













Scikit Learn
 Scikit-learn הוא ספרייה ללמידת מכונה עבור Python. הוא כולל מספר אלגוריתמים לרגרסיה, סיווג ואשוח בתוכנית כולל SVMs, הגברת השוליים, k-means, יערות אקראיים ו-DBSCAN. הוא מיועד לעבוד עם Python Numpy ו-SciPy. פרויקט scikit-learn התחיל כפרויקט של גוגל סאמר אוף קוד (שם נוסף GSoC) של דיוויד קורנפו כ-scikits.learn. השם שלו מגיע מ-"Scikit", הוספה חיצונית נפרדת ל-SciPy.
Scikit-learn הוא ספרייה ללמידת מכונה עבור Python. הוא כולל מספר אלגוריתמים לרגרסיה, סיווג ואשוח בתוכנית כולל SVMs, הגברת השוליים, k-means, יערות אקראיים ו-DBSCAN. הוא מיועד לעבוד עם Python Numpy ו-SciPy. פרויקט scikit-learn התחיל כפרויקט של גוגל סאמר אוף קוד (שם נוסף GSoC) של דיוויד קורנפו כ-scikits.learn. השם שלו מגיע מ-"Scikit", הוספה חיצונית נפרדת ל-SciPy.
Python Scikit-learn
Scikit כתוב ב-Python (רובו) וחלק מהאלגוריתמים היסודיים שלו כתובים ב-Cython לביצועים אפילו טובים יותר. Scikit-learn משמש לבניית מודלים ואין מומלץ להשתמש בו לקריאה, עיבוד וסיכום נתונים מכיוון שישנם מסגרות טובות יותר למטרה זו. הוא תואם פתח ושוחרר תחת רישיון BSD.
התקן את Scikit Learn
Scikit מניח שיש לך פלטפורמת Python רצה בגרסה 2.7 או מעלה עם חבילות NumPY (1.8.2 ומעלה) ו־SciPY (0.13.3 ומעלה) על המכשיר שלך. לאחר שנתקין את החבילות האלה, נוכל להמשיך עם ההתקנה. להתקנת pip, הריצו את הפקודה הבאה בטרמינל:
pip install scikit-learn
אם אתם מעדיפים את conda, תוכלו גם להשתמש ב־conda עבור התקנת החבילות, הריצו את הפקודה הבאה:
conda install scikit-learn
שימוש ב־Scikit-Learn
לאחר שתסיימו עם ההתקנה, תוכלו להשתמש ב־scikit-learn בקלות בקוד Python שלכם על ידי יבואו כך:
import sklearn
טעינת קבוצת נתונים ב־Scikit Learn
בואו נתחיל עם טעינת קבוצת נתונים כדי לשחק עם. בואו נטען קבוצת נתונים פשוטה בשם Iris. זו קבוצת נתונים של פרח, היא מכילה 150 תצפיות על מדידות שונות של הפרח. בואו נראה כיצד לטעון את הקבוצת נתונים באמצעות scikit-learn.
# יבוא scikit learn
from sklearn import datasets
# טעינת נתונים
iris= datasets.load_iris()
# הדפסת צורת הנתונים כדי לאשר שהנתונים נטענו
print(iris.data.shape)
אנו מדפיסים את צורת הנתונים לצורך נוחות, תוכלו גם להדפיס את כל הנתונים אם תרצו, בהרצת הקודים נקבל פלט כזה: 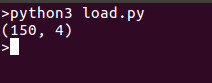
Scikit Learn SVM – למידה וחיזוי
עכשיו שטענו את הנתונים, בואו ננסה ללמוד מהם ולחזות על נתונים חדשים. למטרה זו עלינו ליצור מערכת ולקרוא לשיטת ההתאמה שלה.
from sklearn import svm
from sklearn import datasets
# טעינת קובץ
iris = datasets.load_iris()
clf = svm.LinearSVC()
# למידה מהנתונים
clf.fit(iris.data, iris.target)
# חיזוי על נתונים שלא נראו קודם
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# ניתן לשנות פרמטרים של המודל על ידי שימוש במאפיינים שמסתיימים בקו תחתון
print(clf.coef_ )
הנה מה שאנו מקבלים כאשר אנו מריצים סקריפט זה: 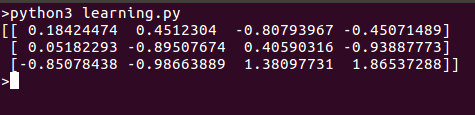
Scikit Learn התאמה ליניארית
יצירת מודלים שונים די פשוטה באמצעות scikit-learn. בואו נתחיל עם דוגמה פשוטה של רגרסיה.
#import את המודל
from sklearn import linear_model
reg = linear_model.LinearRegression()
# השתמש בו כדי להתאים נתונים
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# בואו נבדוק את הנתונים שהותאמו
print(reg.coef_)
הרצת המודל אמורה להחזיר נקודה שניתן לשרטט על אותו קו: 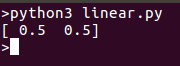
k-Nearest neighbour classifier
בואו ננסה אלגוריתם סיווג פשוט. מחלק הסיווג הזה משתמש באלגוריתם המבוסס על עצי כדורים כדי לייצג את דוגמי האימון.
from sklearn import datasets
# טען סט נתונים
iris = datasets.load_iris()
# צור והתאם מחלק סמוכים ביותר
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# תחזיר והדפס את התוצאה
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
בואו נריץ את המחלק ונבדוק תוצאות, המחלק אמור להחזיר 0. בואו ננסה את הדוגמה: 
K-means clustering
זהו האלגוריתם לקבוצות הכי פשוט. הסט מחולק ל- 'k' קבוצות וכל תצפיה מוקצת לקבוצה. זה נעשה בצורה דומה עד שהקבוצות מתכנסות. ניצור מודל כזה לאיחוד הקבוצות בתכנית הבאה:
from sklearn import cluster, datasets
# טען נתונים
iris = datasets.load_iris()
# צור קבוצות ל- k=3
k=3
k_means = cluster.KMeans(k)
# התאם נתונים
k_means.fit(iris.data)
# הדפס תוצאות
print( k_means.labels_[::10])
print( iris.target[::10])
בהרצת התוכנית נראה קבוצות נפרדות ברשימה. הנה הפלט עבור קטע הקוד למעלה: 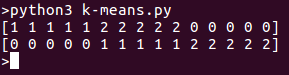
מסקנה
במדריך זה, ראינו ש-Scikit-Learn עושה קל לעבוד עם מספר אלגוריתמים למידת מכונה. ראינו דוגמאות של רגרסיה, סיווג ואשכולות. Scikit-Learn עדיין בשלבי פיתוח ומתפתח ומתוחזק על ידי מתנדבים אך הוא מאוד פופולרי בקהילה. תיכנסו ותנסו את הדוגמאות שלכם.
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial