













מודול Pandas של Python
- Pandas הוא ספרייה קוד פתוח ב-Python. הוא מספק מבני נתונים ביצועים גבוהים שניתן להשתמש בהם מיידית וכלי ניתוח נתונים.
- מודול Pandas רץ על גבי NumPy והוא משמש באופן פופולרי למדעי הנתונים ולניתוח נתונים.
- NumPy הוא מבנה נתונים ברמה נמוכה התומך במערכות מדויימניות ובמגוון רחב של פעולות מערך מתמטיות. Pandas מציע ממשק ברמה גבוהה יותר. הוא מספק גם התאמה ממושכת של נתונים טבלאיים ופונקציות סדרות זמן עוצמתיות.
- DataFrame הוא מבנה הנתונים המרכזי ב-Pandas. הוא מאפשר לנו לאחסן ולעבד נתונים טבלאיים כמבנה נתונים ב-2 מימדים.
- Pandas מספק סט מאפיינים עשיר ב-DataFrame. לדוגמה, התאמת נתונים, סטטיסטיקות נתונים, חתיכת, קיבוץ, מיזוג, חיבור נתונים, וכו '
התקנה והתחלה עם Pandas
עליך להיות בבעלות של Python 2.7 ומעלה כדי להתקין את מודול Pandas. אם אתה משתמש ב־conda, אז תוכל להתקין אותו באמצעות הפקודה הבאה.
conda install pandas
אם אתה משתמש ב־PIP, אז הפעל את הפקודה למטה כדי להתקין את מודול ה־pandas.
pip3.7 install pandas
כדי לייבא את Pandas וְNumPy בתסריט שלך בפייתון, הוסף את קטע הקוד למטה:
import pandas as pd
import numpy as np
מכיוון ש־Pandas תלויה בספריית NumPy, יש לייבא תלות זו.
מבני נתונים במודול Pandas
יש שלושה מבני נתונים במודול Pandas, שהם כדלהלן:
- סדרה (Series): מבנה של מערך בלתי נגוד עם גודל 1־ממד ומידע הומוגני.
- DataFrames: מבנה טבלאי בלתי נגוד עם 2־ממדים, שיש לו עמודות עם סוגים שונים.
- פאנל (Panel): מערך בלתי נגוד בלתי נגוד בגודל שלושה ממדים.
DataFrame של Pandas
DataFrame הוא המבנה נתונים החשוב והנפלא ביותר והוא אופן סטנדרטי לאחסון נתונים. DataFrame מכיל נתונים מסודרים בשורות ועמודות כמו טבלה SQL או מסד נתונים של גליון אלקטרוני. אפשר להזין נתונים ישירות ל־DataFrame או לייבא קובץ CSV, קובץ tsv, קובץ Excel, טבלת SQL, וכו'. ניתן להשתמש בבנאי למטה כדי ליצור אובייקט DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
למטה תמצא תיאור קצר של הפרמטרים:
- נתונים – צור אובייקט DataFrame מהנתונים הקלטיים. זה יכול להיות רשימה, מילון, סדרה, Numpy ndarrays או אפילו כל DataFrame אחר.
- index – מכיל את תווי השורות
- columns – משמש ליצירת תווי עמודות
- dtype – משמש לציון את סוג הנתונים של כל עמודה, פרמטר אופציונלי
- copy – משמש להעתקת הנתונים, אם קיימים
ישנן הרבה דרכים ליצור DataFrame. ניתן ליצור אובייקט DataFrame מתוך מילונים או רשימת מילונים. ניתן גם ליצור אותו מרשימת זוגות, מקובץ CSV, קובץ Excel, וכו'. בואו נריץ קוד פשוט ליצירת DataFrame מרשימת מילונים.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
פלט:  השלב הראשון הוא ליצור מילון. השלב השני הוא להעביר את המילון כארגומנט בשיטת DataFrame(). השלב הסופי הוא להדפיס את ה-DataFrame. כפי שאתה רואה, ה-DataFrame יכול להשוות לטבלה המכילה ערכים הטריים. גם גודל ה-DataFrame יכול להשתנות. סיפקנו את הנתונים בצורה של מפה והמפה משתמשת במפתחותיה כתווי השורות של Pandas. האינדקס מוצג בעמודה השמאלית ומכיל את תווי השורות. כותרת העמודה והנתונים מוצגים בצורה טבלאית. ניתן גם ליצור DataFrame עם אינדקס מזוהה, וזה נעשה על ידי הגדרת פרמטר האינדקס בשיטת
השלב הראשון הוא ליצור מילון. השלב השני הוא להעביר את המילון כארגומנט בשיטת DataFrame(). השלב הסופי הוא להדפיס את ה-DataFrame. כפי שאתה רואה, ה-DataFrame יכול להשוות לטבלה המכילה ערכים הטריים. גם גודל ה-DataFrame יכול להשתנות. סיפקנו את הנתונים בצורה של מפה והמפה משתמשת במפתחותיה כתווי השורות של Pandas. האינדקס מוצג בעמודה השמאלית ומכיל את תווי השורות. כותרת העמודה והנתונים מוצגים בצורה טבלאית. ניתן גם ליצור DataFrame עם אינדקס מזוהה, וזה נעשה על ידי הגדרת פרמטר האינדקס בשיטת DataFrame().
ייבא נתונים מ-CSV ל־DataFrame
ניתן גם ליצור DataFrame על ידי יבוא קובץ CSV. קובץ CSV הוא קובץ טקסט עם רשומה אחת של נתונים לכל שורה. הערכים בתוך הרשומה מופרדים באמצעות התו "פסיק". Pandas מספקת שיטה שימושית, בשם read_csv(), לקריאת תוכן הקובץ CSV ל־DataFrame. לדוגמה, ניתן ליצור קובץ בשם 'cities.csv' המכיל פרטי ערים בהודו. הקובץ CSV מאוחסן באותו ספרייה שמכילה סקריפטים ב-Python. ניתן לייבא את הקובץ הזה באמצעות:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. מטרתנו היא לטעון נתונים ולנתח אותם כדי להגיע למסקנות. לכן, ניתן להשתמש בכל שיטה נוחה לטעינת הנתונים. במדריך זה, אנו מכניסים את הנתונים של ה־DataFrame ישירות בקוד.
בדיקת נתונים ב־DataFrame
הרצת DataFrame באמצעות שמו מציגה את כל הטבלה. בזמן אמת, הקבצים הנתונים לניתוח יכולים להכיל אלפי שורות. עבור ניתוח הנתונים, אנו צריכים לבדוק נתונים מערכות נתונים בעלי נפחים גדולים. Pandas מספקת מספר רב של פונקציות שימושיות כדי לבדוק רק את הנתונים שאנו זקוקים אליהם. ניתן להשתמש ב־`df.head(n)` כדי לקבל את השורות הראשונות n או ב־`df.tail(n)` כדי להדפיס את השורות האחרונות n. לדוגמה, הקוד הבא מדפיס את השורות הראשונות 2 ואת השורה האחרונה מהDataFrame.
print(df.head(2))
פלט: 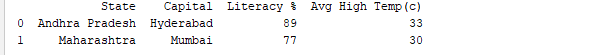
print(df.tail(1))
פלט: 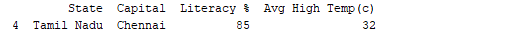 באופן דומה, `print(df.dtypes)` מדפיס את סוגי הנתונים. פלט:
באופן דומה, `print(df.dtypes)` מדפיס את סוגי הנתונים. פלט: 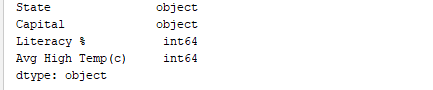 `print(df.index)` מדפיס את האינדקס. פלט:
`print(df.index)` מדפיס את האינדקס. פלט:  `print(df.columns)` מדפיס את העמודות של הDataFrame. פלט:
`print(df.columns)` מדפיס את העמודות של הDataFrame. פלט: 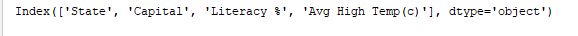 `print(df.values)` מציג את ערכי הטבלה. פלט:
`print(df.values)` מציג את ערכי הטבלה. פלט: 
1. קבלת סיכום סטטיסטי של רשומות
ניתן לקבל סיכום סטטיסטי (ספירה, ממוצע, סטיית תקן, מינימום, מקסימום וכו') של הנתונים באמצעות הפונקציה df.describe(). כעת, בואו נשתמש בפונקציה זו כדי להציג את הסיכום הסטטיסטי של עמודת "אחוזי קריאות". כדי לעשות זאת, נוסיף את קטע הקוד הבא:
print(df['Literacy %'].describe())
פלט: 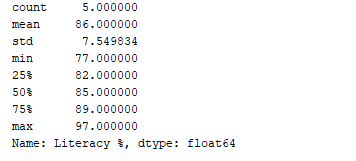 פונקציה
פונקציה df.describe() מציגה את הסיכום הסטטיסטי, יחד עם סוגי הנתונים.
2. מיון רשומות
ניתן למיין רשומות לפי עמודה כלשהי באמצעות הפונקציה df.sort_values(). לדוגמה, בואו נמיין את עמודת "אחוזי קריאות" בסדר יורד.
print(df.sort_values('Literacy %', ascending=False))
פלט: 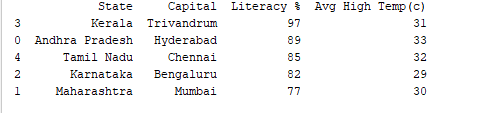
3. חתיכת רשומות
אפשר לחלץ נתונים מעמודה מסוימת על ידי שימוש בשם העמודה. לדוגמה, כדי לחלץ את עמודת 'בירה', נשתמש ב:
df['Capital']
או
(df.Capital)
פלט:  ניתן גם לחתוך עמודות מרובות. נעשה זאת על ידי סגירת שמות עמודות מרובות בסוגריים מרובעים, עם שמות העמודות מופרדים באמצעות פסיקים. הקוד הבא חותך את עמודות 'מדינה' ו-'בירה' של מסגרת הנתונים.
ניתן גם לחתוך עמודות מרובות. נעשה זאת על ידי סגירת שמות עמודות מרובות בסוגריים מרובעים, עם שמות העמודות מופרדים באמצעות פסיקים. הקוד הבא חותך את עמודות 'מדינה' ו-'בירה' של מסגרת הנתונים.
print(df[['State', 'Capital']])
פלט:  ניתן גם לחתוך שורות. ניתן לבחור שורות מרובות באמצעות אופרטור ":". הקוד למטה מחזיר את השורות הראשונות 3.
ניתן גם לחתוך שורות. ניתן לבחור שורות מרובות באמצעות אופרטור ":". הקוד למטה מחזיר את השורות הראשונות 3.
df[0:3]
פלט:  תכונה מעניינת של ספריית Pandas היא היכולת לבחור נתונים בהתבסס על תוויות השורות והעמודות שלה באמצעות הפונקציה
תכונה מעניינת של ספריית Pandas היא היכולת לבחור נתונים בהתבסס על תוויות השורות והעמודות שלה באמצעות הפונקציה iloc[0]. לעיתים רבות, נרצה רק כמה עמודות כדי לנתח. ניתן גם לבחור לפי אינדקס באמצעות loc['index_one']. לדוגמה, כדי לבחור את השורה השנייה, נוכל להשתמש ב־df.iloc[1,:]. נניח, נרצה לבחור את האיבר השני בעמודה השנייה. ניתן לעשות זאת באמצעות הפונקציה df.iloc[1,1]. בדוגמה זו, הפונקציה df.iloc[1,1] מציגה "מומבאי" כפלט.
4. סינון נתונים
ניתן גם לסנן על ערכי העמודות. לדוגמה, הקוד למטה מסנן את העמודות שיש להן אחוז הליטרציה מעל 90%.
print(df[df['Literacy %']>90])
כל מפעיל השוואה יכול לשמש לסינון, בהתבסס על תנאי. פלט:  דרך נוספת לסנן נתונים היא באמצעות השימוש ב־
דרך נוספת לסנן נתונים היא באמצעות השימוש ב־isin. הנה הקוד לסינון של שני מדינות בלבד, 'קרנטקה' ו'טמיל נאדו'.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
פלט: 
5. שינוי שם עמודה
ניתן להשתמש בפונקציית df.rename() כדי לשנות את שם העמודה. הפונקציה מקבלת את שם העמודה הישן ואת שם העמודה החדש כארגומנטים. לדוגמה, נשנה את שם העמודה 'Literacy %' ל־'Literacy percentage'.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
הארגומנט `inplace=True` מבצע את השינויים במסגרת המסד נתונים. פלט: 
6. עיבוד נתונים
מדע הנתונים משתלב בעיבוד הנתונים באופן שיהיה נוח לאלגוריתמים הנתונים. Data Wrangling הוא התהליך של עיבוד הנתונים, כולל מיזוג, קיבוץ וחיבור. ספריית Pandas מספקת פונקציות שימושיות כמו merge(), groupby() ו- concat() כדי לתמוך במשימות Data Wrangling. בואו ניצור שני DataFrame ונראה את פונקציות ה-Data Wrangling כדי להבין אותו טוב יותר.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
פלט:

בואו ניצור את ה-DataFrame השני באמצעות הקוד הבא:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
פלט:

a. Merging
עכשיו, בואו נמזג את שני ה-DataFrames שיצרנו, לפי ערכי העמודה 'Employee_id' באמצעות פונקציית merge():
print(pd.merge(df1, df2, on='Employee_id'))
פלט:

ניתן לראות כי פונקציית merge() מחזירה את השורות משני ה-DataFrames שיש להם את אותו ערך בעמודה שנמזגה.
b. Grouping
קיבוץ הוא תהליך של איסוף נתונים לקטגוריות שונות. לדוגמה, בדוגמה למטה, שדה "Employee_Name" מכיל את השם "מירה" פעמיים. לכן, בואו נקבץ אותו לפי עמודת "Employee_name".
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
שדה 'Employee_name' שהוא עם הערך 'מירה' מקובץ לפי עמודה "Employee_name". הפלט הדוגמה הוא כך:
פלט:
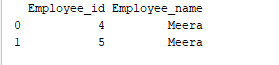
c. Concatenating
מחיבור נתונים מדובר בהוספת סט של נתונים לאחר. Pandas מספקת פונקציה בשם concat() לחיבור DataFrames. לדוגמה, נחבר את ה-DataFrames df1 ו־df2, באמצעות:
print(pd.concat([df1, df2]))
פלט: 
יצירת DataFrame על ידי מעבר של מילון של Series
כדי ליצור Series, ניתן להשתמש בשיטת pd.Series() ולמסור לה מערך. ניצור סדרה פשוטה כדלקמן:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
פלט:  יצרנו סדרה. ניתן לראות ששתי עמודות מוצגות. העמודה הראשונה מכילה את ערכי האינדקס החל מ־0. העמודה השנייה מכילה את האלמנטים שעברו כסדרה. ניתן ליצור DataFrame על ידי מעבר של מילון של `Series`. ניצור DataFrame שנוצר על ידי איחוד והעברת אינדקסי הסדרות. דוגמה
יצרנו סדרה. ניתן לראות ששתי עמודות מוצגות. העמודה הראשונה מכילה את ערכי האינדקס החל מ־0. העמודה השנייה מכילה את האלמנטים שעברו כסדרה. ניתן ליצור DataFrame על ידי מעבר של מילון של `Series`. ניצור DataFrame שנוצר על ידי איחוד והעברת אינדקסי הסדרות. דוגמה
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
פלט דוגמה 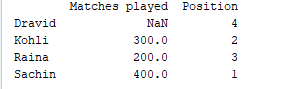 עבור הסדרה הראשונה, מכיוון שלא צוין תווית 'd', NaN חוזר.
עבור הסדרה הראשונה, מכיוון שלא צוין תווית 'd', NaN חוזר.
בחירת עמודה, הוספה, מחיקה
ניתן לבחור עמודה מסוימת מDataFrame. לדוגמה, כדי להציג רק את העמודה הראשונה, ניתן לכתוב מחדש את הקוד מעלה כך:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
הקוד מעלה מדפיס רק את העמודה "משחקים שנערכו" של DataFrame. פלט 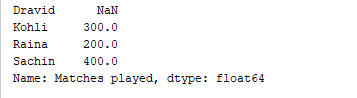 ניתן גם להוסיף עמודות לDataFrame קיים. לדוגמה, הקוד הבא מוסיף עמודה חדשה בשם "קצב ריצה" לDataFrame מעלה.
ניתן גם להוסיף עמודות לDataFrame קיים. לדוגמה, הקוד הבא מוסיף עמודה חדשה בשם "קצב ריצה" לDataFrame מעלה.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
פלט:  ניתן למחוק עמודות באמצעות הפונקציות `delete` ו- `pop`. לדוגמה, כדי למחוק את העמודה 'משחקים שנערכו' בדוגמה הנ"ל, ניתן לעשות זאת באחת משתי הדרכים הבאות:
ניתן למחוק עמודות באמצעות הפונקציות `delete` ו- `pop`. לדוגמה, כדי למחוק את העמודה 'משחקים שנערכו' בדוגמה הנ"ל, ניתן לעשות זאת באחת משתי הדרכים הבאות:
del df['Matches played']
או
df.pop('Matches played')
פלט: 
מסקנה
במדריך זה, קיבלנו הקדמה קצרה לספריית Pandas של Python. עשינו גם דוגמאות מעשיות כדי לשחרר את כוח הספרייה של Pandas המשמשת בתחום של מדעי הנתונים. עברנו גם דרך יצירת מבני נתונים שונים בספריית Python. מקור: אתר הרשמי של Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial