













Los microservicios y los contenedores están revolucionando la forma en que se construyen, implementan y gestionan las aplicaciones modernas en la nube. Sin embargo, desarrollar y operar microservicios puede introducir una complejidad significativa, a menudo requiriendo que los desarrolladores pasen tiempo valioso en preocupaciones transversales como el descubrimiento de servicios, la gestión de estados y la observabilidad.
Dapr, o Distributed Application Runtime, es un tiempo de ejecución de código abierto para construir microservicios en entornos de nube y borde. Proporciona bloques de construcción independientes de la plataforma como el descubrimiento de servicios, la gestión de estados, la mensajería pub/sub y la observabilidad listos para usar. Dapr ha alcanzado el nivel de madurez graduado de CNCF (Cloud Native Computing Foundation) y actualmente es utilizado por muchas empresas.
Al combinarse con Amazon Elastic Kubernetes Service (Amazon EKS), un servicio de Kubernetes administrado de AWS, Dapr puede acelerar la adopción de microservicios y contenedores, permitiendo a los desarrolladores centrarse en escribir la lógica empresarial sin preocuparse por la infraestructura subyacente. Amazon EKS facilita la gestión de los clústeres de Kubernetes, permitiendo escalar sin esfuerzo a medida que cambian las cargas de trabajo.
En esta publicación de blog, exploraremos cómo Dapr simplifica el desarrollo de microservicios en Amazon EKS. Comenzaremos sumergiéndonos en dos bloques de construcción esenciales: invocación de servicios y gestión de estados .
Invocación de Servicios
La comunicación fluida y confiable entre microservicios es crucial. Sin embargo, los desarrolladores a menudo luchan con tareas complejas como el descubrimiento de servicios, la estandarización de APIs, la seguridad de los canales de comunicación, el manejo de fallos de manera elegante e implementar observabilidad.
Con la invocación de servicios de Dapr, estos problemas se convierten en cosa del pasado. Sus servicios pueden comunicarse fácilmente entre sí utilizando protocolos estándar de la industria como gRPC y HTTP/HTTPS. La invocación de servicios se encarga de toda la carga pesada, desde el registro y descubrimiento de servicios hasta los reintentos de solicitud, cifrado, control de acceso y trazabilidad distribuida.
Gestión del Estado
El bloque de construcción de gestión de estado de Dapr simplifica la forma en que los desarrolladores trabajan con el estado en sus aplicaciones. Proporciona una API consistente para almacenar y recuperar datos de estado, independientemente del almacén de estado subyacente (por ejemplo, Redis, AWS DynamoDB, Azure Cosmos DB).
Esta abstracción permite a los desarrolladores construir aplicaciones con estado sin preocuparse por las complejidades de gestionar y escalar almacenes de estado.
Prerrequisitos
Para seguir esta publicación, debes tener lo siguiente:
- Una cuenta de AWS. Si no tienes una, puedes registrarte para obtener una.
- Un usuario de IAM con permisos adecuados. El principal de seguridad de IAM que estás utilizando debe tener permiso para trabajar con roles de IAM de Amazon EKS, roles vinculados al servicio, AWS CloudFormation, una VPC y recursos relacionados. Para más información, consulta Acciones, recursos y claves de condición para Amazon Elastic Container Service para Kubernetes y Uso de roles vinculados al servicio en la Guía del usuario de AWS Identity and Access Management.
Arquitectura de la aplicación
En el diagrama a continuación, tenemos dos microservicios: una aplicación de Python y una aplicación de Node.js. La aplicación de Python genera datos de pedidos e invoca el endpoint /neworder expuesto por la aplicación de Node.js. La aplicación de Node.js escribe los datos de pedido entrantes en un almacén de estado (en este caso, Amazon ElastiCache) y devuelve un ID de pedido a la aplicación de Python como respuesta.
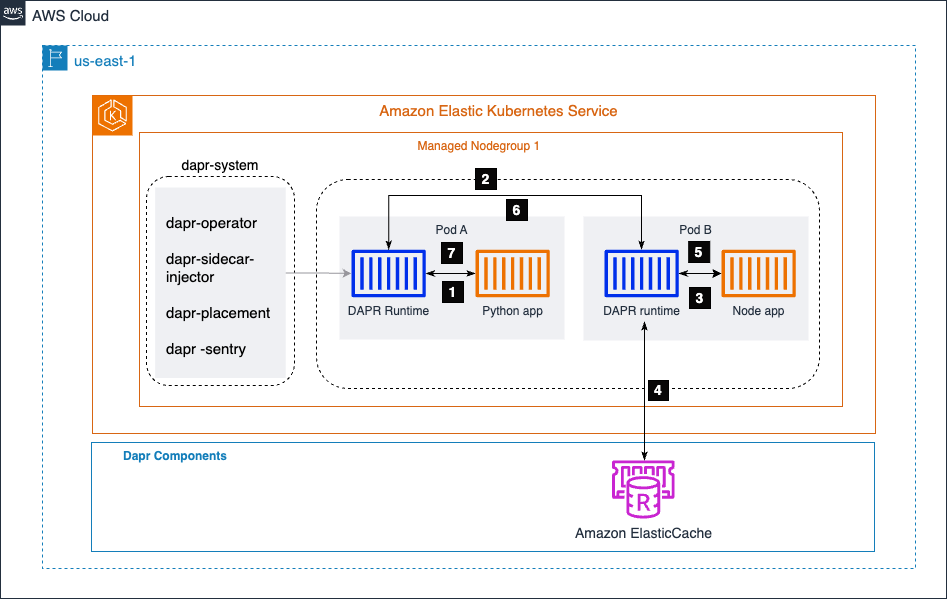
Al aprovechar el bloque de construcción de invocación de servicio de Dapr, la aplicación de Python puede comunicarse sin problemas con la aplicación de Node.js sin preocuparse por el descubrimiento de servicios, la estandarización de la API, la seguridad del canal de comunicación, el manejo de fallos o la observabilidad. Implementa mTLS para proporcionar comunicación segura de servicio a servicio.
Dapr maneja estas preocupaciones transversales, permitiendo a los desarrolladores centrarse en escribir la lógica empresarial central.
Además, el bloque de construcción de gestión de estado de Dapr simplifica cómo interactúa la aplicación Node.js con la tienda de estado (Amazon ElastiCache). Dapr proporciona una API consistente para almacenar y recuperar datos de estado, abstrayendo las complejidades de gestionar y escalar la tienda de estado subyacente. Esta abstracción permite a los desarrolladores construir aplicaciones con estado sin preocuparse por las complejidades de la gestión de la tienda de estado.
El clúster de Amazon EKS aloja un espacio de nombres llamado dapr-system, que contiene los componentes del plano de control de Dapr. El dapr-sidecar-injector inyecta automáticamente un tiempo de ejecución de Dapr en las cápsulas de los microservicios habilitados para Dapr.
Pasos de Invocación de Servicio
- El servicio generador de pedidos (aplicación Python) invoca el método de la aplicación Node,
/neworder. Esta solicitud se envía al sidecar de Dapr local, que se está ejecutando en la misma cápsula que la aplicación Python. - Dapr resuelve la aplicación objetivo utilizando el proveedor de DNS del clúster de Amazon EKS y envía la solicitud al sidecar de la aplicación Node.
- El sidecar de la aplicación Node luego envía la solicitud al microservicio de la aplicación Node.
- La aplicación Node luego escribe el ID del pedido recibido de la aplicación Python en Amazon ElasticCache.
- La aplicación Node envía la respuesta a su sidecar de Dapr local.
- El sidecar de la aplicación Node reenvía la respuesta al sidecar de Dapr de la aplicación Python.
- El sidecar de la aplicación Python devuelve la respuesta a la aplicación Python, que había iniciado la solicitud al método
/neworderde la aplicación Node.
Pasos de Implementación
Crear y confirmar un clúster de EKS
Para configurar un clúster de Amazon EKS (Elastic Kubernetes Service), deberás seguir varios pasos. Aquí tienes una descripción general del proceso:
Requisitos previos
- Instalar y configurar AWS CLI
- Instalar
eksctl,kubectly AWS IAM Authenticator
1. Crear un clúster de EKS. Usa eksctl para crear un clúster básico con un comando como:
eksctl create cluster --name my-cluster --region us-west-2 --node-type t3.medium --nodes 3
2. Configurar kubectl. Actualiza tu kubeconfig para conectarte al nuevo clúster:
aws eks update-kubeconfig --name my-cluster --region us-west-2
3. Verificar el clúster. Verifica si tus nodos están listos:
kubectl get nodes
Instalar DAPR en tu clúster de EKS
1. Instalar DAPR CLI:
wget -q https://raw.githubusercontent.com/dapr/cli/master/install/install.sh -O - | /bin/bash
2. Verificar la instalación:
dapr -h
3. Instalar DAPR y validar:
dapr init -k --dev
dapr status -k
Los componentes de Dapr statestore y pubsub se crean en el espacio de nombres predeterminado. Puedes verificarlo usando el siguiente comando:
dapr components -k
Configurar Amazon ElastiCache como tu Dapr StateStore
Crea Amazon ElastiCache para almacenar el estado del microservicio. En este ejemplo, estamos utilizando ElastiCache serverless, que crea rápidamente una caché que escala automáticamente para satisfacer las demandas de tráfico de la aplicación sin necesidad de servidores que gestionar.
Configure el grupo de seguridad de ElastiCache para permitir conexiones desde su clúster EKS. Por simplicidad, manténgalo en la misma VPC que su clúster EKS. Tome nota del punto de conexión de la caché, que necesitaremos para los pasos siguientes.
Ejecutando una Aplicación de Ejemplo
1. Clona el repositorio Git de la aplicación de ejemplo:
git clone https://github.com/dapr/quickstarts.git
2. Crea redis-state.yaml y proporciona un punto de conexión de Amazon ElasticCache para redisHost:
apiVersiondapr.io/v1alpha1
kindComponent
metadata
namestatestore
namespacedefault
spec
typestate.redis
versionv1
metadata
nameredisHost
valueredisdaprd-7rr0vd.serverless.use1.cache.amazonaws.com6379
nameenableTLS
valuetrue
Aplica la configuración yaml para el componente de almacenamiento de estado utilizando kubectl.
kubectl apply -f redis-state.yaml
3. Implementa microservicios con el sidecar.
Para la aplicación de nodo de microservicio, navega hasta el archivo /quickstarts/tutorials/hello-kubernetes/deploy/node.yaml y notarás las siguientes anotaciones. Indica al plano de control de Dapr que inyecte un sidecar y también asigna un nombre a la aplicación de Dapr.
annotations
dapr.io/enabled"true"
dapr.io/app-id"nodeapp"
dapr.io/app-port"3000"
Agrega una anotación service.beta.kubernetes.io/aws-load-balancer-scheme: “internet-facing” en node.yaml para crear un AWS ELB.
kindService
apiVersionv1
metadata
namenodeapp
annotations
service.beta.kubernetes.io/aws-load-balancer-scheme"internet-facing"
labels
appnode
spec
selector
appnode
ports
protocolTCP
port80
targetPort3000
typeLoadBalancer
Implementa la aplicación de nodo utilizando kubectl. Navega al directorio /quickstarts/tutorials/hello-kubernetes/deploy y ejecuta el siguiente comando.
kubectl apply -f node.yaml
Obtén el AWS NLB, que aparece bajo IP Externa, en la salida del siguiente comando.
kubectl get svc nodeapp http://k8s-default-nodeapp-3a173e0d55-f7b14bedf0c4dd8.elb.us-east-1.amazonaws.com
Navega al directorio /quickstarts/tutorials/hello-kubernetes, que tiene el archivo sample.json para ejecutar el siguiente paso.
curl --request POST --data "@sample.json" --header Content-Type:application/json http://k8s-default-nodeapp-3a173e0d55-f14bedff0c4dd8.elb.us-east-1.amazonaws.com/neworder
Puedes verificar la salida accediendo al endpoint /order utilizando el balanceador de carga en un navegador.
http://k8s-default-nodeapp-3a173e0d55-f7b14bedff0c4dd8.elb.us-east-1.amazonaws.com/order
Verá la salida como {“OrderId”:“42”}
A continuación, implemente la segunda aplicación de microservicio Python, que tiene una lógica empresarial para generar un nuevo ID de orden cada segundo e invocar el método de la aplicación Node /neworder.
Navegue hasta el directorio /quickstarts/tutorials/hello-kubernetes/deploy y ejecute el siguiente comando.
kubectl apply -f python.yaml
4. Validación y prueba de implementación de su aplicación.
Ahora que tenemos ambos microservicios implementados. La aplicación Python está generando órdenes e invocando /neworder como se evidencia en los registros a continuación.
kubectl logs --selector=app=python -c daprd --tail=-1
time"2024-03-07T12:43:11.556356346Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
time"2024-03-07T12:43:12.563193147Z" levelinfo msg"HTTP API Called" app_idpythonapp instancepythonapp974db9877dljtw method"POST /neworder" scopedapr.runtime.httpinfo typelog useragentpythonrequests2.31.0 ver1.12.5
Podemos ver que la aplicación Node está recibiendo las solicitudes y escribiendo en la tienda de estado Amazon ElasticCache en nuestro ejemplo.
kubectl logs —selector=app=node -c node —tail=-1
Got a new order Order ID: 367
Successfully persisted state for Order ID: 367
Got a new order Order ID: 368
Successfully persisted state for Order ID: 368
Got a new order Order ID: 369
Successfully persisted state for Order ID: 369
Para confirmar si los datos están persistidos en Amazon ElasticCache, accedemos al punto final /order a continuación. Devuelve el ID de orden más reciente, que fue generado por la aplicación Python.
http://k8s-default-nodeapp-3a173e0d55-f7b14beff0c4dd8.elb.us-east-1.amazonaws.com/order
Verá una salida con la orden más reciente como {“OrderId”:“370”}.
Limpieza
Ejecute el siguiente comando para eliminar las implementaciones de la aplicación Node y la aplicación Python junto con el componente de la tienda de estado.
Navegue hasta el directorio /quickstarts/tutorials/hello-kubernetes/deploy para ejecutar el siguiente comando.
kubectl delete -f node.yaml
kubectl delete -f python.yaml
Puede desmontar su clúster EKS utilizando el comando eksctl y eliminar Amazon ElastiCache.
Navegue al directorio que tiene el archivo cluster.yaml utilizado para crear el clúster en el primer paso.
eksctl delete cluster -f cluster.yaml
Conclusión
Dapr y Amazon EKS forman una poderosa alianza para el desarrollo de microservicios. Dapr simplifica las preocupaciones transversales, mientras que EKS gestiona la infraestructura de Kubernetes, permitiendo a los desarrolladores centrarse en la lógica empresarial principal y aumentar la productividad.
Esta combinación acelera la creación de aplicaciones escalables, resilientes y observables, reduciendo significativamente la sobrecarga operativa. Es una base ideal para tu viaje con microservicios. Estén atentos a próximas publicaciones que explorarán las capacidades de Dapr y EKS en el rastreo distribuido y observabilidad, ofreciendo una visión más profunda y las mejores prácticas.
Source:
https://dzone.com/articles/streamline-microservices-development-with-dapr-amazon-eks