













ביום 11 בדצמבר 2024, שירותי OpenAI חוו השבתה משמעותית בשל בעיה שנבעה מהשקת שירות טלמטריה חדש. אירוע זה השפיע על שירותי API, ChatGPT וסורה, מה שגרם להפרעות בשירות שנמשכו מספר שעות. כחברה השואפת לספק פתרונות AI מדויקים ויעילים, OpenAI שיתפה דוח מפורט על האירוע כדי לדון בשקיפות מה השתבש וכיצד הם מתכננים למנוע הישנות מקרים דומים בעתיד.
במאמר זה, אני אציין את ההיבטים הטכניים של האירוע, אנתח את הסיבות השורשיות ואחקור את הלקחים המרכזיים שמהם יכולים ללמוד מפתחים וארגונים המנהלים מערכות מבוזרות.
ציר זמן האירוע
הנה תמונה של איך האירועים התפתחו ביום 11 בדצמבר 2024:
| Time (PST) | Event |
|---|---|
| 15:16 |
השפעה מינורית על לקוחות החלה; נצפתה ירידת שירות |
| 15:27 | מהנדסים החלו להפנות תנועה מקלאסטרים שנפגעו |
| 15:40 | השפעה מקסימלית על לקוחות תועדה; השבתות משמעותיות בכל השירותים |
| 16:36 | הקלאסטר הראשון של Kubernetes החל בשיקום |
| 17:36 | שיקום משמעותי עבור שירותי API החל |
| 17:45 | שיקום משמעותי עבור ChatGPT נצפה |
| 19:38 | כל השירותים חזרו לפעולה מלאה בכל הקלאסטרים |
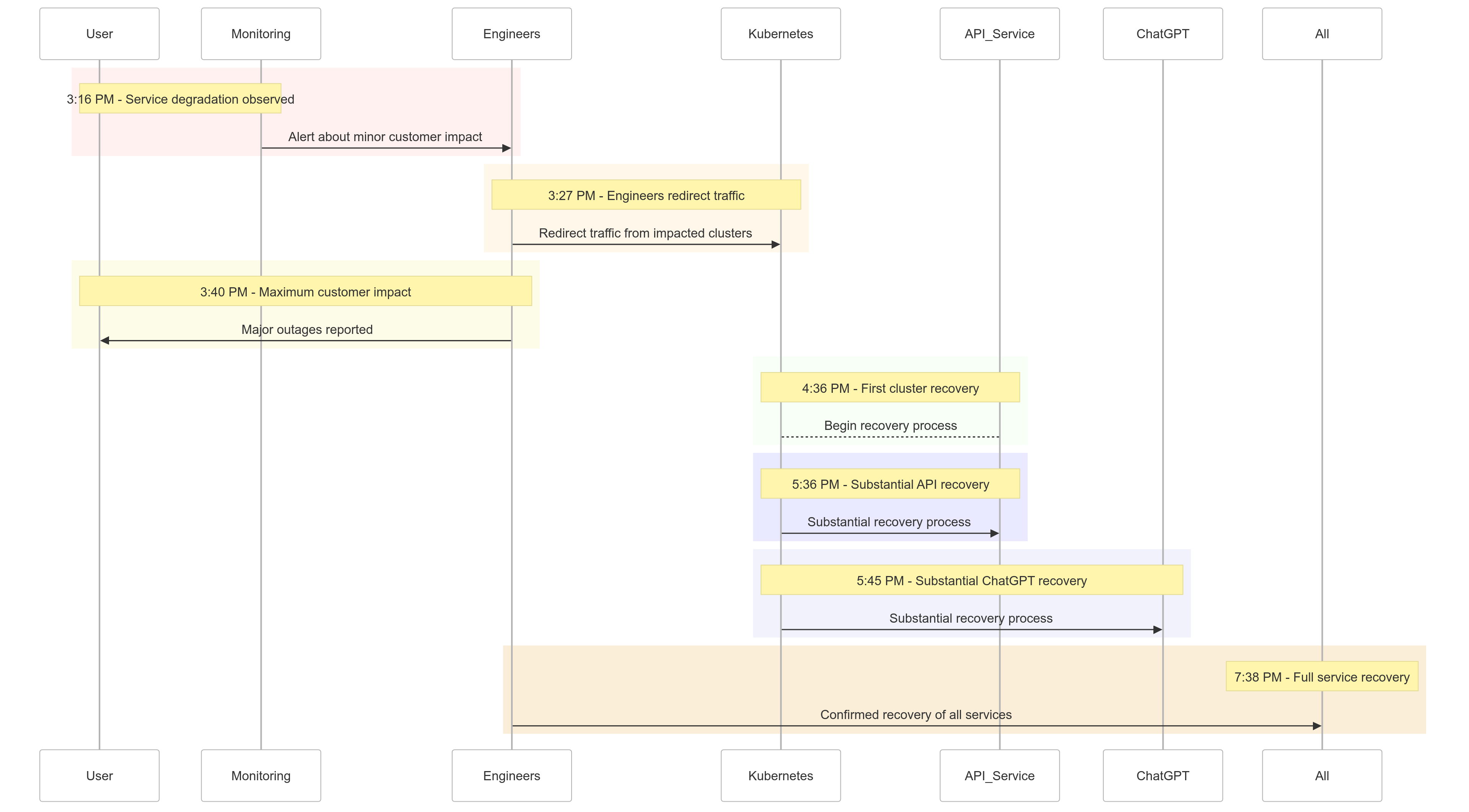
איור 1: ציר זמן של תקרית OpenAI – ירידת שירות לשיקום מלא.
ניתוח סיבת השורש
שורש התקרית היה שירות טלמטריה חדש שהושק בשעה 3:12 PM PST כדי לשפר את הנראות של מישורי הבקרה של Kubernetes. שירות זה, בטעות, העמיס על שרתי ה-API של Kubernetes במגוון אשכולות, מה שהוביל לכישלונות מתמשכים.
פירוק הבעיה
הפצת שירות טלמטריה
שירות הטלמטריה עוצב לאסוף מדדים מפורטים של מישורי הבקרה של Kubernetes, אך ההגדרה שלו גרמה בטעות להפעלת פעולות API אינטנסיביות במשאבים על פני אלפי צמתים בו זמנית.
העמסה על מישור הבקרה
המישור הבקרה של Kubernetes, האחראי על ניהול האשכול, הפך להעמוס. בעוד שמישור הנתונים (המטפל בבקשות משתמשים) נותר פועל חלקית, הוא התבסס על מישור הבקרה עבור פתרון DNS. כאשר רשומות ה-DNS השמורות פגו, שירותים שתלויים בפתרון DNS בזמן אמת החלו למעוד.
בדיקות לא מספקות
ההפצה נבדקה בסביבה של שלב הבדיקה, אך אשכולות הבדיקה לא שיקפו את גודל אשכולות הייצור. כתוצאה מכך, בעיית העומס על שרת ה-API לא זוהתה במהלך הבדיקות.
איך הבעיה הוקלה
כאשר האירוע החל, מהנדסי OpenAI זיהו במהירות את הסיבה השורשית אך נתקלו באתגרים ביישום תיקון משום שהמטוס של Kubernetes היה על עומס וזה מנע גישה ל-שרתים API. אומצה גישה מרובת מישורים:
- הקטנת גודל הקלאסטר: הפחתת מספר הצמתים בכל קלאסטר צמצמה את העומס על שרת ה-API.
- חסימת גישה לרשת ל-API של מנהלי Kubernetes: מנעה בקשות API נוספות, מה שאיפשר לשרתים להתאושש.
- הגדלת שרתי ה-API של Kubernetes: הקצאת משאבים נוספים עזרה לנקות בקשות ממתינות.
צעדים אלה אפשרו למהנדסים לשוב לגישה למטוסים ולסלק את שירות הטלמטריה הבעייתי, והחזירו את הפונקציונליות של השירות.
לקחים שנלמדו
אירוע זה מדגיש את הקריטיות של בדיקות חזקות, ניטור ומנגנוני כשל בטוחים במערכות מפוזרות. הנה מה שלמדו (ויישמו) ב-OpenAI מהפסקת השירות:
1. השקות בשלביות חזקות
כל שינוי תשתיתי יעקוב עכשיו אחרי השקות בשלביות עם ניטור רציף. זה מבטיח שעניינים יזוהו בשלב מוקדם ויופחתו לפני שתהיה הגדלה לכל הצי.
2. בדיקות הזרקת תקלות
על ידי סימולציה של תקלות (למשל, השבתת המטוס או השקת שינויים רעים), OpenAI תוודא שמערכותיה יכולות להתאושש אוטומטית ולזהות בעיות לפני השפעה על לקוחות.
3. גישה למטוס הבקרה החירום
מנגנון "שבר זכוכית" יבטיח מהנדסים יכולים לגשת לשרתים של API של קוברנטיס גם תחת עומס כבד.
4. פיצול בין מטוסי הבקרה והנתונים
כדי להפחית תלות, OpenAI תפריד בין מטוס הנתונים של קוברנטיס (הטיפול בעומסים) לבין מטוס הבקרה (האחראי על אורקסטרציה), תוך כדי הבטחת שהשירותים הקריטיים יכולים להמשיך לפעול גם במהלך בעיות במטוס הבקרה.
5. מנגנוני התאוששות מהירים
אסטרטגיות חדשות לאחסון ולמגבלת קצב ישפרו את זמני ההפעלה של הקלאסטר, מה שיבטיח התאוששות מהירה במהלך כשלים.
קוד לדוגמה: דוגמת פריסה מדורגת
הנה דוגמה ליישום פריסה מדורגת עבור קוברנטיס באמצעות הלם ופרומתאוס לצפייה.
פריסת הלם עם פריסות מדורגות:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
שאילתת פרומתאוס לניטור עומס שרת API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
שאילתה זו מסייעת לעקוב אחר זמני התגובה לבקשות שרת API, מה שמבטיח זיהוי מוקדם של שיאים בעומס.
דוגמת הזרקת תקלות
באמצעות chaos-mesh, OpenAI יכולה לדמות כשלים במטוס הבקרה של קוברנטיס.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
הגדרה זו הורגת בכוונה פוד של שרת API כדי לאמת את עמידות המערכת.
מה זה אומר עבורך
האירוע הזה מדגיש את חשיבות עיצוב מערכות עמידות ואימוץ מתודולוגיות בדיקה נחושות. בין אם אתה ניהול מערכות מבוזרות בקנה מידה או מיישם Kubernetes עבור עומס העבודה שלך, הנה כמה לקחים:
- הדמיה שגיאות באופן קבוע: השתמש בכלים להנדסת כאוס כמו Chaos Mesh כדי לבדוק את עמידת המערכת בתנאים ממשיים.
- ניטור ברמות מרובות: וודא שמערכת הניטור שלך מעקבת אחר מדדים ברמת השירות ומדדי בריאות הקינון.
- נתח את תלות עצמית בעיקריות: צמצם את ההתלות בנקודות כשל, כמו גילוי שירות מבוסס DNS.
מסקנה
אמנם שאין מערכת שאינה חושפת לכשלים, אירועים כמו זה מזכירים לנו על ערך של שקיפות, תיקון מהיר ולמידה מתמדת. הגישה הפרואקטיבית של OpenAI לשיתוף פוסט-מורטם זה מספקת שיטת בנייה לארגונים אחרים לשפר את הפרקטיקות התפעוליות והאמינות שלהם.
על ידי העדפת השקת גרסאות בשלבים עמידים, בדיקת הזרקת תקלות ועיצוב מערכת עמידה, OpenAI קובעת דוגמה חזקה לכיצד לטפל וללמוד מכשלים בגדלים גדולים.
עבור צוותים שמנהלים מערכות מבוזרות, האירוע הזה הוא ניתוח מקרה נהדר של כיצד לגשת לניהול סיכונים ולמזער את זמן העצירה עבור תהליכי עסק עיקריים.
בואו נשתמש בזה כהזדמנות לבנות מערכות טובות יותר ועמידות יחד.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident