













Une identité peut-elle exister sans être référencée par une autre identité? Comment le saurions-nous?
Cela peut sembler un peu philosophique pour un article technologique sur la sécurité, mais c’est un point important à garder à l’esprit lorsqu’on aborde le sujet des identités non humaines. Une meilleure question en matière de sécurité serait en fait, « Devrait une identité exister si elle ne peut pas interagir avec? » Nous pourrions ne pas être en mesure de répondre à cette première question, car prouver la nature de la réalité dépasse un peu le champ de la science informatique. Cependant, de nombreuses personnes travaillent dur pour mettre en place des outils de gouvernance NHI afin de déterminer si une identité de machine existe, pourquoi elle existe, et répondre à la question de savoir si elle devrait exister.
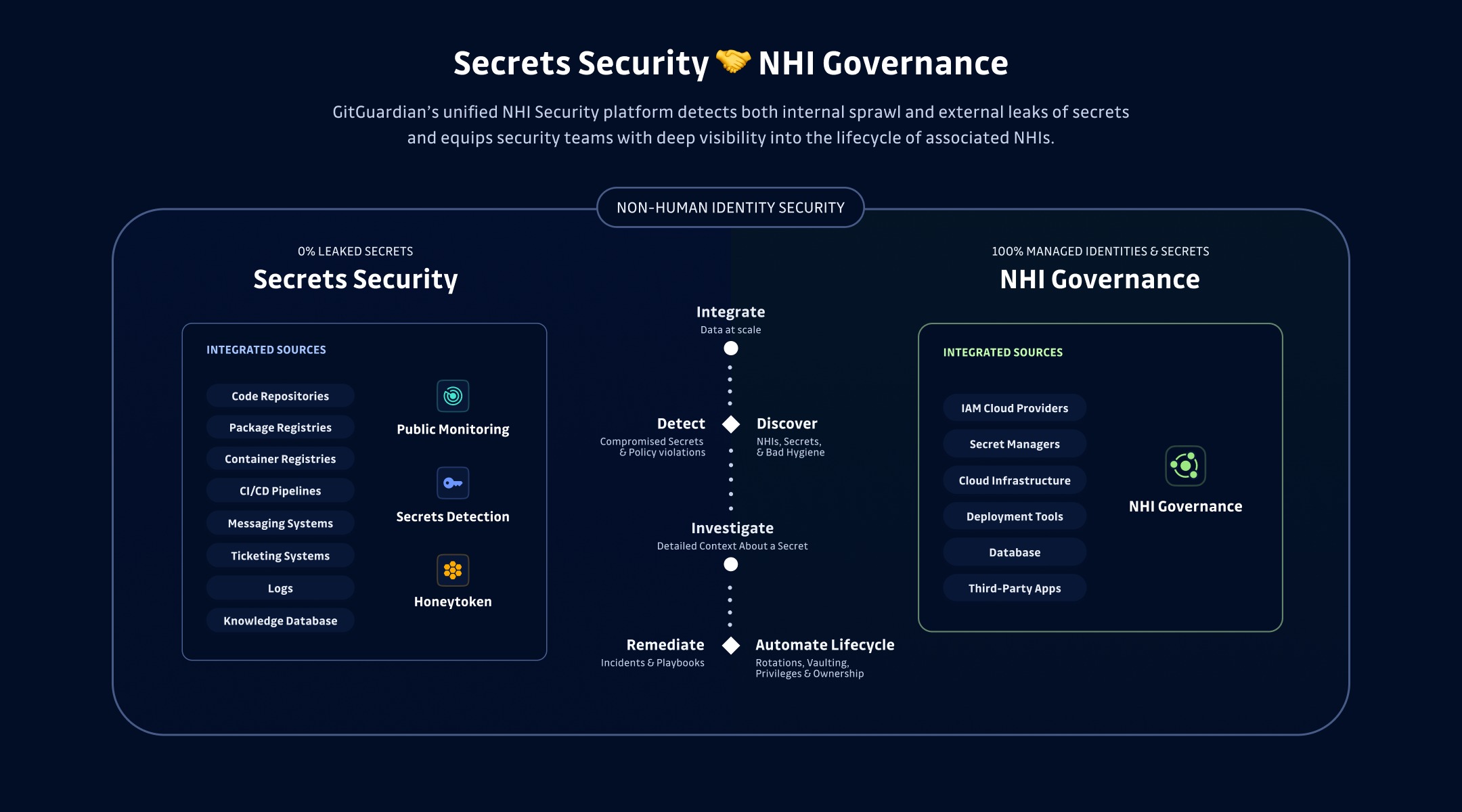
L’avenir de l’élimination de la prolifération des secrets signifie avoir une meilleure compréhension des cycles de vie et des interdépendances des identités non humaines qui dépendent de secrets. Mais pourquoi maintenant? Revenons en arrière et réexaminons certaines de nos hypothèses sur les NHIs et leur existence.
Qu’est-ce que les identités non humaines?
Avant de continuer, définissons NHI dans le contexte de cette conversation.
In the simplest terms, a non-human identity, also commonly referred to as a machine identity or a workload identity, is any entity that is not human and can perform an action within your system, most commonly interacting exclusively with other non-humans.
Cela pourrait être un pod Kubernetes qui doit interagir avec une source de données et envoyer les données traitées à un système de reporting. Cela pourrait être un capteur de l’ Internet des objets (IdO) envoyant des données à un serveur central. Cela pourrait être un chatbot basé sur Slack. Si aucune intervention humaine n’est directement nécessaire après la création initiale pour que l’entité puisse travailler, alors nous devrions considérer cette identité comme ‘non humaine’.
La seule chose que tous ces exemples ont en commun est qu’ils interagissent avec un autre système. Si nous voulons qu’ils communiquent avec le monde entier, c’est facile, il suffit de pointer vers les autres identités non humaines et de décrire de manière programmatique comment elles devraient interagir. Cependant, nous voulons très probablement que ces systèmes communiquent de manière sécurisée, n’autorisant que des identités spécifiques dans des circonstances spécifiques. Cela a conduit à l’évolution des secrets pour la gestion des accès, des simples paires nom d’utilisateur/mot de passe aux clés API et certificats.
De toute évidence, c’est une définition large des NHI. Cependant, nous pouvons préciser ce qui nous importe avec les identités machine en prenant du recul et en considérant comment ces entités se rapportent les unes aux autres à travers le prisme de leurs secrets, permettant l’accès et la communication.
Tous les NHI se connectent à d’autres systèmes
Pouvez-vous créer une application autonome qui n’accepte aucune entrée, ne produit aucune sortie et n’a pas d’interface adressable? Une telle application existe-t-elle en dehors d’une expérience de pensée? Bien que cela soit amusant d’y penser, la réalité est que tous les NHI qui nous intéressent existent pour communiquer avec d’autres identités.
Les NHI nécessitent intrinsèquement des connexions avec d’autres systèmes et services pour remplir leur objectif. Cette interconnectivité signifie que chaque NHI devient un nœud dans une toile d’interdépendances. Du point de vue de la gouvernance des NHI, cela nécessite de maintenir un inventaire précis et dynamique de ces connexions pour gérer les risques associés. Par exemple, si un seul NHI est compromis, à quoi est-il connecté et à quoi un attaquant pourrait-il accéder pour se déplacer latéralement?
Une gouvernance appropriée du NHI doit inclure des outils pour cartographier et surveiller ces relations. Alors qu’il existe de nombreuses façons de procéder manuellement, ce que nous voulons en réalité est une méthode automatisée pour savoir ce qui est connecté à quoi, ce qui est utilisé à quel usage, et par qui. En pensant à la sécurisation de nos systèmes, nous pouvons exploiter un autre fait important concernant tous les NHIs dans une application sécurisée pour construire cette carte, ils ont tous, nécessairement, des secrets.
Tous les NHIs sécurisés doivent avoir un secret
Pour établir une communication de confiance entre deux NHIs, un secret unique, tel qu’une clé API, un jeton, ou un certificat, doit exister pour que ces entités s’authentifient. Nous pouvons utiliser le secret pour prouver l’identité d’un NHI et le cartographier dans l’écosystème. La question est alors, où chercher ces secrets ?
Dans l’entreprise moderne, en particulier les plus grandes, il n’y a essentiellement que deux endroits où un secret peut résider. Votre première option est la meilleure pratique et la plus sûre : un système de gestion des secrets, tel que Conjur de CyberArk, Vault de HashiCorp, ou AWS Secrets Manager. L’autre option est beaucoup moins sécurisée mais malheureusement trop courante : en dehors d’un coffre, dans du code, ou une configuration en texte clair.
Les plateformes de gestion des secrets d’entreprise, souvent appelées coffres, sont essentielles pour stocker et protéger les secrets utilisés par les NHI. Les coffres peuvent fournir une source unique de vérité pour tous les secrets, garantissant qu’ils sont chiffrés au repos, soumis à un contrôle d’accès strict et surveillés pour détecter les tentatives d’accès non autorisées. Cela suppose que vous vous soyez standardisé sur une seule plateforme de gestion des secrets d’entreprise. La plupart des organisations utilisent en réalité de nombreux coffres en même temps, rendant la synchronisation entre tous les coffres un défi supplémentaire.
Les équipes peuvent cartographier toutes les identités machines existantes en fonction de l’existence de ces secrets. Pour les entreprises ayant plusieurs solutions de gestion des secrets en place, vous devez savoir quels coffres contiennent ou ne contiennent pas un secret et réduire la surcharge de stockage de la même clé de manière redondante dans plusieurs coffres.
Tous les secrets NHI ont une histoire d’origine
Les machines ne peuvent pas s’accorder elles-mêmes des autorisations et un accès. Chaque identité machine a été créée par ou représente une identité humaine. La gouvernance des NHI doit inclure le suivi de la création des secrets pour s’assurer que chaque secret est traçable à son origine, distribué en toute sécurité et lié à une identité légitime. Bien que cet aspect puisse être pris en compte avec l’utilisation appropriée d’une plateforme de gestion des secrets, nos données continuent de nous indiquer qu’un certain pourcentage de secrets fuitent année après année parce que nous n’utilisons pas de manière cohérente ces solutions de coffre.
Nous savons, grâce à des années d’expérience à aider les équipes à remédier aux incidents, que le créateur d’un secret sera presque toujours la personne qui a d’abord introduit le credential dans un écosystème. Nous pouvons également déterminer, à partir de l’historique du code ou d’autres informations de timestamp du système, quand cela a été vu pour la première fois, ce qui est le moment le plus probable de sa création ou, du moins, de son existence d’une manière significative.
C’est un détail critique qui n’a peut-être jamais été correctement enregistré ou documenté ailleurs. Une fois que vous comprenez qui a créé un secret pour pouvoir tirer parti d’un NHI, vous comprenez alors véritablement le début de notre cycle de vie NHI.
Tous les Secrets NHI Doivent Accorder un Certain Ensemble de Permissions
Lors de leur création, chaque secret NHI doit se voir accorder un certain ensemble de permissions. La portée détermine quelles actions une identité peut effectuer et sur quels systèmes. Cela rend la définition et l’application des permissions des composants cruciaux de la gouvernance.
Essentiellement, deux risques rendent la compréhension de la portée d’un secret critique pour la sécurité des entreprises. Le premier est que des secrets mal configurés ou trop privilégiés peuvent involontairement accorder l’accès à des données sensibles ou à des systèmes critiques, augmentant considérablement la surface d’attaque. Imaginez accorder accidentellement des privilèges d’écriture à un système qui peut accéder aux données personnelles identifiables de vos clients. C’est une horloge qui tourne, attendant qu’un acteur malveillant la trouve et l’exploite.
De plus, tout aussi préoccupant est que lorsqu’un secret est divulgué ou compromis, une équipe ne peut pas le remplacer tant qu’elle n’a pas d’abord compris comment ces autorisations étaient configurées. Par exemple, supposez que vous sachiez qu’un secret critique pour la mission d’un microservice a été accidentellement poussé dans un dépôt public GitHub. Dans ce cas, il est seulement question de temps avant qu’il ne soit découvert et utilisé par quelqu’un à l’extérieur de votre organisation. Dans notre récent rapport Voice of the Practitioner, les décideurs informatiques ont admis qu’il leur fallait, en moyenne, 27 jours pour faire tourner ces secrets critiques. Les équipes devraient pouvoir agir en quelques secondes ou minutes, pas en jours.
Des outils fournissant un contexte supplémentaire sur les secrets détectés, y compris leurs rôles et autorisations, sont nécessaires. Comprendre rapidement quels actifs sont exposés lorsqu’une fuite se produit et quels dommages potentiels peuvent être infligés par un acteur malveillant est essentiel pour répondre à un incident. Savoir exactement comment le remplacer à partir d’une vue tableau de bord ou d’un appel API peut faire la différence entre une violation et un attaquant frustré découvrant que la clé qu’il possède est invalide.
Tous les secrets NHI doivent être tournés
Une identité machine peut, et devrait probablement, avoir de nombreux secrets au cours de sa vie. Si les informations d’identification sont laissées actives pendant des mois ou des années, ou dans le pire des cas, pour toujours, l’exposition ou la compromission des secrets NHI devient de plus en plus probable. La rotation manuelle est sujette aux erreurs et exigeante en termes opérationnels, notamment dans des environnements comprenant des milliers de NHI. L’automatisation du processus de rotation des secrets est un pilier de la gouvernance des NHI, garantissant que les secrets sont actualisés avant leur expiration ou leur fuite.
Pour l’un des secrets stockés dans vos coffres, la rotation devrait être une simple question de script. La plupart des plateformes de gestion des secrets fournissent des scripts ou un autre mécanisme pour gérer le délicat processus de remplacement et de révocation du vieux secret en toute sécurité.
Mais que dire des secrets NHI qui se trouvent en dehors de ces coffres, ou peut-être du même secret réparti dans plusieurs coffres ? Une bonne plateforme de balayage des secrets doit s’intégrer de manière transparente avec ces coffres afin que votre équipe puisse plus facilement les trouver et les stocker en toute sécurité dans le gestionnaire de secrets, et préparer le terrain pour une rotation automatisée. L’implémentation de référence de GitGuardian avec Conjur de CyberArk détaille comment vous pouvez automatiser entièrement le processus de stockage et de rotation.
En identifiant tous les NHI et en sachant quand ils ont été créés, nous pouvons également prédire quand ils doivent être renouvelés. Bien que chaque équipe juge exactement combien de temps chaque secret doit vivre, tout secret qui n’a jamais été renouvelé après sa création est prêt à être remplacé. Tout secret âgé de plus d’un an, ou pour certains systèmes critiques, de quelques jours, devrait également être priorisé pour un renouvellement dès que possible.
Tous les NHI auront une fin de vie
Les NHI, comme leurs homologues humains, ont des cycles de vie limités. Ils peuvent être décommissionnés lorsqu’un service est retiré, remplacé ou n’est plus nécessaire. Sans aborder la désactivation et le nettoyage des NHI pour empêcher la persistance de secrets inutilisés ou de connexions obsolètes, nous créons des angles morts en matière de sécurité. Mais comment savons-nous quand nous sommes à la fin de la route pour un NHI, surtout si son secret reste valide ?
Une réponse est qu’il ne devrait plus exister lorsqu’un NHI ne se connecte plus à un autre système actif. Cela garantit que les attaquants ne peuvent pas exploiter les secrets de NHI obsolètes pour prendre pied dans votre environnement. Rappelez-vous que les attaquants ne se soucient pas de la manière dont un secret doit être utilisé de manière appropriée ; ils se soucient uniquement de ce qu’ils peuvent en faire.
En cartographiant toutes les relations que les secrets d’un NHI permettent, vous pouvez identifier quand un système n’est plus connecté à aucune autre identité. Une fois qu’il n’y a plus de moyens pour une identité de communiquer, alors elle et ses secrets ne devraient plus exister. Cela signifie également que le secret n’a plus besoin d’être stocké dans vos gestionnaires de secrets, vous offrant une chose de moins à stocker et à gérer.
Comprendre le monde qui entoure vos NHI est crucial pour la sécurité.
En 2022, la recherche de CyberArk a montré que pour chaque identité humaine dans un environnement, au moins 45 identités non humaines doivent être gérées. Ce ratio est probablement aujourd’hui plus proche de 1 à 100 et ne cesse d’augmenter. Le meilleur moment pour s’attaquer à votre gouvernance et gestion du cycle de vie des NHI était il y a des années. Le prochain meilleur moment est maintenant.
Il est temps d’adopter une approche de cycle complet pour la sécurité des identités non humaines, en traçant non seulement l’emplacement de vos secrets NHI, mais, tout aussi important, quelles autres NHI sont connectées. Nous sommes en retard, dans tous les secteurs, pour mettre en œuvre une gouvernance des NHI à grande échelle. Trouver et stocker correctement vos secrets n’est que le début de l’histoire. Nous devons mieux documenter et comprendre la portée des secrets NHI, leur ancienneté, qui les a mis en œuvre, et d’autres informations contextuelles, telles que le moment où ils doivent être renouvelés.
Bien que les identités machines soient plus nombreuses que les êtres humains, il n’y a aucune raison de travailler seul pour résoudre ce problème ; nous sommes tous dans le même bateau.
Source:
https://dzone.com/articles/understanding-non-human-identities-governance