













Les microservices et les conteneurs révolutionnent la manière dont les applications modernes sont construites, déployées et gérées dans le cloud. Cependant, le développement et l’exploitation des microservices peuvent introduire une complexité significative, nécessitant souvent aux développeurs de passer du temps précieux sur des préoccupations transversales telles que la découverte de services, la gestion de l’état et l’observabilité.
Dapr, ou Distributed Application Runtime, est un runtime open source pour la construction de microservices sur des environnements cloud et edge. Il fournit des blocs de construction indépendants de la plateforme tels que la découverte de services, la gestion de l’état, la messagerie pub/sub et l’observabilité prêts à l’emploi. Dapr est passé au niveau de maturité gradué de CNCF (Cloud Native Computing Foundation) et est actuellement utilisé par de nombreuses entreprises.
Associé à Amazon Elastic Kubernetes Service (Amazon EKS), un service Kubernetes géré par AWS, Dapr peut accélérer l’adoption des microservices et des conteneurs, permettant aux développeurs de se concentrer sur l’écriture de la logique métier sans se soucier de l’infrastructure sous-jacente. Amazon EKS facilite la gestion des clusters Kubernetes, permettant un redimensionnement aisé lorsque les charges de travail évoluent.
Dans cet article de blog, nous explorerons comment Dapr simplifie le développement de microservices sur Amazon EKS. Nous commencerons par plonger dans deux blocs de construction essentiels : l’invocation de service et la gestion de l’état.
Invocation de service
Une communication fluide et fiable entre les microservices est cruciale. Cependant, les développeurs rencontrent souvent des difficultés avec des tâches complexes telles que la découverte de service, la normalisation des APIs, la sécurisation des canaux de communication, la gestion élégante des défaillances et la mise en place de l’observabilité.
Avec l’invocation de service de Dapr, ces problèmes appartiennent au passé. Vos services peuvent communiquer facilement entre eux en utilisant des protocoles standard de l’industrie tels que gRPC et HTTP/HTTPS. L’invocation de service gère toute la partie complexe, de l’enregistrement et de la découverte de service aux tentatives de requête, au chiffrement, au contrôle d’accès et à la traçabilité distribuée.
Gestion de l’État
Le bloc de construction de gestion de l’état de Dapr simplifie la manière dont les développeurs travaillent avec l’état dans leurs applications. Il fournit une API cohérente pour stocker et récupérer des données d’état, indépendamment du magasin d’état sous-jacent (par exemple, Redis, AWS DynamoDB, Azure Cosmos DB).
Cette abstraction permet aux développeurs de créer des applications étatiques sans se soucier des complexités de la gestion et de l’extension des magasins d’état.
Prérequis
Pour suivre ce billet, vous devez disposer des éléments suivants :
- Un compte AWS. Si vous n’en avez pas, vous pouvez en créer un.
- Un utilisateur IAM avec les autorisations appropriées. Le principal de sécurité IAM que vous utilisez doit avoir la permission de travailler avec les rôles IAM Amazon EKS, les rôles liés au service, AWS CloudFormation, un VPC et les ressources associées. Pour plus d’informations, consultez les Actions, ressources et clés de condition pour Amazon Elastic Container Service pour Kubernetes et Utilisation des rôles liés au service dans le Guide de l’utilisateur AWS Identity and Access Management.
Architecture de l’application
Dans le diagramme ci-dessous, nous avons deux microservices : une application Python et une application Node.js. L’application Python génère des données de commande et appelle l’endpoint /neworder exposé par l’application Node.js. L’application Node.js écrit les données de commande entrantes dans un magasin d’état (ici, Amazon ElastiCache) et renvoie un ID de commande à l’application Python en tant que réponse.
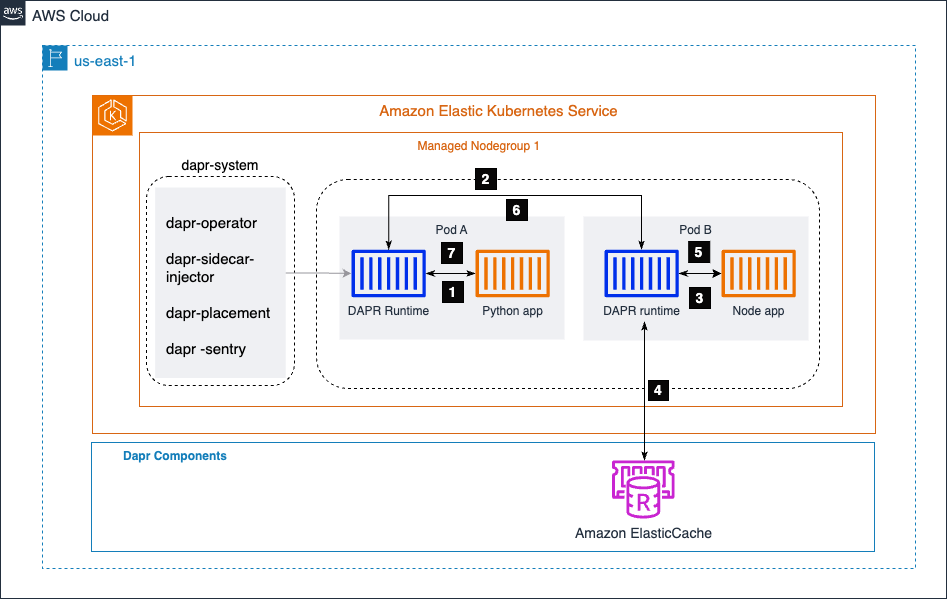
En utilisant le bloc de construction d’invocation de service de Dapr, l’application Python peut communiquer de manière transparente avec l’application Node.js sans se soucier de la découverte de service, de la normalisation de l’API, de la sécurité du canal de communication, de la gestion des erreurs ou de l’observabilité. Il met en œuvre mTLS pour fournir une communication sécurisée entre les services.
Dapr gère ces préoccupations transversales, permettant aux développeurs de se concentrer sur l’écriture de la logique métier principale.
De plus, le bloc de construction de gestion de l’état de Dapr simplifie la façon dont l’application Node.js interagit avec le magasin d’état (Amazon ElastiCache). Dapr fournit une API cohérente pour stocker et récupérer des données d’état, en abstrayant les complexités de la gestion et de la mise à l’échelle du magasin d’état sous-jacent. Cette abstraction permet aux développeurs de construire des applications étatiques sans se soucier des subtilités de la gestion du magasin d’état.
Le cluster Amazon EKS héberge un espace de noms appelé dapr-system, qui contient les composants du plan de contrôle de Dapr. Le dapr-sidecar-injector injecte automatiquement un runtime Dapr dans les pods des microservices activés par Dapr.
Étapes d’Invocation de Service
- Le service de génération de commandes (application Python) invoque la méthode de l’application Node,
/neworder. Cette demande est envoyée au sidecar Dapr local, qui s’exécute dans le même pod que l’application Python. - Dapr résout l’application cible en utilisant le fournisseur de DNS du cluster Amazon EKS et envoie la demande au sidecar de l’application Node.
- Le sidecar de l’application Node envoie ensuite la demande au microservice de l’application Node.
- L’application Node écrit ensuite l’ID de commande reçu de l’application Python dans Amazon ElasticCache.
- L’application Node envoie la réponse à son sidecar Dapr local.
- Le sidecar de l’application Node transmet la réponse au sidecar Dapr de l’application Python.
- Le sidecar de l’application Python renvoie la réponse à l’application Python, qui avait initié la demande à la méthode de l’application Node
/neworder.
Étapes de Déploiement
Créer et Confirmer un Cluster EKS
Pour mettre en place un cluster Amazon EKS (Elastic Kubernetes Service), vous devrez suivre plusieurs étapes. Voici un aperçu général du processus :
Prérequis
- Installer et configurer AWS CLI
- Installer
eksctl,kubectlet AWS IAM Authenticator
1. Créer un cluster EKS. Utilisez eksctl pour créer un cluster de base avec une commande du type :
eksctl create cluster --name my-cluster --region us-west-2 --node-type t3.medium --nodes 3
2. Configurer kubectl. Mettez à jour votre kubeconfig pour vous connecter au nouveau cluster :
aws eks update-kubeconfig --name my-cluster --region us-west-2
3. Vérifier le cluster. Vérifiez si vos nœuds sont prêts :
kubectl get nodes
Installer DAPR sur Votre Cluster EKS
1. Installer DAPR CLI :
wget -q https://raw.githubusercontent.com/dapr/cli/master/install/install.sh -O - | /bin/bash
2. Vérifier l’installation :
dapr -h
3. Installer DAPR et valider :
dapr init -k --dev
dapr status -k
Les composants Dapr statestore et pubsub sont créés dans l’espace de noms par défaut. Vous pouvez le vérifier en utilisant la commande ci-dessous :
dapr components -k
Configurer Amazon ElastiCache comme Votre Dapr StateStore
Créez Amazon ElastiCache pour stocker l’état du microservice. Dans cet exemple, nous utilisons ElastiCache serverless, qui crée rapidement un cache qui s’adapte automatiquement à la demande de trafic de l’application sans serveurs à gérer.
Configurez le groupe de sécurité de l’ElastiCache pour autoriser les connexions depuis votre cluster EKS. Pour des raisons de simplicité, gardez-le dans le même VPC que votre cluster EKS. Prenez note du point de terminaison du cache, dont nous aurons besoin pour les étapes suivantes.
Exécution d’une application de démonstration
1. Clonez le repo Git de l’application de démonstration :
git clone https://github.com/dapr/quickstarts.git
2. Créez redis-state.yaml et fournissez un point de terminaison Amazon ElasticCache pour redisHost :
apiVersiondapr.io/v1alpha1
kindComponent
metadata
namestatestore
namespacedefault
spec
typestate.redis
versionv1
metadata
nameredisHost
valueredisdaprd-7rr0vd.serverless.use1.cache.amazonaws.com6379
nameenableTLS
valuetrue
Appliquez la configuration yaml pour le composant de stockage d’état en utilisant kubectl.
kubectl apply -f redis-state.yaml
3. Déployez des microservices avec le sidecar.
Pour l’application node du microservice, accédez au fichier /quickstarts/tutorials/hello-kubernetes/deploy/node.yaml et vous remarquerez les annotations ci-dessous. Cela indique au plan de contrôle Dapr d’injecter un sidecar et attribue également un nom à l’application Dapr.
annotations
dapr.io/enabled"true"
dapr.io/app-id"nodeapp"
dapr.io/app-port"3000"
Ajoutez une annotation service.beta.kubernetes.io/aws-load-balancer-scheme: « internet-facing » dans node.yaml pour créer AWS ELB.
kindService
apiVersionv1
metadata
namenodeapp
annotations
service.beta.kubernetes.io/aws-load-balancer-scheme"internet-facing"
labels
appnode
spec
selector
appnode
ports
protocolTCP
port80
targetPort3000
typeLoadBalancer
Déployez l’application node en utilisant kubectl. Accédez au répertoire /quickstarts/tutorials/hello-kubernetes/deploy et exécutez la commande ci-dessous.
kubectl apply -f node.yaml
Obtenez le NLB AWS, qui apparaît sous External IP, dans la sortie de la commande ci-dessous.
kubectl get svc nodeapp http://k8s-default-nodeapp-3a173e0d55-f7b14bedf0c4dd8.elb.us-east-1.amazonaws.com
Accédez au répertoire /quickstarts/tutorials/hello-kubernetes, qui contient le fichier sample.json pour exécuter l’étape ci-dessous.
curl --request POST --data "@sample.json" --header Content-Type:application/json http://k8s-default-nodeapp-3a173e0d55-f14bedff0c4dd8.elb.us-east-1.amazonaws.com/neworder
Vous pouvez vérifier la sortie en accédant à l’endpoint /order en utilisant le répartiteur de charge dans un navigateur.
http://k8s-default-nodeapp-3a173e0d55-f7b14bedff0c4dd8.elb.us-east-1.amazonaws.com/order
Vous verrez la sortie comme {“OrderId”:“42”}
Ensuite, déployez la deuxième application Python de microservice, qui a une logique métier pour générer un nouvel identifiant de commande chaque seconde et invoquer la méthode de l’application Node /neworder.
Naviguez vers le répertoire /quickstarts/tutorials/hello-kubernetes/deploy et exécutez la commande ci-dessous.
kubectl apply -f python.yaml
4. Validation et test de votre déploiement d’application.
Maintenant que nous avons déployé les deux microservices. L’application Python génère des commandes et invoque /neworder comme le montrent les journaux ci-dessous.
kubectl logs --selector=app=python -c daprd --tail=-1
time"2024-03-07T12:43:11.556356346Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
time"2024-03-07T12:43:12.563193147Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
Nous pouvons voir que l’application Node reçoit les demandes et écrit dans le magasin d’état Amazon ElasticCache dans notre exemple.
kubectl logs —selector=app=node -c node —tail=-1
Got a new order Order ID: 367
Successfully persisted state for Order ID: 367
Got a new order Order ID: 368
Successfully persisted state for Order ID: 368
Got a new order Order ID: 369
Successfully persisted state for Order ID: 369
Pour confirmer si les données sont persistées dans Amazon ElasticCache, nous accédons à l’endpoint /order ci-dessous. Il renvoie le dernier identifiant de commande, qui a été généré par l’application Python.
http://k8s-default-nodeapp-3a173e0d55-f7b14beff0c4dd8.elb.us-east-1.amazonaws.com/order
Vous verrez une sortie avec la commande la plus récente comme {“OrderId”:“370”}.
Nettoyage
Exécutez la commande ci-dessous pour supprimer les déploiements de l’application Node et de l’application Python ainsi que le composant du magasin d’état.
Naviguez vers le répertoire /quickstarts/tutorials/hello-kubernetes/deploy pour exécuter la commande ci-dessous.
kubectl delete -f node.yaml
kubectl delete -f python.yaml
Vous pouvez démanteler votre cluster EKS en utilisant la commande eksctl et supprimer Amazon ElastiCache.
Naviguez vers le répertoire contenant le fichier cluster.yaml utilisé pour créer le cluster à la première étape.
eksctl delete cluster -f cluster.yaml
Conclusion
Dapr et Amazon EKS forment une alliance puissante pour le développement de microservices. Dapr simplifie les préoccupations transversales, tandis qu’EKS gère l’infrastructure Kubernetes, permettant aux développeurs de se concentrer sur la logique métier principale et d’augmenter leur productivité.
Cette combinaison accélère la création d’applications évolutives, résilientes et observables, réduisant considérablement les tâches opérationnelles. C’est une base idéale pour votre parcours des microservices. Restez à l’affût des prochains articles explorant les capacités de Dapr et EKS en matière de traçage distribué et d’observabilité, offrant des insights approfondis et des meilleures pratiques.
Source:
https://dzone.com/articles/streamline-microservices-development-with-dapr-amazon-eks