













Introduction
Dans les sciences des données, et en particulier dans le traitement du langage naturel, la synthèse de texte est depuis toujours un sujet d’intérêt intense. Si les méthodes de synthèse de texte existent depuis déjà une certaine période, les dernières années ont été marquées par d’importantes avancées dans le traitement du langage naturel et l’apprentissage profond. De nombreux articles sont publiés sur ce sujet par des géants d’Internet, comme le récent ChatGPT. Si beaucoup de travail est accompli sur ce sujet de recherche, il est très peu écrit sur les implémentations pratiques de la synthèse assistée par intelligence artificielle. La difficulté de parser des déclarations larges et générales est un obstacle à la synthèse efficace.
Synthétiser un article de nouvelles et un rapport financier des profits sont deux tâches différentes. Lorsque l’on traite des caractéristiques textuelles qui varient en longueur ou en matière (tech, sports, finance, voyage, etc.), la synthèse devient une tâche de sciences des données difficile. Il est essentiel de couvrir un certain fond théorique dans la synthèse avant d’entrer dans un aperçu des applications.
Synthèse extractive
Le processus de résumé extractif implique de sélectionner les phrases les plus pertinentes d’un article et de les organiser systématiquement. Les phrases composant le résumé sont prises telles quelles à partir du matériel source.
Les systèmes de résumé extractif, tel que nous les connaissons maintenant, tournent autour de trois opérations fondamentales :
Construction d’une représentation intermédiaire du texte d’entrée
Les représentations basées sur les méthodes de représentation, telles que la représentation des thèmes et la représentation des indicateurs, sont des exemples à cet effet. Pour comprendre les sujets mentionnés dans le texte, la représentation des thèmes convertit le texte en une représentation intermédiaire.
Calcul du score des phrases sur la base de la représentation
Au moment de la génération de la représentation intermédiaire, chaque phrase reçoit un score de signification. En utilisant une méthode qui repose sur la représentation des thèmes, le score d’une phrase reflète à quel point elle éclaire les concepts clé du texte. Dans la représentation des indicateurs, le score est calculé en agrégant les preuves de différents indicateurs pondérés.
Sélection d’un résumé composé de plusieurs phrases
Pour générer un résumé, le logiciel de résumé sélectionne les k phrases les plus importantes. Par exemple, certaines méthodes utilisent des algorithmes gloutons pour choisir et sélectionner les phrases les plus pertinentes, tandis que d’autres peuvent transformer la sélection de phrases en un problème d’optimisation où un ensemble de phrases est sélectionné sous réserve qu’il doit maximiser l’importance et la cohérence globales tout en minimisant l’information redondante.
Allons plus loin dans les méthodes que nous avons mentionnées :
Approches de représentation des sujets
Mots de sujet : En utilisant cette méthode, vous pouvez trouver des mots liés au sujet dans le document d’entrée. L’importance d’une phrase peut être calculée de deux manières : d’abord, en fonction du nombre de signatures de sujet qu’elle contient ; deuxièmement, en tant que fraction des signatures de sujet qu’elle contient.
Tandis que la première méthode donne des notes plus élevées aux phrases plus longues avec plus de mots, la seconde mesure la densité des mots de sujet.
Approches basées sur la fréquence : Par cette méthode, les mots sont attribués une importance relative. Si le terme convient au sujet, il obtient 1 point ; sinon, il atteint zéro. Selon la manière dont elles sont mises en œuvre, les poids peuvent être continus. Les représentations de sujet peuvent être réalisées en utilisant l’une des deux méthodes :
Probabilité des mots : Elle ne prend en compte que la fréquence du mot pour indiquer son importance. Pour calculer la probabilité d’un mot w, on divise sa fréquence d’occurrence f(w) par le nombre total de mots N.
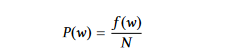
La moyenne de l’importance des mots dans une phrase donne l’importance de la phrase lors de l’utilisation de probabilités de mots.
TFIDF (Terme Fréquence Inverse Document Fréquence) : Cette méthode améliore l’approche de probabilité de mot. Ici, les poids sont déterminés en utilisant l’approche TF-IDF. La technique de Terme Fréquence Inverse Document Fréquence (TFIDF) accorde moins d’importance aux termes qui apparaissent fréquemment dans la plupart des documents. Le poids de chaque mot w dans le document d est calculé comme suit :
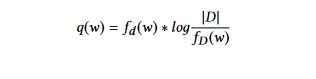
où fd (w) est la fréquence du terme w dans le document d,
fD (w) est le nombre de documents contenant le mot w, et |D| est le nombre de documents dans la collection D.
Analyse sémantique latente : L’analyse sémantique latente (LSA) est une méthode non supervisée pour extraire une représentation de la sémantique du texte sur la base des mots observés. Le processus de LSA commence par la construction d’une matrice mot-phrases (n par m), où chaque ligne représente un mot de l’entrée (n mots) et chaque colonne représente une phrase (m phrases). Dans la matrice, le poids du mot i dans la phrase j est défini par l’entrée aij. Selon la technique TFIDF, chaque mot dans une phrase est attribué un certain poids, avec zéro étant affecté aux termes qui ne sont pas inclus dans la phrase.
Approches de représentation par indicateurs
Méthodes basées sur le graphe
Les méthodes graphiques, influencées par l’algorithme PageRank, représentent les documents sous forme de graphe connecté. Les phrases forment les sommets du graphe, et les arrêtes connectant les phrases montrent dans quelle mesure deux phrases sont liées l’une à l’autre. Une méthode fréquemment utilisée pour lier deux sommets est d’évaluer dans quelle mesure deux phrases sont similaires, et si la similarité est supérieure à un certain seuil, les sommets sont connectés. Deux résultats sont possibles avec cette représentation de graphe. Premièrement, les partitions du graphe (sous-graphes) définissent les catégories individuelles d’information couvertes par les documents. Le second résultat est que les phrases clés des documents sont mises en avant. Les phrases connectées à beaucoup d’autres phrases dans la partition sont peut-être le centre du graphe et sont plus susceptibles d’être incluses dans le résumé. Les techniques de résumé à un seul document et les techniques de résumé multi-document peuvent tirer profit de l’utilisation de techniques basées sur le graphe.
Apprentissage automatique
Les techniques d’apprentissage automatique considèrent le problème de résumé comme un défi de classification. Les modèles essayent de catégoriser les phrases en catégories de résumé et de non-résumé en fonction de leurs caractéristiques. Nous avons un jeu de données d’entraînement composé de documents et de résumés extraits et évalués par des humains, à partir desquels nous entraînons nos algorithmes. Cela est souvent effectué en utilisant Naive Bayes, Arbre de décision ou Machine à support vectoriel.
Résumé abstractif
En opposition à la réduction extractive, le résumé abstractif est un méthode plus efficace. La capacité de créer des phrases uniques qui transmettent des informations cruciales des sources textuelles a contribué à cette popularité croissante.
Un résumé abstractif présente les matériels de manière logique, bien organisée et grammaticalement solide. La qualité d’un résumé peut être nettement améliorée en le rendant plus lisible ou en améliorant sa qualité linguistique. (inclure l’image).
Il existe deux approches : la méthode basée sur la structure et la méthode basée sur la sémantique.
MÉTHODE BASÉE SUR LA STRUCTURE
Dans une méthode basée sur une structure initiale, les informations les plus importantes du document (ou des documents) sont encodées à l’aide de schémas de caractéristiques psychologiques tels que des gabarits, des règles d’extraction et des structures alternatives, y compris l’arbre, l’ontologie, l’introduction et le corps, la règle et la structure à base de graphe. Dans la suite, nous lirons sur certaines des méthodes diverses qui sont intégrées dans cette stratégie.
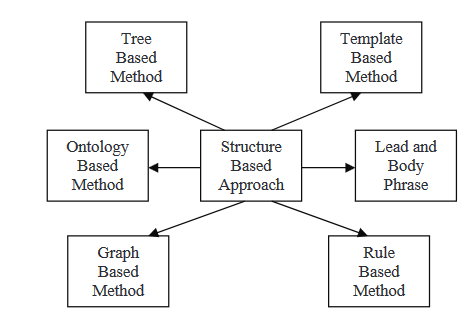
Méthodes arborescentes
Dans cette méthode, le contenu d’un document est représenté sous forme d’un arbre de dépendances. La sélection du contenu pour une table des matières peut être réalisée via plusieurs autres techniques, telles que programmes algorithmiques d’intersection de sujets ou ceux qui utilisent une alignement naturelle croisée entre les phrases parsées. Cette approche emploie soit un générateur de langage soit un algorithme associé pour la génération de tables des matières. Dans ce document, les auteurs proposent une méthode de fusion de phrases utilisant un alignement local multic séquence ascendant pour trouver les phrases d’information commune. Les systèmes de résumé multic gène utilisent une technique appelée fusion de phrases.
Dans cette méthode, un ensemble de documents est utilisé en entrée, traité à l’aide d’un algorithme de sélection de sujet pour extraire le thème central, puis un algorithme de clustering est utilisé pour classer les phrases en fonction de leur importance. Après l’arrangement des phrases, ils sont fusionnés à l’aide de la fusion de phrases, et un résumé statistique est généré. La méthode structurée encode les données les plus importantes du(s) document(s) en utilisant des schémas de caractéristiques psychologiques tels que des gabarits, des règles d’extraction et d’autres structures telles que l’arbre, l’ontologie, l’introduction et le corps, la règle et la structure basée sur le graphe.
Méthodes basées sur des templates
Dans cette méthode, un guide est utilisé pour représenter tout document. Des patrons linguistiques ou des critères d’extraction sont comparés pour identifier les extraits de texte qui peuvent être mappés dans les cases du guide. Ces extraits de texte sont des indicateurs d’unités de zone pour le contenu de l’outline. Ce document a proposé deux méthodes (résumption de document unique et résumption de multi-documents) pour la résumison de documents. Pour créer des extraits et des résumés à partir de documents, ils ont suivi les méthodes décrites dans GISTEXTER.
Élaboré pour l’extraction d’information, GISTEXTER est un système de résumison qui identifie l’information liée au sujet dans le texte d’entrée et la convertit en entrées de base de données ; les phrases sont ensuite ajoutées au résumé selon les demandes de l’utilisateur.

Méthodes basées sur l’ontologie
De nombreux chercheurs ont essayé d’améliorer l’efficacité des résumés en utilisant des ontologies (base de connaissances). La plupart des documents sur Internet traitent d’un domaine commun, c’est-à-dire qu’ils traitent tout d’une même question générale. Une ontologie est une représentation puissante de l’information structurale unique de chaque domaine.
Ce document propose d’utiliser une ontologie floue, qui modélise l’incertitude et décrit précisément les connaissances du domaine, pour rédiger les résumés des nouvelles chinoises. Dans cette méthode, les experts du domaine définissent d’abord l’ontologie du domaine pour les événements journalistiques, puis la phase de préparation des documents extrait des mots sémantiques du corpus des nouvelles et du dictionnaire chinois des nouvelles.
Méthode des phrases introductives et du corps
Cette approche consiste à réécrire la phrase d’introduction en effectuant des opérations sur les phrases avec le même module de synthèse (insertion et substitution) dans l’introduction et le corps de la phrase. En utilisant l’analyse syntaxique des modules de phrases, Tanaka a suggéré une technique pour résumer les nouvelles écoutées. Des méthodes de fusion de phrases sont utilisées pour inférer la base de ce concept.
Résumer les bulletins d’information consiste à localiser les phrases communes entre l’introduction et le corps du texte, puis à insérer et à remplacer ces phrases pour produire un résumé par révision de phrases. Premièrement, un parseur syntaxique est appliqué aux parties introduction et corps. Ensuite, les paires de recherche de déclencheurs sont identifiées, et finalement, les phrases sont alignées en utilisant diverses critères de similarité et d’alignement. La dernière étape peut être soit une insertion, soit une substitution ou les deux.
Le processus d’insertion implique de choisir un point d’insertion, de vérifier pour la redondance et de vérifier le discours pour assurer la cohérence interne, pour garantir la cohérence et l’élimination de la redondance. L’étape de substitution fournit plus d’information en substituant la phrase du corps dans l’introduction.
Méthode basée sur des règles
Dans cette technique, les documents à résumer sont décrits en fonction de classes et d’une liste d’aspects. Le module de choix de contenu sélectionne le candidat le plus efficace parmi ceux générés par les règles d’extraction de données pour répondre à un ou plusieurs aspects d’une catégorie. Enfin, les patrons de génération sont utilisés pour la génération de phrases de schéma.
Pour identifier les noms et verbes semantiquement liés, Pierre-Etienne et al. ont proposé un ensemble de critères pour l’extraction d’information. Une fois extraits, les données sont envoyées à l’étape de sélection du contenu, qui s’efforce de filtrer les candidats mélangés. Il est utilisé pour la structure des phrases et les mots dans un schéma de génération directe. Après la génération, une summarisation guidée par le contenu est effectuée.
Methodes basées sur le graphe
De nombreux chercheurs utilisent une structure de données de type graphe pour représenter les documents linguistiques. Les graphes sont une sélection courante pour représenter les documents dans la communauté de recherche en linguistique. Chaque noeud dans le système représente une unité de mot, accompagné de flèches orientées, définissant ainsi la structure d’une phrase. Pour améliorer les performances de la synthèse, Dingding Wang et al. ont proposé des systèmes de synthèse de documents multiples utilisant une large gamme de stratégies, telles que la méthode du centre de masse, la méthode du graphe, etc., pour évaluer diverses méthodes de base de combinaison, telles que la moyenne des scores, la moyenne des ranks, le comptage de Borda, l’agrégation de médianes, etc.
Une méthode de consensus pondéré unique est développée pour rassembler les résultats de différentes stratégies de synthèse. Dans une approche sémantique, une illustration linguistique d’un document ou de documents est utilisée pour alimenter un système de génération de langage naturel (NLG). Cette technique se spécialise dans l’identification de phrases nominales et verbales à l’aide de données linguistiques.
APPROCHE SÉMANTIQUE
Les approches sémantiques utilisent l’illustration linguistique d’un document pour alimenter un système de génération de langage naturel (NLG). Cette méthode traite les données linguistiques pour identifier les phrases nominales et verbales.
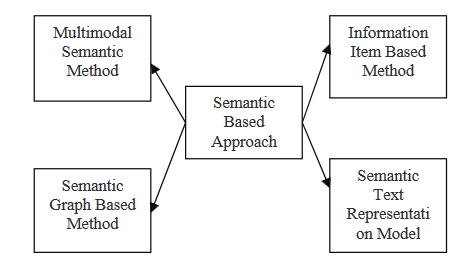
- Modèle sémantique multimodal : Dans ce cas, un modèle linguistique captant les concepts et les relations entre les idées est créé pour décrire le contenu de documents multimodaux tels que le texte et les images. Les idées clés sont évaluées à l’aide de plusieurs critères, et les concepts sélectionnés sont ensuite exprimés sous forme de phrases pour former un résumé.
- Méthode axée sur l’élément d’information : Dans cette approche, plutôt que d’utiliser des phrases des documents de base, une représentation abstraite de ces documents est utilisée pour générer le contenu du résumé. L’illustration abstraite est un élément d’information, la plus petite partie cohérente d’information dans un texte.
- Modèle de graphe sémantique : Cette technique vise à résumer un document en construisant un graphe sémantique riche (GSR) pour le document initial, puis en réduisant le graphe linguistique créé et en générant l’outline abstraitif final à partir du graphe linguistique réduit.
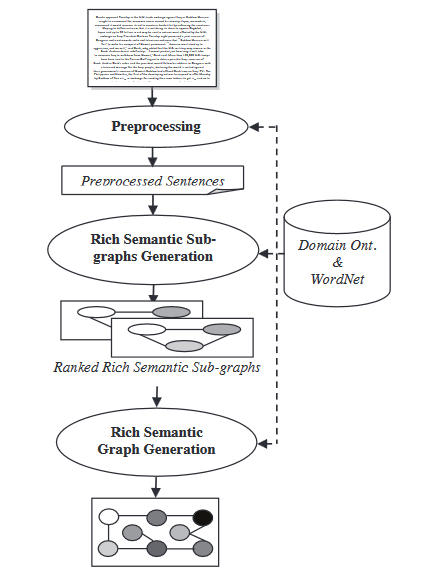
Pendant la phase de génération du graphe sémantique riche, un ensemble de règles heuristiques est appliqué au graphe sémantique riche généré pour le réduire en fusionnant, supprimant ou consolideant les nœuds du graphe.
- Modèle de représentation textuelle sémantique : Cette technique analyse le texte d’entrée en utilisant la sémantique des mots plutôt que la syntaxe/Structure du texte.
Études de cas en affaires
- Programmation de langages informatiques : Plusieurs efforts ont été déployés pour développer une technologie IA capable d’écrire du code et de développer des sites Web indépendamment. Dans l’avenir, les programmeurs pourraient être en mesure de compter sur des « résumés de code » spécialisés pour extraire les éléments essentiels de projets nouveaux.
- Aide à ceux qui sont physiquement handicapés : Les personnes ayant de la difficulté à entendre pourraient trouver que le résumé leur permet de mieux suivre le contenu grâce à l’avancement de la technologie de conversion audio en texte.
- Conférences et autres réunions vidéo : Avec l’expansion du télétravail, la capacité de pouvoir enregistrer les idées et le contenu significatifs des interactions est de plus en plus requise. Il serait fantastique si vos séances d’équipe pouvaient être résumées à l’aide d’une méthode de conversion audio en texte.
- La recherche de brevets : Trouver de l’information pertinente sur les brevets pourrait être temps-consommant. Un générateur de résumés de brevets pourrait vous sauver du temps que vous effectuez soit des recherches de marché ou que vous préparez un nouveau brevet.
- Livres et littérature : Les résumés sont utiles car ils offrent aux lecteurs une overview concise du contenu qu’ils peuvent attendre d’un livre avant de décider s’il le faire acheter.
- Publicité par le biais des médias sociaux : Les organisations qui créent des livres blancs, des e-books et des blogs de la société pourraient utiliser le résumé pour rendre leur travail plus digeste et plus partageable sur les plateformes telles que Twitter et Facebook.
- Recherche économique : L’industrie de la banque d’investissement investit des montants vastes dans l’acquisition de données pour les utiliser dans les décisions, telles que les transactions boursières automatisées. Tout analyste financier qui passe toute la journée à examiner les données et les nouvelles du marché finira par atteindre l’overload informationnel. Les documents financiers, tels que les rapports financiers et les nouvelles financières, pourraient tirer profit de systèmes de résumé qui permettent aux analystes de dégager des signaux du marché du contenu rapidement.
- Promouvoir votre entreprise en utilisant l’optimisation pour les moteurs de recherche : Les évaluations de l’optimisation pour les moteurs de recherche (SEO) nécessitent une connaissance approfondie des sujets discutés dans le contenu des concurrents. Il s’agit d’une importance primordiale en tenant compte des modifications récentes de l’algorithme de Google et de l’emphase ultérieure sur l’autorité du sujet. La capacité de résumer rapidement plusieurs documents, identifier les points communs et scanner les informations cruciales peut être un outil de recherche puissant.
Conclusion
Bien que le résumé abstrait soit moins fiable que les approches extractives, il présente un potentiel incroyable pour produire des résumés alignés avec la manière dont les humains les écriraient. Par conséquent, une multitude de nouvelles techniques computationnelles, cognitives et linguistiques est susceptible de surgir dans ce domaine.
Références
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques