













Grafana Loki es un sistema de agregación de registros altamente disponible y escalable horizontalmente. Está diseñado para ser simple y rentable. Creado por Grafana Labs en 2018, Loki ha surgido rápidamente como una alternativa atractiva a los sistemas de registro tradicionales, especialmente para entornos nativos de la nube y Kubernetes.
Loki puede proporcionar un viaje de registro integral. Podemos seleccionar los flujos de registro adecuados y luego filtrar para centrarnos en los registros relevantes. Luego podemos analizar datos de registro estructurados para que se ajusten a nuestras necesidades de análisis personalizadas. Los registros también pueden transformarse adecuadamente para su presentación, por ejemplo, o para un procesamiento adicional en la canalización.
Loki se integra perfectamente con el amplio ecosistema de Grafana. Los usuarios pueden consultar registros utilizando LogQL, un lenguaje de consulta diseñado intencionalmente para que se asemeje a Prometheus PromQL. Esto proporciona una experiencia familiar para los usuarios que ya trabajan con métricas de Prometheus y permite una poderosa correlación entre métricas y registros dentro de los paneles de Grafana.
Este artículo comienza con los fundamentos de Loki, seguido de una visión arquitectónica básica. Luego se presentan los conceptos básicos de LogQL, y concluimos con los compromisos involucrados.
Fundamentos de Loki
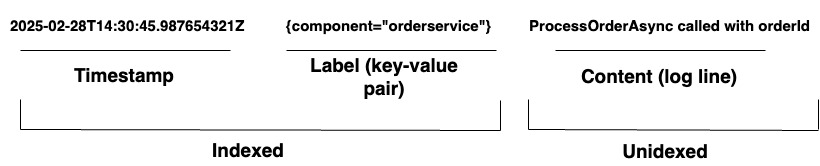
Para las organizaciones que gestionan sistemas complejos, Loki proporciona una solución unificada de registro. Admite la ingestión de registros desde cualquier origen a través de una amplia variedad de agentes o su API, garantizando una cobertura completa de hardware y software diversos. Loki almacena sus registros como flujos de registro, como se muestra en el Diagrama 1. Cada entrada tiene lo siguiente:
- Un marca de tiempo con precisión en nanosegundos
- Pares clave-valor llamados etiquetas se utilizan para buscar registros. Las etiquetas proporcionan los metadatos para la línea de registro. Se utilizan para la identificación y recuperación de datos. Forman el índice para los flujos de registro y estructuran el almacenamiento de registros. Cada combinación única de etiquetas y sus valores define un flujo de registro distinto. Las entradas de registro dentro de un flujo se agrupan, comprimen y almacenan en segmentos.
- El contenido de registro real. Esta es la línea de registro en bruto. No está indexada y se almacena en fragmentos comprimidos.
Arquitectura
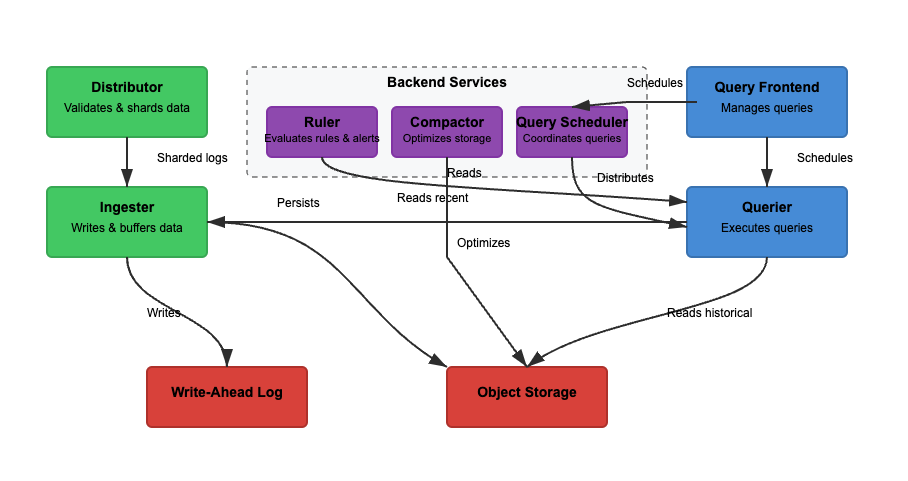
Vamos a analizar la arquitectura de Loki basándonos en tres características básicas. Lectura, escritura y almacenamiento de registros. Loki puede operar en modo monolítico (binario único) o modo de microservicios, donde los componentes se separan para escalar de forma independiente. La funcionalidad de lectura y escritura se puede escalar de forma independiente para adaptarse a casos de uso específicos. Consideremos cada camino con más detalle.
Escritura
En el Diagrama 2, la ruta de escritura es la ruta verde. A medida que los registros entran en Loki, el distribuidor divide los registros según las etiquetas. El ingestor luego almacena los registros en memoria, y el compactador optimiza el almacenamiento. Los pasos principales involucrados son los siguientes.
Paso 1: Los registros entran en Loki
Las escrituras de los registros entrantes llegan al distribuidor. Los registros se estructuran como flujos, con etiquetas (como {job="nginx", level="error"}). El distribuidor divide los registros, particiona los registros y envía los registros a los ingestors. Hashea las etiquetas de cada flujo y lo asigna a un ingestor utilizando hashing consistente. Los distribuidores validan los registros y previenen datos mal formados. El hashing consistente puede garantizar una distribución uniforme de registros entre los ingestors.
Paso 2: Almacenamiento a Corto Plazo
El ingestor almacena los registros en memoria para una recuperación rápida. Los registros se agrupan y se escriben en Registros de Escritura Adelantada (WAL) para prevenir la pérdida de datos. El WAL ayuda con la durabilidad, pero no es consultable directamente: los ingestors aún necesitan estar en línea para consultar registros recientes.
Periódicamente, los registros se vacían de los ingestors al almacenamiento de objetos. El consultor y el gobernante leen del ingestor para acceder a los datos más recientes. El consultor también puede acceder a los datos del almacenamiento de objetos.
Paso 3: Los registros se mueven al Almacenamiento a Largo Plazo
El compactador procesa periódicamente registros almacenados en almacenamiento a largo plazo (object-storage). El almacenamiento de objetos es económico y escalable. Permite a Loki almacenar grandes cantidades de registros sin altos costos. El compactador elimina registros redundantes, comprime registros para una eficiencia de almacenamiento y elimina registros antiguos según la configuración de retención. Los registros se almacenan en formato segmentado (sin indexación de texto completo).
Lectura
En el Diagrama 2, la ruta de lectura es la ruta azul. Las consultas van al frontend de consultas, y el interrogador recupera los registros. Los registros son filtrados, analizados y analizados utilizando LogQL. Los principales pasos involucrados son los siguientes.
Paso 1: El Frontend de Consultas Optimiza las Solicitudes
Los usuarios consultan registros utilizando LogQL en Grafana. El frontend de consultas divide las consultas grandes en fragmentos más pequeños y los distribuye entre varios interrogadores, ya que la ejecución paralela acelera las consultas. Es responsable de acelerar la ejecución de la consulta y garantizar reintentos en caso de falla. El frontend de consultas ayuda a evitar tiempos de espera y sobrecargas, mientras que las consultas fallidas se vuelven a intentar automáticamente.
Paso 2: El Interrogador Recupera Registros
Los interrogadores analizan el LogQL y consultan a los ingesters y almacenamiento de objetos. Los registros recientes se recuperan de los ingesters, y los registros más antiguos se obtienen del almacenamiento de objetos. Los registros con el mismo sello temporal, etiquetas y contenido se deduplican.
Se utilizan filtros de Bloom y etiquetas de índice para encontrar registros eficientemente. Las consultas de agregación, como count_over_time(), se ejecutan más rápido porque Loki no indexa completamente los registros. A diferencia de Elasticsearch, Loki no indexa todo el contenido del registro.
Por el contrario, indexa etiquetas de metadatos ({app="nginx", level="error"}), lo que ayuda a encontrar registros de forma eficiente y económica. Las búsquedas de texto completo se realizan solo en fragmentos de registro relevantes, reduciendo los costos de almacenamiento.
Conceptos básicos de LogQL
LogQL es el lenguaje de consulta utilizado en Grafana Loki para buscar, filtrar y transformar registros de manera eficiente. Consta de dos componentes principales:
- Selector de flujo – Selecciona flujos de registro basados en coincidencias de etiquetas
- Filtrado y transformación – Extrae líneas de registro relevantes, analiza datos estructurados y formatea los resultados de la consulta
Al combinar estas características, LogQL permite a los usuarios recuperar registros de manera eficiente, extraer información y generar métricas útiles a partir de datos de registro.
Selector de flujo
Un selector de flujo es el primer paso en cada consulta de LogQL. Selecciona flujos de registro basados en coincidencias de etiquetas. Para refinar los resultados de la consulta a flujos de registro específicos, podemos utilizar operadores básicos para filtrar por etiquetas de Loki. Mejorar la precisión de nuestra selección de flujo de registro minimiza el volumen de flujos escaneados, aumentando así la velocidad de la consulta.
Ejemplos
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobFiltros de líneas
Una vez que se seleccionan los registros, los filtros de líneas refinan los resultados buscando texto específico o aplicando condiciones lógicas. Los filtros de líneas funcionan en el contenido del registro, no en las etiquetas.
Ejemplos
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)Analizadores
Loki puede aceptar registros no estructurados, semi-estructurados o estructurados. Sin embargo, entender los formatos de registro con los que estamos trabajando es crucial al diseñar y construir soluciones de observabilidad. De esta manera, podemos ingerir, almacenar y analizar datos de registro para utilizarlos de manera efectiva. Loki admite analizadores JSON, logfmt, patrón, regexp y unpack.
Ejemplos
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesFiltros de etiquetas
Una vez analizados, los registros pueden filtrarse por campos extraídos. Las etiquetas pueden extraerse como parte del pipeline de registro utilizando expresiones de analizadores y formateadores. La expresión del filtro de etiquetas puede luego utilizarse para filtrar nuestra línea de registro con cualquiera de estas etiquetas.
Ejemplos
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminFormato de línea
Se utiliza para modificar la salida de registro extrayendo y formateando campos. Esto formatea cómo se muestran los registros en Grafana.
Ejemplo
{app="nginx"} | json | line_format "User {user} encountered {status} error"Formato de etiqueta
Se utiliza para renombrar, modificar, crear o eliminar etiquetas. Acepta una lista separada por comas de operaciones de igualdad, lo que permite realizar múltiples operaciones simultáneamente.
Ejemplos
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level Compensaciones
Grafana Loki ofrece una solución de registro rentable y escalable que almacena registros en fragmentos comprimidos con un índice mínimo. Esto conlleva compensaciones en el rendimiento de las consultas y la velocidad de recuperación. A diferencia de los sistemas tradicionales de gestión de registros que indexan el contenido completo de los registros, el indexado basado en etiquetas de Loki acelera el filtrado.
Sin embargo, puede ralentizar las búsquedas de texto complejas. Además, aunque Loki destaca en el manejo de entornos distribuidos de alto rendimiento, depende del almacenamiento de objetos para la escalabilidad. Esto puede introducir latencia y requiere una cuidadosa selección de etiquetas para evitar problemas de alta cardinalidad.
Escalabilidad y Multiinquilino
Loki está diseñado para la escalabilidad y el multiinquilino. Sin embargo, la escalabilidad conlleva compensaciones arquitectónicas. Escalar escrituras (ingesters) es sencillo debido a la capacidad de fragmentar registros en función de la partición basada en etiquetas. Escalar lecturas (queriers) es más complicado debido a que la consulta de conjuntos de datos grandes desde el almacenamiento de objetos puede ser lenta. El multiinquilino está soportado, pero la gestión de cuotas específicas para inquilinos, explosión de etiquetas y seguridad (aislamiento de datos por inquilino) requiere una configuración cuidadosa.
Ingestión Simple Sin Preanálisis
Loki no requiere preanálisis porque no indexa el contenido completo de los registros. Almacena los registros en formato crudo en fragmentos comprimidos. Dado que Loki carece de indexación de texto completo, la consulta de registros estructurados (por ejemplo, JSON) requiere análisis LogQL. Esto significa que el rendimiento de las consultas depende de la estructura de los registros antes de la ingestión. Sin registros estructurados, la eficiencia de la consulta se ve afectada porque los filtros deben aplicarse en el momento de la recuperación, no en la ingestión.
Almacenamiento en Almacén de Objetos
Loki vuelca fragmentos de registro en almacenamiento de objetos (por ejemplo, S3, GCS, Azure Blob). Esto reduce la dependencia de almacenamiento de bloques costoso como, por ejemplo, el que requiere Elasticsearch.
Sin embargo, leer registros desde el almacenamiento de objetos puede ser lento en comparación con hacer consultas directamente desde una base de datos. Loki compensa esto manteniendo registros recientes en ingester para una recuperación más rápida. La compactación reduce la sobrecarga de almacenamiento, pero la latencia de recuperación de registros aún puede ser un problema para consultas a gran escala.
Etiquetas y Cardinalidad
Dado que las etiquetas se utilizan para buscar registros, son críticas para consultas eficientes. Un etiquetado deficiente puede provocar problemas de alta cardinalidad. El uso de etiquetas de alta cardinalidad (por ejemplo, user_id, session_id) aumenta el uso de memoria y ralentiza las consultas. Loki hashea las etiquetas para distribuir registros entre los ingesters, por lo que un mal diseño de etiquetas puede causar una distribución desigual de registros.
Filtrado Temprano
Dado que Loki almacena registros sin procesar comprimidos en el almacenamiento de objetos, es importante filtrar temprano si queremos que nuestras consultas sean rápidas. Procesar análisis complejos en conjuntos de datos más pequeños aumentará el tiempo de respuesta. Según esta regla, una buena consulta sería la Consulta 1 y una mala consulta sería la Consulta 2.
Consulta 1
{job="nginx", status_code=~"5.."} | jsonLa Consulta 1 filtra registros donde job="nginx" y el status_code comienza con 5 (errores del 500 al 599). Luego, extrae campos JSON estructurados usando | json. Esto minimiza la cantidad de registros procesados por el analizador JSON, haciéndolo más rápido.
Consulta 2
{job="nginx"} | json | status_code=~"5.."La Consulta 2 primero recupera todos los registros de nginx. Esto podría ser millones de entradas. Luego analiza JSON para cada registro antes de filtrar por status_code. Esto es ineficiente y considerablemente más lento.
Finalizando
Grafana Loki es un poderoso y rentable sistema de agregación de registros diseñado para la escalabilidad y la simplicidad. Al indexar solo metadatos, mantiene bajos los costos de almacenamiento mientras permite consultas rápidas utilizando LogQL.
Su arquitectura de microservicios admite implementaciones flexibles, lo que lo hace ideal para entornos nativos de la nube. Este artículo abordó los conceptos básicos de Loki y su lenguaje de consultas. Al navegar a través de las características destacadas de la arquitectura de Loki, podemos obtener una mejor comprensión de las compensaciones involucradas.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture