













Les données en temps réel sont importantes pour les entreprises afin de prendre des décisions rapides. Visualiser ces données peut aider à prendre des décisions encore plus rapidement. Nous pouvons créer des représentations visuelles des données à l’aide de diverses applications de données ou tableaux de bord. Dash est une bibliothèque Python open-source qui offre un large éventail de composants intégrés pour créer des graphiques interactifs, des tableaux, des tableaux et d’autres éléments UI. RisingWave est une base de données SQL de streaming pour le traitement des données en temps réel. Cet article expliquera comment utiliser Python, Dash et RisingWave pour créer des visualisations de données en temps réel.
Comment visualiser les données en temps réel
Nous savons que les données en temps réel sont des données générées et traitées immédiatement, lorsqu’elles sont collectées à partir de différentes sources de données. Les sources peuvent être des bases de données classiques telles que Postgres ou MySQL, et des brokers de messages comme Kafka. Une visualisation de données en temps réel comprend quelques étapes : d’abord, nous ingérons, puis traitons, et enfin montrons ces données dans un tableau de bord.
Dans le cas des données de livraison d’ordres, visualiser ces données en temps réel peut fournir des informations précieuses sur la performance d’un restaurant ou d’un service de livraison. Par exemple, nous pouvons utiliser les données en temps réel pour surveiller le temps qu’il faut pour livrer les commandes, identifier les goulots d’étranglement dans le processus de livraison et suivre les changements dans le volume des commandes au fil du temps. Lorsqu’on traite avec des données qui changent constamment, il peut être difficile de suivre tout ce qui se passe et d’identifier des modèles ou tendances. En utilisant des outils gratuits tels que Dash et RisingWave, nous pouvons créer des visualisations interactives qui nous permettent d’explorer et d’analyser ces données en constante évolution.
En ce qui concerne le travail avec des données, le premier langage de programmation auquel vous pourriez penser est Python, car il dispose d’une gamme de bibliothèques. Dash en est une qui nous permet de créer une application de données avec une interface utilisateur riche et personnalisable en utilisant uniquement du code Python. Dash est construit sur Flask, Plotly.js et React.js, des outils populaires de développement web, vous n’avez donc pas besoin de connaître HTML, CSS ou d’autres frameworks JavaScript.
Avec RisingWave, nous pouvons consommer des flux de données provenant de diverses sources, créer des vues matérialisées optimisées pour des requêtes complexes et interroger des données en temps réel en utilisant SQL. Comme RisingWave est compatible au niveau du raccordement avec PostgreSQL, nous pouvons utiliser le pilote psycopg2 (bibliothèque cliente PostgreSQL en Python) pour se connecter à RisingWave et effectuer des opérations de requête. Voir la section suivante.
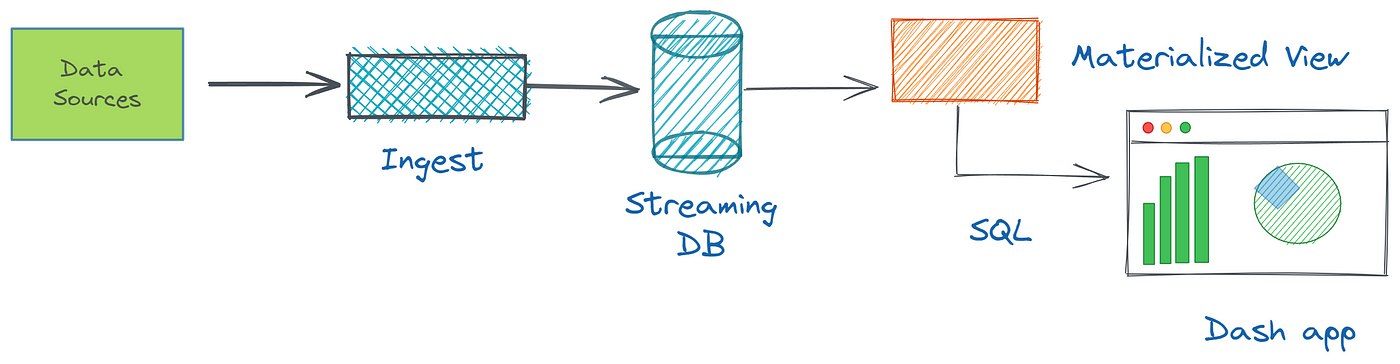
Visualiser les données de livraison d’ordres – Démo
Dans le tutoriel de démonstration, nous allons exploiter le dépôt GitHub avec les démos RisingWave où nous supposons que toutes les choses nécessaires sont configurées à l’aide de Docker Compose. Vous pouvez consulter les autres méthodes pour exécuter RisingWave sur le site officiel. Nous avons un sujet Kafka nommé delivery_orders qui contient des événements pour chaque commande passée sur un site de livraison de nourriture. Chaque événement inclut des informations sur la commande, telles que le ID de commande, le ID de restaurant, et le statut de livraison. Le générateur de charge de travail (script Python appelé Datagen) simule la génération de données fictives aléatoires en continu et les diffuse dans les sujets Kafka. En réalité, ces données fictives peuvent être remplacées par des données provenant de votre application web ou service backend.
Avant de commencer
Pour réaliser ce tutoriel, vous avez besoin des éléments suivants:
- Assurez-vous d’avoir Docker et Docker Compose installés dans votre environnement.
- Assurez-vous que l’interface interactive PostgreSQL, psql, est installée dans votre environnement. Pour des instructions détaillées, voir Télécharger PostgreSQL.
- Téléchargez et installez Python 3 pour votre système d’exploitation. La commande
pipsera installée automatiquement.
Le démo que j’ai testé sur le système d’exploitation Windows, Docker Desktop, et Python 3.10.11 version installée.
Étape 1 : Configuration du cluster de démonstration RisingWave
Tout d’abord, clonez le référentiel d’exemple RisingWave dans votre environnement local.
git clone <https://github.com/risingwavelabs/risingwave.git>
Ensuite, accédez au répertoire integration_tests/delivery et lancez le cluster de démonstration à partir du fichier docker compose.
cd risingwave/integration_tests/delivery
docker compose up -d
Assurez-vous que tous les conteneurs sont en cours d’exécution!
Étape 2 : Installation des bibliothèques Dash et Psycopg2
Pour installer Dash, vous pouvez également vous référer au guide Installation de Dash sur le site web. Fondamentalement, nous devons installer deux bibliothèques (Dash lui-même et Pandas) en exécutant la commande pip install suivante :
# This also brings along the Plotly graphing library.
# Plotly is known for its interactive charts
# Plotly Express requires Pandas to be installed too.
pip install dash pandas
Nous devons également installer psycopg2 pour interagir avec la base de données en streaming RisingWave :
pip install psycopg2-binary
Étape 3 : Créer une Source de Données
Pour ingérer des données en temps réel avec RisingWave, vous devez d’abord configurer une source de données. Dans le projet de démonstration, Kafka doit être défini comme source de données. Nous allons créer un nouveau fichier appelé create-a-source.py, dans le même répertoire integration_tests/delivery avec le script Python où nous nous connectons à RisingWave et créons une table pour consommer et persister les sujets Kafka delivery_orders. Vous pouvez simplement copier et coller le code ci-dessous dans le nouveau fichier.
import psycopg2
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566") # Connect to RisingWave.
conn.autocommit = True # Set queries to be automatically committed.
with conn.cursor() as cur:
cur.execute("""
CREATE TABLE delivery_orders_source (
order_id BIGINT,
restaurant_id BIGINT,
order_state VARCHAR,
order_timestamp TIMESTAMP
) WITH (
connector = 'kafka',
topic = 'delivery_orders',
properties.bootstrap.server = 'message_queue:29092',
scan.startup.mode = 'earliest'
) ROW FORMAT JSON;""") # Execute the query.
conn.close() # Close the connection.
Après avoir créé le fichier, vous exécutez python create-a-source.py et cela créera la table source dans RisingWave.
Étape 4 : Créer une Vue Matérialisée
Ensuite, nous créons une nouvelle vue matérialisée semblable à la manière dont nous avons créé la table. Nous créons un nouveau fichier nommé create-a-materialized-view.py et exécutons une requête SQL en utilisant la bibliothèque psycopg2. Il est également possible de fusionner les deux dernières étapes ci-dessus en un seul fichier de script Python.
import psycopg2
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566")
conn.autocommit = True
with conn.cursor() as cur:
cur.execute("""CREATE MATERIALIZED VIEW restaurant_orders_view AS
SELECT
window_start,
restaurant_id,
COUNT(*) AS total_order
FROM
HOP(delivery_orders_source, order_timestamp, INTERVAL '1' MINUTE, INTERVAL '15' MINUTE)
WHERE
order_state = 'CREATED'
GROUP BY
restaurant_id,
window_start;""")
conn.close()
Ci-dessus, la requête SQL calcule le nombre total de commandes créées à partir d’un restaurant spécifique au cours des 15 dernières minutes en temps réel et stocke le résultat dans la vue matérialisée. Si des changements de données se produisent ou si de nouveaux sujets Kafka arrivent, RisingWave incrémente et met à jour automatiquement le résultat de la vue matérialisée. Une fois que vous avez configuré la source de données, la vue matérialisée, vous pouvez commencer à ingérer des données et à visualiser ces données à l’aide de Dash.
Étape 5 : Création d’une application Dash
Nous construisons maintenant notre application Dash pour interroger et visualiser le contenu de la vue matérialisée que nous avons dans RisingWave. Vous pouvez suivre le tutoriel Dash en 20 minutes pour comprendre les éléments de base de Dash. Notre exemple de code d’application affiche les données de commande des restaurants sous forme de tableau et de graphique. Voir le code Python ci-dessous dans dash-example.py :
import psycopg2
import pandas as pd
import dash
from dash import dash_table
from dash import dcc
import dash_html_components as html
import plotly.express as px
# Connect to the PostgreSQL database
conn = psycopg2.connect(database="dev", user="root", password="", host="localhost", port="4566")
# Retrieve data from the materialized view using pandas
df = pd.read_sql_query("SELECT window_start, restaurant_id, total_order FROM restaurant_orders_view;", conn)
# Create a Dash application
app = dash.Dash(__name__)
# Define layout
app.layout = html.Div(children=[
html.H1("Restaurant Orders Table"),
dash_table.DataTable(id="restaurant_orders_table", columns=[{"name": i, "id": i} for i in df.columns], data=df.to_dict("records"), page_size=10),
html.H1("Restaurant Orders Graph"),
dcc.Graph(id="restaurant_orders_graph", figure=px.bar(df, x="window_start", y="total_order", color="restaurant_id", barmode="group"))
])
# Run the application
if __name__ == '__main__':
app.run_server(debug=True)
Ce code extrait les données de la vue matérialisée restaurant_orders_view à l’aide de pandas et les affiche dans un tableau Dash à l’aide de dash_table.DataTable et un graphique en barres à l’aide de dcc.Graph. Le tableau et le graphique en barres ont des colonnes qui correspondent aux colonnes de la vue matérialisée (‘window_start’, ‘total_order’, et ‘restaurant_id’) et des lignes qui correspondent aux données de la vue matérialisée.
Étape 6 : Afficher les Résultats
Vous pouvez exécuter l’application en lançant le script dash-example.py ci-dessus et en vous rendant sur http://localhost:8050/ dans votre navigateur web (vous recevrez un message dans le terminal vous indiquant d’aller à cette adresse).
Résumé
Dans l’ensemble, Dash est un outil puissant pour créer des vues analytiques de données qui nécessitent des interfaces utilisateur complexes et des capacités de visualisation des données, tout en utilisant la simplicité et l’élégance du langage de programmation Python. Lorsque nous l’utilisons avec la base de données en streaming RisingWave, nous obtenons des insights sur les données en temps réel qui peuvent nous aider à prendre des décisions plus éclairées et à agir pour optimiser les performances.
Ressources connexes
Source:
https://dzone.com/articles/visualize-real-time-data-with-python-dash-and-risi