













SettingWithCopyWarning est un avertissement que Pandas peut déclencher lorsque nous effectuons une affectation à un DataFrame. Cela peut se produire lorsque nous utilisons des affectations en chaîne ou lorsque nous utilisons un DataFrame créé à partir d’une tranche. C’est une source courante de bugs dans le code Pandas que nous avons tous rencontrée auparavant. Il peut être difficile à déboguer car l’avertissement peut apparaître dans du code qui semble fonctionner correctement.
Comprendre le SettingWithCopyWarning est important car il signale des problèmes potentiels de manipulation des données. Cet avertissement suggère que votre code peut ne pas modifier les données comme prévu, ce qui peut entraîner des conséquences non voulues et des bugs obscurs difficiles à tracer.
Dans cet article, nous explorerons le SettingWithCopyWarning dans Pandas et comment l’éviter. Nous discuterons également de l’avenir de Pandas et comment l’option copy_on_write changera notre manière de travailler avec les DataFrames.
Vues et Copies de DataFrame
Lorsque nous sélectionnons une tranche d’un DataFrame et que nous l’assignons à une variable, nous pouvons obtenir soit une vue soit une copie fraîche du DataFrame.
Avec une vue, la mémoire entre les deux DataFrames est partagée. Cela signifie que modifier une valeur d’une cellule présente dans les deux DataFrames modifiera les deux.

Avec une copie, une nouvelle mémoire est allouée et un DataFrame indépendant avec les mêmes valeurs que l’original est créé. Dans ce cas, les deux DataFrames sont des entités distinctes, donc modifier une valeur dans l’un d’eux n’affecte pas l’autre.
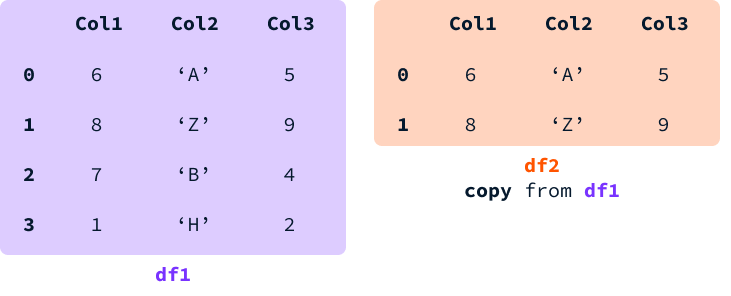
Pandas tente d’éviter de créer une copie lorsqu’il le peut pour optimiser les performances. Cependant, il est impossible de prédire à l’avance si nous obtiendrons une vue ou une copie. Le SettingWithCopyWarning est déclenché chaque fois que nous attribuons une valeur à un DataFrame pour lequel il n’est pas clair s’il s’agit d’une copie ou d’une vue d’un autre DataFrame.
Comprendre le SettingWithCopyWarning avec des données réelles
Nous utiliserons l’ensemble de données Kaggle Real Estate Data London 2024 pour apprendre comment le SettingWithCopyWarning se produit et comment le corriger.
Cet ensemble de données contient des données immobilières récentes de Londres. Voici un aperçu des colonnes présentes dans l’ensemble de données:
addedOn: La date à laquelle l’annonce a été ajoutée.title: Le titre de l’annonce.descriptionHtml: Une description HTML de l’annonce.propertyType: Le type de propriété. La valeur sera"Non spécifié"si le type n’a pas été spécifié.sizeSqFeetMax: La taille maximale en pieds carrés.bedrooms: Le nombre de chambres.listingUpdatedReason: Raison de la mise à jour de l’annonce (par exemple, nouvelle annonce, réduction de prix).price: Le prix de l’annonce en livres.
Exemple avec une variable temporaire explicite
Disons que nous sommes informés que les propriétés avec un type de propriété non spécifié sont des maisons. Nous voulons donc mettre à jour toutes les lignes avec propertyType égal à "Not Specified" à "House". Une façon de le faire est de filtrer les lignes avec un type de propriété non spécifié dans une variable DataFrame temporaire et de mettre à jour les valeurs de la colonne propertyType de cette manière :
import pandas as pd dataset_name = "realestate_data_london_2024_nov.csv" df = pd.read_csv(dataset_name) # Obtenir toutes les lignes avec un type de propriété non spécifié no_property_type = df[df["propertyType"] == "Not Specified"] # Mettre à jour le type de propriété à "House" sur ces lignes no_property_type["propertyType"] = "House"
Exécuter ce code provoquera la SettingWithCopyWarning de pandas :
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy no_property_type["propertyType"] = "House"
La raison en est que pandas ne peut pas savoir si le DataFrame no_property_type est une vue ou une copie de df.
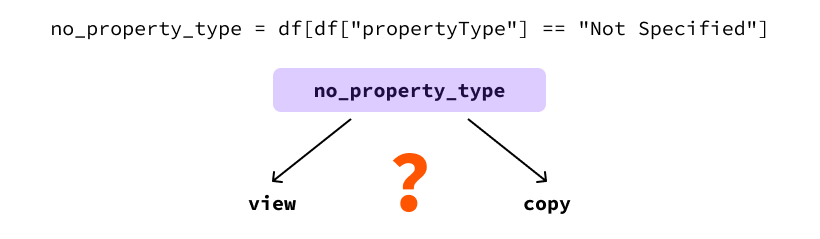
C’est un problème car le comportement du code suivant peut être très différent selon qu’il s’agit d’une vue ou d’une copie.
Dans cet exemple, notre objectif est de modifier le DataFrame original. Cela se produira uniquement si no_property_type est une vue. Si le reste de notre code suppose que df a été modifié, cela peut être incorrect car il n’y a aucun moyen de garantir que c’est le cas. En raison de ce comportement incertain, Pandas lance l’avertissement pour nous informer de ce fait.
Même si notre code s’exécute correctement parce que nous avons obtenu une vue, nous pourrions obtenir une copie dans des exécutions ultérieures, et le code ne fonctionnera pas comme prévu. Il est donc important de ne pas ignorer cet avertissement et de s’assurer que notre code fera toujours ce que nous voulons qu’il fasse.
Exemple avec une variable temporaire masquée
Dans l’exemple précédent, il est clair qu’une variable temporaire est utilisée car nous assignons explicitement une partie du DataFrame à une variable nommée no_property_type.
Cependant, dans certains cas, cela n’est pas aussi explicite. L’exemple le plus courant où l’avertissement SettingWithCopyWarning se produit est avec l’indexation en chaîne. Supposons que nous remplaçons les deux dernières lignes par une seule ligne :
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
À première vue, il ne semble pas qu’une variable temporaire soit créée. Cependant, son exécution entraîne également un SettingWithCopyWarning.
La façon dont ce code est exécuté est la suivante :
df[df["propertyType"] == "Not Specified"]est évalué et temporairement stocké en mémoire.- L’index
["propertyType"]de cet emplacement mémoire temporaire est accédé.

Les accès index sont évalués un par un, et donc, l’indexation en chaîne entraîne le même avertissement car nous ne savons pas si les résultats intermédiaires sont des vues ou des copies. Le code ci-dessus est essentiellement équivalent à :
tmp = df[df["propertyType"] == "Not Specified"] tmp["propertyType"] = "House"
Cet exemple est souvent appelé indexation en chaîne car nous enchaînons les accès indexés en utilisant []. D’abord, nous accédons à [df["propertyType"] == "Not Specified"] puis à ["propertyType"].

Comment résoudre l’avertissement SettingWithCopyWarning
Apprenons à écrire notre code de manière à ce qu’il n’y ait aucune ambiguïté et que le SettingWithCopyWarning ne soit pas déclenché. Nous avons appris que cet avertissement provient d’une ambiguïté concernant le fait qu’un DataFrame est une vue ou une copie d’un autre DataFrame.
La façon de le résoudre est de s’assurer que chaque DataFrame que nous créons est une copie si nous voulons que ce soit une copie, ou une vue si nous voulons que ce soit une vue.
Modifier en toute sécurité le DataFrame d’origine avec loc
Corrigeons le code de l’exemple ci-dessus où nous voulons modifier le DataFrame d’origine. Pour éviter d’utiliser une variable temporaire, utilisez la propriété de l’indexeur loc.
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"
Avec ce code, nous agissons directement sur le DataFrame df d’origine via la propriété de l’indexeur loc, il n’est donc pas nécessaire d’utiliser des variables intermédiaires. C’est ce que nous devons faire lorsque nous voulons modifier directement le DataFrame d’origine.
Cela peut ressembler à un indexage en chaîne à première vue en raison de la présence de paramètres, mais ce n’est pas le cas. Ce qui définit chaque indexage ce sont les crochets [].

Remarquez que l’utilisation de loc est sûre uniquement si nous affectons directement une valeur, comme nous l’avons fait ci-dessus. Si nous utilisons à la place une variable temporaire, nous retombons dans le même problème. Voici deux exemples de code qui ne résolvent pas le problème :
- Utilisation de
locavec une variable temporaire :
# Utiliser loc avec une variable temporaire ne résout pas le problème no_property_type = df.loc[df["propertyType"] == "Not Specified"] no_property_type["propertyType"] = "House"
- Utilisation de
locavec un index (similaire à l’indexation en chaîne) :
# Utiliser loc avec l'indexation est équivalent à l'indexation en chaîne df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
Ces deux exemples ont tendance à embrouiller les gens car il est courant de penser que tant qu’il y a un loc, nous modifions les données originales. C’est incorrect. La seule façon de s’assurer que la valeur est assignée au DataFrame original est de l’assigner directement en utilisant un seul loc sans aucune indexation séparée.
Travailler en toute sécurité avec une copie du DataFrame original avec copy()
Lorsque nous voulons nous assurer que nous travaillons sur une copie du DataFrame, nous devrions utiliser la méthode .copy().
Disons que nous devons analyser le prix par pied carré des propriétés. Nous ne voulons pas modifier les données originales. Le but est de créer un nouveau DataFrame avec les résultats de l’analyse à envoyer à une autre équipe.
La première étape consiste à filtrer certaines lignes et nettoyer les données. Plus précisément, nous devons :
- Supprimez les lignes où
sizeSqFeetMaxn’est pas défini. - Supprimez les lignes où le
prixest"POA"(prix sur demande). - Convertissez les prix en valeurs numériques (dans l’ensemble de données d’origine, les prix sont des chaînes de caractères avec le format suivant :
"£25,000,000")
Nous pouvons effectuer les étapes ci-dessus en utilisant le code suivant :
# 1. Filtrer toutes les propriétés sans taille ou sans prix properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")] # 2. Supprimer les caractères £ et , des colonnes de prix properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False) # 3. Convertir la colonne de prix en valeurs numériques properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])
Pour calculer le prix par pied carré, nous créons une nouvelle colonne dont les valeurs sont le résultat de la division de la colonne prix par la colonne taillePiedsCarresMax:
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]
Si nous exécutons ce code, nous obtenons à nouveau l’avertissement SettingWithCopyWarning. Cela ne devrait pas être surprenant car nous avons explicitement créé et modifié une variable temporaire DataFrame propriétés_avec_taille_et_prix.
Puisque nous voulons travailler sur une copie des données plutôt que sur le DataFrame original, nous pouvons résoudre le problème en nous assurant que properties_with_size_and_price est une copie fraîche du DataFrame et non une vue en utilisant la méthode .copy() à la première ligne :
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()
Ajout sécurisé de nouvelles colonnes
Créer de nouvelles colonnes se comporte de la même manière que l’assignation de valeurs. Chaque fois qu’il est ambigu si nous travaillons avec une copie ou une vue, pandas va émettre un SettingWithCopyWarning.
Si nous voulons travailler avec une copie des données, nous devrions explicitement la copier en utilisant la méthode .copy(). Ensuite, nous sommes libres d’attribuer une nouvelle colonne de la manière que nous voulons. Nous avons fait cela lorsque nous avons créé la colonne pricePerSqFt dans l’exemple précédent.
En revanche, si nous voulons modifier le DataFrame original, il y a deux cas à considérer.
- Si la nouvelle colonne couvre chaque ligne, nous pouvons modifier directement le DataFrame original. Cela ne provoquera pas d’avertissement car nous ne sélectionnerons pas un sous-ensemble des lignes. Par exemple, nous pourrions ajouter une colonne
notepour chaque ligne où le type de maison est manquant :
df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")
- Si la nouvelle colonne ne définit des valeurs que pour un sous-ensemble des lignes, alors nous pouvons utiliser la propriété de l’indexeur
loc. Par exemple :
df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"
Notez que dans ce cas, la valeur des colonnes qui n’ont pas été sélectionnées sera indéfinie, donc la première approche est préférée car elle nous permet de spécifier une valeur pour chaque ligne.
SettingWithCopyWarning Erreur dans Pandas 3.0
Actuellement, SettingWithCopyWarning n’est qu’un avertissement, pas une erreur. Notre code est toujours exécuté, et Pandas nous informe simplement d’être prudent.
Selon la documentation officielle de Pandas, SettingWithCopyWarning ne sera plus utilisé à partir de la version 3.0 et sera remplacé par une erreur par défaut, appliquant des normes de code plus strictes.
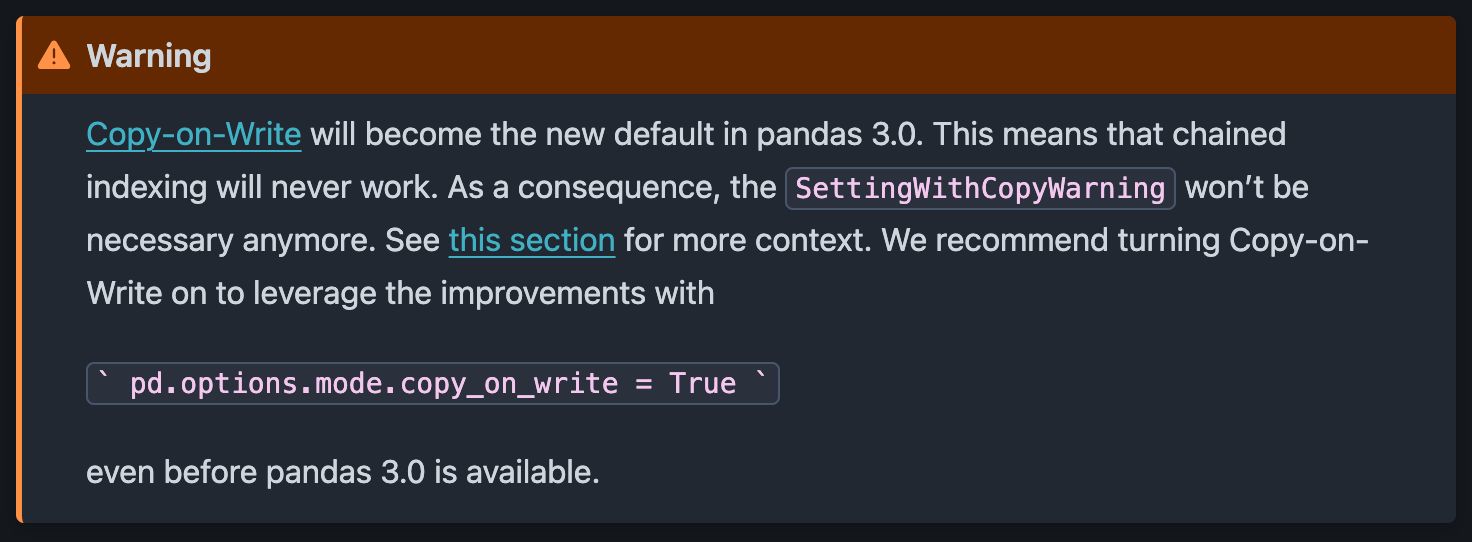
Pour garantir que notre code reste compatible avec les futures versions de pandas, il est recommandé de le mettre à jour dès maintenant pour générer une erreur au lieu d’un avertissement.
Ceci est fait en définissant l’option suivante après l’importation de pandas :
import pandas as pd pd.options.mode.copy_on_write = True
Ajouter cela au code existant garantira que nous traitons chaque affectation ambiguë dans notre code et que le code fonctionne toujours lorsque nous mettons à jour vers pandas 3.0.
Conclusion
Le SettingWithCopyWarning se produit chaque fois que notre code rend ambiguë la valeur que nous modifions, qu’il s’agisse d’une vue ou d’une copie. Nous pouvons le corriger en étant toujours explicites sur ce que nous voulons :
- Si nous voulons travailler avec une copie, nous devrions la copier explicitement en utilisant la méthode
copy(). - Si nous voulons modifier le DataFrame original, nous devrions utiliser la propriété indexeur
locet attribuer la valeur directement lors de l’accès aux données sans utiliser de variables intermédiaires.
Bien qu’il ne s’agisse pas d’une erreur, nous ne devrions pas ignorer cet avertissement car il peut mener à des résultats inattendus. De plus, à partir de Pandas 3.0, cela deviendra une erreur par défaut, nous devrions donc anticiper l’avenir de notre code en activant Copy-on-Write dans notre code actuel en utilisant pd.options.mode.copy_on_write = True. Cela garantira que le code reste fonctionnel pour les futures versions de Pandas.
Source:
https://www.datacamp.com/tutorial/settingwithcopywarning-pandas