













Mikroservices und Container revolutionieren, wie moderne Anwendungen in der Cloud gebaut, bereitgestellt und verwaltet werden. Die Entwicklung und der Betrieb von Mikroservices können jedoch erhebliche Komplexität mit sich bringen, was oft bedeutet, dass Entwickler wertvolle Zeit mit Querschnittsthemen wie Dienstentdeckung, Zustandsverwaltung und Beobachtbarkeit verbringen müssen.
Dapr, oder Distributed Application Runtime, ist eine Open-Source-Laufzeitumgebung zum Erstellen von Mikroservices in Cloud- und Edge-Umgebungen. Es bietet plattformunabhängige Bausteine wie Dienstentdeckung, Zustandsverwaltung, Pub/Sub-Nachrichten und Beobachtbarkeit direkt out of the box. Dapr hat das graduierte Reifelevel der CNCF (Cloud Native Computing Foundation) erreicht und wird derzeit von vielen Unternehmen genutzt.
In Kombination mit dem Amazon Elastic Kubernetes Service (Amazon EKS), einem verwalteten Kubernetes-Service von AWS, kann Dapr die Einführung von Mikroservices und Containern beschleunigen, sodass Entwickler sich auf das Schreiben von Geschäftslogik konzentrieren können, ohne sich um die Infrastruktur kümmern zu müssen. Amazon EKS erleichtert die Verwaltung von Kubernetes-Clustern und ermöglicht müheloses Skalieren, wenn sich die Arbeitslasten ändern.
In diesem Blogbeitrag werden wir untersuchen, wie Dapr die Entwicklung von Mikroservices auf Amazon EKS vereinfacht. Wir beginnen mit zwei wesentlichen Bausteinen: Dienstaufruf und Zustandsverwaltung.
Service Invocation
Eine nahtlose und zuverlässige Kommunikation zwischen Microservices ist entscheidend. Entwickler*innen kämpfen jedoch oft mit komplexen Aufgaben wie der Service-Entdeckung, der Standardisierung von APIs, der Sicherung von Kommunikationskanälen, dem angemessenen Umgang mit Fehlern und der Implementierung von Überwachungsfunktionen.
Mit der Service-Invocation von Dapr gehören diese Probleme der Vergangenheit an. Ihre Dienste können mühelos miteinander kommunizieren, indem sie Branchenstandards wie gRPC und HTTP/HTTPS verwenden. Die Service-Invocation übernimmt alle schweren Aufgaben, von der Dienstregistrierung und -entdeckung bis hin zu Anforderungswiederholungen, Verschlüsselung, Zugriffskontrolle und verteiltem Tracing.
Zustandsverwaltung
Der Zustandsverwaltungs-Baustein von Dapr vereinfacht die Art und Weise, wie Entwickler mit dem Zustand in ihren Anwendungen arbeiten. Er bietet eine konsistente API zum Speichern und Abrufen von Zustandsdaten, unabhängig vom zugrunde liegenden Zustandspeicher (z. B. Redis, AWS DynamoDB, Azure Cosmos DB).
Diese Abstraktion ermöglicht es Entwicklern, zustandsbehaftete Anwendungen zu erstellen, ohne sich um die Komplexität der Verwaltung und Skalierung von Zustandspeichern kümmern zu müssen.
Voraussetzungen
Um diesem Beitrag zu folgen, sollten Sie Folgendes haben:
- Ein AWS-Konto. Wenn Sie noch keins haben, können Sie sich eines erstellen.
- Ein IAM-Benutzer mit den entsprechenden Berechtigungen. Der IAM-Sicherheitsprinzipal, den Sie verwenden, muss die Berechtigung haben, mit Amazon EKS IAM-Rollen, servicegebundenen Rollen, AWS CloudFormation, einem VPC und verwandten Ressourcen zu arbeiten. Weitere Informationen finden Sie unter Aktionen, Ressourcen und Bedingungsschlüssel für Amazon Elastic Container Service für Kubernetes und Verwendung von servicegebundenen Rollen im AWS Identity and Access Management Benutzerhandbuch.
Anwendungsarchitektur
In dem untenstehenden Diagramm haben wir zwei Mikrodienste: eine Python-Anwendung und eine Node.js-Anwendung. Die Python-Anwendung generiert Bestelldaten und ruft den /neworder Endpunkt auf, der von der Node.js-Anwendung bereitgestellt wird. Die Node.js-Anwendung schreibt die eingehenden Bestelldaten in einen Statusspeicher (in diesem Fall Amazon ElastiCache) und gibt der Python-Anwendung als Antwort eine Bestell-ID zurück.
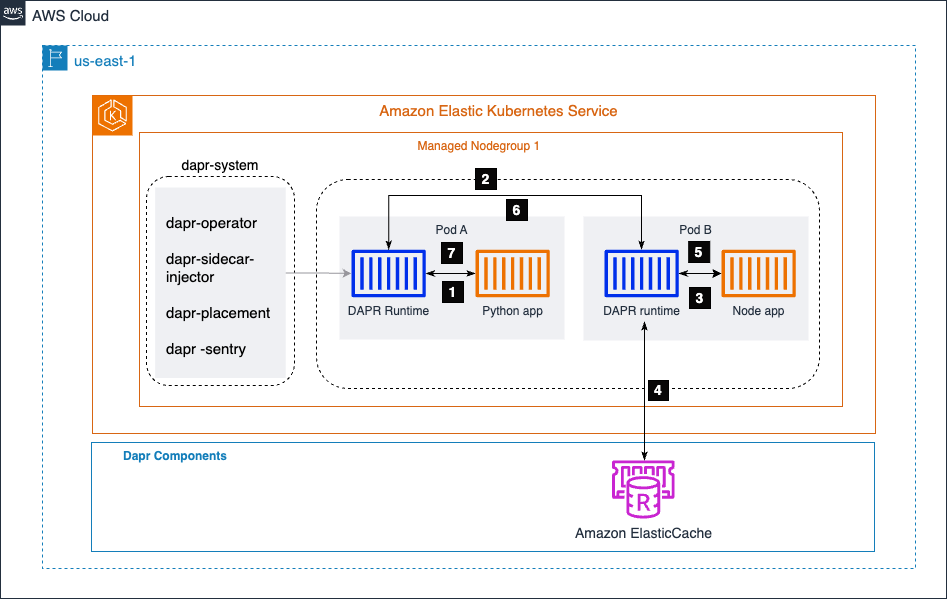
Durch die Nutzung des Dapr-Serviceaufruf-Bausteins kann die Python-Anwendung nahtlos mit der Node.js-Anwendung kommunizieren, ohne sich um Dienstentdeckung, API-Standardisierung, Sicherheit der Kommunikationskanäle, Fehlerbehandlung oder Beobachtbarkeit kümmern zu müssen. Sie implementiert mTLS, um eine sichere Kommunikation zwischen den Diensten zu gewährleisten.
Dapr kümmert sich um diese Querschnittsbelange, sodass sich die Entwickler auf das Schreiben der Kerngeschäftslogik konzentrieren können.
Zusätzlich vereinfacht der Zustandsverwaltungsbaustein von Dapr, wie die Node.js-App mit dem Zustandsspeicher (Amazon ElastiCache) interagiert. Dapr bietet eine konsistente API zum Speichern und Abrufen von Zustandsdaten, indem es die Komplexitäten der Verwaltung und Skalierung des zugrunde liegenden Zustandsspeichers abstrahiert. Diese Abstraktion ermöglicht es Entwicklern, zustandsbehaftete Anwendungen zu erstellen, ohne sich um die Feinheiten der Zustandsspeicherverwaltung kümmern zu müssen.
Der Amazon EKS-Cluster hostet einen Namespace namens dapr-system, der die Dapr-Steuerungskomponenten enthält. Der dapr-sidecar-injector fügt automatisch eine Dapr-Runtime in die Pods von Dapr-aktivierten Mikroservices ein.
Schritte für den Dienstaufruf
- Der Bestellgenerierungsdienst (Python-App) ruft die Methode der Node-App,
/neworder, auf. Diese Anfrage wird an den lokalen Dapr-Sidecar gesendet, der im selben Pod wie die Python-App läuft. - Dapr löst die Ziel-App mithilfe des DNS-Anbieters des Amazon EKS-Clusters auf und sendet die Anfrage an den Sidecar der Node-App.
- Der Sidecar der Node-App sendet dann die Anfrage an den Mikroservice der Node-App.
- Die Node-App schreibt dann die vom Python-App erhaltenen Bestell-ID in Amazon ElasticCache.
- Die Node-App sendet die Antwort an ihren lokalen Dapr-Sidecar.
- Der Sidecar der Node-App leitet die Antwort an den Dapr-Sidecar der Python-App weiter.
- Der Python-App-Sidecar sendet die Antwort an die Python-App zurück, die die Anfrage an die Methode der Node-App
/newordergestartet hatte.
Bereitstellungsschritte
Erstellen und Bestätigen eines EKS-Clusters
Um einen Amazon EKS (Elastic Kubernetes Service)-Cluster einzurichten, müssen Sie mehrere Schritte befolgen. Hier ist eine allgemeine Übersicht des Prozesses:
Voraussetzungen
- Installieren und Konfigurieren der AWS CLI
- Installieren Sie
eksctl,kubectlund AWS IAM Authenticator
1. Einen EKS-Cluster erstellen. Verwenden Sie eksctl, um mit einem Befehl wie diesem einen grundlegenden Cluster zu erstellen:
eksctl create cluster --name my-cluster --region us-west-2 --node-type t3.medium --nodes 3
2. Kubectl konfigurieren. Aktualisieren Sie Ihre kubeconfig, um eine Verbindung zum neuen Cluster herzustellen:
aws eks update-kubeconfig --name my-cluster --region us-west-2
3. Den Cluster überprüfen. Überprüfen Sie, ob Ihre Knoten bereit sind:
kubectl get nodes
DAPR auf Ihrem EKS-Cluster installieren
1. DAPR-CLI installieren:
wget -q https://raw.githubusercontent.com/dapr/cli/master/install/install.sh -O - | /bin/bash
2. Installation überprüfen:
dapr -h
3. DAPR installieren und validieren:
dapr init -k --dev
dapr status -k
Die Dapr-Komponenten statestore und pubsub werden im Standardnamespace erstellt. Sie können dies mit dem folgenden Befehl überprüfen:
dapr components -k
Amazon ElastiCache als Ihren Dapr StateStore konfigurieren
Erstellen Sie Amazon ElastiCache, um den Zustand für den Microservice zu speichern. In diesem Beispiel verwenden wir ElastiCache Serverless, das schnell einen Cache erstellt, der automatisch skaliert, um den Anforderungen des Anwendungsverkehrs gerecht zu werden, ohne Server verwalten zu müssen.
Konfigurieren Sie die Sicherheitsgruppe des ElastiCache, um Verbindungen von Ihrem EKS-Cluster zuzulassen. Zur Vereinfachung sollte es sich im selben VPC wie Ihr EKS-Cluster befinden. Notieren Sie sich den Cache-Endpunkt, den wir für die nächsten Schritte benötigen.
Ausführen einer Beispielanwendung
1. Klonen Sie das Git-Repo der Beispielanwendung:
git clone https://github.com/dapr/quickstarts.git
2. Erstellen Sie redis-state.yaml und geben Sie einen Amazon ElasticCache-Endpunkt für redisHost an:
apiVersiondapr.io/v1alpha1
kindComponent
metadata
namestatestore
namespacedefault
spec
typestate.redis
versionv1
metadata
nameredisHost
valueredisdaprd-7rr0vd.serverless.use1.cache.amazonaws.com6379
nameenableTLS
valuetrue
Wenden Sie die yaml-Konfiguration für den Zustandsspeicher-Komponenten mit kubectl an.
kubectl apply -f redis-state.yaml
3. Bereitstellen Sie Mikroservices mit dem Sidecar.
Für die Mikroservice-Node-App wechseln Sie zur Datei /quickstarts/tutorials/hello-kubernetes/deploy/node.yaml und Sie werden die unten stehenden Annotationen bemerken. Es informiert die Dapr-Steuerungsebene, einen Sidecar einzufügen und weist auch einer Dapr-Anwendung einen Namen zu.
annotations
dapr.io/enabled"true"
dapr.io/app-id"nodeapp"
dapr.io/app-port"3000"
Fügen Sie eine Annotation service.beta.kubernetes.io/aws-load-balancer-scheme: „internet-facing“ in node.yaml hinzu, um ein AWS ELB zu erstellen.
kindService
apiVersionv1
metadata
namenodeapp
annotations
service.beta.kubernetes.io/aws-load-balancer-scheme"internet-facing"
labels
appnode
spec
selector
appnode
ports
protocolTCP
port80
targetPort3000
typeLoadBalancer
Bereitstellen Sie die Node-App mit kubectl. Wechseln Sie zum Verzeichnis /quickstarts/tutorials/hello-kubernetes/deploy und führen Sie den unten stehenden Befehl aus.
kubectl apply -f node.yaml
Holen Sie sich den AWS NLB, der unter Externe IP im Output des unten stehenden Befehls erscheint.
kubectl get svc nodeapp http://k8s-default-nodeapp-3a173e0d55-f7b14bedf0c4dd8.elb.us-east-1.amazonaws.com
Wechseln Sie zum Verzeichnis /quickstarts/tutorials/hello-kubernetes, das die Datei sample.json enthält, um den unten stehenden Schritt auszuführen.
curl --request POST --data "@sample.json" --header Content-Type:application/json http://k8s-default-nodeapp-3a173e0d55-f14bedff0c4dd8.elb.us-east-1.amazonaws.com/neworder
Sie können das Ergebnis über den Zugriff auf den /order-Endpunkt über den Lastenausgleicher in einem Browser überprüfen.
http://k8s-default-nodeapp-3a173e0d55-f7b14bedff0c4dd8.elb.us-east-1.amazonaws.com/order
Sie werden die Ausgabe als {“OrderId”:“42”}
sehen. Als nächstes implementieren Sie die zweite Microservice-Python-App, die eine Geschäftslogik hat, um jede Sekunde eine neue Bestell-ID zu generieren und die Methode der Node-App /neworder aufzurufen.
Navigieren Sie zum Verzeichnis /quickstarts/tutorials/hello-kubernetes/deploy und führen Sie den folgenden Befehl aus.
kubectl apply -f python.yaml
4. Validierung und Test Ihrer Anwendungsbereitstellung.
Jetzt, da wir beide Microservices bereitgestellt haben. Die Python-App generiert Bestellungen und ruft /neworder auf, wie aus den folgenden Protokollen ersichtlich ist.
kubectl logs --selector=app=python -c daprd --tail=-1
time"2024-03-07T12:43:11.556356346Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
time"2024-03-07T12:43:12.563193147Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
Wir können sehen, dass die Node-App die Anfragen empfängt und in den Status-Speicher Amazon ElasticCache in unserem Beispiel schreibt.
kubectl logs —selector=app=node -c node —tail=-1
Got a new order Order ID: 367
Successfully persisted state for Order ID: 367
Got a new order Order ID: 368
Successfully persisted state for Order ID: 368
Got a new order Order ID: 369
Successfully persisted state for Order ID: 369
Um zu bestätigen, ob die Daten in Amazon ElasticCache gespeichert sind, greifen wir auf den Endpunkt /order unten zu. Es gibt die neueste Bestell-ID zurück, die von der Python-App generiert wurde.
http://k8s-default-nodeapp-3a173e0d55-f7b14beff0c4dd8.elb.us-east-1.amazonaws.com/order
Sie werden eine Ausgabe mit der aktuellsten Bestellung als {“OrderId”:“370”} sehen.
Bereinigung
Führen Sie den folgenden Befehl aus, um die Bereitstellungen der Node-App und der Python-App sowie die Komponente des Status-Speichers zu löschen.
Navigieren Sie zum Verzeichnis /quickstarts/tutorials/hello-kubernetes/deploy, um den folgenden Befehl auszuführen.
kubectl delete -f node.yaml
kubectl delete -f python.yaml
Sie können Ihren EKS-Cluster mit dem Befehl eksctl herunterfahren und Amazon ElastiCache löschen.
Navigieren Sie zu dem Verzeichnis, das die Datei cluster.yaml enthält, die zur Erstellung des Clusters im ersten Schritt verwendet wurde.
eksctl delete cluster -f cluster.yaml
Fazit
Dapr und Amazon EKS bilden eine leistungsstarke Allianz für die Entwicklung von Microservices. Dapr vereinfacht bereichsübergreifende Anliegen, während EKS die Kubernetes-Infrastruktur verwaltet, sodass Entwickler sich auf die Kerngeschäftslogik konzentrieren und die Produktivität steigern können.
Diese Kombination beschleunigt die Erstellung von skalierbaren, resilienten und beobachtbaren Anwendungen und reduziert erheblich den operativen Aufwand. Es ist eine ideale Grundlage für Ihre Microservices-Reise. Achten Sie auf kommende Beiträge, die die Fähigkeiten von Dapr und EKS in Bezug auf verteiltes Tracing und Observability erkunden, um tiefere Einblicke und Best Practices zu bieten.
Source:
https://dzone.com/articles/streamline-microservices-development-with-dapr-amazon-eks