













Le 11 décembre 2024, les services d’OpenAI ont connu une panne significative en raison d’un problème lié au déploiement d’un nouveau service de télémétrie. Cet incident a affecté les services API, ChatGPT et Sora, entraînant des interruptions de service qui ont duré plusieurs heures. En tant qu’entreprise visant à fournir des solutions d’IA précises et efficaces, OpenAI a partagé un rapport d’analyse post-mortem détaillé pour discuter de manière transparente de ce qui s’est mal passé et comment elle prévoit de prévenir des occurrences similaires à l’avenir.
Dans cet article, je vais décrire les aspects techniques de l’incident, décomposer les causes profondes et explorer les leçons clés que les développeurs et les organisations gérant des systèmes distribués peuvent tirer de cet événement.
La Chronologie de l’Incident
Voici un aperçu du déroulement des événements du 11 décembre 2024 :
| Time (PST) | Event |
|---|---|
| 15h16 |
Impact mineur sur les clients commencé ; dégradation du service observée |
| 15h27 | Les ingénieurs ont commencé à rediriger le trafic des clusters affectés |
| 15h40 | Impact maximum sur les clients enregistré ; pannes majeures sur tous les services |
| 16h36 | Le premier cluster Kubernetes a commencé à se rétablir |
| 17h36 | Rétablissement substantiel des services API commencé |
| 17h45 | Rétablissement substantiel de ChatGPT observé |
| 19h38 | Tous les services entièrement rétablis sur tous les clusters |
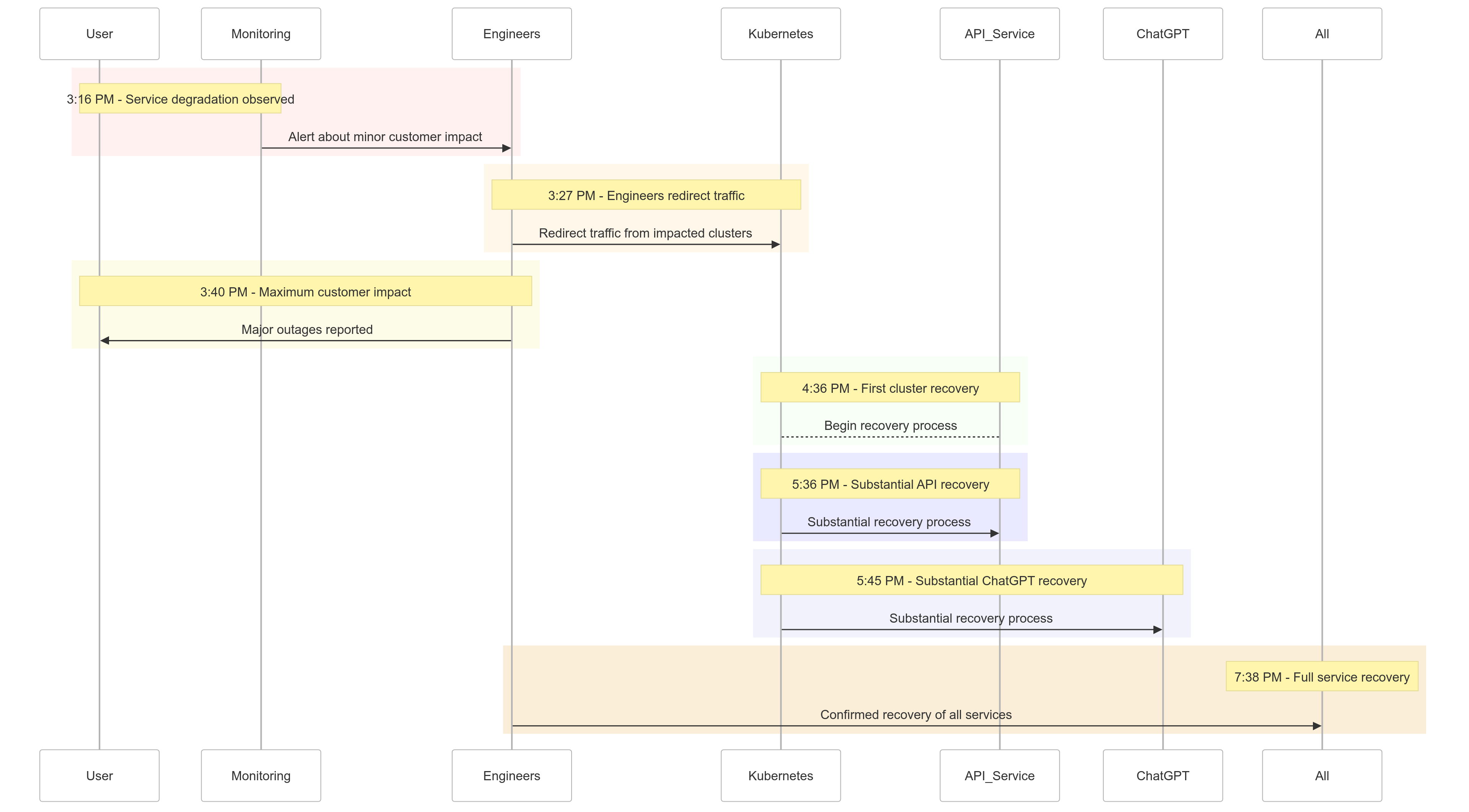
Figure 1 : Chronologie de l’incident OpenAI – De la dégradation du service à la récupération complète.
Analyse des causes profondes
La cause profonde de l’incident résidait dans un nouveau service de télémétrie déployé à 15h12 PST pour améliorer l’observabilité des plans de contrôle Kubernetes. Ce service a involontairement submergé les serveurs API Kubernetes sur plusieurs clusters, entraînant des défaillances en cascade.
Analyse détaillée
Déploiement du service de télémétrie
Le service de télémétrie était conçu pour collecter des métriques détaillées du plan de contrôle Kubernetes, mais sa configuration a déclenché involontairement des opérations API Kubernetes consommatrices de ressources sur des milliers de nœuds simultanément.
Plan de contrôle surchargé
Le plan de contrôle Kubernetes, chargé de l’administration des clusters, a été submergé. Alors que le plan de données (traitant les demandes des utilisateurs) est resté partiellement fonctionnel, il dépendait du plan de contrôle pour la résolution DNS. Au fur et à mesure que les enregistrements DNS mis en cache expiraient, les services reposant sur une résolution DNS en temps réel ont commencé à échouer.
Tests insuffisants
Le déploiement a été testé dans un environnement de staging, mais les clusters de staging ne reproduisaient pas l’échelle des clusters de production. Par conséquent, le problème de charge du serveur API est passé inaperçu lors des tests.
Comment le problème a été atténué
Lorsque l’incident a commencé, les ingénieurs d’OpenAI ont rapidement identifié la cause racine, mais ont rencontré des difficultés pour mettre en place une solution car le surchargé plan de contrôle Kubernetes empêchait l’accès aux serveurs API. Une approche à plusieurs volets a été adoptée :
- Réduction de la taille du cluster : La réduction du nombre de nœuds dans chaque cluster a permis de diminuer la charge des serveurs API.
- Blocage de l’accès réseau aux APIs administratives Kubernetes : A empêché les requêtes API supplémentaires, permettant aux serveurs de récupérer.
- Augmentation des serveurs API Kubernetes : La provision de ressources supplémentaires a aidé à vider les requêtes en attente.
Ces mesures ont permis aux ingénieurs de retrouver l’accès aux plans de contrôle et de supprimer le service de télémétrie problématique, restaurant la fonctionnalité du service.
Leçons apprises
Cet incident met en lumière l’importance de tests robustes, de surveillance et de mécanismes de secours dans les systèmes distribués. Voici ce qu’OpenAI a appris (et mis en œuvre) suite à l’incident :
1. Déploiements progressifs robustes
Toutes les modifications d’infrastructure suivront désormais des déploiements progressifs avec une surveillance continue. Cela garantit que les problèmes sont détectés tôt et atténués avant de se propager à l’ensemble de la flotte.
2. Tests d’injection de pannes
En simulant des pannes (par exemple, en désactivant le plan de contrôle ou en déployant de mauvaises modifications), OpenAI vérifiera que leurs systèmes peuvent récupérer automatiquement et détecter les problèmes avant qu’ils n’affectent les clients.
3. Accès au Plan de Contrôle d’Urgence
Un mécanisme « briser le verre » garantira que les ingénieurs peuvent accéder aux serveurs API Kubernetes même en cas de forte charge.
4. Découplage des Plans de Contrôle et de Données
Pour réduire les dépendances, OpenAI découplera le plan de données Kubernetes (gérant les charges de travail) du plan de contrôle (responsable de l’orchestration), s’assurant que les services critiques peuvent continuer à fonctionner même pendant les pannes du plan de contrôle.
5. Mécanismes de Récupération Plus Rapides
De nouvelles stratégies de mise en cache et de limitation de débit amélioreront les temps de démarrage des clusters, garantissant une récupération plus rapide en cas de défaillance.
Exemple de Code : Exemple de Déploiement Phasé
Voici un exemple de mise en œuvre d’un déploiement phasé pour Kubernetes utilisant Helm et Prometheus pour l’observabilité.
Déploiement Helm avec déploiements phasés :
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Requête Prometheus pour surveiller la charge du serveur API :
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Cette requête aide à suivre les temps de réponse pour les requêtes au serveur API, garantissant une détection précoce des pics de charge.
Exemple d’Injection de Panne
En utilisant chaos-mesh, OpenAI pourrait simuler des pannes dans le plan de contrôle Kubernetes.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml :
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Cette configuration tue intentionnellement un pod de serveur API pour vérifier la résilience du système.
Ce que Cela Signifie pour Vous
Cet incident souligne l’importance de concevoir des systèmes résilients et d’adopter des méthodologies de test rigoureuses. Que vous gériez des systèmes distribués à grande échelle ou que vous mettiez en œuvre Kubernetes pour vos charges de travail, voici quelques leçons à retenir :
- Simulez des Échecs Régulièrement : Utilisez des outils d’ingénierie de chaos comme Chaos Mesh pour tester la robustesse du système dans des conditions réelles.
- Surveillez à Plusieurs Niveaux : Assurez-vous que votre pile d’observabilité suit à la fois les métriques au niveau du service et les métriques de santé du cluster.
- Dissociez les Dépendances Critiques : Réduisez la dépendance aux points de défaillance uniques, tels que la découverte de services basée sur DNS.
Conclusion
Bien qu’aucun système ne soit à l’abri des échecs, des incidents comme celui-ci nous rappellent la valeur de la transparence, de la remédiation rapide et de l’apprentissage continu. L’approche proactive d’OpenAI pour partager ce post-mortem fournit un modèle pour d’autres organisations afin d’améliorer leurs pratiques opérationnelles et leur fiabilité.
En donnant la priorité à des déploiements robustes par phases, à des tests d’injection de pannes et à la conception de systèmes résilients, OpenAI donne un bon exemple de la manière de gérer et d’apprendre des pannes à grande échelle.
Pour les équipes qui gèrent des systèmes distribués, cet incident constitue une excellente étude de cas sur la manière d’aborder la gestion des risques et de minimiser les temps d’arrêt pour les processus commerciaux essentiels.
Utilisons cela comme une opportunité pour construire ensemble de meilleurs systèmes, plus résilients.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident