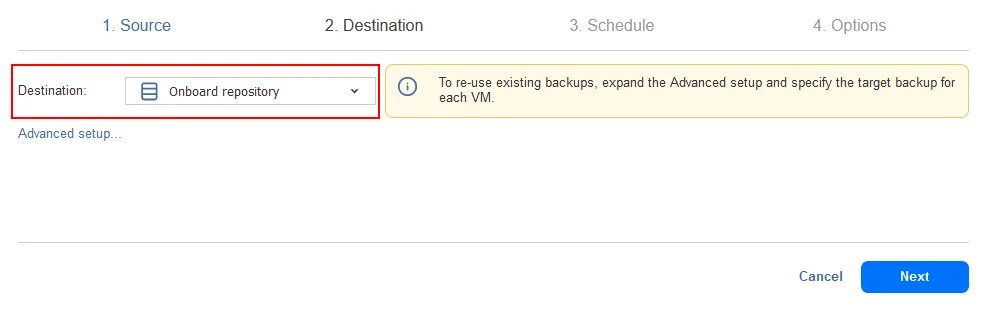
- Destinazione. Seleziona uno dei repository di backup che hai distribuito in locale. Stiamo utilizzando il repository Onboard situato sulla macchina locale in cui è installato NAKIVO Backup & Replication (soluzione completa) come repository primario.
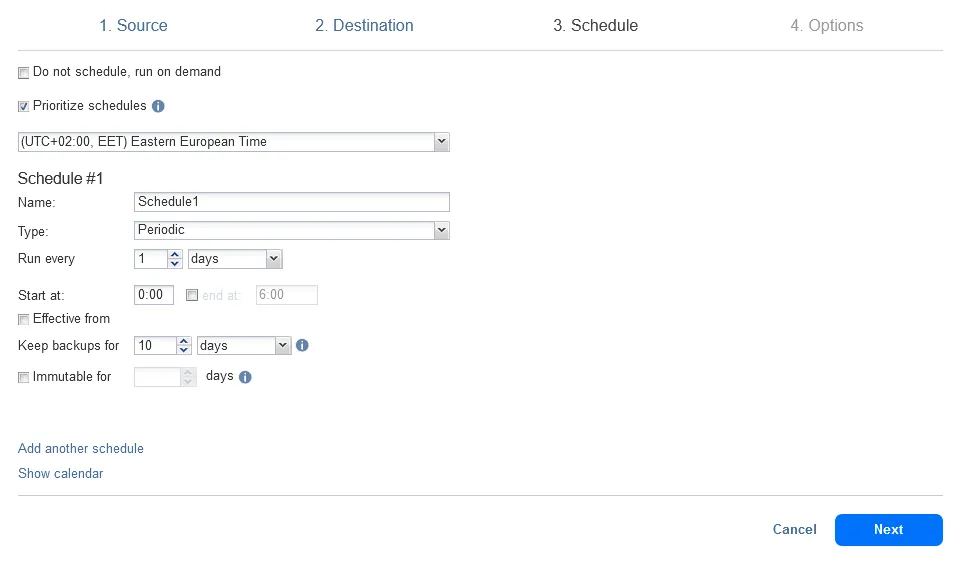
- Pianificazione. Imposta la pianificazione per un job di backup per definire quando eseguire il backup dei dati nel repository di backup in locale. Configuriamo un job di backup da eseguire ogni giorno alle 0:00 AM. È possibile configurare più regole di pianificazione e conservazione in questo passaggio.
- Opzioni. Immettere un nome per il job di backup e configurare altre opzioni del job di backup. Ad esempio, è possibile abilitare l’encryption di rete per proteggere i dati in transito, utilizzare l’accelerazione di rete, escludere i file di scambio, le partizioni e i blocchi inutilizzati per velocizzare i trasferimenti di dati, ecc. Completare l’assistente.
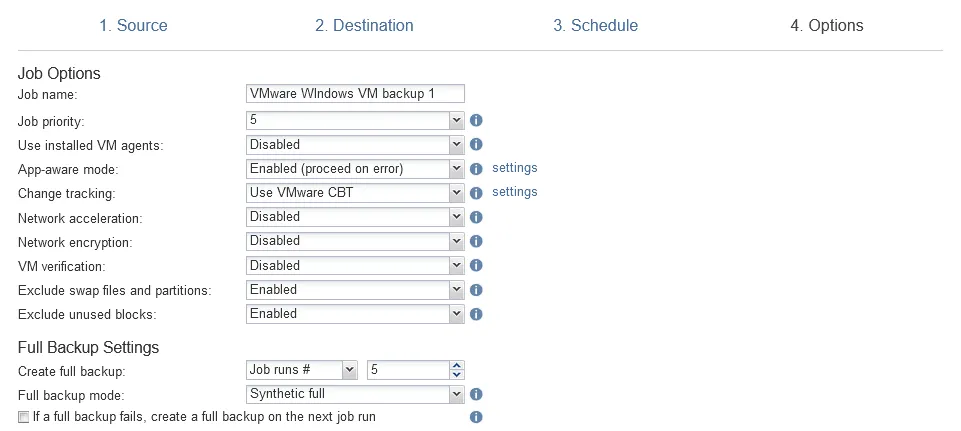
Configurazione di un job di copia di backup nel cloud
Configurare copia di backup nel cloud per una configurazione di backup ibrido cloud.
Fare clic su Job nel riquadro a sinistra, premere + e fare clic su Job di copia di backup nel menu che si apre. Viene aperto l’Assistente per il nuovo job di copia di backup.
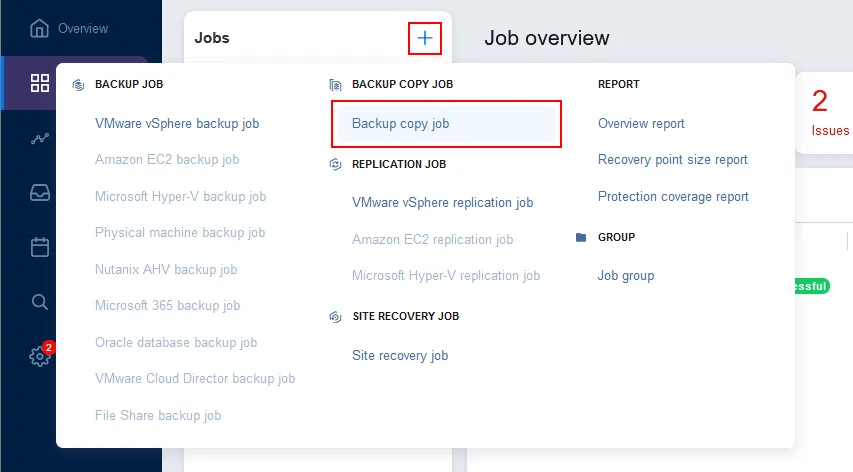
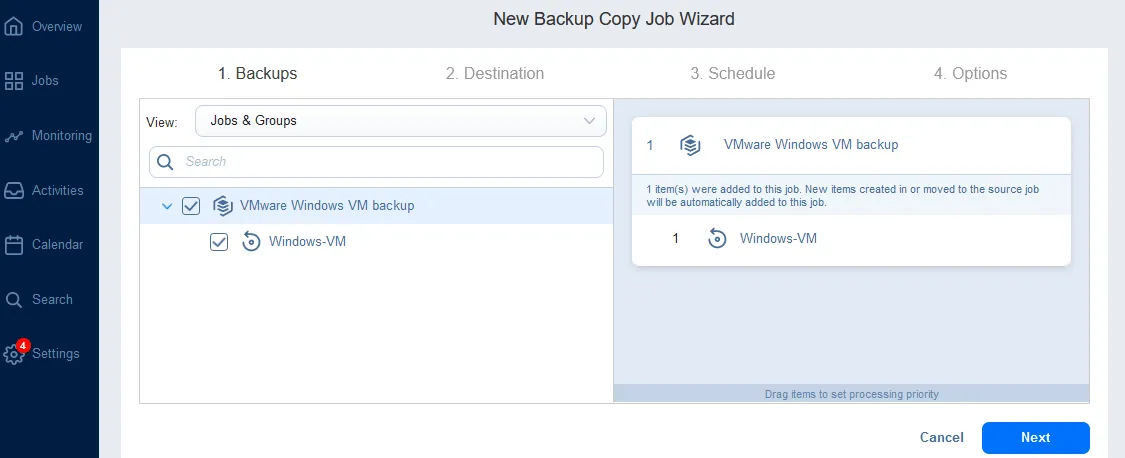
- Backup. Selezionare il job di backup che è stato creato e eseguito in precedenza. Nel nostro caso, selezioniamo il backup del VM VMware Windows job con tutti i backup VM creati da questo job.
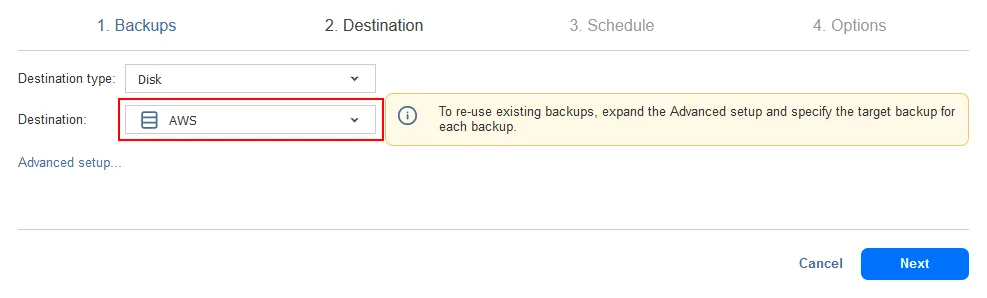
- Destinazione. Seleziona il repository di backup che hai creato nel cloud pubblico. In questo caso, selezioniamo il repository di backup S3 come destinazione.
- Pianificazione. Configura una pianificazione e una politica di conservazione per il lavoro di copia di backup. Poiché abbiamo configurato il backup locale per essere eseguito ogni giorno alle 0:00, configuriamo la copia di backup nel cloud per essere avviata ogni giorno alle 3:00. La nostra VM non è grande e il lavoro di backup locale dovrebbe terminare entro le 3:00. In alternativa, puoi utilizzare Concatenazione di lavori per avviare automaticamente il lavoro di copia di backup dopo un lavoro di backup riuscito.
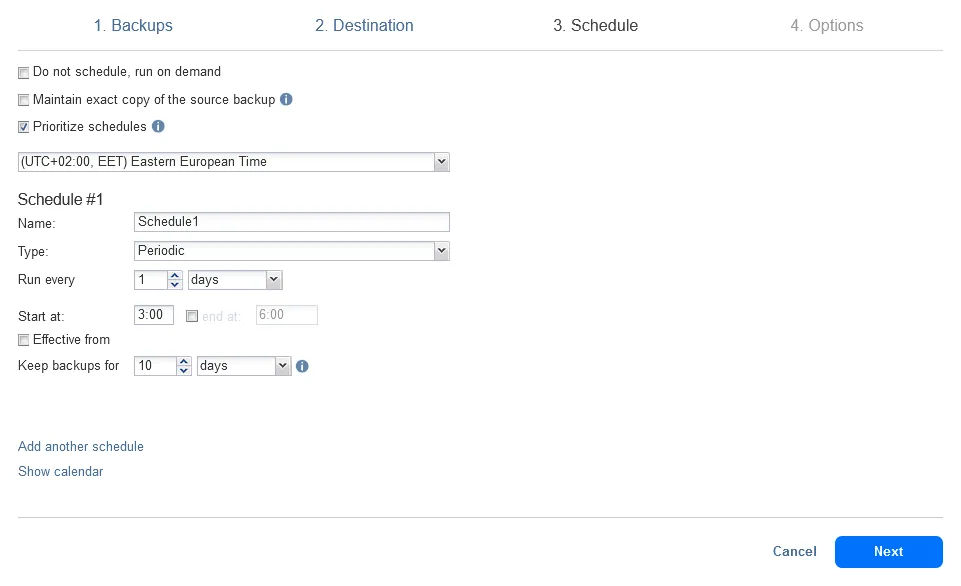
- Opzioni. Inserisci un nome per il lavoro di copia di backup, seleziona le opzioni necessarie, come l’accelerazione della rete o la crittografia della rete, e premi Fine o Fine & Esegui.
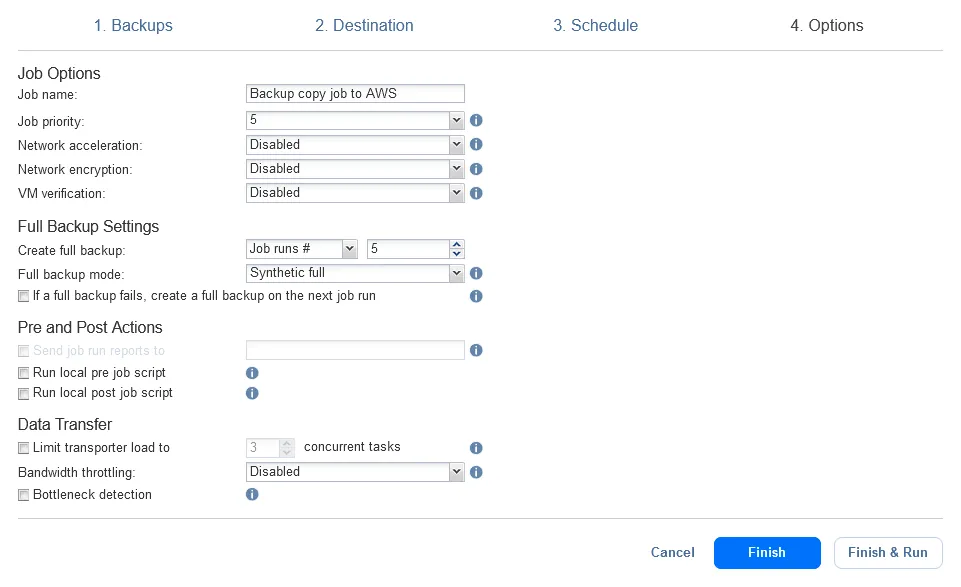
Abbiamo configurato il backup ibrido nel NAKIVO Backup & Replication. Attendere fino al completamento dei lavori di backup on-premises e di copia di backup nel cloud.
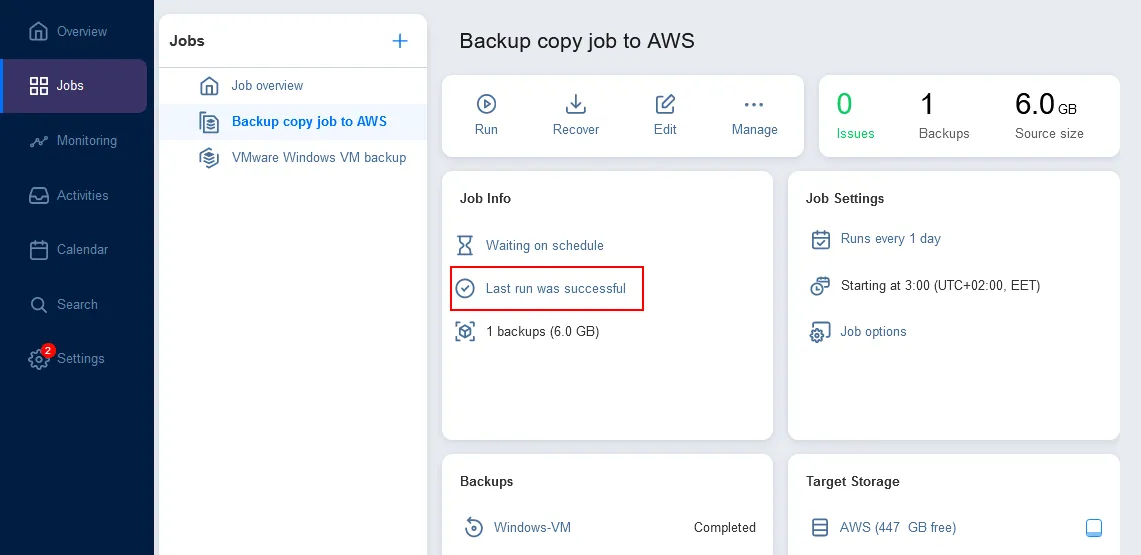
Ora hai due backup in posizioni diverse da utilizzare per il ripristino: backup locale + backup cloud. Un approccio di backup ibrido cloud combina i vantaggi di un accesso rapido e di disponibilità locale con la ridondanza e l’affidabilità dei backup basati su cloud.
Source:
https://www.nakivo.com/blog/hybrid-cloud-backup-implementation-setup/