













אתה יכול להמיר את המידע הגולמי שלך למידע מאורגן ופעול יכול לשמע מורכב. ובכן, לא כשיש לך פתרון מהיר ויעיל. אל תדאג! המדריך החברתי למתחילים של AWS Glue יעזור לך.
במדריך זה, תלמד את השלבים החיוניים לתצורה וביצוע המרות נתונים עם AWS Glue.
חקור וסדר את ההכנה לנתונים עבור אנליטיקה בענן!
דרישות מוקדמות
לפני שתתחיל לעבוד עם AWS Glue, וודא שיש לך חשבון פעיל ב-Amazon Web Services (AWS) עם הפעלת חיוב. חשבון חינם לטווח יעמוד בכדי למדריך זה.
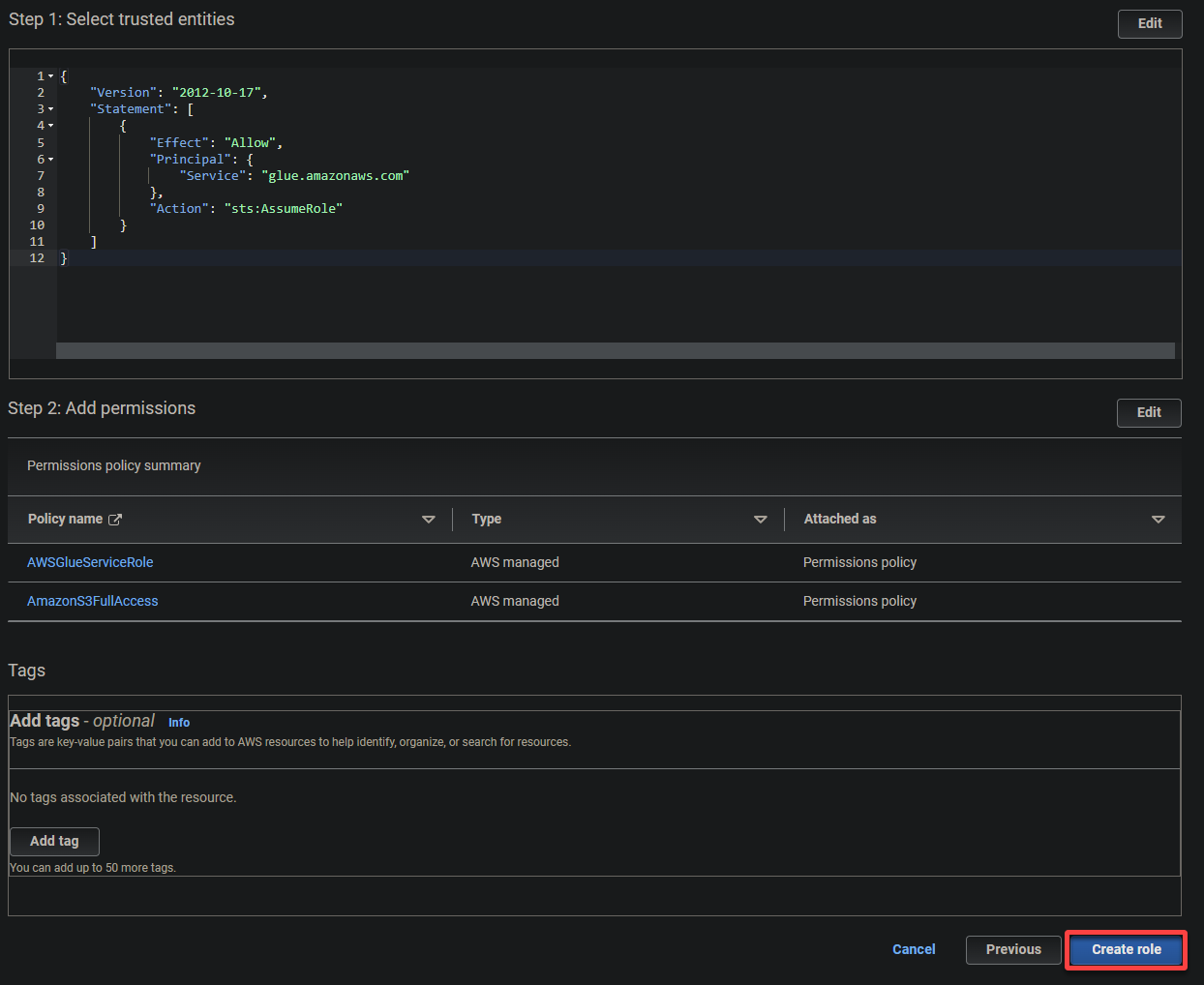
יצירת תפקיד IAM עבור AWS Glue
לפני ביצוע משימת ההמרה, עליך ליצור תפקיד של ניהול וגישה (IAM) המעניק הרשאות לשירות AWS Glue. תפקיד זה מגדיר אילו משאבים ה-S3 יכול לגשת אליהם בחשבונך שב- AWS.
כדי ליצור את תפקיד ה- IAM, עקוב אחר השלבים הבאים:
1. פתח את הדפדפן שלך, והתחבר ל- AWS Management Console .
2. חפש ובחר את IAM ברשימת התוצאות כדי לגשת לממשק ה-IAM.
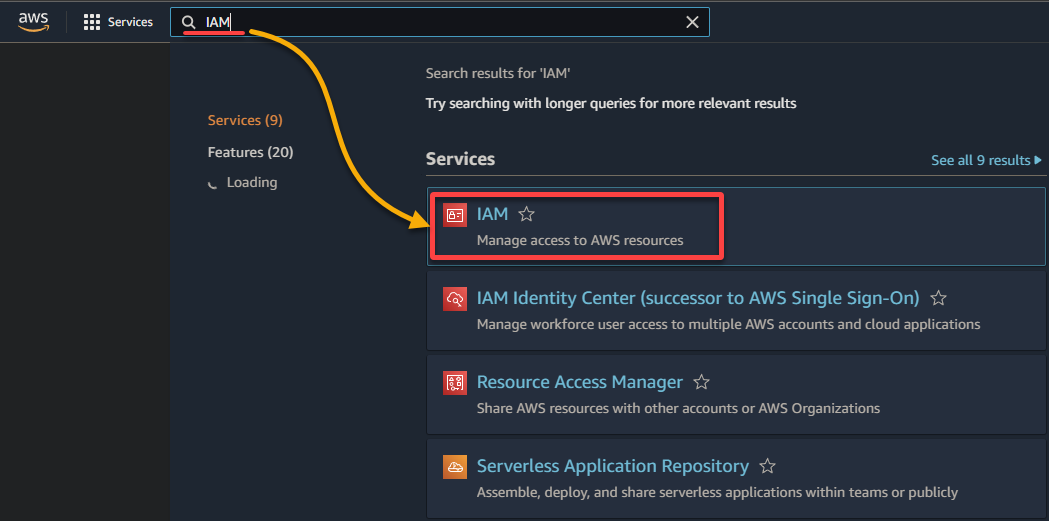
3. בממשק ה-IAM, נווט ל תפקידים (לוח שמאלי) ולחץ על צור תפקיד (למעלה מימין), מפנה את הדפדפן שלך לדף חדש שנועד להגדרת התפקיד.

4. כעת, הגדר את הגדרות התפקיד הבאות:
- סוג הישות המהימנה – בחר שירות AWS כך ששירות AWS יכול להאמין בתפקיד. ביצוע זה מאפשר לשירות זה להניח את התפקיד ולפעול מטעמך.
- מקרה שימוש – בחר Glue בתחתית המקרי שימוש עבור שירותי AWS אחרים מאשר תיצור את התפקיד של IAM במיוחד עבור AWS Glue ולחץ על הבא.
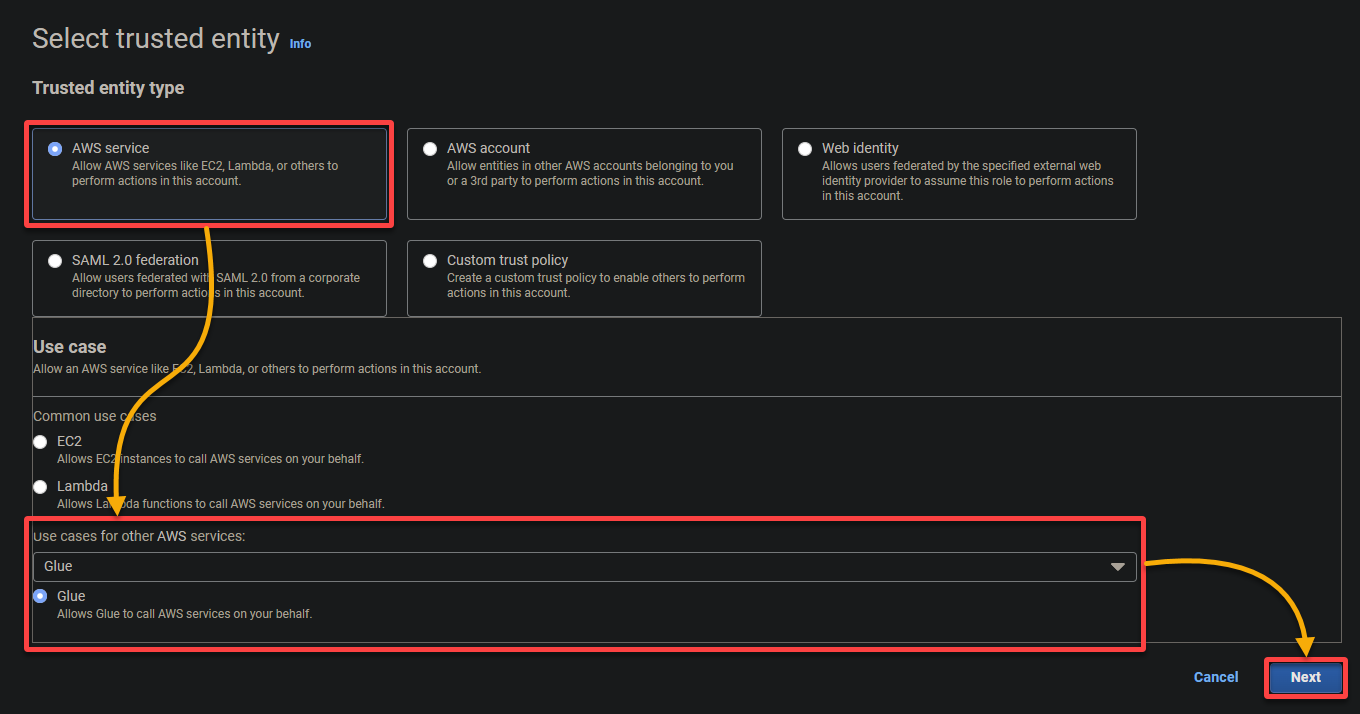
5. חפש ובחר את המדיניות הבאות, ולחץ על הבא.
- AWSGlueServiceRole – מעניק לשירות AWS Glue את ההרשאות הנדרשות כדי לבצע את הפעולות שלו.
- S3FullAccess – מעניק גישה מלאה למשאבי S3, מאפשר ל-AWS Glue לקרוא מהם ולכתוב אליהם.
AWS Glue זקוק להרשאות מתקדמות כדי לקרוא ממקוני S3 ולכתוב אליהם כדי לבצע משימות של חילוץ, המרה והטענה של נתונים (ETL) ביעילות.
? נסה לא להעניק הרשאות יתר עודפות שאינן נחוצות, שכן יתכן שתגרום לסיכוני אבטחה.
6. ספק שם תיאורטי עבור התפקיד (כגון תפקיד_ג'לו) ותיאור.
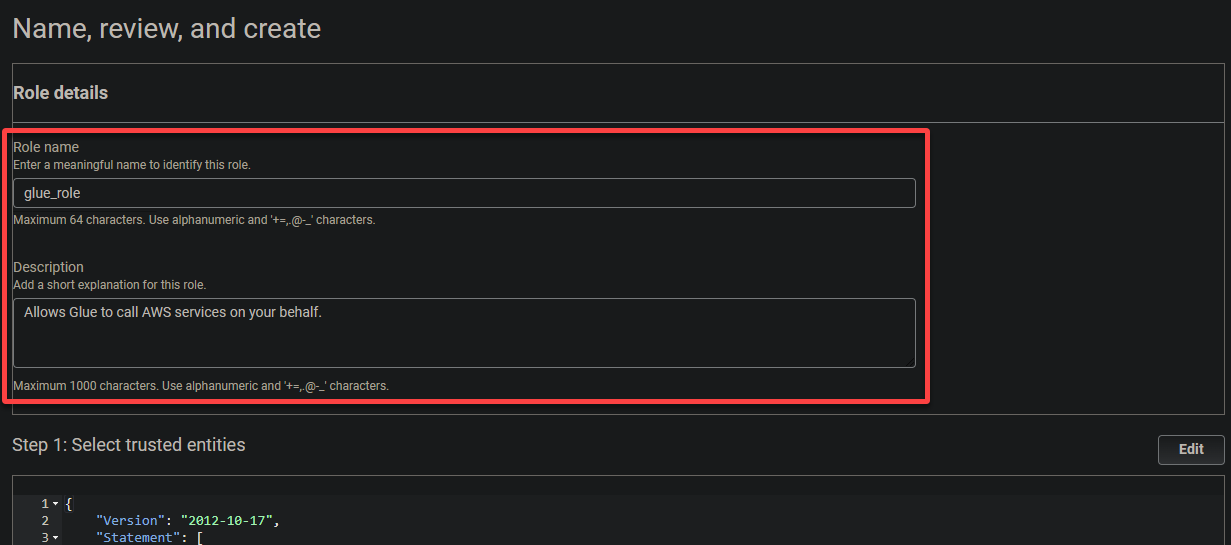
7. לבסוף, גלולו למטה, בדקו את ההגדרות שלכם, ולחצו על צור תפקיד (בתחתית-ימין) כדי לסיים את יצירת התפקיד.
יצירת קופסא S3 והעלאת קובץ לדוגמה
עכשיו שיש לכם תפקיד IAM עבור AWS Glue, נדרש לכם מקום לאחסון הנתונים שלכם, במיוחד, קופסת S3. קופסת S3 מספקת מיקום מרכזי לאחסון הנתונים שיעבוד AWS Glue.
בדוגמה זו, AWS Glue ישתמש ב- AWS S3 כאחסון נתונים למגוון פעולות, כמו אחסון, המרה וטעינה (ETL).
כדי ליצור קופסת S3 ולהעלות קובץ לדוגמה, עקבו אחרי השלבים האלה:
1. הורידו קובץ נתונים לדוגמה (דוגמה לסט נתונים של כל פוליטיקאי) למחשב המקומי שלכם. קובץ זה מכיל אוסף לא מובנה של רשומות שישמשו כקלט למשימת ההמרה של AWS Glue.
2. חפשו ובחרו בשירות S3 כדי לגשת לממשק ה-S3.
3. לחצו על צור קופסא כדי להתחיל ביצירת קופסת S3 חדשה.

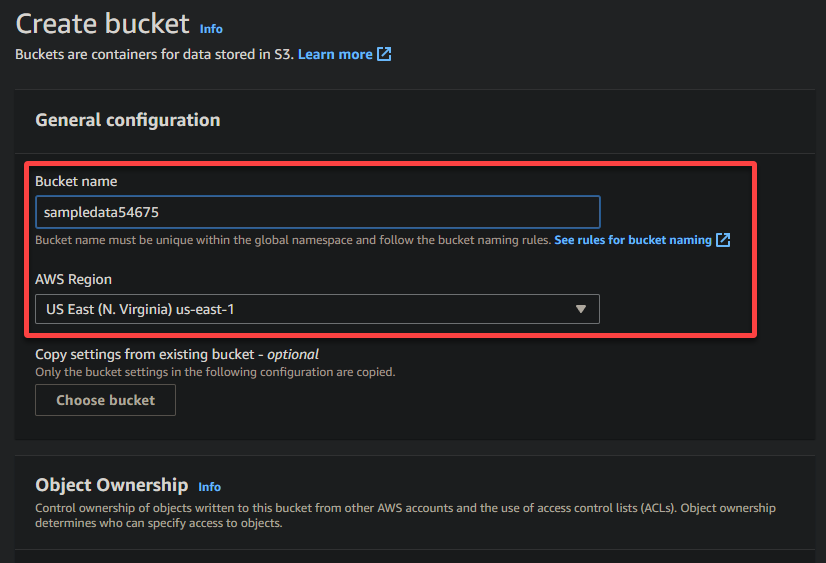
4. עכשיו, ספקו שם ייחודי לקופסא שלכם (לדוגמה, sampledata54675) ובחרו את האזור בו יימצא הקופסא.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
5. גללו למטה, השאירו את שאר האפשרויות כפי שהן, ולחצו על צור קופסא כדי ליצור את הקופסא.

6. לאחר שנוצרה, לחצו על הקישור לקופסא S3 שנוצרה חדשה.

7. לחצו על העלאה ואתרו את הקובץ לדוגמה שתרצו להעלות.
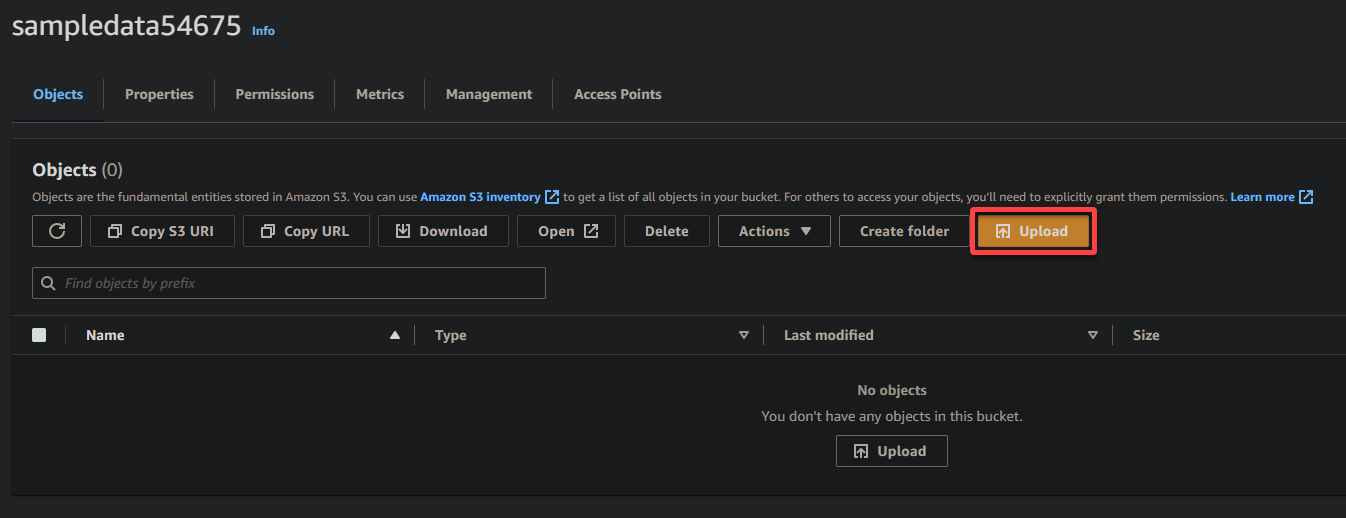
8. לבסוף, שמרו על ההגדרות האחרות כמו שהן, ולחצו על העלאה כדי להעלות את קובץ הדוגמה לדלי החדש שנוצר.
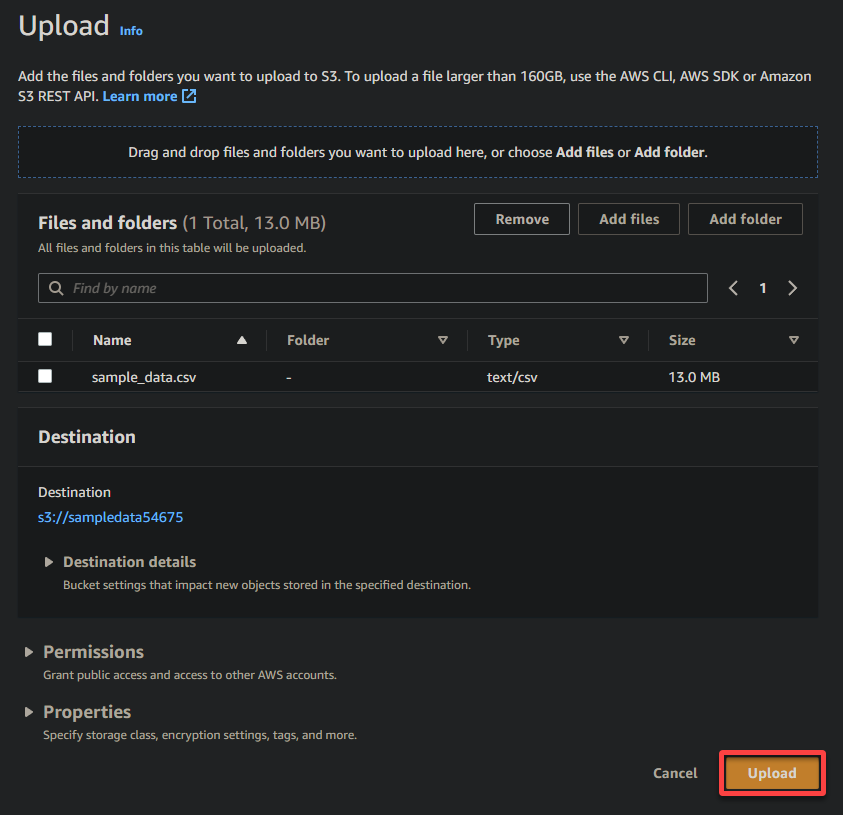
אם ההעלאה הצליחה, תראו את קובץ העלאתכם בדלי שלכם, כפי שמוצג למטה.
יצירת ג'לו קרולר לסריקה וקטלוג של נתונים
העליתם לאחרונה נתוני דוגמה לדלי ה-S3 שלכם, אך מאחר והם כרגע לא מובנים, נדרש דרך לקרוא את הנתונים ולבנות קטלוג מטא-נתונים. איך? על ידי יצירת ג'לו קרולר שסורק ומקטלוג את הנתונים באופן אוטומטי.
כדי ליצור ג'לו קרולר, עקבו אחר השלבים הבאים:
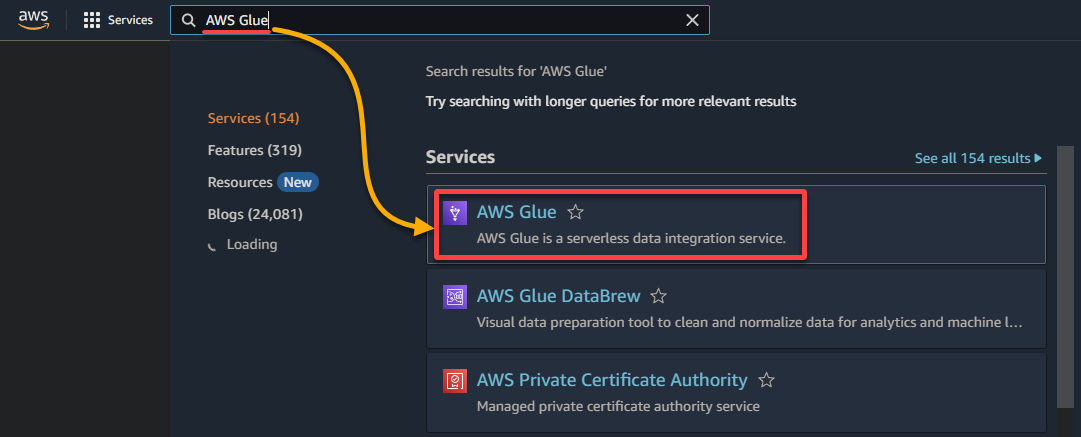
1. נווטו אל לוח הבקרה של AWS Glue דרך לוח הבקרה לניהול של AWS, כפי שמוצג למטה.
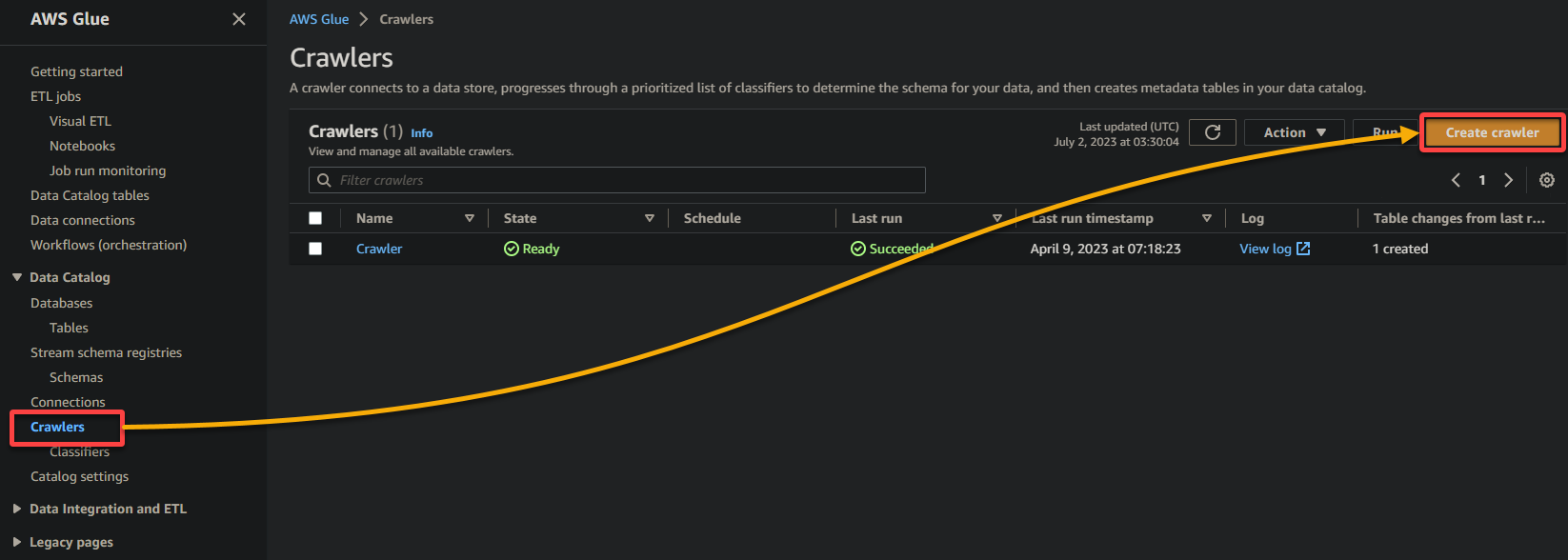
2. לאחר מכן, נווטו אל קרולר (בפאנל השמאלי) ולחצו על הוספת קרולר (למעלה-ימין) כדי להתחיל ביצירת ג'לו קרולר חדש.
3. ספקו שם תיאורי (לדוגמה, ג'לו קרולר) ותיאור לקרולר, שמרו על ההגדרות האחרות כמו שהן, ולחצו על הבא.
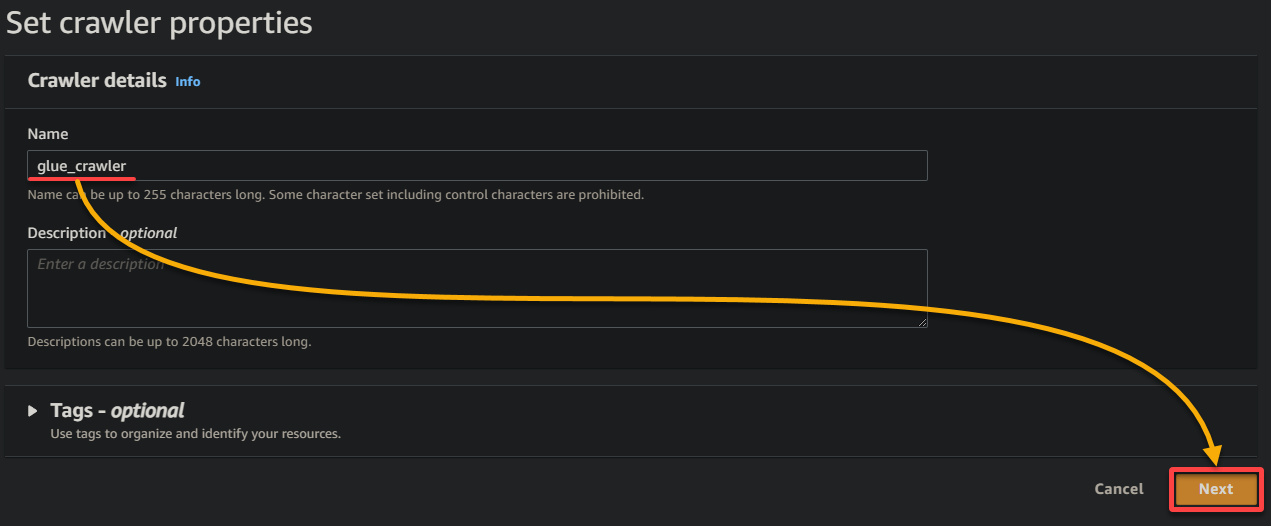
4. כעת, לחצו על הוספת מקור נתונים תחת מקורות נתונים כדי להתחיל בהוספת מקור נתונים חדש לקרולר.
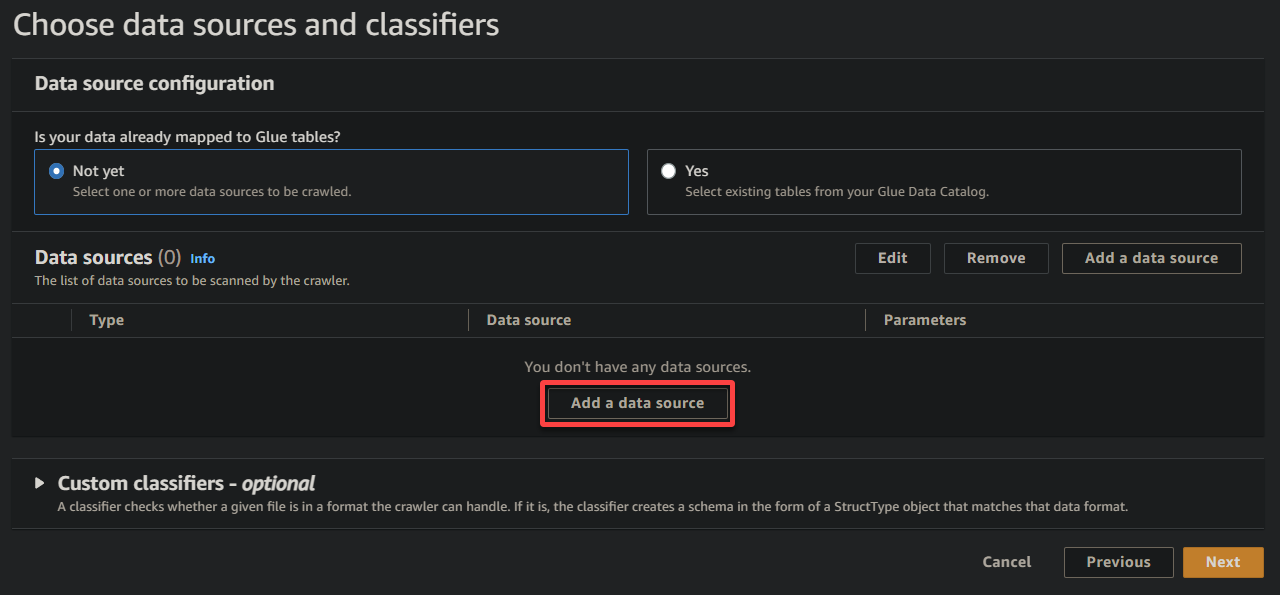
5. בחלון הקופץ, הגדירו את מקור הנתונים כך:
- מקור הנתונים – בחרו ב-S3 מאחר והנתונים שלכם נמצאים בדלי ה-S3 שלכם.
- נתיב S3 – לחץ על עיין ב-S3, ובחר את הדלי שמכיל את הנתונים הדוגמיים שהועלו על ידך (sampledata54675).
- שמור על ההגדרות האחרות כפי שהן, ולחץ על הוסף מקור נתונים מ-S3 כדי להוסיף את הנתונים הדוגמיים לצוללת.
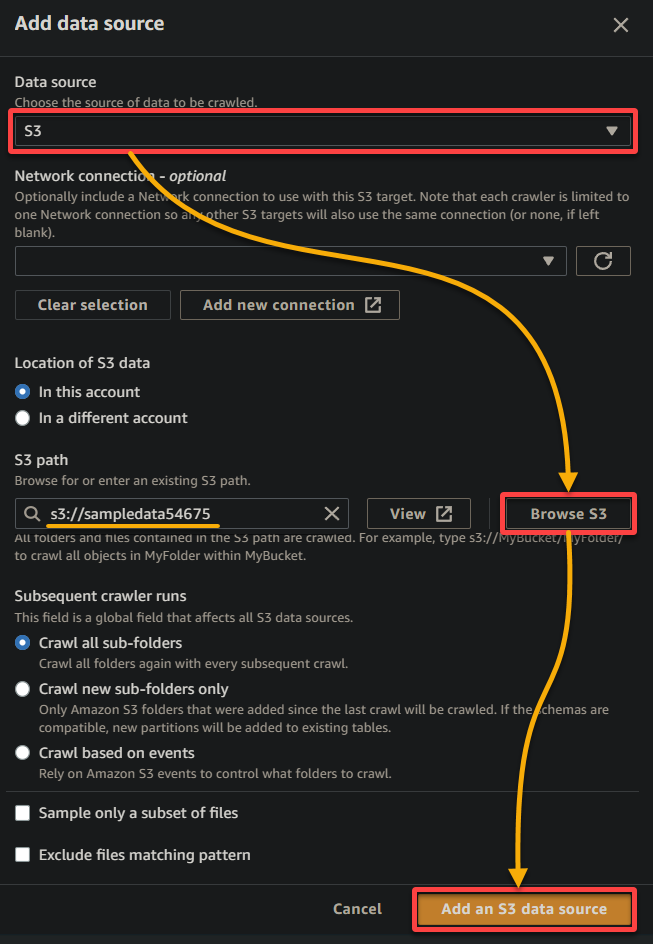
6. לאחר הגדרת הצוללת, אמת את מקור הנתונים, כפי שמוצג למטה, ולחץ על הבא כדי להמשיך.
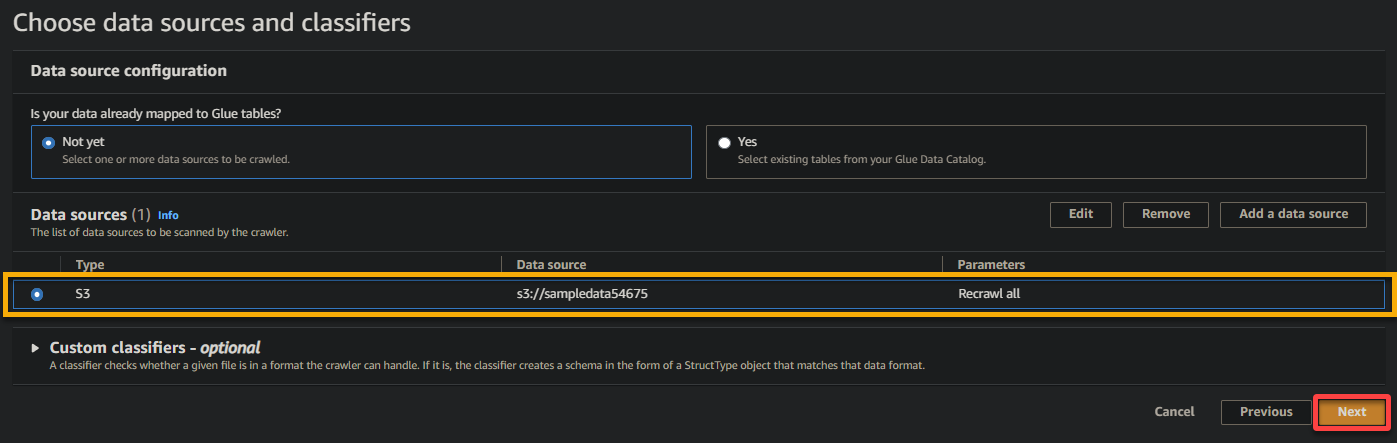
7. במסך הבא, בחר בתפקיד IAM שיצרת קודם (glue_role), שמור על ההגדרות האחרות כפי שהן, ולחץ על הבא.
8. בחלק הפלט והתזמון, לחץ על הוסף מסד נתונים כדי להתחיל בהוספת מסד נתונים חדש לאחסון הנתונים המעובדים והמטא-נתונים שיוצרו על ידי הצוללת שלך. פעולה זו תפתח לוח דפדפן חדש, שם תגדיר את פרטי המסד הנתונים שלך (שלב שמונה).
המסד הזה מספק תיאור מובנה של הנתונים לשאילתות ולניתוח.
9. בלוח דפדפן החדש, ספק שם מתאר תיאורי למסד הנתונים (כגון, glue_database), ולחץ על צור מסד נתונים כדי ליצור את המסד הנתונים.
10. החלף ללוח דפדפן הקודם, בחר במסד הנתונים שנוצר לאחרונה (glue_database) מהתפריט הנפתח, שמור על ההגדרות האחרות כפי שהן, ולחץ על הבא.
11. לבסוף, בדוק את ההגדרות שלך במסך הסופי כדי לוודא שהן נכונות, ולחץ על צור צוללת (בתחתית הימנית) כדי ליצור את הצוללת החדשה.
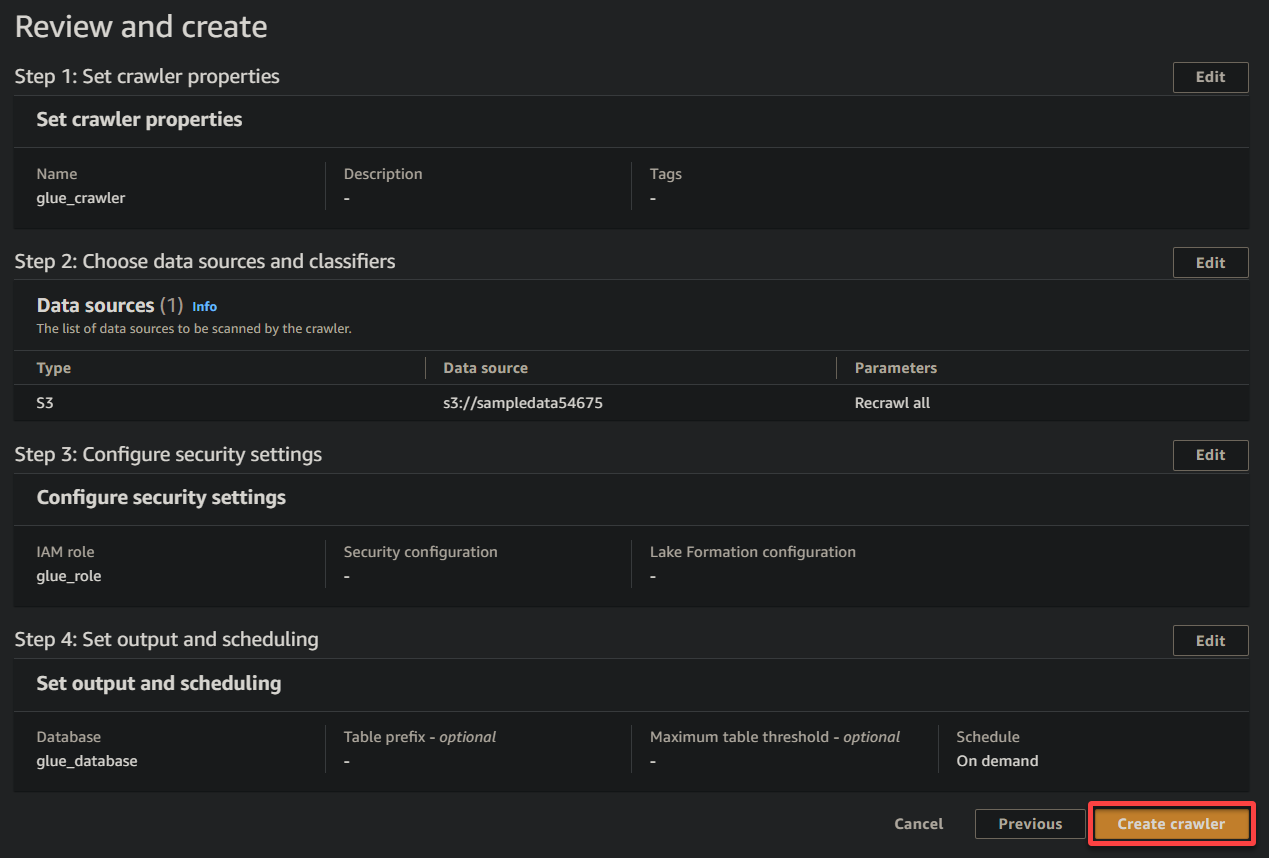
אם הכל הולך כצפוי, תראה מסך המאשר את יצירת הצוללת בהצלחה. אל תסגור מסך זה עדיין; תפעיל את הצוללת הזו בקטע הבא.
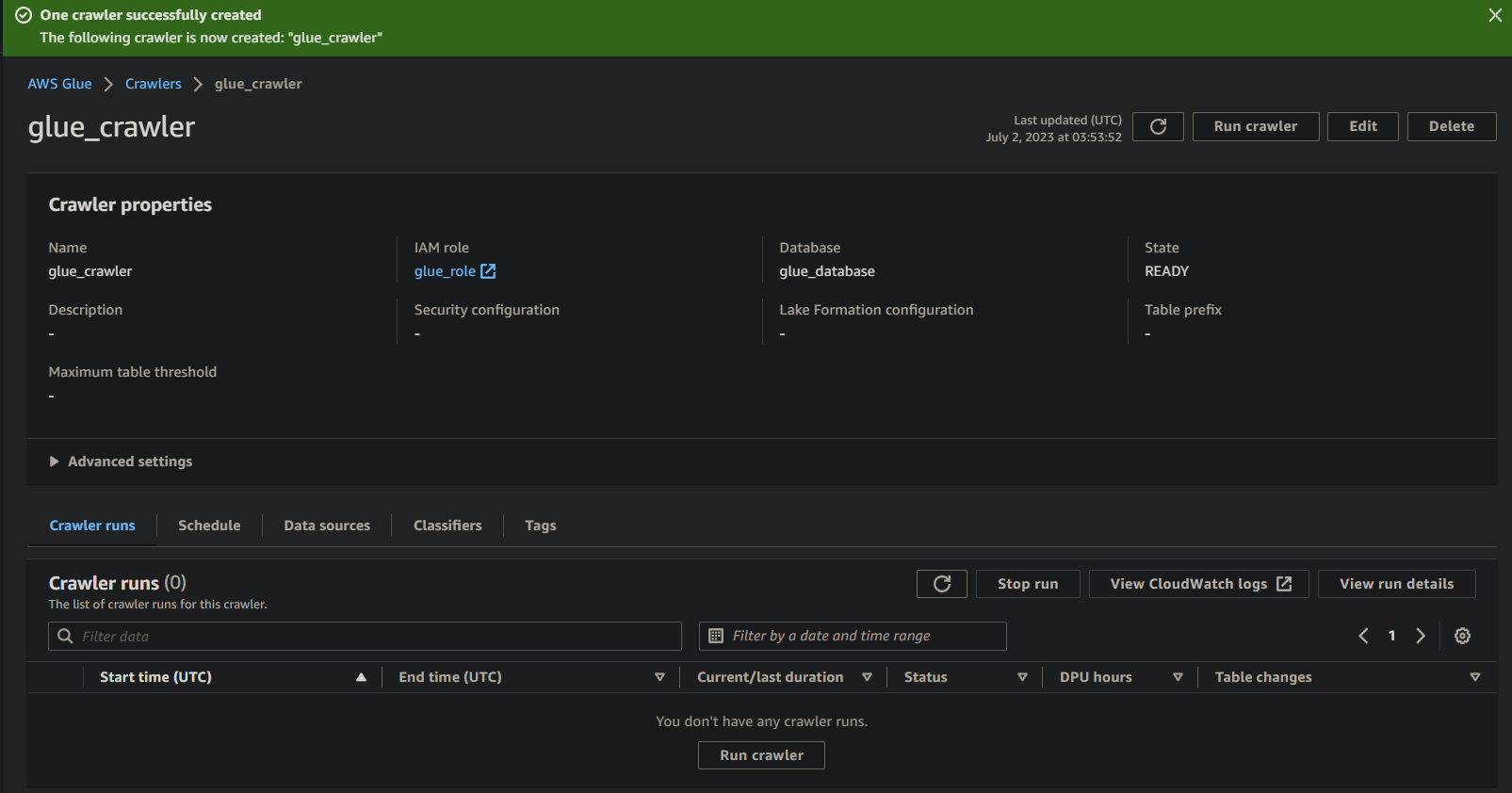
רץ את Glue Crawler כדי לבנות קטלוג מטה-נתונים
עם גרסה חדשה של ה-Crawler ברשותך, הפעלת ה-Crawler היא חיונית כדי להתחיל בתהליך הסריקה והקטלוגיזציה. ה-Glue Crawler שלך יבנה קטלוג מטה-נתונים המספק ייצוג מובנה של הנתונים שלך לצורך שאילתות וניתוח.
כדי להפעיל את ה-Glue Crawler שיצרת:
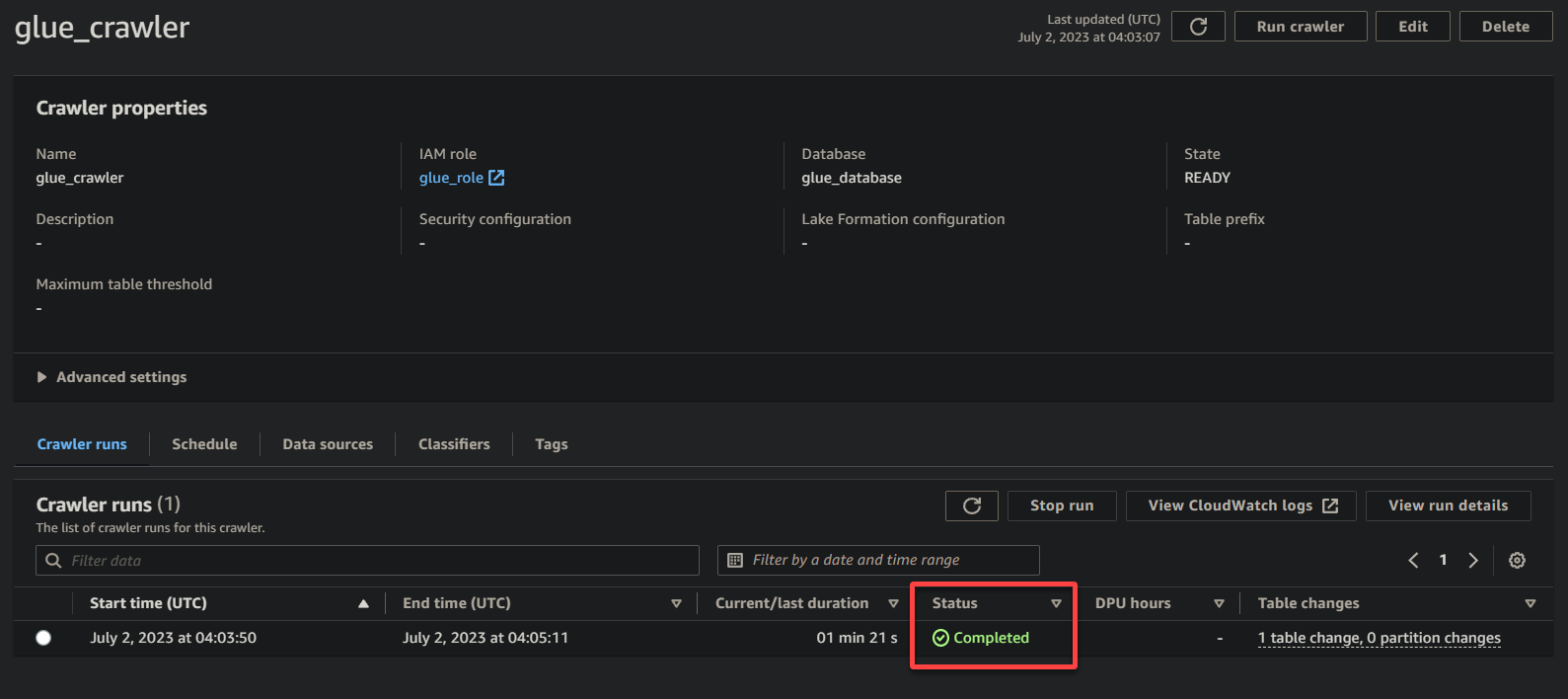
1. בדף פרטי ה-Crawler, לחץ על Run crawler תחת לשונית Crawler runs כדי להתחיל את ביצוע ה-Crawler.
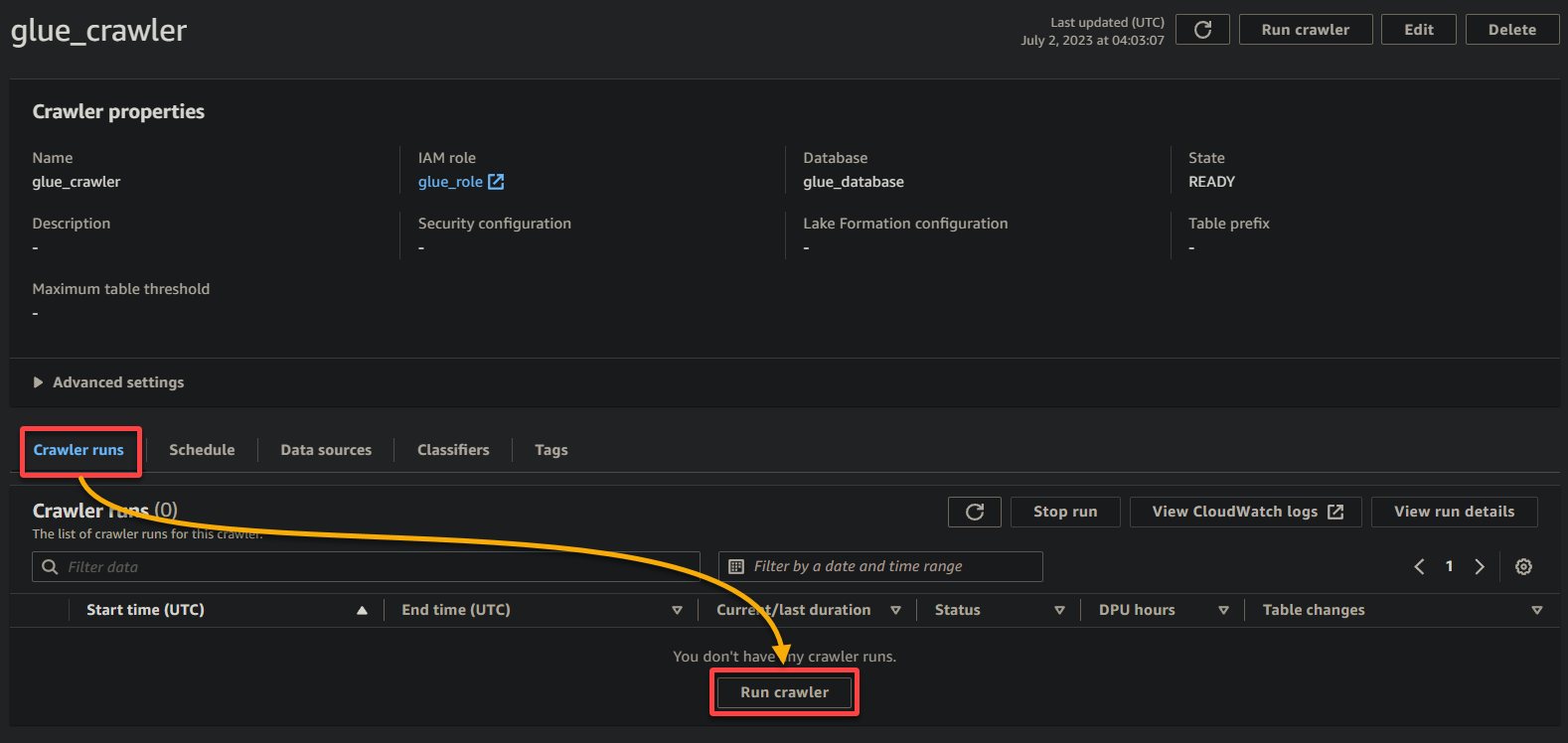
כאשר ה-Crawler מתחיל לרוץ, תראה את המצב וההתקדמות שלו בדף פרטי ה-Crawler.
בהתאם לגודל ולמורכבות של הנתונים שלך, ייתכן שה-Crawler ייקח זמן מה כדי להשלים את ביצועו. תוכל לרענן את הדף באופן תדיר כדי לראות את המצב המעודכן של ה-Crawler.
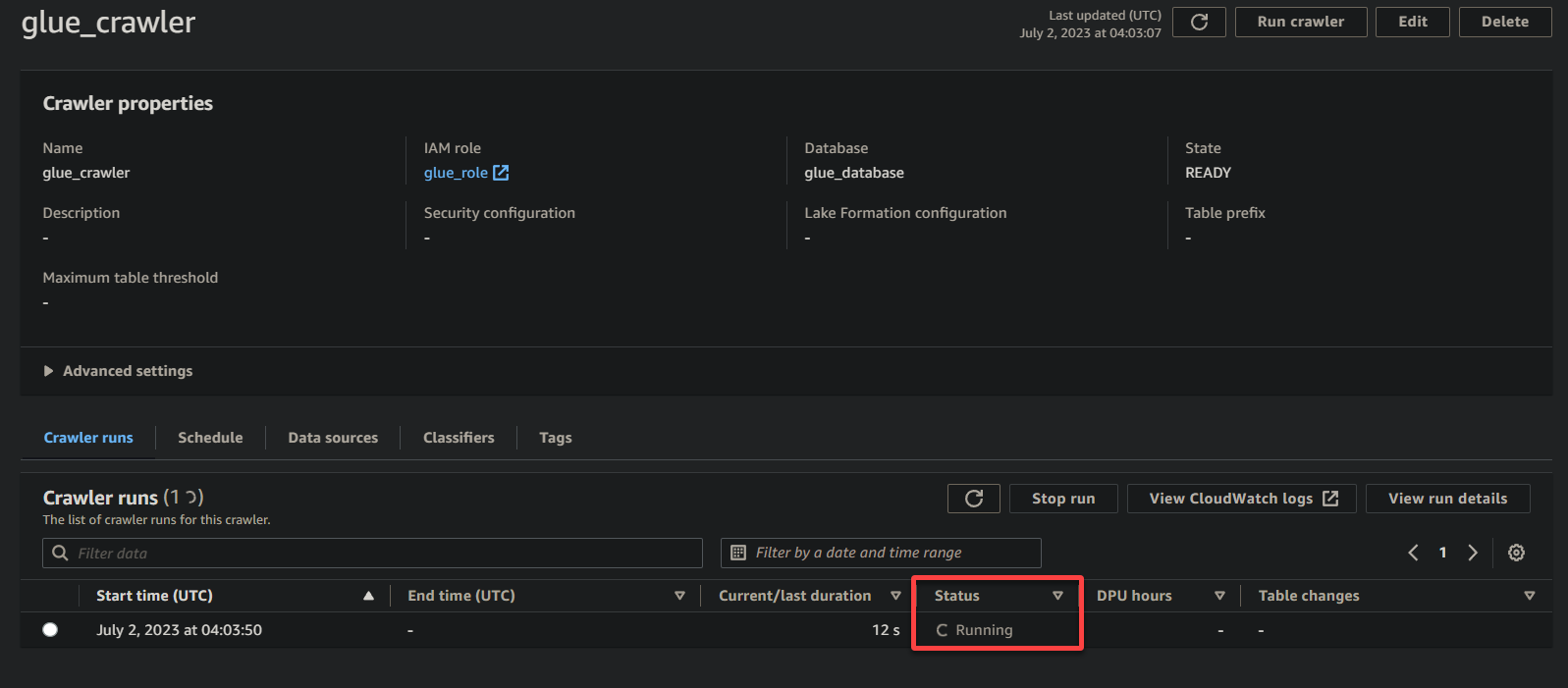
לאחר שה-Crawler השלים את ביצועו, המצב משתנה ל-הושלם, כפי שמוצג למטה. בנקודה זו, תוכל להמשיך לשאילתת הנתונים שלך.
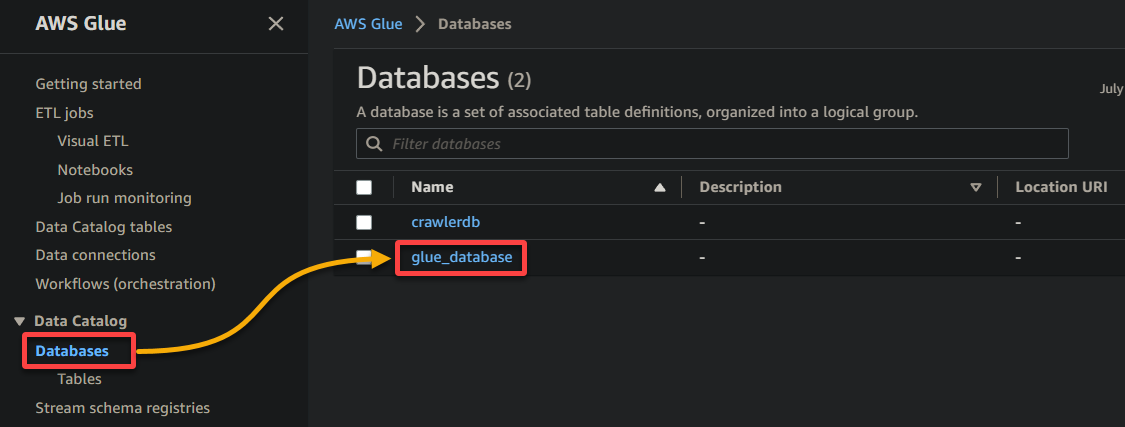
2. לאחר מכן, נווט ל-Database (לוח השמאלי) ולחץ על מסד הנתונים שלך כדי לגשת למאפייניו ולטבלאותיו.
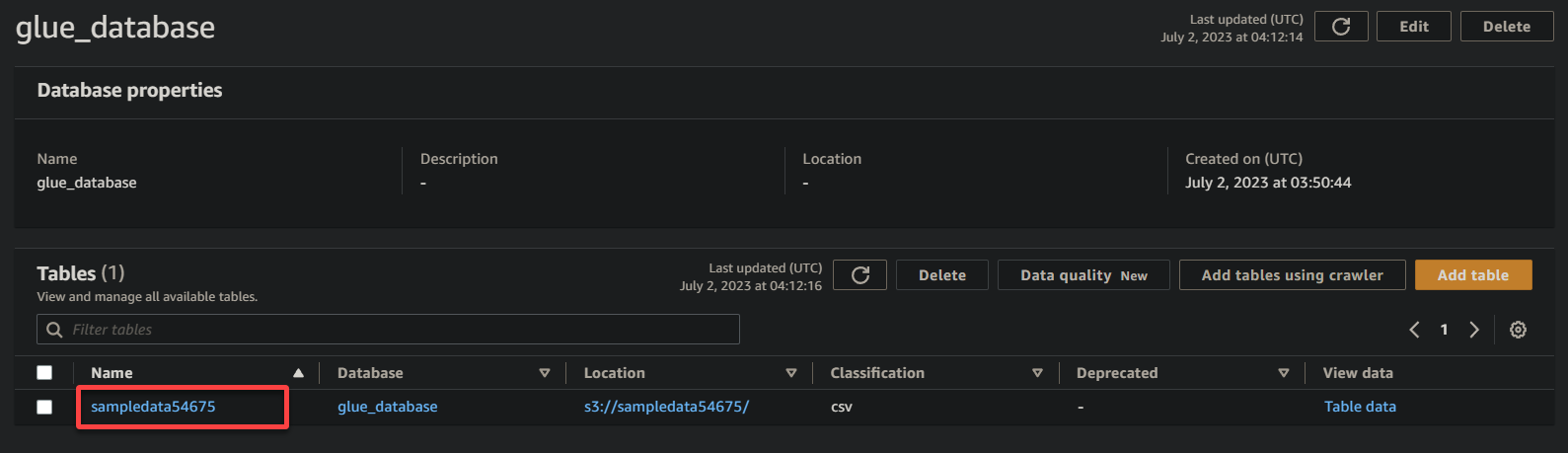
3. לבסוף, לחץ על שם הסלולה שלך (sampledata54675), שעכשיו הוא טבלה, כדי לראות את הנתונים שמאוחסנים בה.
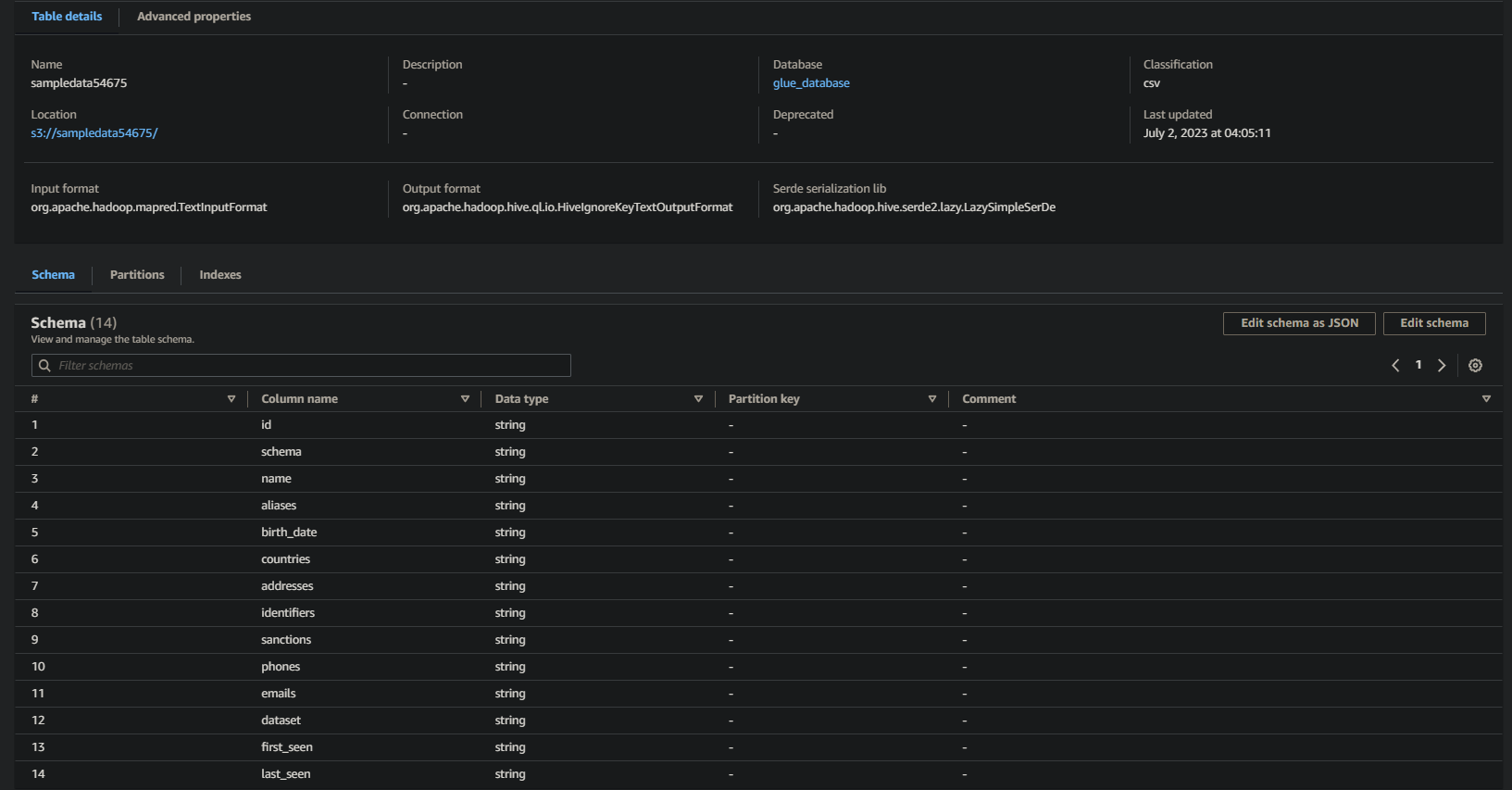
אם הפעולה הצליחה, תראה מידע דומה למטה. מידע זה מאשר שהנתונים הועברו בהצלחה לטבלת בסיס הנתונים, ומספק פרטים יקרים.
שאילתת נתונים מקטלוג באמצעות AWS Athena
עכשיו שהמידע שלך זמין בקטלוג הנתונים של AWS Glue, תוכל להשתמש בכלים שונים כדי לשאול ולנתח את המידע שלך. כלי כזה הוא AWS Athena, שירות שאילתה אינטראקטיבי שמאפשר לך לנתח מידע בענן באמצעות SQL סטנדרטי.
כדי לשאול את המידע באמצעות AWS Athena, עקוב אחר השלבים הבאים:
1. חפש וגש לממשק ה- Athena.
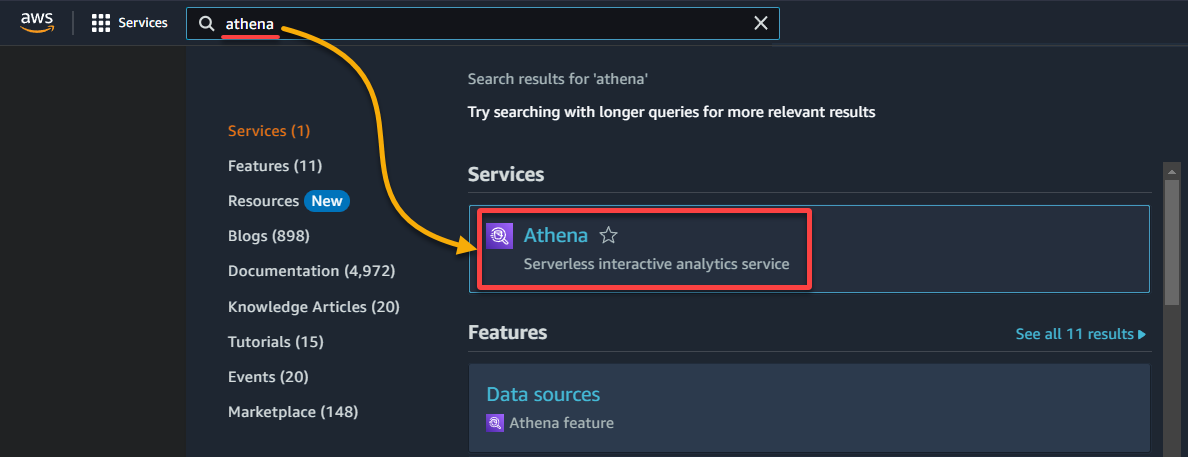
2. בחר במסד הנתונים שבו המידע שלך מוערך בקטגוריית נתונים כך:
- מקור הנתונים – בחר AwsDataCatalog כדי לציין שברצונך לשאול את המידע שמאותר ב-AWS Glue.
- מסד הנתונים – בחר במסד הנתונים המתאים מתוך רשימה נפתחת (כמו glue_database).
? אם אתה לא רואה את מסד הנתונים הרצוי שלך ברשימה, וודא שה-Crawler הושלם בהצלחה ושהמידע נרשם בקטלוג.
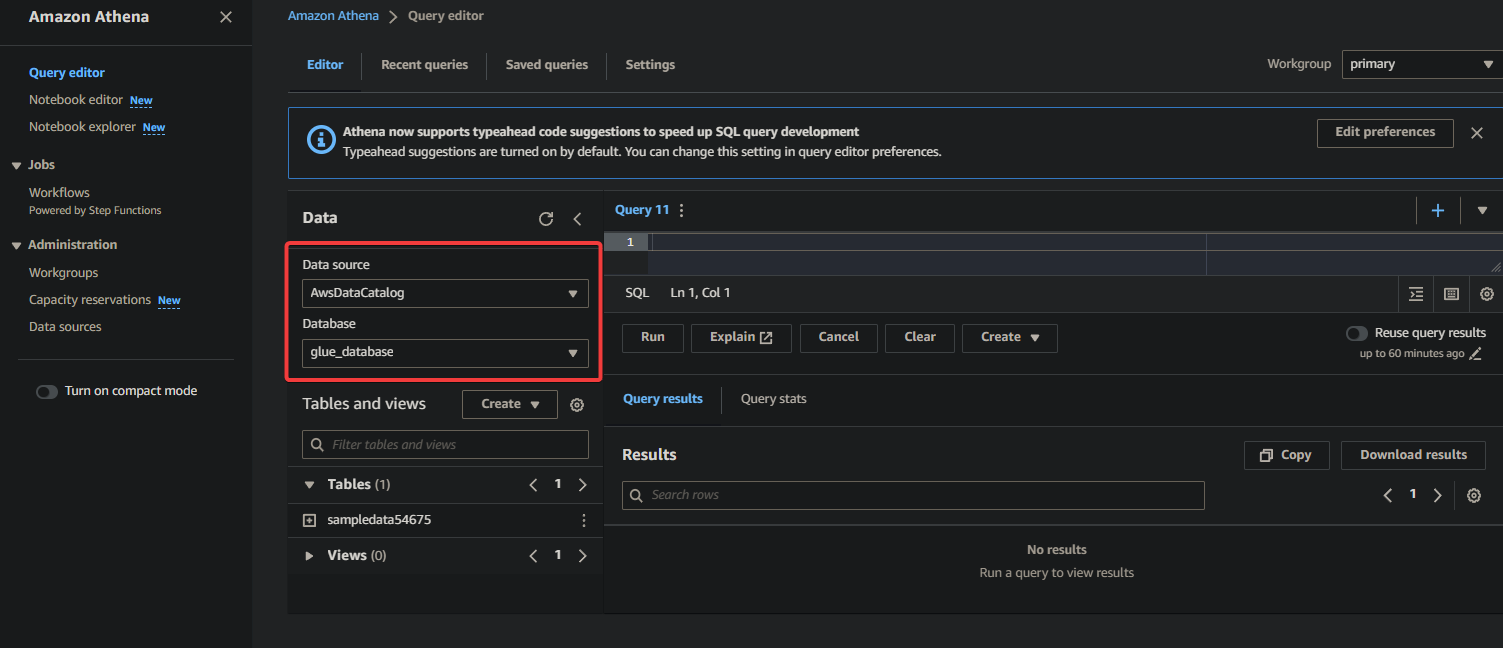
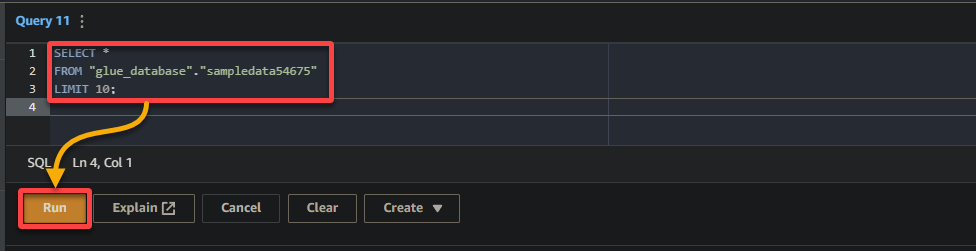
3. לבסוף, מלא והפעל את השאילתה הבאה בעורך השאילתות בימין.
השאילתה מחזירה את השורות הראשונות העשר מהטבלה sampledata54675 במסד הנתונים glue_database. תרגיש חופשי לשנות את השאילתה כדי להתאים לדרישותיך הספציפיות.
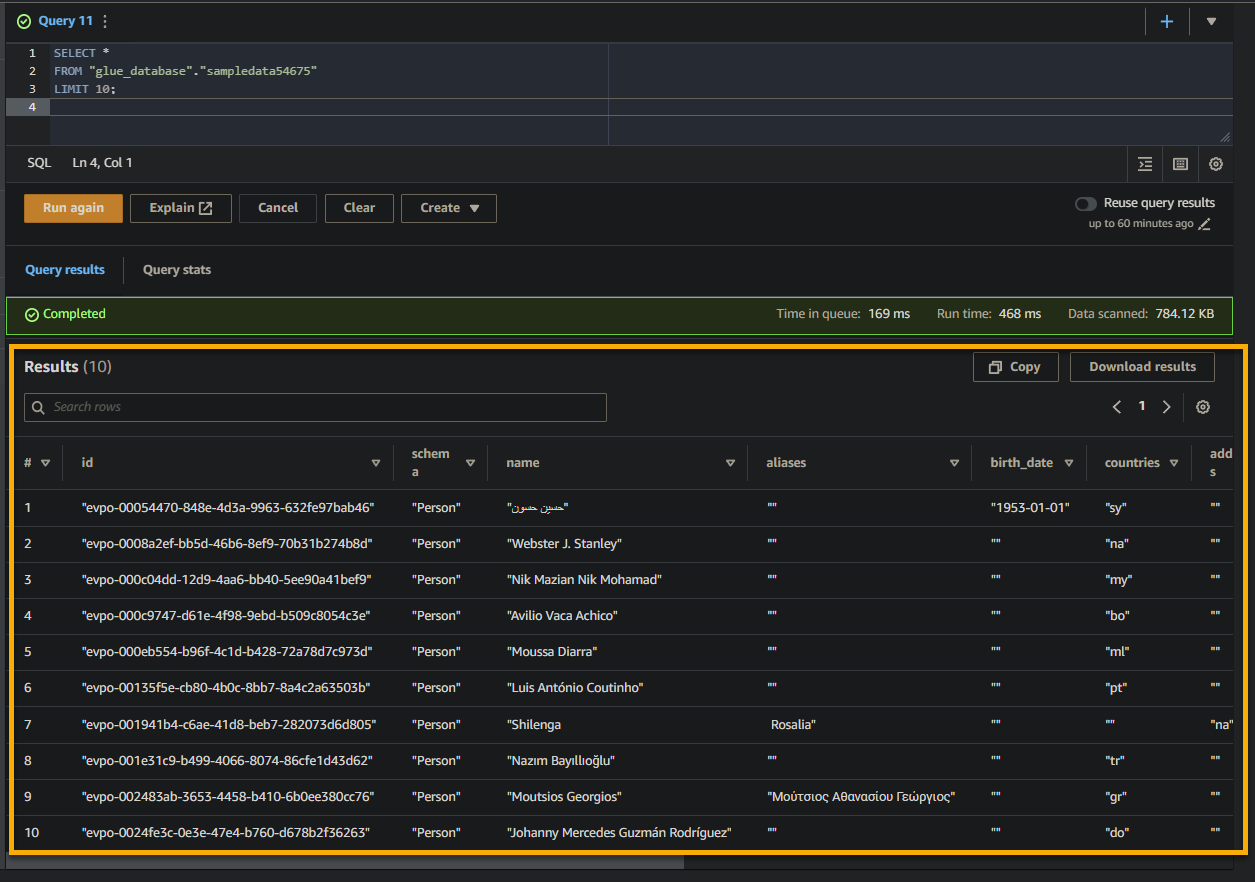
אם השאילתה הצליחה, תראה את התוצאות בחלון תוצאות, כפי שמוצג למטה. התוצאות מכילות מידע על הרשומות שמאוחסנות בטבלה בהתבסס על שאילתת ה-SQL שלך.
שים לב לשמות העמודות, סוגי הנתונים, והערכים שחוזרים בקבוצת התוצאות. מידע זה יסייע לך להבין את מבנה הנתונים שאתה שואל עליו.
מסקנות
במדריך זה, למדת את היסודות של שימוש ב-AWS Glue ליצירת כלי גרר, לקטלוג את הנתונים שלך, ולשאול נתונים באמצעות AWS Athena. הכנת נתונים וניתוח הם חיוניים לכל אפליקציה המבוססת על נתונים. וכלים כמו AWS Glue מספקים דרך מהירה לחלוץ, להפוך, ולטעון (ETL) נתונים ממקורות שונים לתוך טבלה במסד נתונים.
עם AWS Glue, כעת תוכל לנהל ולארגן נתונים במהירות, מאפשר לך להתמקד יותר בניתוח והפקת תובנות מהנתונים שלך. אך מה שראית הוא רק קצה הקרח. חקור את היכולות והפונקציות הרחבות ש-AWS Glue יכולה להציע!
למה לא להשתמש ב־חיבורי AWS Glue כדי לשלב בקלות עם שירותים אחרים של AWS, כמו Amazon RDS או Amazon Redshift? שילוב זה מאפשר לך לבנות צינורות ETL מורכבים ולהשיג יכולות ניתוח נתונים עוד יותר גדולות.