













מביא
במדעי המידע ובעיקר בעיבוד השפה הטבעית, סיכום הוא ותמיד היה נושא של עניין מאד חזק. למרוצת הזמן, היו לנו שיטות סיכום טקסט אבל השנים האחרונות ראו פיתוחים משמעותיים בעיבוד השפה הטבעית ובלמידת עומדים. יש עכשיו ערימה של מאמרים שמפרסמים על הנושא על ידי גדולי האינטרנט כמו האחרונים ChatGPT. למרוצת הזמן, הרבה עבודה נעשתה בנושא המחקר הזה, אך מעט מאוד נכתב על יישומים מעשיים של סיכום נועד על ידי מערכות בעלות AI. הקשר בין ההצהרות הרחבות והניפות היא מאבק לשיווק סיכום יעיל.
סיכום של מאמר חדשות ודוח רווחות פיננסיים הם שני משימות שונות. כשמטילים יד על תכונות טקסט שמשתנות באורך או נושא (טכנולוגיה, ספורט, פיננסים, דרך, וכן הלאה), המשימה של סיכום נעשה למשימה מדעית מאתגרת. חשוב לעסוק ראשון בתאוריית סיכום לפני שינוי לסקירה של יישומים.
סיכום מוצק
תהליך הסיכום המוצלח מערבה בעיקרן במשפטים המרכזיים ביותר ממאמר ומארגן אותם באופן שיטתי. המשפטים המרכזיים בסיכום נלקחים בעצם מהמקור המקורי.
מערכות סיכום מוצלח כפי שאנו מכירים אותן עכשיו, מסתדרות סביב שלושה פעולות בסיסיות:
בניית ייצוג בינייני לטקסט הקדמי
ייצוגים של נושא וייצוגים של סימן הם דוגמאות לשיטות העלויות על ידי ייצוג. כדי להבין את הנושא(ים) המצוטערים בטקסט, ייצוג הנושא ממהלך את הטקסט לייצוג בינייני.
עריכת הציונים עבור המשפטים על פי הייצוג
בזמן יצירת הייצוג הבינייני, לכל משפט נתנה ציון חשובות. בשימוש בשיטה שתלויה בייצוג הנושא, ציון משפט משקף את יכולת המשפט להבין את הרעיונות המרכזיים בטקסט. בייצוג הסימנים, הציון מוערך על-ידי הצטברות הועדה מסיבות משונות במשקל.
בחירת סיכום הכוללת מספר משפטים
כדי ליצור סיכום, תוכנה הסיכום בוחרת את המשפטים העליונים בסדר המשפטים. לדוגמה, חלק השיטות משתמשים באלגוריתמים הגדילים כדי לבחור ולהחליט אילו משפטים הם הכי רלוונטיים, בעוד אחרות יכולות להמיר את בחירת המשפטים לבעיית ההתאמה המיטבית, בה מערכת של משפטים נבחרת על ידי הדרישה שהיא תגביר את החשיבות הכללית ואת ההתאמה בזמן שתמיד את המידה של המידע החדרני.
בואו נעדר לעומק בשיטות שאמרנו:
גישות לייצוג נושאים
מילים נושא: באמצעות השיטה הזו, ניתן למצוא מילים שקשורות לנושא במסמך הקבלה. החשיבות של משפט יכולה להיות מוערכת בשתי דרכים: ראשונה, כפונקציה של מספר חתימות נושא שהוא מכיל; שנית, כשליש של החתימות הנושאיות שהוא מכיל.
בעוד שהשיטה הראשונה נותנת ציונים גבוהים למשפטים הארוכים יותר עם מילים יותר, השיטה השניה מודדת את הדחיסות של המילים הנושאיות.
גישות מונעות על-ידי תדירות: דרך השיטה הזו, מועדים לתוך חשיבות יחסית מילים. אם המונח מתאים לנושא, הוא מקבל ניקוד אחד; אחרת, הוא מגיע לאפס. תלוי באופן בו הם מובנים, המשקלים עשויים להיות מתמשכים. ייצוגים של נושאים יכולים להיות מושגים באמצעות אחת משתי שיטות:
סבירות מילים: היא משתמשת רק בתדירות המילים כדי להצביע על החשיבות שלהן. כדי לחשב את סבירות המילה w, אנחנו מחלקים את תדירות המילה שלה, f (w), על סך כל המילים, N.
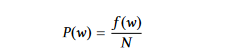
החשיבות הממוצעת של המילים במשפט נותנת את החשיבות של המשפט בשימוש בסבירות המילים.
TFIDF (תדירות מושג בהתיחסות לתדירות המילים הפוכה). השיטה הזו היא שיפור על גישת סבירות המילים. כאן, המשקלים מוגדרים בעזרת הגישה TF-IDF. טכניקת תדירות המושג בהתיחסות לתדירות המילים הפוכה (TFIDF) נותנת פחות חשיבות למושגים שמופיעים ברוב המסמכים. משקל כל מילה w במסמך d מווישך כך:
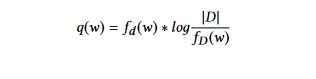
היכן שfd (w)היא תדירות המילה w במסמך d,fD (w) היא מספר המסמכים שמכילים את המילה w, ו |D| היא מספר המסמכים באוסף D.
ניתוח השמנים הנסתרים: ניתוח השמנים הנסתרים (LSA) הוא שיטה אינטראקציבית להוצאת ייצוג של הסמנטיקה של טקסט על בסיס מילים נראות. תהליך LSA מתחיל בבניית מטבלת מילים-משפטים (n על ידי x m), בה כל שורה מייצגת מילה מהקלט (n מילים), וכל עמודה מייצגת משפט (m משפטים). במטבלה, המשקל של המילה i במשפט j מוגדר על-ידי המידע aij. לפי טכניקת TFIDF, לכל מילה במשפט נתנה משקל מסויים, עם אפס שניתן למוליכים למונחים שאינם במשפט.
דרכים של ייצוג מסגרתי
שיטות מבוססות גרף
גרף שיטות, שנותנות השפעה מאלגוריתם PageRank, מייצגות המסמכים בגרף מחובר. משפטים מייצגים את הצלעות של הגרף, והקישורים שבין המשפטים מראים את מידת הקשר בין שתי משפטים. שיטה אחת שנעדרת להיות בשימוש כדי לקשר שתי צלעות היא להעריך את הדומיניסטיביות בין שתי משפטים, ואם הדומיניסטיביות גבוהה מסכם מסויים, הצלעות נקשרות. שני תוצאות אפשריות קיימות עם הייצוג הגרף הזה. ראשית, החלקים של הגרף (סב-גרפים) מגדירים קטגוריות יחידות של מידע שמתוארות על ידי המסמכים. התוצאה השנייה היא שמספרים מפורטים במסמכים נראות בבירור. משפטים שמקושרים להרבה משפטים אחרים בחלק הסב-גרף יכולים להיות המרכז של הגרף וסביר יותר שהם יוכלו להיות כוללים בסיכם. שיטות מקושרות בגרף מועילות גם לסיכום ספרות ולסיכום מספרים מסויימים.
למידת מכונה
שיטות למידת מכונה מתייחסות לבעיית הסיכום בעיניים של משימה קלASSIfICATION. מודלים מנסים לקטגורגות משפטים לקטגוריות סיכום ולא סיכום בהתבסס על מאפייניהם. יש לנו מערך הכשרה שמורכב ממסמכים וסיכומים מבקרים אנושיים שממנו אנחנו מאמנים את האלגוריתמים שלנו. זה בד "" כ עושה בעזרת נאיבס בייז, עץ החלטות, או מכונת
סיכוי סיכויים
בניגוד לסיכויים, סיכוי סיכויים הוא שיטה יעילה יותר.היכולת ליצור משפטים ייחודיים שמעבירים מידע חשוב ממקורות טקסטיים סייעה לתחילת הפיכה הזו.
סיכות סיכויים מציגה את החומר בצורה הגיונית, מאורגנת טוב ובעלת איכות שפה מושלמת. איכות סיכות יכולה להיעלות באמצעות הפיכתה ליותר קריאה או שיפור איכותה השפתית. (כולל תמונה).
יש שני גישות: גישת המבנה המודלי והגישה הסמנטית.
גישה מבנה-מודלית
בגישה המבנה הראשונית, המידע החשוב מהמסמך(ם) מוקפד בעזרת סקים פסיכולוגיים כמו תבניות, חוקי הניצול, ומבנים חלופיים, כולל עץ, אונטולוגיה, שורות ראשים וגוף, חוקים, ומבנה גרף. בחלק הבא, נקרא על חלק מהשיטות המאוחדות בהגישה הזו.
שיטות מבוססות עץ
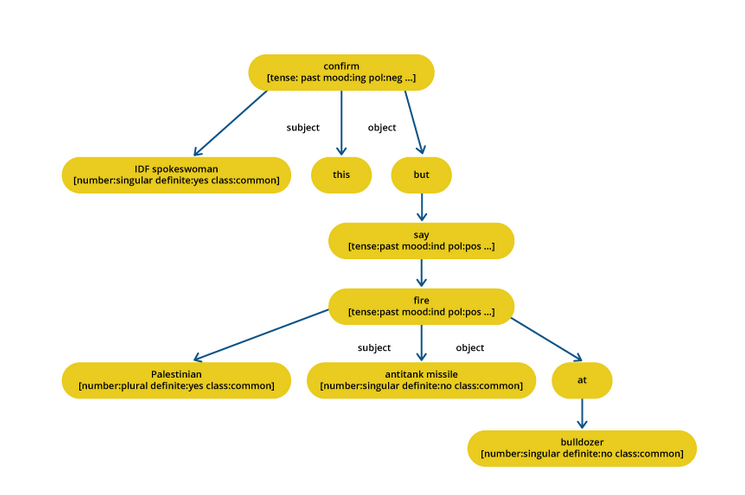
בשיטה הזו, התוכן של מסמך מיוצג בצורת עץ התלויות. בחירת התוכן לתת תוכן יכולה להיות ביצועה באמצעות דרכים נוספות, כמו תוכנה להצטרף נושאים או אחת שמשתמשת בהתאמה מקורית לרגלים במשפטים פרסומים. הגישה הזו משתמשת בין אם במערכת השפה או באלגוריתם שותף עבור יצירת תתכניות. במאמרזה, המחברים מציעים שיטת התאחדת משפטים שמשתמשת בהתאמה מקורית מרוחבים למסלול כדי למצוא את הביטויים המשותפים למידע. מערכות סיכום רב-גן משתמשות בטכניקה שנקראת התאחדת משפטים.
בשיטה הזו, נבדקים מספר מסמכים משמשים כקלט, מעבדים בעזרת תוכנית בחירת נושא על מנת להוציא את הנושא המרכזי, ואחר כך משמשים אלגוריתם לסדר את הביטויים לפי חשיבותם. אחרי שהמשפטים נסדרו, הם מתאחדים בעזרת התאחדת המשפטים, ונוצרת סיכום סטטיסטי. השיטה המבנויה מקדשת את הנתונים החשובים ביותר מהמסמך (הם) בעזרת סchema פסיכולוגיים כמו תבניות, חוקי הוצאה, ומבנים חלקיים כמו עץ, אונטולוגיה, הם והגוף, חוק, ומבנה מבוסס-גרף.
שיטות בעלות תבנית
בשיטה זו משמשת מדריך כדי לייצג מסמך שלם. דפוסים לغיתיים או קריטריונים לניצול מובעים בהשוואה כדי לזהות פסקאות טקסט שיכולות להתמapped לתוך תוכניות המדריך. הפסקאות האלה הן סימן לאיזור התוכן של הערך ההסתם. המאמרהזה מציע שתי שיטות (סיכום ספרות יחידי ומרובה-מסמכים) לסיכום מסמכים. כדי ליצור דגימות וסקירות מהמסמכים, הם עוקבות אחר השיטות המופיעות בGISTEXTER.
מובנה לניצול מידע, GISTEXTER הוא מערכת סיכום שמזהה מידע קשור לנושא בטקסט הקדם ומוסיף אותו לרשימות הבסיס למידע; המשפטים אז מוסיפים לסקירה על פי בקשות המשתמש.

שיטות מבוססות אונטולוגיה
מחקרים רבים ניסו לשפר את יעילות הסיכו summaries בעזרת הידע המקורי (מבנה ידע). רוב המסמכים ברשת האינטרנט מעורבים בתחום רב שייך, אז כל אחד מהם מתייחס לאותו סוג של נושא כללי. הידע המקורי הוא יצירה חזקה של מבנה המידע הייחודי של כל תחום.
המאמר הזה מציע את שימוש באונטולוגיה מערבת, שמייצגה את האינטרנסיות ותומכת בדיוק בתחום הידע של התחום, כדי לסכם חדשות סיניות. בשיטה הזו, מומחים בתחום ראשים בהגדרת האונטולוגיה עבור אירועי החדשות, ואחר כך בשלב ההכנה של המסמכים נוצרת עיצוב מילים סמנטיות מהקורפוס של החדשות ומהמילון הסיני לחדשות.
שיטת משמעות וביט מילים
הגישה הזו מעברת את המשמעות באופן של עיבוד משמעות עם אותם ביטים הראשיים במשמעות ובגוף המשפט. בעזרת ניתוח סינטיק של הביטים האלה, Tanaka הציעה טכניקה לסכם חדשות ברדיו. שיטות התאמה המשפטית משתמשות להבין את הבסיס של התפיסה הזו.
קישור חדשות מסוכן במציאת משפטים משותפים בפירוש הראשון ובחלקים הגוף, ואחר כך ביטוי והחלפת המשפטים האלה על מנת יצירת סיכרון דרך עידוד משפטים. ראשית, מערך סינטקטי ניתן לשימוש על הפירוש הראשון והחלקים הגוף. בשלב הבא, זוויות חיפוש מזוהמות ולבסוף, מילות מתאימות בעזרת מספר קריטריונים של דומין והתאמה. השלב האחרון עשוי להיות התקנה, חילוף מילים או שניהם.
התהליך ההכנסה מתבצע על ידי בחירת נקודת ההכנסה, בדיקה להידמה ובדיקה להאחדות הדיסקourse כדי לוודא קישור וסינגוף והסרת ההדמה. השלב ההחלפה מספק מידע נוסף על ידי החלפת המילים בפירוש הגוף בפירוש הראשון.
שיטת הגדרות בסיסיות
בשיטה הזאת, המסמכים שצריכים להסכמות מוצגים בתור מושגים ורשימות של אספקטים. המודל המעבד לבחירת תוכן מוצא את המועמד הכי יעיל מתוך אלה שנוצרים על-ידי כללים להוצאה ממידע להגיב לאחד או הרבה אספקטים של קטגוריה. לבסוף, דפוסי יצירה משמשים ליצירת משפטים של התחתית.
כדי לזהות אותם עושר של שםים ופעלים שהם סמנטית קשורים, Pierre-Etienne ואחרים הציעו מערך של מדדים עבור ניתוח מידע. אחרי ניטוחן, המידע נשלח לשלב בחירת תוכן שמנסה לסנן את המועמדים המעורבים. הוא משמש למבנה משפטים ולמילים בתבנית ייצור ישירה. אחרי ייצורן, מבצעת סיכום מודרכת תוכן.
שיטות על-גרף
מספר חוקרים משתמשים במבנה גרף כדי לייצג מסמך שפתי. גרפים הם בחירה פופולרית לייצג מסמכים בקהילת המחקר הלINGוגי. כל עצם במערכת מייצג יחידת מילים, שביחד עם קווים מובאים מסגרת המשפט. כדי להתאים את הביצועים של הסיכום, דינגדיין וואנג ואחרים הציעו מערכות סיכום רב-מסמכים המשתמשות במספר אסטרטגיות שונות, כמו שיטת המרכזים, שיטת הגרף, וכן הלאה, כדי לבחון מערכות בסיס שונות, כמו ממוצע ציון, ממוצע מיקום, ספירת בורדה, אגבדיה של מדיונים, וכן הלאה. שיטה משקלית יחודית נוצרה כדי לאסוף את תוצאות הסיכומים של האסטרטגיות השונות. בגישה הסמנטית, דוגמה למסמך או מסמכים מושתת על השפה הטבעי מושתת על מערכת ייצור שפה טבעי (NLG). הטכניקה הזו מתמחה בזיהוי משפטים על פי נתונים לשפה.
גישה סמנטית
גישות סמנטיות משתמשות בתיאור השפה של המסמך כדי לאסוף על מערכת ייצור שפה טבעי (NLG). השיטה הזו מעבדת את הנתונים הלשוניים על מנת לזהות משפטים על פי שם ופעל.
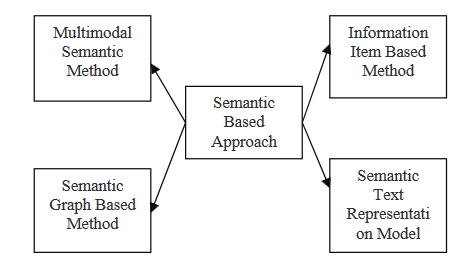
- מודל סמנטי רב-מודלי: בשיטה זו, נוצר מודל בלשני המתאר מושגים ויחסים בין רעיונות כדי לתאר את התוכן של מסמכים רב-מודליים כגון טקסט ותמונות. הרעיונות המרכזיים מדורגים לפי מספר קריטריונים, והמושגים הנבחרים מבוטאים כמשפטים כדי ליצור תקציר.
- שיטה מבוססת פריטי מידע: בגישה זו, במקום להשתמש במשפטים מהמסמכים המקוריים, נעשה שימוש בייצוג מופשט של אותם מסמכים כדי ליצור את תוכן התקציר. הייצוג המופשט הוא פריט מידע, החלק הקטן ביותר של מידע קוהרנטי בטקסט.
- מודל גרף סמנטי: טכניקה זו מטרתה לסכם מסמך על ידי בניית גרף סמנטי עשיר (RSG) עבור המסמך הראשוני, ואז צמצום הגרף הבלשני שנוצר ויצירת התקציר המופשט הסופי מהגרף הבלשני המצומצם.
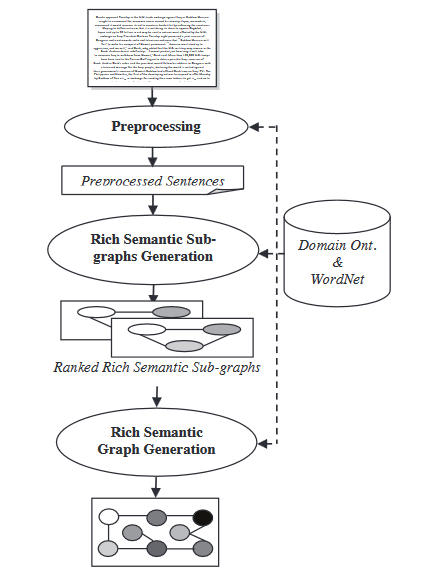
במהלך מודול יצירת הגרף הסמנטי העשיר, מיושמת סדרה של כללים היוריסטיים על הגרף הסמנטי העשיר שנוצר כדי לצמצם אותו על ידי מיזוג, מחיקה או איחוד של צמתי הגרף.
- מודל ייצוג טקסט סמנטי: טכניקה זו מנתחת טקסט קלט באמצעות הסמנטיקה של המילים במקום התחביר/מבנה של הטקסט.
מדגם מקצועים בעסקים
- תכנות שפה מחשב: היו מאמצים רבים לפיתוח טכנולוגיית בינת אינטגרטיבית שיכולה לכתוב קוד ולפתח אתרים באופן עצמאי. בעתיד, מתכנתים יוכלו לסמוך על מסמכים מתמחים "סיקורי קוד" כדי לקחת את האבנים העיקריים מפרויקטים חדשים.
- עזרה לאנשים פגועים פיזית: אנשים שמקבלים קשה בשמיעה יוכלו למצוא שסיקור עוזר להם לעקוב טוב יותר אחר התוכן בהתפתחות הטכנולוגיה של קול-לטקסט.
- ועידוד ואחרות ישיבות וידאו: עם ההתפשטות של עבודה מרחוק, יש צורך גדל ביכולת להקליט רעיונות עיקריים ותוכן מאינטראקציות. היה נהדר אם היתה לך אפשרות לסכם את הישיבות של הצוות באמצעות שיתוף קול-לטקסט.
- חיפוש פטנטים: מציאת מידע פטנטים רלוונטי עלולה להיות מעברת זמן. סיקור מילוט פטנטים עשוי להציל את הזמן שלך בין אם אתה עושה מחקר סיום שוק או מתכונן לרישום פטנט חדש.
- ספרים וספרות: סיקורים מועילים מפני שהם מעניקים לקוראים סקירה קצרה של התוכן שהם עשויים לצפות בספר לפני שיחתכו אותו.
- פרסום דרך מדיה חברתית: ארגונים שיוצרים דף לבן, ספרים אלקטרוניים ובלוגים חברתיים עשויים להשתמש בסיקור כדי להפוך את העבו
- מחקר כלכלי: תעשיית הבנקאות השקעה במימון רב ברכישת מידע עבור שימוש בהם בהחלטות, כמו סחר במניות ממוחשב. כל מנצח פיננסים שמבלה כל היום בסריקת מידע וחדשות שווקים יגיע בסוף לעמוד בעולם המידע הרב יותר. מסמכים פיננסיים, כמו דוחות רווחים וחדשות פיננסיות, יכולים להרוויח ממערכות סיכום שמאפשרות למנצחים להוציא אותם מהתוכן בקצב מהיר.
- קידום עסקים באמצעות אופטימיזציה במנעדים (SEO): הערכות הSEO דורשות מודעות מושלמת לנושאים שדוברים עליהם בתוכן של המתחרים. זה חשוב מאוד בהתחשב בשינוי האלגוריתם האחרון של גוגל והדחף המקדם שלו על סמכות הנושא. היכולת לסכם מספר מסמכים, לזהות הדברים המשותפים ולסרוק על מידע חשוב יכולה להיות כלי מחקר חזק.
סיכום
למרות שסכם דוגמני פחות אמין מאשר גישות הוצאה, הוא מחזיק בעתיד המעשים הכי גדול ליצירת סכמות המתאימות לדרך בה בני אדם יכולים לכתובם. כתוצאה מכך, סביר שיובסט הרבה טכניקות חדשות, קוגניטיביות ולינגוגיות בתחום הזה.
מקורות
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques