













Ayant utilisé Amazon Aurora pendant un certain temps maintenant dans diverses entreprises, j’ai vu de première main comment il excelle en tant que moteur de base de données relationnelle entièrement géré, offrant des performances élevées, une évolutivité et une fiabilité.
En tant que solution native du cloud prenant en charge MySQL et PostgreSQL, Aurora est un excellent choix pour les entreprises qui nécessitent une disponibilité élevée et un dimensionnement automatique. Comme AWS gère les sauvegardes, la bascule et la réplication automatiquement, l’utilisation d’Aurora vous permet d’augmenter l’efficacité de la base de données tout en réduisant les coûts de maintenance.
Dans ce tutoriel, je vous guiderai à travers la configuration d’une instance Aurora, sa gestion efficace, l’optimisation des performances, et la garantie de la sécurité et de la rentabilité.
Qu’est-ce qu’AWS Aurora?
Amazon Aurora est une base de données relationnelle basée sur le cloud qui surpasse les bases de données traditionnelles MySQL et PostgreSQL en redimensionnant dynamiquement les ressources de stockage et de calcul.
Selon AWS, Aurora peut fournir jusqu’à cinq fois le débit de MySQL standard et trois fois les performances de PostgreSQL standard – en raison de son architecture distribuée et hautement disponible.
Aurora est dotée de fonctionnalités telles que des sauvegardes automatiques, des réplicas de lecture pour le dimensionnement horizontal et des mécanismes de basculement qui garantissent un temps d’arrêt minimal.
La couche de stockage d’Aurora est conçue pour être tolérante aux pannes et autoréparatrice.
De plus, les données sont automatiquement répliquées dans plusieurs zones de disponibilité (AZ) pour garantir la durabilité.
L’image ci-dessous donne un aperçu général de l’architecture et des fonctionnalités clés d’Amazon Aurora.
La relation entre le volume du cluster, l’instance DB en écriture et les instances DB en lecture dans un cluster Aurora. Source: Documentation AWS
Le moteur de base de données surveille continuellement les requêtes et optimise les plans d’exécution, ce qui entraîne des améliorations significatives de l’efficacité.
L’un des principaux avantages d’Aurora est sa compatibilité avec les bases de données existantes MySQL et PostgreSQL, ce qui facilite la migration des entreprises sans avoir besoin de modifier considérablement leurs applications.
La structure de coûts d’Aurora est également attrayante. Elle facture en fonction de l’utilisation réelle des ressources de calcul et de stockage. Ce modèle de coût élimine le besoin de surdimensionner l’infrastructure, ce qui permet d’économiser de l’argent.
> Si vous souhaitez avoir une compréhension plus large des options de stockage d’AWS, consultez ce Tutoriel sur le stockage AWS.
Mise en place d’AWS Aurora
La configuration d’AWS Aurora implique la création d’un cluster de base de données, la configuration des paramètres de sécurité et la garantie d’un accès réseau adéquat. Faisons cela dans cette section!
> Si vous êtes nouveau sur AWS, envisagez de passer en revue les sujets fondamentaux avec le cours d’Introduction à AWS avant de plonger dans Aurora.
Création d’un cluster de base de données Aurora
La configuration d’un cluster de base de données Aurora nécessite quelques étapes clés, notamment le choix du moteur de base de données approprié, la configuration des paramètres de sécurité et la définition des spécifications d’instance.
- Pour commencer, connectez-vous à la console de gestion AWS et accédez au tableau de bord RDS (Relational Database Service).
- Vous pouvez le faire en recherchant « Aurora » dans le panneau de recherche de la console de gestion AWS – comme indiqué dans l’image ci-dessous.
- Une fois sur place, cliquez sur “Créer une base de données” – comme indiqué dans l’image ci-dessous.
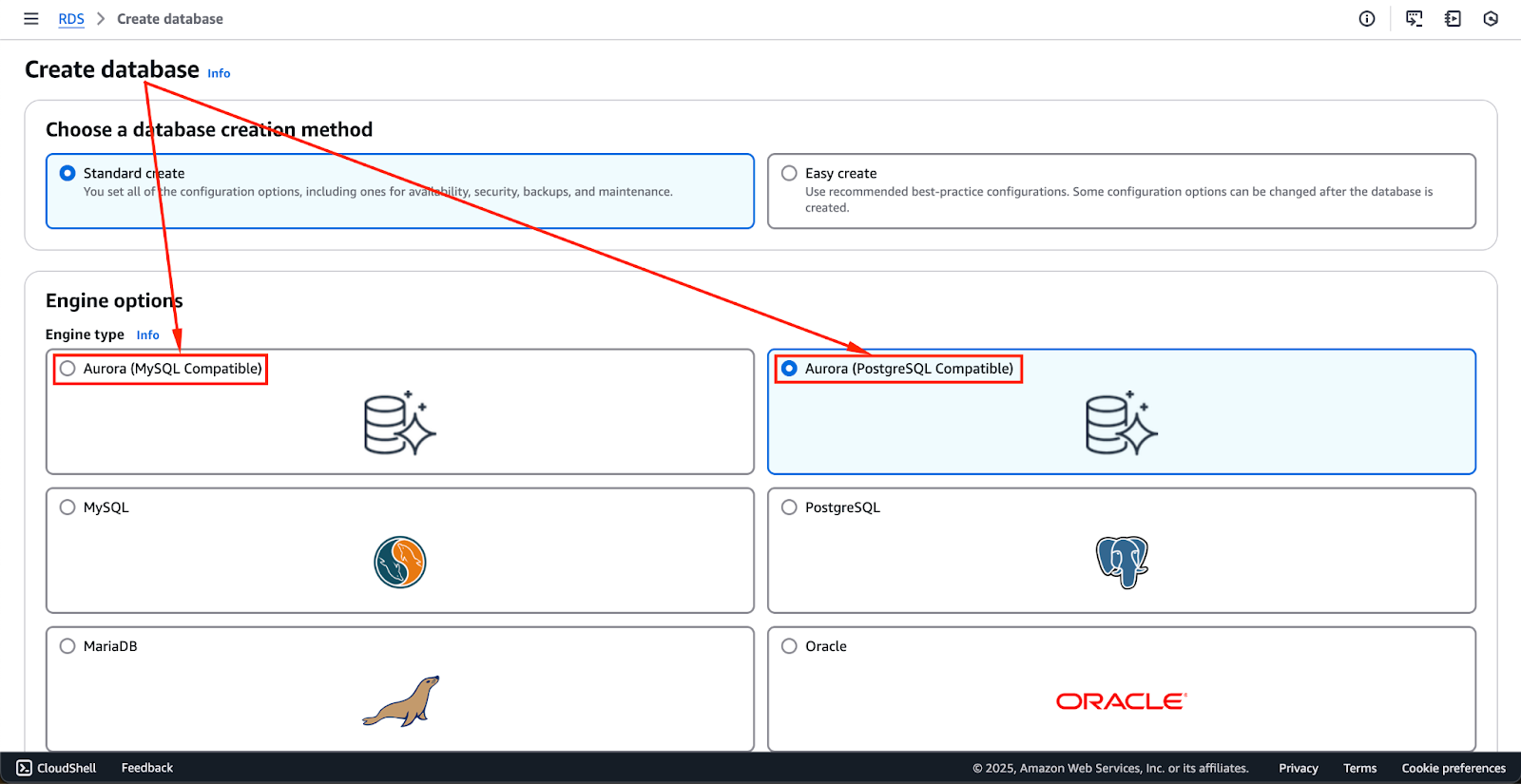
- Vous aurez alors la possibilité de choisir « Amazon Aurora » comme moteur de base de données.
- N’oubliez pas qu’Aurora prend en charge à la fois MySQL et PostgreSQL, il est donc important de sélectionner la version qui répond le mieux aux exigences de votre application.
L’image ci-dessous montre les options de moteur actuellement disponibles. Elles pourraient changer à l’avenir, mais les deux premières options – Aurora (compatible avec MySQL) et Aurora (compatible avec PostgreSQL) – sont les moteurs Aurora.
- Après avoir sélectionné le moteur, vous devez spécifier le type d’instance et les configurations de stockage.
- Aurora offre la flexibilité de mettre automatiquement à l’échelle le stockage jusqu’à 128 To, garantissant que les charges de travail croissantes sont gérées efficacement sans nécessiter d’intervention manuelle.
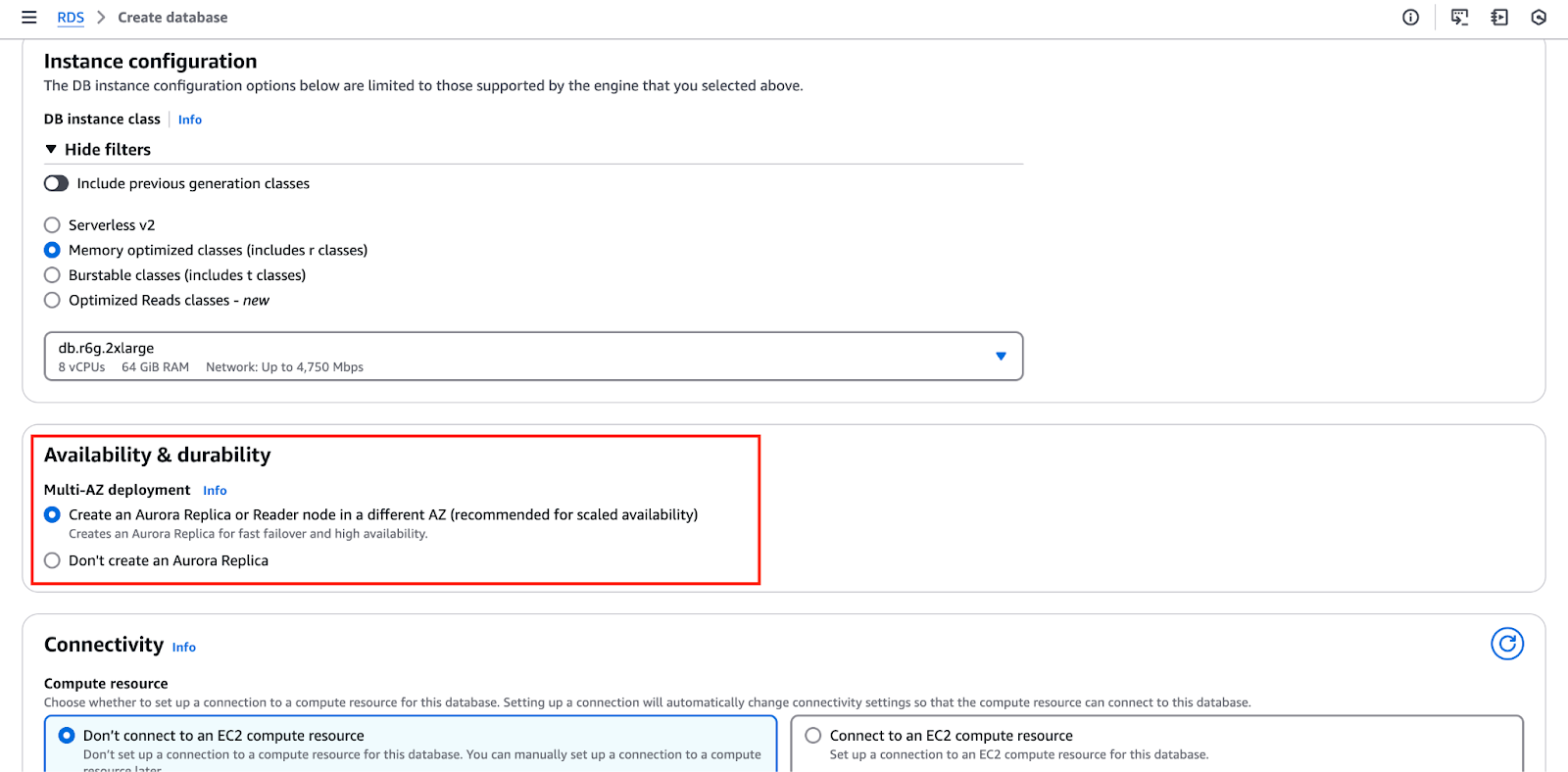
- La prochaine étape consiste à définir les paramètres de réplication. Vous pouvez opter pour un déploiement sur une seule instance ou activer des réplicas de lecture pour distribuer le trafic de la base de données de manière plus efficace.
- L’utilisation de réplicas de lecture améliore également la disponibilité et la tolérance aux pannes, garantissant ainsi une durabilité accrue en cas de défaillance.
L’image ci-dessous met en évidence la section « Disponibilité et durabilité », où vous pouvez configurer ces paramètres.
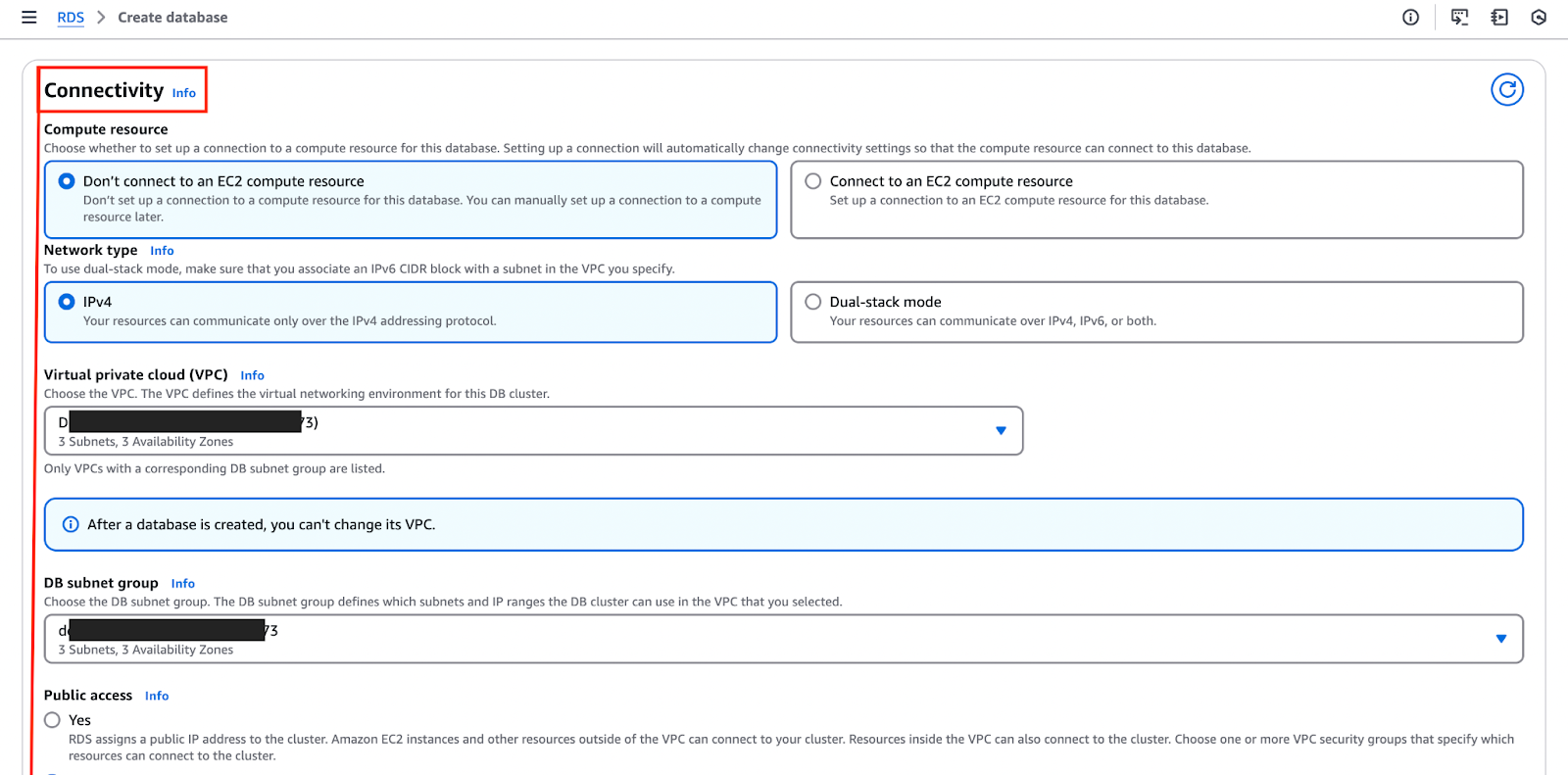
- La configuration du réseau est cruciale, car elle implique la mise en place du Cloud privé virtuel (VPC), la sélection d’un groupe de sécurité et la définition des contrôles d’accès.
- Un groupe de sécurité agit comme un pare-feu qui régule le trafic entrant et sortant de la base de données. Pour renforcer la sécurité, il est recommandé de n’autoriser l’accès qu’à partir d’adresses IP et d’applications de confiance.
L’image ci-dessous met en évidence la section « Connectivité », où vous pouvez configurer et personnaliser ces paramètres.
- Les informations d’identification de la base de données doivent également être configurées lors de la mise en place – vous attribuez un nom d’utilisateur principal et un mot de passe qui seront utilisés pour authentifier les connexions.
- Aurora permet d’activer des sauvegardes automatisées et des options de récupération à un instant donné. Cela garantit que des instantanés de la base de données sont créés de manière cohérente pour éviter toute perte de données.
Après avoir examiné toutes les configurations, vous pouvez procéder à la création du cluster Aurora. L’image ci-dessous montre le bouton « Créer une base de données » sur lequel vous pouvez cliquer pour lancer le processus de création.
Le processus de provisionnement peut prendre plusieurs minutes, en fonction de la taille de l’instance sélectionnée et des paramètres réseau.
> Si vous êtes nouveau dans les services AWS, la revue du cours Technologie et services Cloud AWS peut vous aider à comprendre les concepts clés d’AWS pertinents pour la configuration d’Aurora.Configurer le réseau et la sécurité peut vous aider à comprendre les concepts clés d’AWS pertinents pour la configuration d’Aurora.
Configuring network and security
La sécurité est essentielle pour la gestion d’une base de données Aurora, et AWS propose plusieurs outils pour imposer des contrôles d’accès solides.
- La première étape pour sécuriser une instance Aurora consiste à configurer des groupes de sécurité VPC. Ces groupes de sécurité déterminent quelles adresses IP et quels services peuvent interagir avec la base de données.
- Vous devriez limiter l’accès à des serveurs d’application spécifiques et à des administrateurs pour empêcher les connexions non autorisées.
- Identity and Access Management (IAM) d’AWS peut également être utilisé pour définir des permissions détaillées pour les opérations de base de données.
- L’intégration des rôles IAM vous permet de personnaliser l’accès à la base de données en fonction des rôles et responsabilités spécifiques des utilisateurs.
- Par exemple, les développeurs d’applications ne pourront peut-être avoir qu’un accès en lecture, tandis que les administrateurs auront un contrôle total sur les modifications de la base de données.
- Le chiffrement doit également être activé pour protéger les données sensibles. AWS Aurora prend en charge le chiffrement au repos et en transit en utilisant le service de gestion des clés AWS (KMS).
- Le chiffrement des données au repos garantit que même si le support de stockage est compromis, les données restent inaccessibles sans la clé de déchiffrement appropriée.
- De même, l’activation du chiffrement SSL (Secure Sockets Layer) pour les données en transit empêche l’interception non autorisée des communications de la base de données.
> Pour une plongée plus profonde dans la sécurisation des environnements AWS, jetez un coup d’œil au cours AWS Security and Cost Management. Si vous souhaitez en savoir plus sur le fonctionnement de IAM et comment l’implémenter efficacement, consultez ce guide sur la gestion des identités et des accès AWS (IAM).
Connexion à AWS Aurora
La connexion à AWS Aurora est essentielle pour interagir avec la base de données. Vous pouvez le faire soit via des outils clients, soit via des applications. Voyons comment dans cette section !
Connexion à Aurora MySQL
Une fois que la base de données Aurora est opérationnelle, vous devez établir une connexion pour commencer à interagir avec la base de données.
Pour Aurora MySQL, des clients de base de données courants tels que MySQL Workbench et HeidiSQL peuvent être utilisés pour se connecter. Alternativement, vous pouvez utiliser des interfaces en ligne de commande.
La connexion nécessite de spécifier le point de terminaison de la base de données, qui peut être trouvé dans la Console de gestion AWS.
En utilisant le CLI MySQL, la connexion peut être établie avec la commande suivante:
mysql -h your-cluster-endpoint -u admin -p
Après avoir saisi le mot de passe principal, vous devriez pouvoir exécuter des requêtes SQL, créer des tables et gérer des données.
Connexion à Aurora PostgreSQL
Pour Aurora PostgreSQL, vous pouvez vous connecter en utilisant des outils tels que pgAdmin ou l’interface en ligne de commande PostgreSQL (psql).
La commande de connexion dans psql suit ce format:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Tout comme avec MySQL, les identifiants corrects doivent être saisis pour accéder à la base de données.
Une fois que vous avez obtenu l’accès, vous devriez pouvoir exécuter des requêtes SQL, créer des tables et gérer des données.
Configuration de la connectivité de l’application
Les applications qui doivent interagir avec Aurora doivent être configurées avec les chaînes de connexion à la base de données appropriées. En général, ces chaînes de connexion se composent du nom d’utilisateur, du mot de passe, du numéro de port et de l’endpoint.
Il est recommandé d’utiliser le pooling de connexions pour optimiser les performances et réduire la surcharge liée à l’établissement de nouvelles connexions pour chaque requête.
Des bibliothèques populaires comme SQLAlchemy pour Python ou JDBC pour Java offrent des moyens efficaces de gérer les connexions dans un environnement d’application.
Gestion d’AWS Aurora
Gérer efficacement AWS Aurora implique d’assurer la protection des données, de surveiller les performances et de faire évoluer les ressources selon les besoins. Dans cette section, nous passerons en revue ces pratiques.
Sauvegardes et instantanés
AWS Aurora propose des sauvegardes automatisées qui capturent et stockent en continu les modifications de la base de données dans Amazon S3. Ces sauvegardes sont conservées en fonction des paramètres définis par l’utilisateur, permettant la restauration à tout moment dans la période de rétention.
En plus des sauvegardes automatisées, vous pouvez également créer des instantanés manuels qui persistent au-delà de la fenêtre de rétention. Les instantanés manuels sont particulièrement utiles pour l’archivage à long terme ou avant d’effectuer des mises à jour majeures de la base de données.
Lorsque j’ai travaillé sur un projet avec une application critique, nous avons programmé des sauvegardes automatisées toutes les deux heures. Cependant, avant d’apporter des modifications ou des mises à jour à l’application, nous créions manuellement une sauvegarde pour nous assurer que nous pouvions revenir en arrière si nécessaire. Cela démontre comment les sauvegardes automatisées et manuelles peuvent être utilisées efficacement ensemble.
L’image ci-dessous montre comment AWS Backup peut être utilisé pour la reprise après sinistre avec Amazon Aurora.
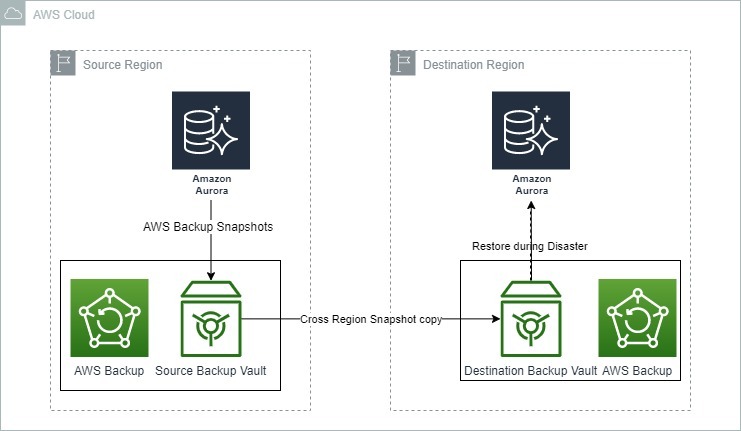
Options de sauvegarde et de récupération pour Amazon Aurora. Source : Blogs AWS
Surveillance d’Aurora avec CloudWatch
La surveillance des performances est essentielle pour maintenir une base de données saine.
AWS CloudWatch fournit des mesures en temps réel qui suivent l’utilisation du CPU, l’utilisation de la mémoire, les E/S disque et le trafic réseau.
La configuration des alarmes CloudWatch peut aider les administrateurs à être notifiés lorsque les seuils de performances sont dépassés, permettant une gestion proactive de la base de données.
En plus de cela, AWS Performance Insights offre une analyse détaillée des requêtes pour identifier et optimiser les requêtes lentes.
L’image ci-dessous montre comment AWS Performance Insights fournit des informations sur les performances de la base de données.
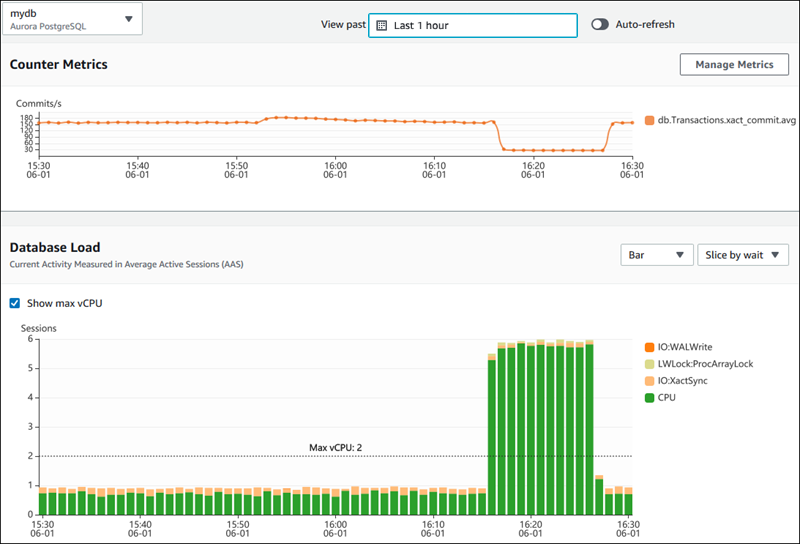
Tableau de bord AWS Performance Insights affichant les métriques de performances de la base de données. Source : Docs AWS
Scaling Aurora
Aurora est conçu pour se redimensionner automatiquement en ajustant la capacité de stockage selon les besoins. Cependant, les ressources de calcul telles que les CPUs et la mémoire peuvent nécessiter un ajustement manuel en fonction de la charge de travail.
Aurora propose des options pour ajuster la capacité de lecture en ajoutant des réplicas de lecture, qui répartissent le trafic de lecture et améliorent les performances.
Lorsque la haute disponibilité est critique, un cluster Aurora peut être configuré avec plusieurs réplicas dans différentes Zones de Disponibilité pour garantir une redondance en cas de basculement.
Optimisation des performances dans AWS Aurora
L’optimisation des performances dans Amazon Aurora garantit une exécution de requêtes efficace et une évolutivité. Examinons quelques bonnes pratiques dans cette section.
Indexation et optimisation des requêtes
Optimiser les performances des requêtes dans Amazon Aurora est crucial pour maintenir une base de données performante.
- L’indexation est l’un des moyens les plus efficaces pour réduire le temps d’exécution des requêtes et améliorer l’efficacité de la base de données.
- Créer des index sur les colonnes fréquemment interrogées peut aider à localiser rapidement les données, minimisant le besoin de parcourir l’intégralité de la table.
- Vous devriez utiliser stratégiquement des index primaires et secondaires pour correspondre aux motifs de requêtes et aux demandes de charge de travail.
- En plus de cela, vous pouvez utiliser des index composites pour les requêtes impliquant plusieurs colonnes afin d’améliorer davantage les temps de recherche.
- L’optimisation des requêtes joue également un rôle significatif dans les performances de la base de données. Rédiger des requêtes SQL efficaces garantit qu’Aurora traite les demandes plus rapidement avec une consommation minimale de ressources.
- Utiliser
EXPLAIN ou EXPLAIN ANALYZEdans les requêtes SQL aide à identifier les goulets d’étranglement et fournit un aperçu des plans d’exécution. - Des techniques telles que l’évitement de
SELECT *(qui récupère des données inutiles), la normalisation du schéma de base de données pour réduire la redondance, et l’exploitation des stratégies de partitionnement peuvent entraîner des gains de performance. - L’optimiseur de plan de requête d’Aurora affine en continu les plans d’exécution, ce qui permet d’apporter des ajustements en fonction des modèles de charge de travail de la base de données, améliorant ainsi l’efficacité globale.
Utiliser les répliques en lecture d’Aurora
Pour gérer des charges à fort trafic, Amazon Aurora prend en charge des répliques en lecture qui aident à distribuer les requêtes intensives en lecture sur plusieurs instances.
Les réplicas de lecture réduisent la charge sur l’instance de base de données principale en traitant les demandes de lecture séparément, ce qui améliore la réactivité et réduit la latence.
Pour configurer une réplica de lecture Aurora, vous devrez sélectionner un cluster Aurora existant et activer la réplication avec une configuration minimale. Aurora synchronise automatiquement les données entre l’instance principale et ses réplicas, garantissant la cohérence des données sans intervention manuelle.
Le mécanisme de réplication d’Aurora est très efficace, permettant une synchronisation des données quasi temps réel avec un délai de réplication de moins d’une seconde.
Les applications qui effectuent des opérations de lecture fréquentes, telles que les tableaux de bord de reporting ou les services d’analyse, peuvent bénéficier considérablement des réplicas de lecture en redirigeant les requêtes intensives en lecture vers ces instances.
En cas de défaillance de l’instance principale, une réplique en lecture peut être promue pour devenir la nouvelle instance principale avec un temps d’arrêt minimal, garantissant une haute disponibilité et la continuité des activités.
L’image ci-dessous montre comment les répliques Aurora interrégionales peuvent aider en cas de reprise après sinistre et de haute disponibilité.
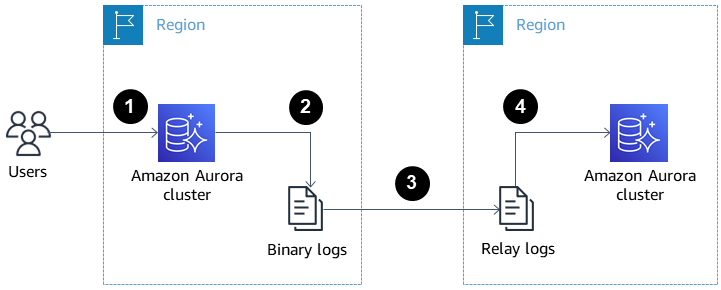
Répliques Aurora interrégionales pour la reprise après sinistre et la haute disponibilité. Source : Docs AWS
Stratégies de mise en cache pour Aurora
La mise en cache est une technique puissante pour améliorer les performances de la base de données en réduisant les charges de requêtes directes sur Aurora. Une couche de mise en cache peut accélérer considérablement la récupération des données pour les requêtes fréquemment consultées.
Amazon ElastiCache, qui prend en charge Redis et Memcached, est couramment utilisé aux côtés d’Aurora pour stocker les résultats de requête et éviter les requêtes redondantes à la base de données.
L’intégration de la mise en cache dans une architecture d’application peut aider à améliorer les temps de réponse tout en préservant les ressources de calcul de la base de données.
Des stratégies de mise en cache telles que la mise en cache en écriture directe (où les données sont écrites à la fois dans le cache et Aurora simultanément) et le chargement paresseux (où les données ne sont mises en cache que lorsqu’elles sont demandées) aident à optimiser les performances en fonction des modèles d’utilisation.
Configurer un temps de vie approprié (TTL) pour les données mises en cache garantit que le cache reste frais et empêche la récupération de données obsolètes.
Sécurité et conformité dans AWS Aurora
Sécuriser votre base de données Aurora est crucial pour protéger les données sensibles et garantir la conformité. Examinons les meilleures pratiques dans cette section.
Chiffrement des données
La sécurité des données est fondamentale pour la gestion de bases de données, et AWS Aurora propose des mécanismes de chiffrement robustes pour protéger les données sensibles.
- Aurora chiffre les données au repos en utilisant le service de gestion des clés AWS (KMS), ce qui garantit que les informations stockées restent sécurisées même si le stockage sous-jacent est compromis.
- Activer le cryptage lors de la création de la base de données garantit que toutes les sauvegardes automatiques, instantanés et répliques héritent des mêmes paramètres de cryptage.
- Pour les données en transit, Aurora prend en charge le cryptage SSL/TLS, qui sécurise les connexions de base de données et empêche l’accès non autorisé ou l’interception des transmissions de données.
- Les applications se connectant à Aurora doivent être configurées pour utiliser des certificats SSL afin de maintenir une communication sécurisée.
Ces mesures de cryptage peuvent vous aider à respecter les meilleures pratiques de sécurité et les exigences réglementaires.
L’image ci-dessous montre comment AWS KMS s’intègre avec Amazon Aurora pour crypter votre base de données.
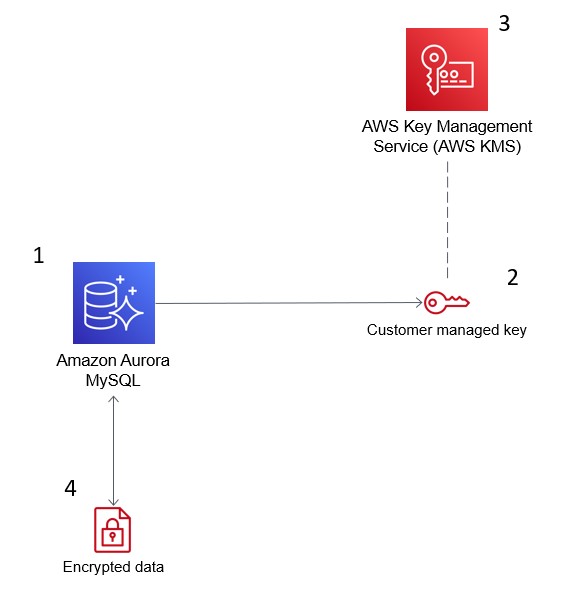
AWS Key Management Service (KMS) crypte les données dans Amazon Aurora pour la conformité en matière de sécurité. Source : Blogs AWS
Intégration IAM pour le contrôle d’accès
Le contrôle d’accès dans Aurora est géré via AWS IAM, permettant aux administrateurs de définir des autorisations détaillées basées sur les rôles des utilisateurs.
- Les politiques IAM peuvent être utilisées pour restreindre l’accès aux instances de base de données, empêchant les utilisateurs non autorisés d’effectuer des opérations critiques telles que des modifications de données ou des tâches administratives.
- L’authentification IAM offre une alternative plus sécurisée à l’authentification basée sur des mots de passe traditionnels. Elle permet aux applications de se connecter en utilisant des informations d’identification de sécurité temporaires. Cela élimine le besoin de stocker et de gérer les mots de passe de la base de données, réduisant ainsi le risque d’exposition des informations d’identification.
Vous devriez appliquer les principes d’accès au moindre privilège, qui minimisent les risques de sécurité et maintiennent un contrôle strict sur l’accès à la base de données.
L’image ci-dessous montre comment l’authentification IAM peut être configurée pour sécuriser l’accès à la base de données Amazon Aurora PostgreSQL.
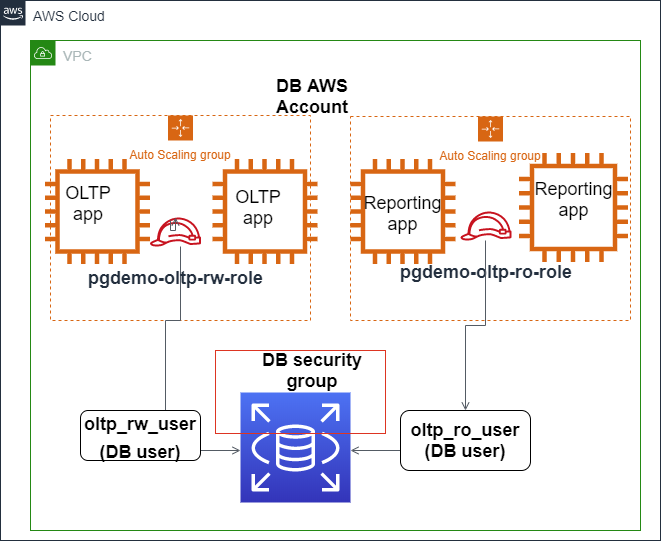
L’authentification IAM s’intègre avec Amazon Aurora PostgreSQL. Source: Blogs AWS
Audit avec les journaux Aurora
La surveillance et l’audit de l’activité de la base de données sont essentiels pour la conformité en matière de sécurité et le dépannage.
Aurora fournit plusieurs mécanismes de journalisation, y compris les journaux d’erreurs, les journaux de requêtes lentes et les journaux généraux, qui aident les administrateurs à suivre l’activité de la base de données et à identifier d’éventuels problèmes. Ces journaux peuvent être activés via la console de gestion AWS et stockés dans Amazon CloudWatch pour une analyse centralisée.
- Les journaux d’erreurs capturent les erreurs et les avertissements du moteur de base de données.
- Les journaux de requêtes lentes aident à identifier les requêtes inefficaces qui peuvent affecter les performances.
L’analyse de ces journaux peut aider les administrateurs à optimiser l’exécution des requêtes, détecter les tentatives d’accès non autorisées et garantir la stabilité de la base de données.
Gestion des coûts et optimisation dans AWS Aurora
Pour gérer et optimiser efficacement les coûts dans Amazon Aurora, vous devez comprendre sa structure tarifaire. Passons en revue !
Compréhension de la tarification d’Aurora
Le modèle tarifaire d’Amazon Aurora est basé sur plusieurs facteurs, notamment les heures d’instance, la consommation de stockage, les demandes d’E/S et le transfert de données.
Contrairement aux bases de données traditionnelles qui nécessitent une provision d’infrastructure initiale, le modèle de paiement à l’utilisation d’Aurora permet aux entreprises de ne payer que pour les ressources qu’elles consomment.
Les instances Compute sont facturées en fonction de la classe de l’instance et du temps de disponibilité, tandis que le stockage est ajusté dynamiquement, éliminant ainsi le besoin d’ajustements manuels.
L’image ci-dessous fournit un détail des différents composants de tarification pour Amazon Aurora. Cependant, gardez à l’esprit que les tarifs peuvent changer, il est donc toujours préférable de consulter la page de tarification d’Aurora pour obtenir les informations les plus récentes.
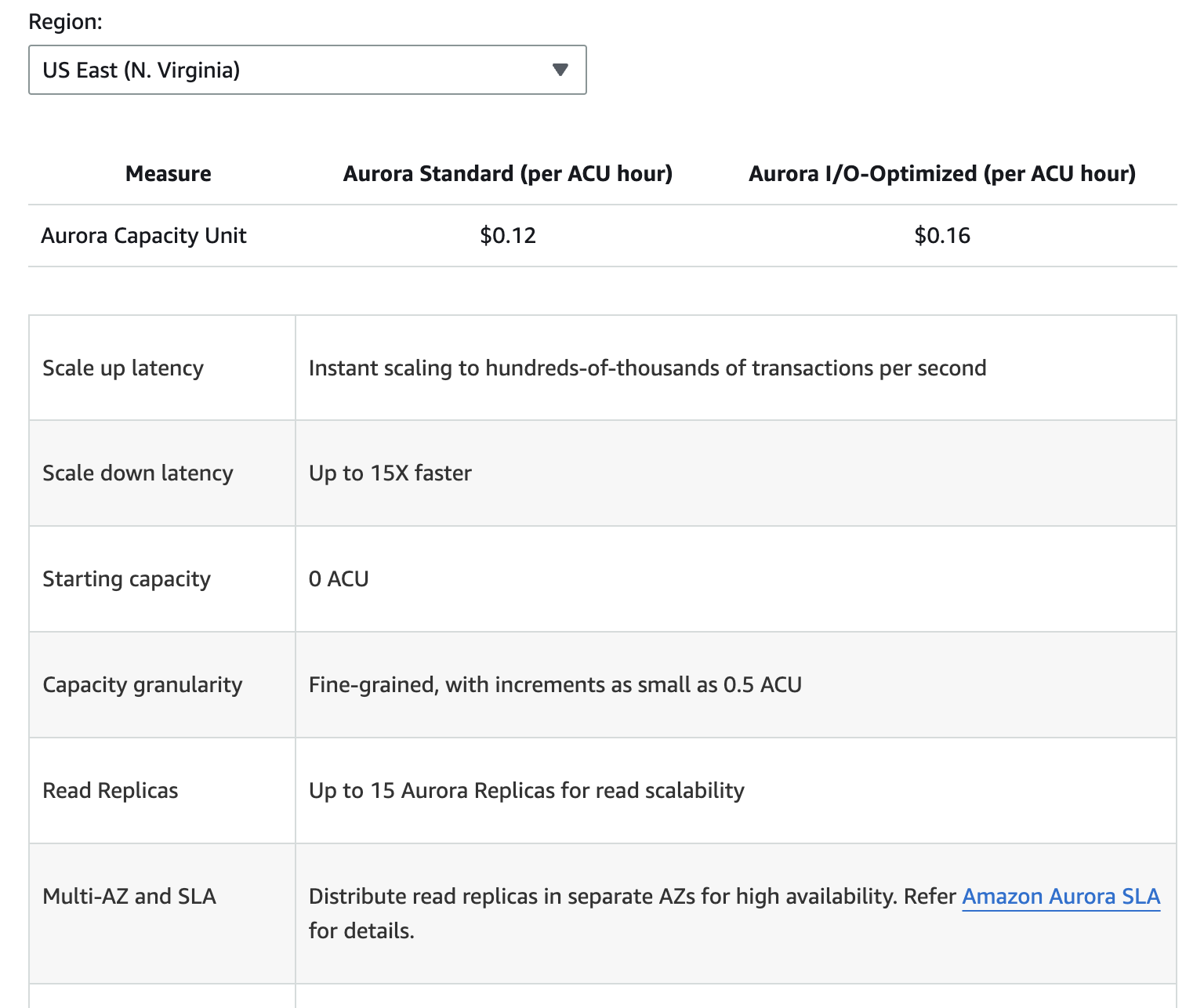
Les coûts supplémentaires comprennent le stockage de sauvegarde au-delà du quota gratuit alloué, les requêtes de lecture et d’écriture E/S, ainsi que les frais de transfert de données pour la réplication entre régions.
Comprendre ces composants de tarification peut vous aider à prévoir les dépenses et à prendre des décisions éclairées concernant l’utilisation de la base de données.
Optimisation des coûts avec Aurora
Pour gérer efficacement les coûts, les organisations peuvent mettre en œuvre plusieurs stratégies d’optimisation.
Le choix de la taille d’instance appropriée garantira que les ressources de la base de données correspondent aux demandes de charge de travail sans surapprovisionnement.
- Si vous avez une charge de travail prévisible, utilisez les Instances Réservées car elles offrent des économies de coûts significatives par rapport aux tarifs à la demande.
- Les techniques d’optimisation du stockage, telles que la surveillance des ressources inutilisées ou sous-utilisées, contribuent à réduire les coûts.
- La fonction d’auto-scaling de Aurora ajuste dynamiquement le stockage, évitant ainsi des dépenses de stockage inutiles.
- De plus, la mise en œuvre de répliques de lecture peut décharger les requêtes de l’instance principale, réduisant potentiellement le besoin d’instances de niveau supérieur.
- Exploitez Aurora Serverless, car c’est une autre option économique pour les applications avec des charges de travail variables. Aurora Serverless ajuste automatiquement les ressources de calcul en fonction de la demande, garantissant aux entreprises de ne payer que pour l’utilisation réelle plutôt que de maintenir une instance en continu.
> Si vous souhaitez obtenir un aperçu plus approfondi de la gestion des coûts, veuillez consulter le cours AWS Security and Cost Management.
Conclusion
Après avoir travaillé avec Amazon Aurora dans plusieurs entreprises pendant un certain temps, je peux affirmer avec confiance que c’est une solution de base de données puissante et évolutive qui facilite la gestion sans compromettre les performances, vous serez probablement d’accord après avoir suivi ce tutoriel.
Aurora vaut la peine d’être envisagée si vous recherchez une base de données relationnelle native du cloud qui prend en charge MySQL et PostgreSQL tout en réduisant les coûts d’exploitation. Elle a été révolutionnaire dans certains de mes projets, et je recommande vivement d’examiner ses capacités si vous travaillez avec les bases de données AWS.
Si vous êtes nouveau dans les bases de données AWS, apprendre les concepts fondamentaux à travers des cours comme AWS Cloud Practitioner (CLF-C02) peut être bénéfique!