













Grafana Loki est un système d’agrégation de journaux hautement disponible et scalable horizontalement. Il est conçu pour la simplicité et l’efficacité en termes de coûts. Créé par Grafana Labs en 2018, Loki est rapidement devenu une alternative convaincante aux systèmes de journalisation traditionnels, en particulier pour les environnements cloud-native et Kubernetes.
Loki peut fournir un parcours de journal complet. Nous pouvons sélectionner les flux de journaux appropriés, puis les filtrer pour nous concentrer sur les journaux pertinents. Nous pouvons ensuite analyser les données de journal structurées pour les formater selon nos besoins d’analyse personnalisés. Les journaux peuvent également être transformés de manière appropriée pour la présentation, par exemple, ou pour un traitement ultérieur en pipeline.
Loki s’intègre parfaitement avec l’écosystème plus large de Grafana. Les utilisateurs peuvent interroger les journaux en utilisant LogQL – un langage de requête conçu intentionnellement pour ressembler à Prometheus PromQL. Cela offre une expérience familière aux utilisateurs déjà familiarisés avec les métriques Prometheus et permet une puissante corrélation entre les métriques et les journaux au sein des tableaux de bord Grafana.
Cet article commence par les principes fondamentaux de Loki, suivi d’un aperçu architectural de base. Les bases de LogQL suivent, et nous concluons avec les compromis impliqués.
Principes fondamentaux de Loki
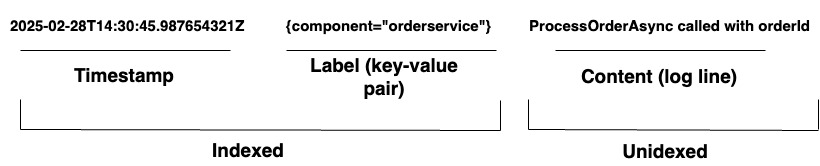
Pour les organisations gérant des systèmes complexes, Loki fournit une solution de journalisation unifiée. Il prend en charge l’ingestion de journaux à partir de n’importe quelle source via une large gamme d’agents ou son API, garantissant une couverture complète du matériel et des logiciels divers. Loki stocke ses journaux sous forme de flux de journaux, comme indiqué dans le schéma 1. Chaque entrée comporte les éléments suivants :
- Un horodatage avec une précision de nanoseconde
- Paires clé-valeur appelées étiquettes sont utilisées pour rechercher des journaux. Les étiquettes fournissent les métadonnées de la ligne de journal. Elles sont utilisées pour l’identification et la récupération des données. Elles forment l’index des flux de journaux et structurent le stockage des journaux. Chaque combinaison unique d’étiquettes et de leurs valeurs définit un flux de journal distinct. Les entrées de journal au sein d’un flux sont regroupées, compressées et stockées en segments.
- Le contenu du journal réel. Il s’agit de la ligne de journal brute. Il n’est pas indexé et est stocké par tranches compressées.
Architecture
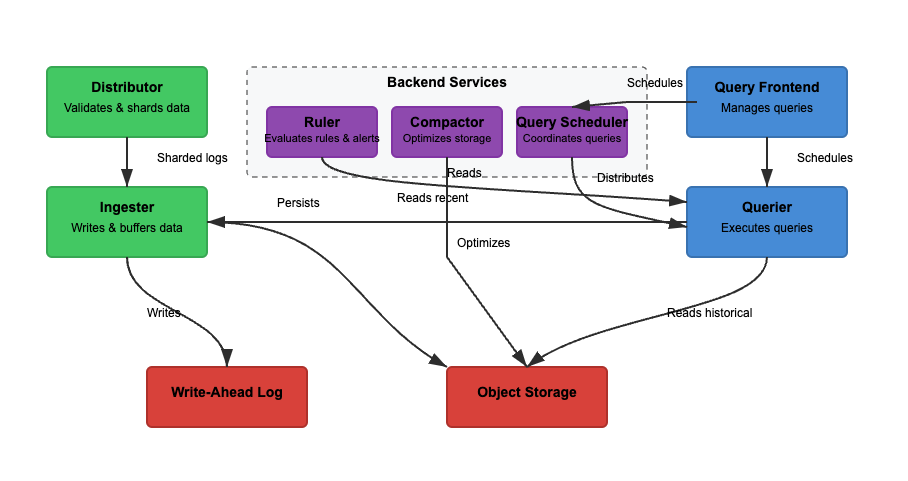
Nous allons analyser l’architecture de Loki en nous basant sur trois fonctionnalités de base. L’écriture, la lecture et le stockage des journaux. Loki peut fonctionner en mode monolithique (un seul binaire) ou en mode microservices, où les composants sont séparés pour un dimensionnement indépendant. Les fonctionnalités de lecture et d’écriture peuvent être dimensionnées de manière indépendante pour s’adapter à des cas d’utilisation spécifiques. Examinons chaque chemin plus en détail.
Écriture
Dans le Schéma 2, le chemin d’écriture est le chemin vert. Lorsque les journaux entrent dans Loki, les répartiteurs répartissent les journaux en fonction des étiquettes. L’ingesteur stocke ensuite les journaux en mémoire, et le compacteur optimise le stockage. Les principales étapes impliquées sont les suivantes.
Étape 1 : Les Journaux Entrent dans Loki
Les écritures pour les journaux entrants arrivent au répartiteur. Les journaux sont structurés en flux, avec des étiquettes (comme {job="nginx", level="error"}). Le répartiteur répartit les journaux, partitionne les journaux et envoie les journaux aux ingesteurs. Il hache les étiquettes de chaque flux et les attribue à un ingesteur en utilisant un hachage cohérent. Les répartiteurs valident les journaux et empêchent les données mal formées. Le hachage cohérent peut garantir une distribution uniforme des journaux entre les ingesteurs.
Étape 2: Stockage à Court Terme
L’ingesteur stocke les journaux en mémoire pour une récupération rapide. Les journaux sont regroupés et écrits dans des journaux d’avance (WAL) pour éviter la perte de données. Les WAL aident à la durabilité mais ne sont pas interrogeables directement – les ingesteurs doivent toujours rester en ligne pour interroger les journaux récents.
Périodiquement, les journaux sont vidés des ingesteurs vers le stockage objet. Le requêteur et le régulateur lisent l’ingesteur pour accéder aux données les plus récentes. Le requêteur peut également accéder aux données du stockage objet.
Étape 3: Les Journaux Passent au Stockage à Long Terme
Le compacteur traite périodiquement les journaux stockés à partir du stockage à long terme (object-storage). Le stockage d’objets est bon marché et évolutif. Il permet à Loki de stocker de grandes quantités de journaux sans coûts élevés. Le compacteur déduplique les journaux redondants, compresse les journaux pour une efficacité de stockage, et supprime les anciens journaux en fonction des paramètres de rétention. Les journaux sont stockés au format segmenté (non indexé en texte intégral).
Lecture
Dans le Schéma 2, le chemin de lecture est le chemin bleu. Les requêtes vont vers le frontal de requête, et le requêteur récupère les journaux. Les journaux sont filtrés, analysés et analysés à l’aide de LogQL. Les principales étapes impliquées sont les suivantes.
Étape 1 : Le frontal de requête optimise les requêtes
Les utilisateurs interrogent les journaux à l’aide de LogQL dans Grafana. Le frontal de requête divise les requêtes volumineuses en plus petits morceaux et les distribue à travers plusieurs requêteurs, car l’exécution parallèle accélère les requêtes. Il est responsable de l’accélération de l’exécution des requêtes et de la garantie de nouvelles tentatives en cas d’échec. Le frontal de requête aide à éviter les délais d’attente et les surcharges, tandis que les requêtes échouées sont automatiquement réessayées.
Étape 2 : Le requêteur récupère les journaux
Les requêteurs analysent le LogQL et interrogent les ingesteurs et le stockage d’objets. Les journaux récents sont récupérés à partir des ingesteurs, et les anciens journaux sont extraits du stockage d’objets. Les journaux avec la même horodatage, étiquettes et contenu sont dédupliqués.
Les filtres de Bloom et les étiquettes d’index sont utilisés pour trouver efficacement les journaux. Les requêtes d’agrégation, comme count_over_time(), s’exécutent plus rapidement car Loki n’indexe pas entièrement les journaux. Contrairement à Elasticsearch, Loki n’indexe pas le contenu complet des journaux.
Au lieu de cela, il indexe des étiquettes de métadonnées ({app="nginx", level="error"}), ce qui permet de trouver des journaux de manière efficace et économique. Les recherches en texte intégral ne sont effectuées que sur des morceaux de journaux pertinents, réduisant les coûts de stockage.
Principes de LogQL
LogQL est le langage de requête utilisé dans Grafana Loki pour rechercher, filtrer et transformer les journaux de manière efficace. Il se compose de deux composants principaux:
- Sélecteur de flux – Sélectionne les flux de journaux en fonction des correspondances d’étiquettes
- Filtrage et transformation – Extrait les lignes de journaux pertinentes, analyse les données structurées et formate les résultats de la requête
En combinant ces fonctionnalités, LogQL permet aux utilisateurs de récupérer efficacement des journaux, d’extraire des informations et de générer des métriques utiles à partir des données de journal.
Sélecteur de flux
Un sélecteur de flux est la première étape de chaque requête LogQL. Il sélectionne les flux de journaux en fonction des correspondances d’étiquettes. Pour affiner les résultats de la requête vers des flux de journaux spécifiques, nous pouvons utiliser des opérateurs de base pour filtrer par étiquettes Loki. Améliorer la précision de notre sélection de flux de journaux réduit le volume de flux analysés, ce qui augmente la vitesse de la requête.
Exemples
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobFiltres de ligne
Une fois les journaux sélectionnés, les filtres de ligne affinent les résultats en recherchant un texte spécifique ou en appliquant des conditions logiques. Les filtres de ligne agissent sur le contenu des journaux, pas sur les étiquettes.
Exemples
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)Parseurs
Loki peut accepter des journaux non structurés, semi-structurés ou structurés. Cependant, comprendre les formats de journal avec lesquels nous travaillons est crucial lors de la conception et de la construction de solutions d’observabilité. De cette manière, nous pouvons ingérer, stocker et analyser les données de journal pour les utiliser efficacement. Loki prend en charge les analyseurs JSON, logfmt, pattern, regexp et unpack.
Exemples
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesFiltres d’étiquettes
Une fois analysés, les journaux peuvent être filtrés par des champs extraits. Les étiquettes peuvent être extraites dans le cadre du pipeline de journal en utilisant des expressions d’analyseur et de formateur. L’expression de filtre d’étiquette peut ensuite être utilisée pour filtrer notre ligne de journal avec l’une de ces étiquettes.
Exemples
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminFormat de ligne
Utilisé pour modifier la sortie de journal en extrayant et en formatant des champs. Cela détermine comment les journaux sont affichés dans Grafana.
Exemple
{app="nginx"} | json | line_format "User {user} encountered {status} error"Format d’étiquette
Utilisé pour renommer, modifier, créer ou supprimer des étiquettes. Il accepte une liste séparée par des virgules d’opérations d’égalité, permettant ainsi à plusieurs opérations d’être effectuées simultanément.
Exemples
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level Compromis
Grafana Loki offre une solution de journalisation rentable et évolutive qui stocke les journaux par blocs compressés avec un indexage minimal. Cela implique des compromis en termes de performances de requête et de vitesse de récupération. Contrairement aux systèmes traditionnels de gestion des journaux qui indexent le contenu complet du journal, l’indexation basée sur les étiquettes de Loki accélère le filtrage.
Cependant, cela peut ralentir les recherches de texte complexes. De plus, bien que Loki excelle dans la gestion d’environnements distribués à haut débit, il dépend du stockage objet pour la scalabilité. Cela peut introduire une latence et nécessite une sélection minutieuse des libellés pour éviter les problèmes de cardinalité élevée.
Scalabilité et Multilocataire
Loki est conçu pour la scalabilité et le multilocataire. Cependant, la scalabilité s’accompagne de compromis architecturaux. Mettre à l’échelle les écritures (ingesters) est simple grâce à la capacité de fragmenter les journaux en fonction du partitionnement basé sur les libellés. Mettre à l’échelle les lectures (queriers) est plus délicat car interroger de grands ensembles de données depuis un stockage objet peut être lent. Le multilocataire est pris en charge, mais la gestion des quotas spécifiques aux locataires, de l’explosion des libellés et de la sécurité (isolation des données par locataire) nécessite une configuration minutieuse.
Ingestion Simple Sans Pré-analyse
Loki ne nécessite pas de pré-analyse car il n’indexe pas le contenu complet des journaux. Il stocke les journaux dans un format brut en blocs compressés. Étant donné que Loki ne dispose pas d’indexation de texte intégrale, l’interrogation des journaux structurés (par exemple, JSON) nécessite une analyse LogQL. Cela signifie que les performances d’interrogation dépendent de la façon dont les journaux sont structurés avant l’ingestion. Sans journaux structurés, l’efficacité de l’interrogation en souffre car le filtrage doit se faire au moment de la récupération, et non de l’ingestion.
Stockage dans un Stockage Objet
Loki envoie les blocs de journaux vers un stockage objet (par exemple, S3, GCS, Azure Blob). Cela réduit la dépendance vis-à-vis des stockages de blocs coûteux comme, par exemple, Elasticsearch l’exige.
Cependant, lire les journaux depuis le stockage d’objets peut être lent par rapport à une requête directe depuis une base de données. Loki compense cela en conservant les journaux récents dans les ingesteurs pour une récupération plus rapide. La compaction réduit la surcharge de stockage, mais la latence de récupération des journaux peut encore poser problème pour les requêtes à grande échelle.
Étiquettes et Cardinalité
Comme les étiquettes sont utilisées pour rechercher des journaux, elles sont essentielles pour des requêtes efficaces. Un mauvais étiquetage peut entraîner des problèmes de haute cardinalité. L’utilisation d’étiquettes à haute cardinalité (par exemple, user_id, session_id) augmente l’utilisation de la mémoire et ralentit les requêtes. Loki hache les étiquettes pour distribuer les journaux à travers les ingesteurs, donc une mauvaise conception d’étiquettes peut provoquer une répartition inégale des journaux.
Filtrage Précoce
Étant donné que Loki stocke des journaux bruts compressés dans le stockage d’objets, il est important de filtrer tôt si nous voulons que nos requêtes soient rapides. Le traitement d’analyses complexes sur des ensembles de données plus petits augmentera le temps de réponse. Selon cette règle, une bonne requête serait la Requête 1, et une mauvaise requête serait la Requête 2.
Requête 1
{job="nginx", status_code=~"5.."} | jsonLa Requête 1 filtre les journaux où job="nginx" et où le status_code commence par 5 (erreurs 500-599). Ensuite, elle extrait des champs JSON structurés en utilisant | json. Cela réduit le nombre de journaux traités par l’analyseur JSON, le rendant plus rapide.
Requête 2
{job="nginx"} | json | status_code=~"5.."La Requête 2 récupère d’abord tous les journaux de nginx. Cela pourrait être des millions d’entrées. Ensuite, elle analyse le JSON pour chaque entrée de journal avant de filtrer par status_code. C’est inefficace et considérablement plus lent.
Conclusion
Grafana Loki est un puissant système d’agrégation de journaux, rentable et conçu pour l’évolutivité et la simplicité. En indexant uniquement les métadonnées, il maintient les coûts de stockage bas tout en permettant des requêtes rapides à l’aide de LogQL.
Son architecture microservices supporte des déploiements flexibles, ce qui le rend idéal pour les environnements cloud-natifs. Cet article aborde les bases de Loki et de son langage de requête. En naviguant à travers les caractéristiques saillantes de l’architecture de Loki, nous pouvons mieux comprendre les compromis impliqués.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture