













La sauvegarde cloud hybride est une stratégie de protection des données qui combine à la fois le stockage sur site et le stockage basé sur le cloud pour les données de sauvegarde. Cette approche se distingue des autres stratégies de sauvegarde en incluant un composant cloud pour améliorer la redondance, la disponibilité, la résilience et l’efficacité des coûts.
Dans cet article, nous ne nous concentrerons pas sur la sauvegarde d’une infrastructure cloud hybride mais plutôt sur la sauvegarde versdes configurations cloud hybrides, y compris les principes de base et la configuration des solutions de protection des données pour s’intégrer aux services cloud.
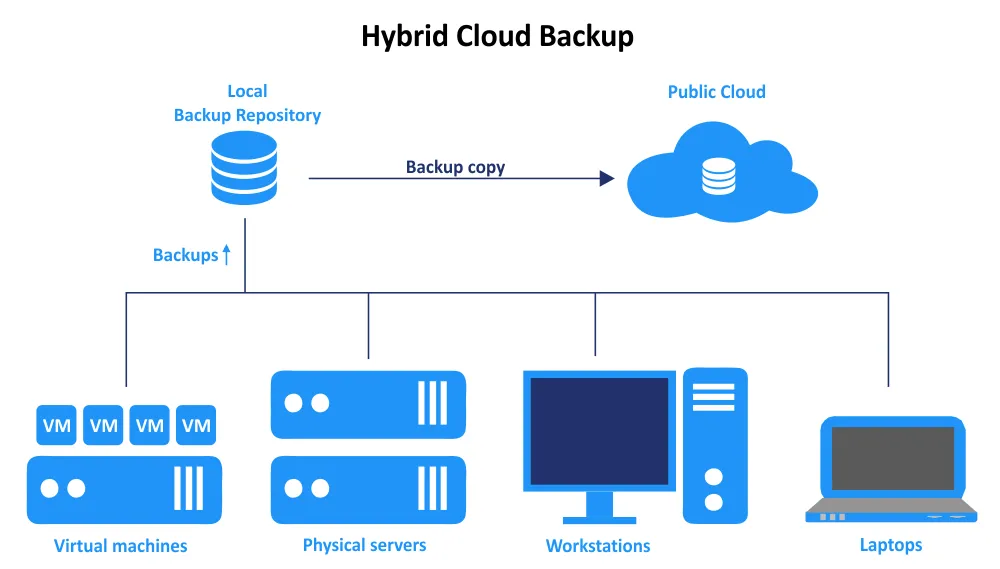
Stratégie de sauvegarde cloud hybride
Examinons maintenant ce que comprend une stratégie cloud hybride pour la sauvegarde et la récupération:
- Sauvegarde locale (infrastructure sur site)
- Une organisation maintient sa propre infrastructure de sauvegarde dans le cadre de son centre de données sur site. Cela inclut des serveurs de sauvegarde, des dispositifs de stockage (par exemple, NAS) ou d’autres appareils.
- Des sauvegardes régulières sont créées à des intervalles spécifiés, capturant les changements de vos données au fil du temps. Des points de récupération fréquents sont créés pour fournir un accès rapide aux données et garantir la continuité opérationnelle.
- Cette infrastructure locale permet des temps de sauvegarde et de récupération plus rapides pour les opérations quotidiennes et convient aux scénarios où un accès immédiat aux données est essentiel et où l’objectif de temps de récupération (RTO) est court.
- Infrastructure basée sur le cloud
- En plus de la configuration sur site, une organisation utilise un fournisseur de services cloud, tel qu’Amazon Web Services (AWS), Microsoft Azure, ou une autre plateforme cloud pour stocker des copies de sauvegarde dans le centre de données distant du fournisseur de services.
- Le stockage cloud offre une redondance externe, ce qui est crucial pour la récupération des données en cas de catastrophes locales, de pannes matérielles ou d’autres problèmes sur site, qui peuvent également rendre les sauvegardes locales indisponibles. Les sauvegardes cloud sont accessibles depuis n’importe quel endroit avec une connexion Internet, permettant la récupération et la restauration des données à distance.
- Les ressources cloud sont également facilement évolutives, permettant à une organisation de s’adapter aux besoins de capacité changeants sans investissements matériels majeurs à l’avance.
- Implémentation
- Un logiciel de gestion des sauvegardes est utilisé pour planifier, gérer et initier les sauvegardes dans les environnements sur site et cloud.
- Initialement, les données des systèmes sur site sont sauvegardées localement, assurant une sauvegarde et une récupération rapides pour les besoins opérationnels.
- Les données de sauvegarde stockées sur site sont ensuite copiées périodiquement vers le stockage cloud, créant des copies redondantes dans l’environnement distant.
- Les organisations établissent des politiques de rétention pour déterminer combien de temps les copies de sauvegarde sont conservées à la fois localement et dans le cloud. Cela aide à gérer les coûts de stockage et les exigences de conformité.
- Données et récupération de machines
- La combinaison des sauvegardes locales et cloud améliore la continuité d’activité et les capacités de récupération après sinistre de votre organisation ainsi que la résilience informatique. En cas de perte de données, de corruption, de défaillance matérielle ou d’autres urgences, vous avez deux options pour la récupération des données : les sauvegardes locales et basées sur le cloud.
- Les sauvegardes locales répondent aux besoins de récupération immédiate, tandis que les sauvegardes cloud constituent un filet de sécurité en cas de catastrophes à plus grande échelle affectant votre environnement sur site.
- Les sauvegardes locales offrent des temps de récupération plus rapides pour les opérations quotidiennes, car les données peuvent être restaurées à partir de l’infrastructure sur site sans avoir besoin d’internet. La vitesse d’un réseau local est également plus rapide que les vitesses d’internet.
- La composante cloud de la sauvegarde cloud hybride sert d’élément crucial dans la planification de la reprise après sinistre, car elle offre une redondance des données dans des emplacements géographiquement séparés. En cas de catastrophe affectant l’infrastructure locale, les organisations peuvent restaurer les données à partir du cloud pour garantir la continuité des activités.
Avantages de la Sauvegarde Cloud Hybride
La sauvegarde cloud hybride offre plusieurs avantages qui en font une stratégie de protection des données convaincante pour les organisations. La résilience opérationnelle accrue résulte de plusieurs facteurs :
- Redondance et reprise après sinistre. La sauvegarde hybride dans le cloud offre une redondance en stockant des données à la fois sur site et dans des environnements cloud. Cette redondance garantit la disponibilité et la récupération des données même en cas de défaillance matérielle, de corruption des données ou de catastrophes locales.
- Flexibilité et évolutivité. La sauvegarde hybride dans le cloud offre une évolutivité en utilisant les ressources cloud pour une capacité de stockage supplémentaire lors des périodes de demande maximale ou lorsque les volumes de données augmentent. Cette évolutivité élimine le besoin de mises à niveau matérielles constantes.
- Accessibilité à distance. Les sauvegardes dans le cloud permettent aux utilisateurs autorisés d’accéder aux données depuis n’importe où avec une connexion internet. Cette accessibilité à distance est cruciale pour les entreprises avec des équipes distantes ou réparties et dans les scénarios de reprise après sinistre.
- Récupération rapide. Les sauvegardes locales permettent une récupération rapide des données pour les opérations courantes, tandis que les sauvegardes dans le cloud offrent une option secondaire pour la reprise après sinistre. Cette combinaison permet aux organisations de répondre à différents objectifs de temps de récupération (RTO) pour différents scénarios.
- Protection hors site. Les sauvegardes dans le cloud offrent une protection hors site, protégeant les données contre les menaces physiques telles que le vol, les inondations, les incendies, les typhons ou autres catastrophes naturelles pouvant affecter l’infrastructure sur site. Le stockage dans le cloud sert de lieu distant pour stocker les données de sauvegarde. En cas de perte de données sur site, de défaillance matérielle ou de catastrophes naturelles, les données stockées dans le cloud restent accessibles et récupérables.
- Améliorations de sécurité. Les fournisseurs de cloud proposent souvent des fonctionnalités avancées en matière de sécurité, de chiffrement et de certifications de conformité. Cela améliore la sécurité des données par rapport aux méthodes de sauvegarde locale traditionnelles qui pourraient manquer de ces mesures. De nombreux fournisseurs de stockage cloud offrent également une immuabilité pour protéger les données stockées dans le cloud contre toute modification, corruption et chiffrement par des logiciels malveillants.
- Mobilité des données et gestion des charges de travail. La sauvegarde cloud hybride permet un déplacement transparent des données entre les environnements sur site et cloud, soutenant des stratégies flexibles de gestion des charges de travail et de migration des données.
- Distribution géographique. Les organisations avec plusieurs sites peuvent gérer les sauvegardes de manière centralisée tout en permettant à différents sites d’accéder aux données depuis le cloud. Cela améliore la disponibilité des données, la collaboration et les capacités de récupération après sinistre. Les fournisseurs de cloud ont souvent des centres de données dans plusieurs régions géographiques. Cette distribution géographique ajoute une couche de redondance supplémentaire, garantissant que les données restent disponibles même si un centre de données rencontre des problèmes.
- Optimisation des coûts. Les organisations peuvent optimiser les coûts en utilisant une infrastructure sur site pour les sauvegardes de routine et en ne recourant aux ressources cloud que lorsque cela est nécessaire. Les ressources cloud utilisent souvent le modèle de paiement à l’usage, réduisant les coûts initiaux d’investissement et de maintenance. La sauvegarde cloud hybride aide à optimiser les coûts en utilisant une infrastructure sur site pour les sauvegardes de routine et les ressources cloud pour une capacité supplémentaire lors de pics de demande ou d’urgences.
Inconvénients de la sauvegarde cloud hybride
- Complexité et surcharge de gestion
- Implémenter et gérer une solution de sauvegarde cloud hybride peut être complexe, nécessitant une expertise dans les technologies sur site et cloud.
- Les administrateurs doivent gérer la synchronisation, le transfert de données et la gestion des politiques de sauvegarde dans différents environnements. Cela peut ajouter des difficultés supplémentaires si plusieurs fournisseurs de cloud public différents sont utilisés.
- Transfert de données et latence
- Transférer de grandes quantités de données entre les locaux et le cloud peut être long et dépendant de la bande passante internet.
- La latence pourrait affecter l’accès aux données et les temps de récupération, en particulier pour les restaurations basées sur le cloud.
- Préoccupations concernant la sécurité des données
- Bien que les fournisseurs de cloud mettent en œuvre des mesures de sécurité avancées, certaines organisations pourraient encore avoir des préoccupations concernant la confiance accordée aux fournisseurs tiers avec des données sensibles.
- Les violations de données ou l’accès non autorisé aux sauvegardes stockées dans le cloud pourraient représenter un risque s’ils ne sont pas correctement gérés.
- L’enfermement par fournisseur.Adopter un fournisseur de cloud spécifique pour les services de sauvegarde pourrait entraîner un enfermement par fournisseur, rendant difficile le changement de fournisseurs ou la migration des données vers un autre environnement.
- Dépendances réseau.La sauvegarde cloud hybride repose fortement sur la connectivité réseau. En cas de problèmes réseau, cela pourrait affecter la capacité à transférer les sauvegardes vers le cloud ou à accéder aux sauvegardes stockées dans le cloud.
- Conformité aux réglementations sur les données.Certains secteurs ont des réglementations strictes en matière de conformité aux données et de résidence des données. S’assurer que les fournisseurs de cloud se conforment à ces réglementations pourrait nécessiter des efforts supplémentaires.
- Contrôle limité sur l’infrastructure cloud.Les services cloud abstraient l’infrastructure sous-jacente, limitant le niveau de contrôle qu’une organisation a sur le matériel et les configurations par rapport aux solutions sur site.
- Dépendance à la récupération des données.Se fier uniquement aux sauvegardes cloud pourrait créer une dépendance aux services externes pour la récupération des données. Si le fournisseur de cloud rencontre des problèmes, la récupération des données pourrait être affectée.
- Propriété et conservation des données.Clarifier les politiques de propriété et de conservation des données lors de l’utilisation de services cloud est important pour garantir que les organisations conservent le contrôle de leurs données.
- Dépendances opérationnelles.Les organisations pourraient devenir opérationnellement dépendantes des services cloud pour la sauvegarde et la récupération. Cette dépendance pourrait poser des défis si le fournisseur de cloud connaît des interruptions.
- Défis initiaux de configuration et de migration.Passer des méthodes de sauvegarde traditionnelles à un modèle de sauvegarde cloud hybride pourrait nécessiter du temps et des ressources pour la configuration, la migration des sauvegardes existantes et la formation des utilisateurs.
- Complexité de la gestion des coûts
- Alors que les ressources cloud peuvent offrir des économies de coûts grâce à des modèles de paiement à l’utilisation, la gestion et la prévision des coûts à la fois sur les environnements locaux et cloud peuvent être difficiles.
- Une mauvaise gestion des coûts pourrait entraîner des dépenses inattendues.
Coûts potentiels du stockage cloud
Les coûts potentiels associés au stockage cloud peuvent être considérés comme un inconvénient de la sauvegarde cloud hybride. Ces coûts peuvent inclure :
- Coûts de stockage. Les fournisseurs de cloud facturent généralement en fonction de la quantité de stockage utilisée. À mesure que les volumes de données augmentent, les coûts de stockage peuvent augmenter. Les organisations doivent estimer avec précision leurs besoins en stockage pour éviter les dépenses inattendues.
- Coûts de transfert de données. Le téléchargement de données vers le cloud et la récupération de données depuis le cloud peuvent entraîner des frais de transfert de données. Ces coûts peuvent s’accumuler, en particulier s’il y a un mouvement fréquent de grandes quantités de données.
- Frais d’accès et de sortie des données. Certains fournisseurs de cloud facturent des frais pour l’accès et la récupération des données. Selon la fréquence des restaurations ou récupérations de données, ces coûts peuvent s’accumuler avec le temps. Frais de sortie. Le déplacement des données hors de l’environnement cloud, surtout s’il s’agit vers un autre fournisseur de cloud ou de retour vers l’infrastructure sur site, peut entraîner des frais de sortie.
- Coûts de redondance et de réplication des données. La réplication des données dans plusieurs régions ou centres de données à des fins de redondance peut entraîner des coûts supplémentaires. Ceci est particulièrement pertinent pour les organisations ayant des exigences élevées en matière de disponibilité des données.
- Frais d’inactivité. Certains fournisseurs de cloud peuvent imposer des frais si les données restent inactives (c’est-à-dire non consultées ou modifiées) pendant des périodes prolongées.
- Variabilité des coûts. Bien que le modèle de paiement à l’utilisation du stockage cloud puisse être rentable, la prévisibilité des coûts peut être préoccupante en raison des fluctuations des besoins de stockage de données et des modèles d’utilisation.
Il est essentiel d’évaluer attentivement ces inconvénients dans le contexte des besoins spécifiques, des objectifs et des ressources de votre organisation. Des stratégies d’atténuation et une planification adéquate peuvent contribuer à relever ces défis et garantir la réussite de la mise en œuvre d’une sauvegarde hybride dans le cloud.
Comment atténuer les problèmes liés aux coûts
Il existe plusieurs mesures que vous pouvez prendre pour atténuer les coûts élevés du stockage cloud dans une configuration de sauvegarde hybride dans le cloud :
- Utilisez une approche de sauvegarde incrémentielle (éventuellement avec des sauvegardes complètes synthétiques périodiques) et des technologies de déduplication.
- Utilisez le cloud comme stockage de sauvegarde secondaire et utilisez des sauvegardes locales comme sauvegardes primaires pour réduire les frais d’accès et de récupération fixés par les fournisseurs de cloud (tels que les frais de sortie). Vous pouvez également choisir des fournisseurs sans frais de sortie, par exemple, Wasabi.
- Choisissez des niveaux de stockage cloud (tels que le stockage standard, l’accès peu fréquent ou le stockage d’archive) qui correspondent aux schémas d’accès de vos données.
- Utilisez des supports plus économiques pour le stockage à long terme et l’archivage, par exemple, des bandes magnétiques.
- Suivez l’utilisation des données et évaluez régulièrement la rentabilité de votre stratégie de stockage.
Types de sauvegarde cloud hybride
La sauvegarde cloud hybride peut englober différentes approches, avec des avantages spécifiques et s’aligner sur différents besoins organisationnels. Le choix du type de sauvegarde dépend de facteurs tels que les objectifs de récupération des données, les besoins de stockage, les considérations budgétaires et l’infrastructure informatique globale. Les principaux types de sauvegarde cloud hybride sont les suivants:
- Sauvegarde locale d’abord + copie de sauvegarde vers le cloud
Les sauvegardes sont d’abord créées en local, sur un stockage sur site. La sauvegarde est ensuite utilisée pour créer une copie de sauvegarde dans le cloud pour une redondance hors site. Cette approche permet une récupération locale rapide et utilise le cloud pour des scénarios de récupération plus graves. Elle minimise également l’impact sur l’environnement de production.
Le calendrier et la politique de rétention des copies de sauvegarde cloud peuvent différer de ceux utilisés pour la sauvegarde locale. De cette manière, le cloud est utilisé pour le tiering, où les points de récupération plus anciens sont déplacés vers le cloud lorsqu’ils sont moins fréquemment consultés. Cette approche optimise les coûts en utilisant le stockage cloud pour les données moins actives tout en conservant les données fréquemment consultées localement pour une récupération rapide.
- Sauvegarde d’abord dans le cloud avec cache local
Dans ce modèle, les sauvegardes sont initialement effectuées directement dans le cloud. Un cache local peut être maintenu pour les données fréquemment consultées, permettant des restaurations plus rapides.
Cette approche est pratique lorsque les besoins de récupération de données sont principalement orientés vers le cloud mais nécessitent un accès local pour des données spécifiques.
- Réplication bidirectionnelle dans le cloud
Les données sont continuellement synchronisées entre l’infrastructure sur site et le cloud. Les modifications apportées dans l’environnement local ou cloud sont répliquées dans l’autre emplacement.
Cette approche est intensive en ressources. Cependant, elle garantit que les données restent cohérentes dans les deux environnements, permettant un accès et une récupération flexibles des données.
- Stockage de sauvegarde à niveaux
Avec cette stratégie, différents niveaux de données sont stockés à des emplacements différents en fonction de la fréquence d’accès. Les données fréquemment consultées peuvent être stockées localement, tandis que les données moins fréquemment consultées sont stockées dans le cloud pour optimiser les coûts.
L’archivage basé sur le cloud consiste à déplacer des données peu consultées ou plus anciennes vers le stockage cloud pour libérer de l’espace dans vos systèmes de stockage sur site. Les données archivées sont conservées à des fins de stockage à long terme et de conformité, mais elles sont moins accessibles par rapport aux données fréquemment utilisées.
- Rotation des sauvegardes et gestion du cycle de vie
Cette approche implique de faire tourner les copies de sauvegarde entre des environnements locaux et cloud en fonction des politiques de rétention. Les sauvegardes plus anciennes peuvent être déplacées vers le cloud pour une conservation à long terme, tandis que les sauvegardes récentes sont conservées localement pour des restaurations plus rapides.
- La récupération après sinistre basée sur le cloud
Le cloud est principalement utilisé à des fins de récupération après sinistre. En stockant des copies de sauvegarde et des images de machine virtuelle dans le cloud, vous pouvez récupérer rapidement des systèmes entiers en cas de sinistre affectant l’environnement local, y compris l’infrastructure de sauvegarde locale.
- Appareils de sauvegarde hybrides
Les appareils hybrides combinent du matériel de sauvegarde local avec une intégration cloud. Ces appareils gèrent la déduplication des données, le chiffrement et la synchronisation entre les sauvegardes locales et cloud.
Ces concepts mettent en évidence les différentes façons dont les organisations peuvent utiliser à la fois le stockage sur site et le cloud pour garantir la protection des données, la récupération après sinistre, l’optimisation des coûts et la gestion efficace des données. L’approche d’une organisation dépend de plusieurs facteurs, tels que les politiques de rétention des données, les objectifs de temps de récupération, les modèles d’accès aux données et les considérations budgétaires.
Mise en place de la sauvegarde cloud hybride avec NAKIVO
NAKIVO Backup & Replication est une solution de protection des données conçue pour différentes infrastructures :
- Sur site, que ce soit des serveurs physiques ou virtualisés
- Cloud, y compris les configurations multi-cloud
- Cloud hybride
La solution prend en charge la sauvegarde des charges de travail dans les datacenters locaux et dans le cloud, ainsi que la sauvegarde vers les datacenters locaux et les clouds publics/privés. La solution NAKIVO offre un moyen pratique d’implémenter une stratégie de sauvegarde cloud hybride en créant une sauvegarde locale, puis en créant un travail de sauvegarde vers un stockage cloud. De plus, ces travaux peuvent être automatisés pour s’exécuter l’un après l’autre avec la fonctionnalité Chaînage de travaux. Découvrons comment configurer une sauvegarde cloud hybride avec NAKIVO Backup & Replication.
Ajout d’éléments à l’inventaire
Vous pouvez ajouter à la fois les plateformes locales et cloud à l’inventaire de la solution NAKIVO pour commencer à les protéger. Vous devez également ajouter le stockage cloud de destination à l’inventaire.
Pour ajouter des éléments à l’inventaire:
- Allez dans Paramètres > Inventaire et cliquez sur l’icône +.
- Sélectionnez la plateforme nécessaire et terminez le Assistant Ajout d’un élément à l’inventaire.
Lisez l’explication détaillée sur l’ajout de différents éléments à l’inventaire.
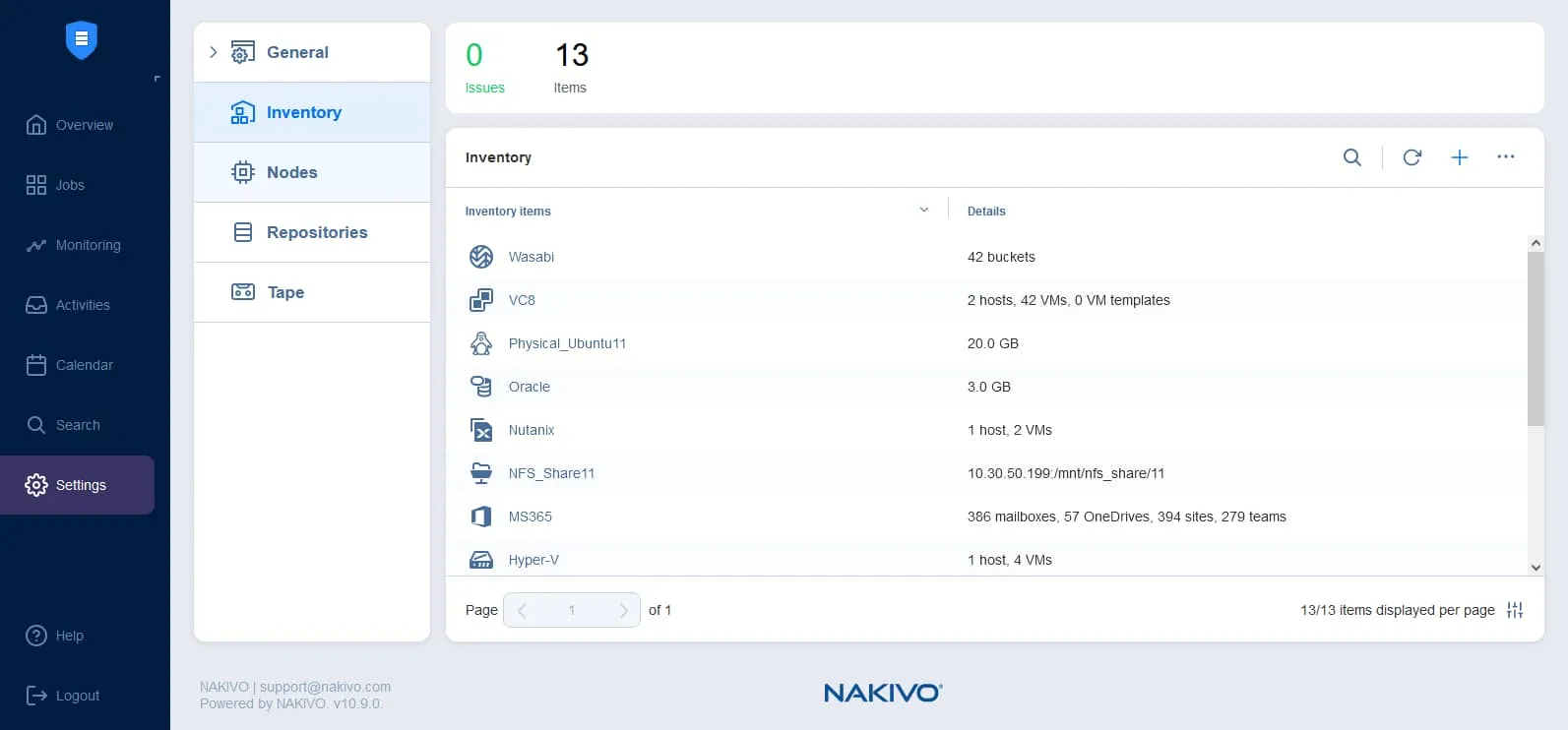
Dans notre exemple, nous ajoutons des hôtes ESXi, qui font partie de VMware vSphere, en tant que plateforme source ainsi qu’un stockage Amazon S3 pour créer une copie de sauvegarde dans le cloud.
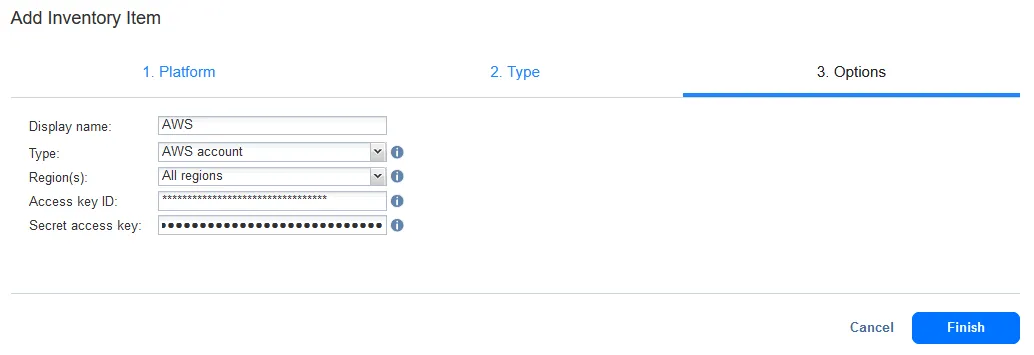
Pour ajouter Amazon S3 ou une autre destination cloud :
- Sélectionnez Stockage au premier étape du Ajouter un élément d’inventaire assistant pour ajouter un stockage cloud.
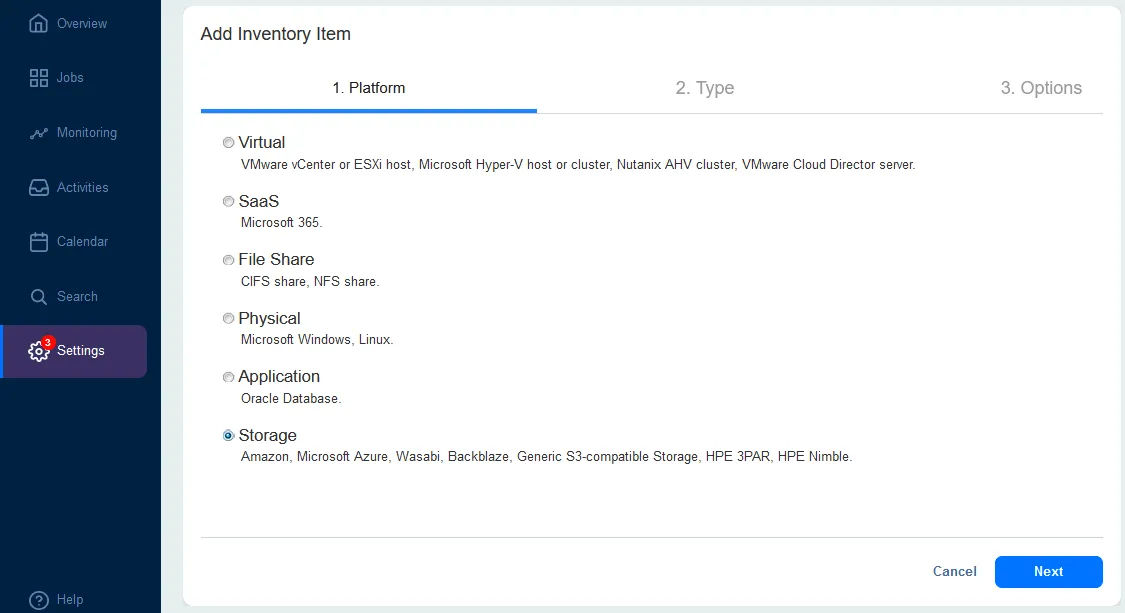
- Pour Type, sélectionnez Amazon S3 ou une autre plateforme cloud. Vous pouvez ajouter un des comptes de stockage cloud pris en charge :
- Amazon S3
- Générique stockage d’objets compatible S3 dans le cloud
- Microsoft Azure Storage
- Wasabi
- BackBlaze B2
- Pour Options, entrez les options de connexion nécessaires.
Création d’un dépôt sur site
Créez un dépôt de sauvegarde dans votre infrastructure locale ou utilisez le Dépôt de sauvegarde embarqué. Allez dans Paramètres > Dépôts et cliquez sur + pour créer un nouveau dépôt de sauvegarde.

Vous pouvez créer un référentiel de sauvegarde en utilisant un dossier local sur une machine équipée d’un Transporter, qui peut être un périphérique NAS ou un appareil de déduplication. Vous pouvez également utiliser des emplacements de référentiel alternatifs dans l’infrastructure sur site et créer un référentiel de sauvegarde sur un partage SMB ou NFS.
Suivez les étapes de l’assistant pour terminer la création d’un référentiel de sauvegarde du type approprié. Vous pouvez activer le chiffrement des données lors de la création d’un référentiel de sauvegarde.
Création d’un référentiel dans un cloud public
Créez un référentiel de sauvegarde dans le cloud. Accédez à Paramètres > Référentiels et cliquez sur + pour créer un nouveau référentiel de sauvegarde. Suivez les instructions pour créer un référentiel de sauvegarde dans le cloud public:
- Créer un dépôt dans Amazon S3
- Créer un dépôt dans le stockage Blob Azure
- Créer un dépôt dans Amazon EC2
- Créer un dépôt dans stockage cloud BackBlaze B2
- Créer un dépôt dans stockage cloud Wasabi Hot
Comme nous utilisons Amazon S3 dans cet exemple, nous sélectionnons Stockage Cloud & S3-Compatible comme type de dépôt, puis Amazon S3 dans l’assistant Créer un dépôt de sauvegarde.
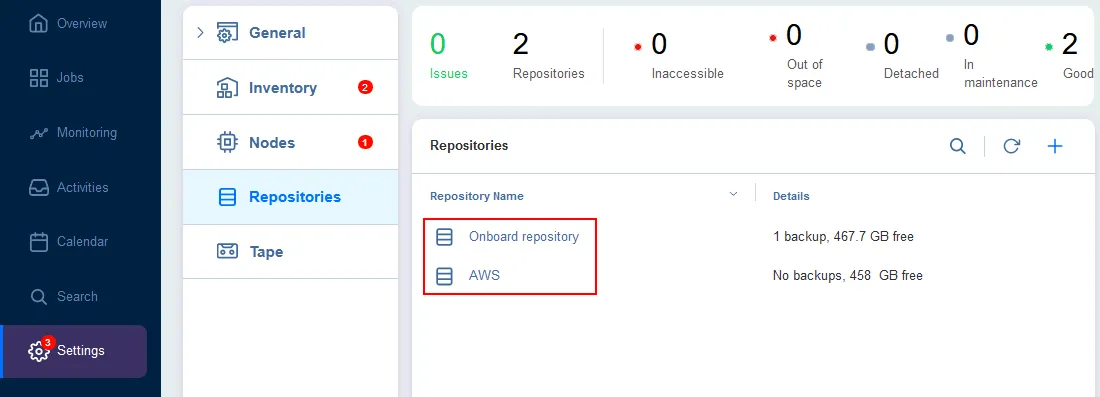
Vous devez avoir au moins un dépôt de sauvegarde sur site, puis créer un dépôt de sauvegarde dans un cloud public. Nos dépôts de sauvegarde sont affichés dans l’image ci-dessous. Vous pouvez avoir plus d’un dépôt sur site et dans le cloud public pour une plus grande flexibilité et scalabilité.
Configuration d’une tâche de sauvegarde locale
Dans notre exemple, nous créons 2 tâches de sauvegarde : une tâche de sauvegarde vers un stockage local pour une récupération opérationnelle rapide et une tâche de copie de sauvegarde vers un bucket Amazon S3 à utiliser lorsque notre infrastructure de sauvegarde locale n’est pas disponible.
Configurons une tâche de sauvegarde pour la sauvegarde de données vers le référentiel de sauvegarde local.
Cliquez sur Jobs dans le panneau de gauche, cliquez sur + et appuyez sur Sauvegarde VMware vSphere ou autre type de tâche de sauvegarde, en fonction de ce que vous souhaitez sauvegarder.
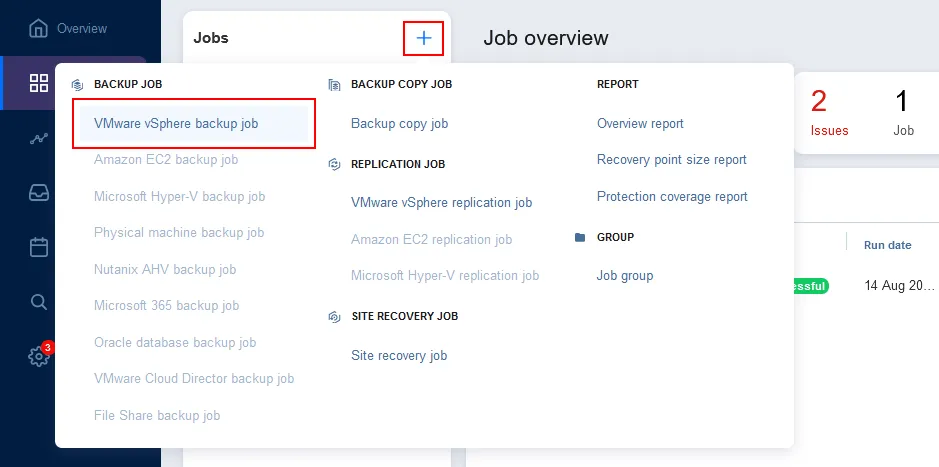
Suivez les instructions pour créer une nouvelle tâche de sauvegarde pour la source de données appropriée.
Comme nous sauvegardons des machines virtuelles VMware dans ce didacticiel, nous suivons les instructions pour créer une tâche de sauvegarde VMware vSphere. Vous devez terminer l’assistant pour créer une tâche de sauvegarde :
- Source. Sélectionnez les éléments que vous souhaitez sauvegarder. Nous sélectionnons une VM Windows hébergée sur un hôte ESXi.
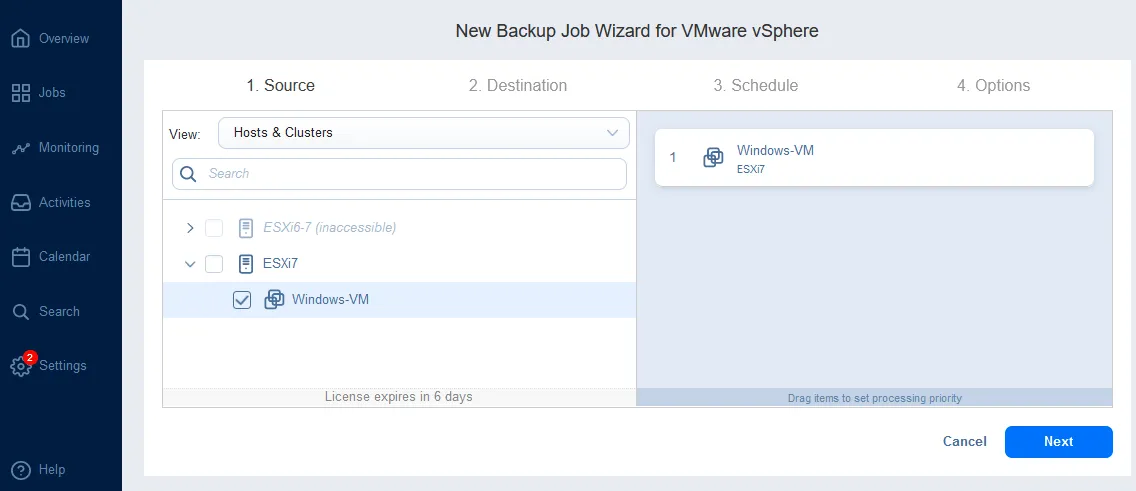
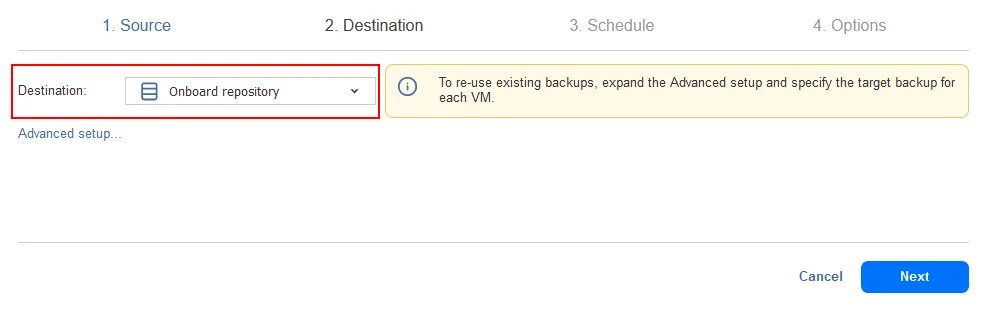
- Destination. Sélectionnez l’un des dépôts de sauvegarde que vous avez déployés sur site. Nous utilisons le dépôt embarqué situé sur l’ordinateur local où NAKIVO Backup & Replication (solution complète) est installé comme dépôt principal.
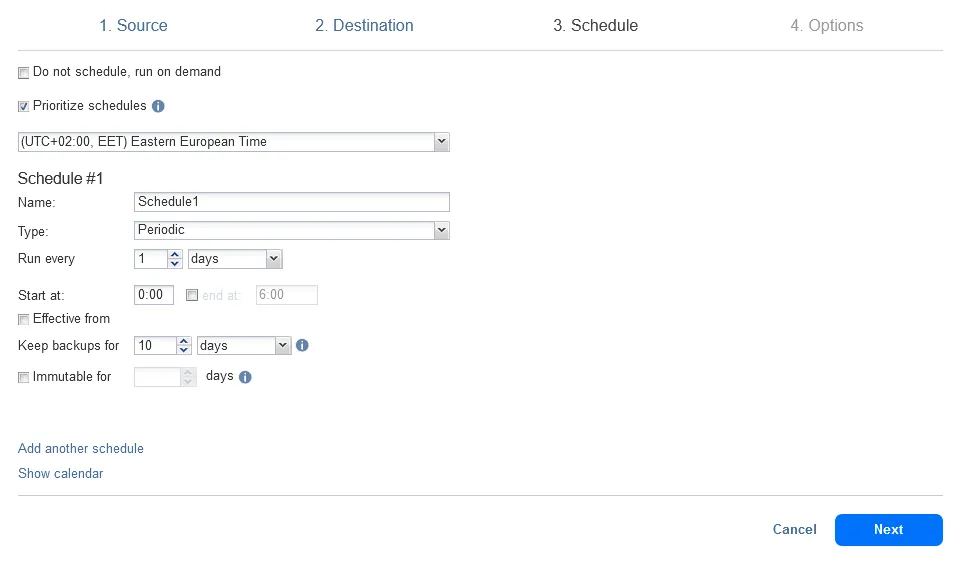
- Planification. Définissez l’horaire d’une tâche de sauvegarde pour déterminer quand sauvegarder les données vers le dépôt de sauvegarde sur site. Nous configurons une tâche de sauvegarde pour être exécutée chaque jour à 00h00. Vous pouvez configurer plusieurs règles de planification et de rétention à ce stade.
- Options. Entrez un nom de travail de sauvegarde et configurez d’autres options de travail de sauvegarde. Par exemple, vous pouvez activer le chiffrement réseau pour protéger les données en vol, utiliser l’accélération réseau, exclure les fichiers de swap, les partitions et les blocs inutilisés pour accélérer les transferts de données, etc. Terminez l’assistant.
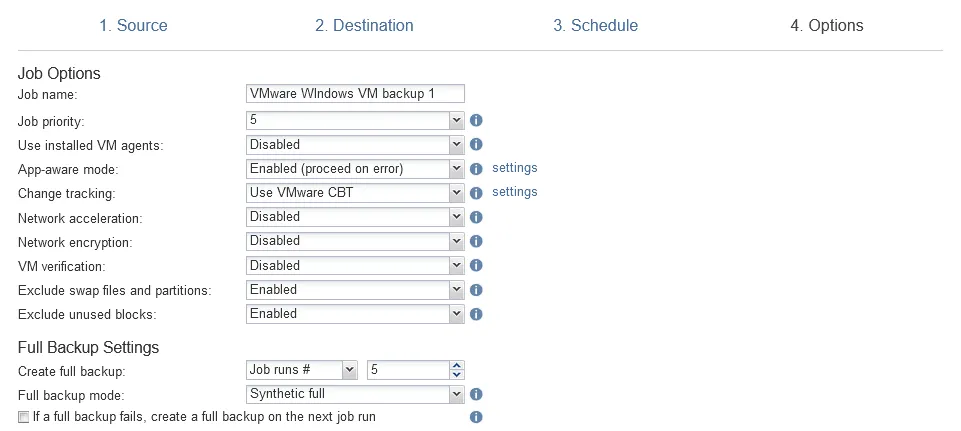
Configuration d’un travail de copie de sauvegarde vers le cloud
Configurez copie de sauvegarde vers le cloud pour une configuration de sauvegarde hybride cloud.
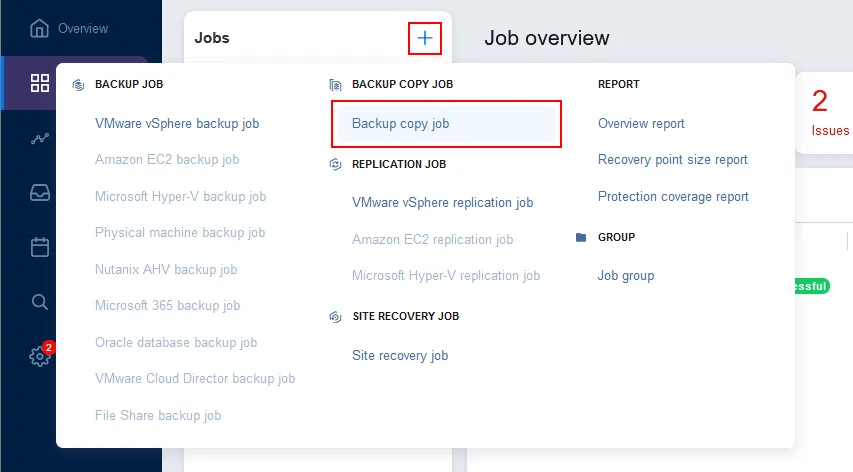
Cliquez sur Jobs dans le volet gauche, appuyez sur + et cliquez sur Backup copy job dans le menu qui s’ouvre. L’assistant New Backup Copy Job Wizard s’ouvre.
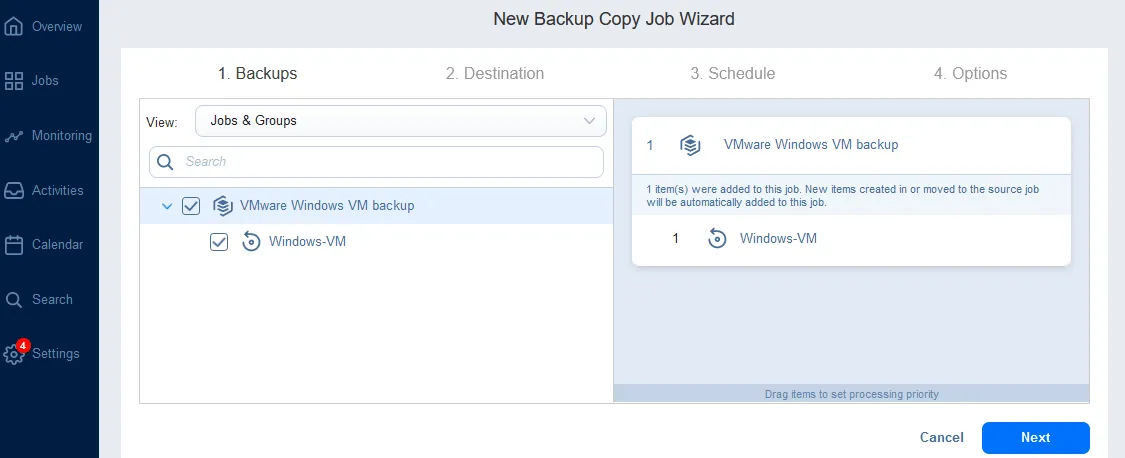
- Sauvegardes. Sélectionnez le travail de sauvegarde que vous avez créé et exécuté précédemment. Dans notre cas, nous sélectionnons le VMware Windows VM backup job avec toutes les sauvegardes de VM créées par ce job.
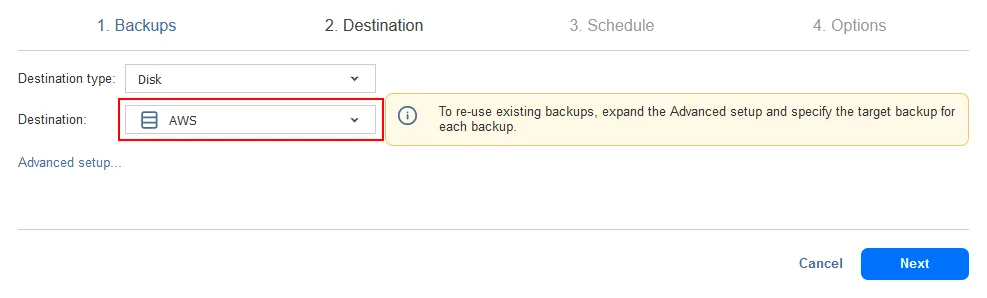
- Destination. Sélectionnez le dépôt de sauvegarde que vous avez créé dans le cloud public. Dans notre cas, nous sélectionnons le dépôt de sauvegarde S3 en tant que destination.
- Planification. Configurez une planification et une politique de rétention pour la tâche de copie de sauvegarde. Comme nous avons configuré la sauvegarde sur site pour être exécutée chaque jour à 0h00, nous configurons la copie de sauvegarde vers le cloud pour être lancée chaque jour à 3h00. Notre VM n’est pas grande et la tâche de sauvegarde sur site devrait être terminée à 3h00. Sinon, vous pouvez utiliser Chaînage de tâches pour que la tâche de copie de sauvegarde soit lancée automatiquement après une sauvegarde réussie.
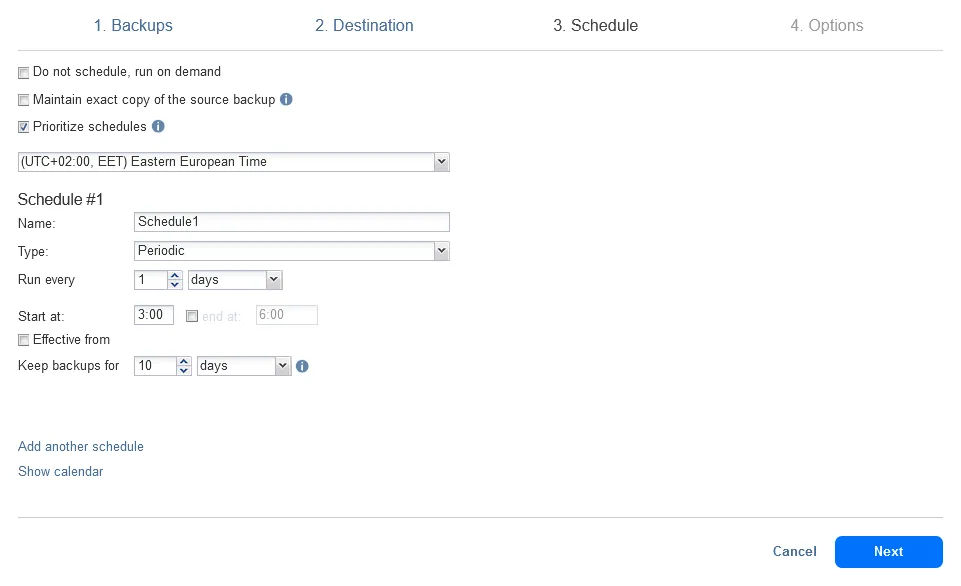
- Options. Entrez un nom pour la tâche de copie de sauvegarde, sélectionnez les options nécessaires, telles que l’accélération réseau ou le chiffrement réseau, et cliquez sur Terminer ou Terminer et exécuter.
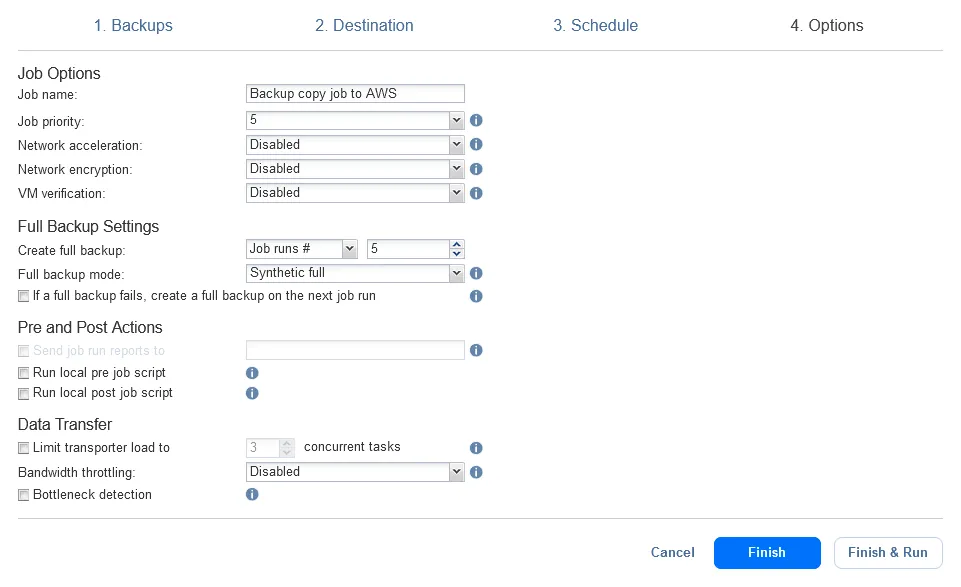
Nous avons configuré la sauvegarde hybride dans NAKIVO Backup & Replication. Attendez que les tâches de sauvegarde sur site et de copie de sauvegarde vers le cloud soient terminées.
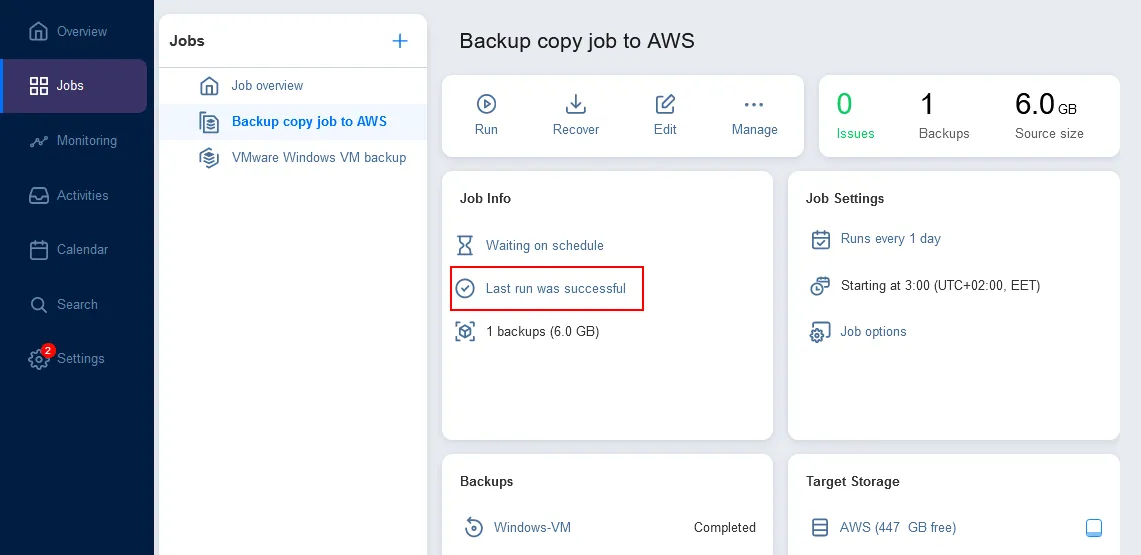
Maintenant, vous disposez de deux sauvegardes dans des emplacements différents à utiliser pour la récupération : la sauvegarde locale + la sauvegarde dans le cloud. Une approche de sauvegarde hybride dans le cloud combine les avantages d’un accès rapide et d’une disponibilité locale avec la redondance et la fiabilité des sauvegardes basées dans le cloud.
Source:
https://www.nakivo.com/blog/hybrid-cloud-backup-implementation-setup/