













Al haber utilizado Amazon Aurora durante un tiempo en varias empresas, he visto de primera mano cómo destaca como un motor de base de datos relacional completamente gestionado, ofreciendo alto rendimiento, escalabilidad y fiabilidad.
Como una solución nativa de la nube que soporta MySQL y PostgreSQL, Aurora es una excelente elección para empresas que requieren alta disponibilidad y escalado automático. Debido a que AWS gestiona automáticamente las copias de seguridad, el failover y la replicación, utilizar Aurora te permite aumentar la eficiencia de la base de datos mientras reduces los costos de mantenimiento.
En este tutorial, te guiaré a través de la configuración de una instancia de Aurora, su gestión eficiente, optimización del rendimiento, y garantizar la seguridad y la rentabilidad.
¿Qué es AWS Aurora?
Amazon Aurora es una base de datos relacional basada en la nube que supera a MySQL y PostgreSQL tradicionales al escalar dinámicamente los recursos de almacenamiento y cómputo.
Según AWS, Aurora puede ofrecer hasta cinco veces más rendimiento que MySQL estándar y tres veces más rendimiento que PostgreSQL estándar, debido a su arquitectura distribuida y altamente disponible.
Aurora está equipado con funciones como copias de seguridad automáticas, réplicas de lectura para escalamiento horizontal y mecanismos de conmutación por error que garantizan tiempos de inactividad mínimos.
La capa de almacenamiento de Aurora está diseñada para ser tolerante a fallos y auto-reparable.
Además, los datos se replican automáticamente en múltiples Zonas de Disponibilidad (AZs) para garantizar la durabilidad.
La imagen a continuación proporciona una visión general de la arquitectura y características clave de Amazon Aurora.
La relación entre el volumen del clúster, la instancia de base de datos escritora y las instancias de base de datos lectoras en un clúster de Aurora. Source: Documentos de AWS
El motor de base de datos monitorea continuamente las consultas y optimiza los planes de ejecución, lo que conduce a mejoras significativas en la eficiencia.
Uno de los beneficios clave de Aurora es su compatibilidad con las bases de datos existentes de MySQL y PostgreSQL, lo que facilita a las empresas migrar sin necesidad de modificar extensamente sus aplicaciones.
La estructura de costos de Aurora también es atractiva. Cobra en función del uso real de los recursos de cómputo y almacenamiento. Este modelo de costos elimina la necesidad de sobreaprovisionar infraestructura, lo cual a su vez ahorra dinero.
> Si estás interesado en tener una comprensión más amplia de las opciones de almacenamiento de AWS, echa un vistazo a este Tutorial de Almacenamiento de AWS.
Configuración de AWS Aurora
Configurar AWS Aurora implica crear un clúster de base de datos, configurar los ajustes de seguridad y garantizar un acceso adecuado a la red. ¡Hagámoslo en esta sección!
> Si eres nuevo en AWS, considera revisar temas fundamentales con el curso de Introducción a AWS antes de sumergirte en Aurora.
Creando un clúster de base de datos Aurora
Configurar un clúster de base de datos Aurora requiere algunos pasos clave, incluyendo seleccionar el motor de base de datos apropiado, configurar los ajustes de seguridad y definir las especificaciones de la instancia.
- Para comenzar, inicia sesión en la Consola de Administración de AWS y navega hasta el panel de control de RDS (Servicio de Base de Datos Relacional).
- Puedes hacer esto buscando “Aurora” en el panel de búsqueda de la Consola de Administración de AWS, como se muestra en la imagen a continuación.
- Una vez allí, haz clic en “Crear base de datos” – como se muestra en la imagen a continuación.
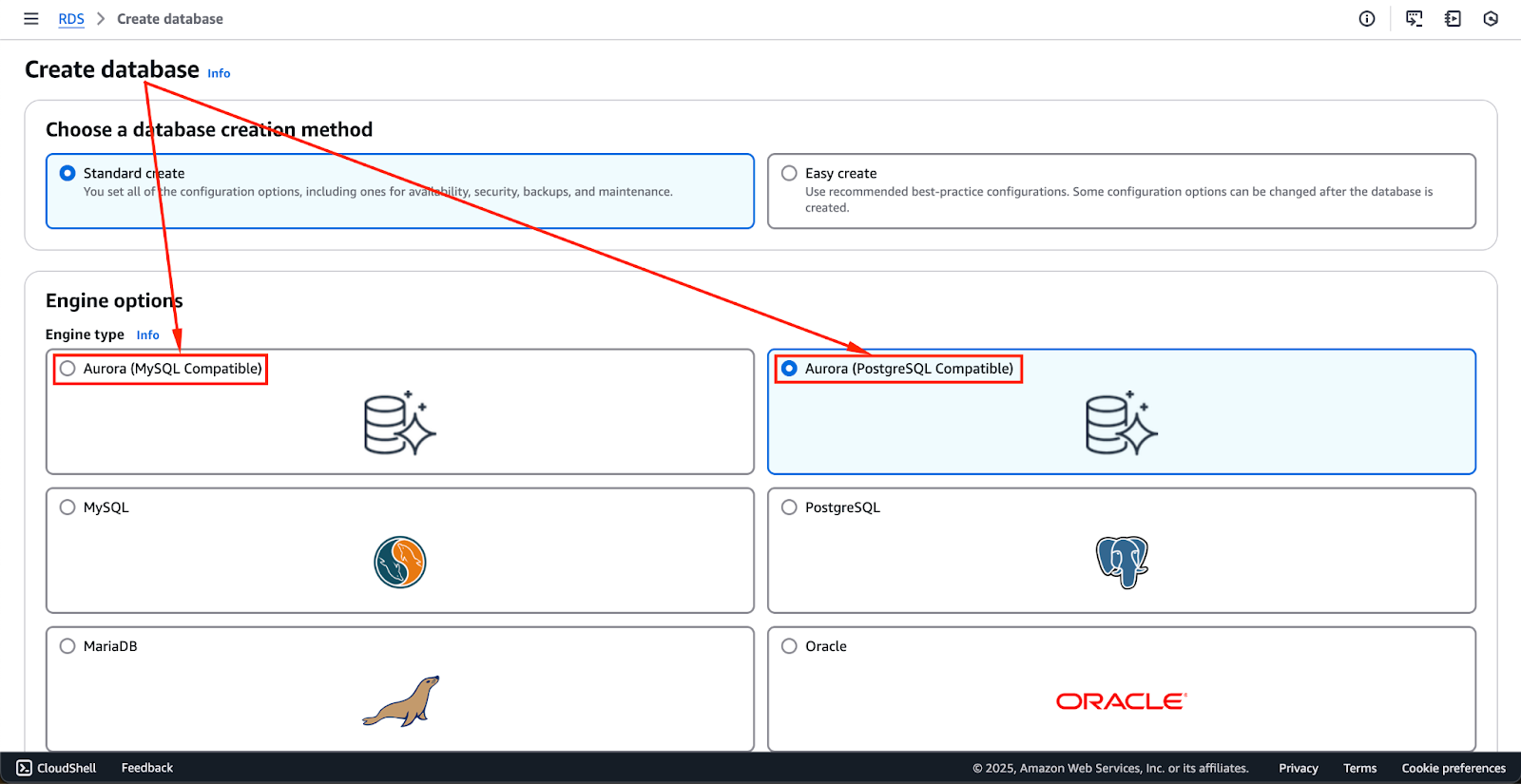
- Luego tendrás la opción de elegir “Amazon Aurora” como motor de base de datos.
- Recuerda que Aurora admite tanto MySQL como PostgreSQL, por lo que es importante seleccionar la versión que mejor se adapte a los requisitos de tu aplicación.
La imagen a continuación muestra las opciones de motor que están actualmente disponibles. Estas podrían cambiar en el futuro, pero las dos primeras opciones—Aurora (Compatible con MySQL) y Aurora (Compatible con PostgreSQL)—son los motores de Aurora.
- Después de seleccionar el motor, debes especificar el tipo de instancia y las configuraciones de almacenamiento.
- Aurora proporciona la flexibilidad de escalar automáticamente el almacenamiento hasta 128TB, asegurando que las cargas de trabajo en crecimiento se manejen de manera eficiente sin requerir intervención manual.
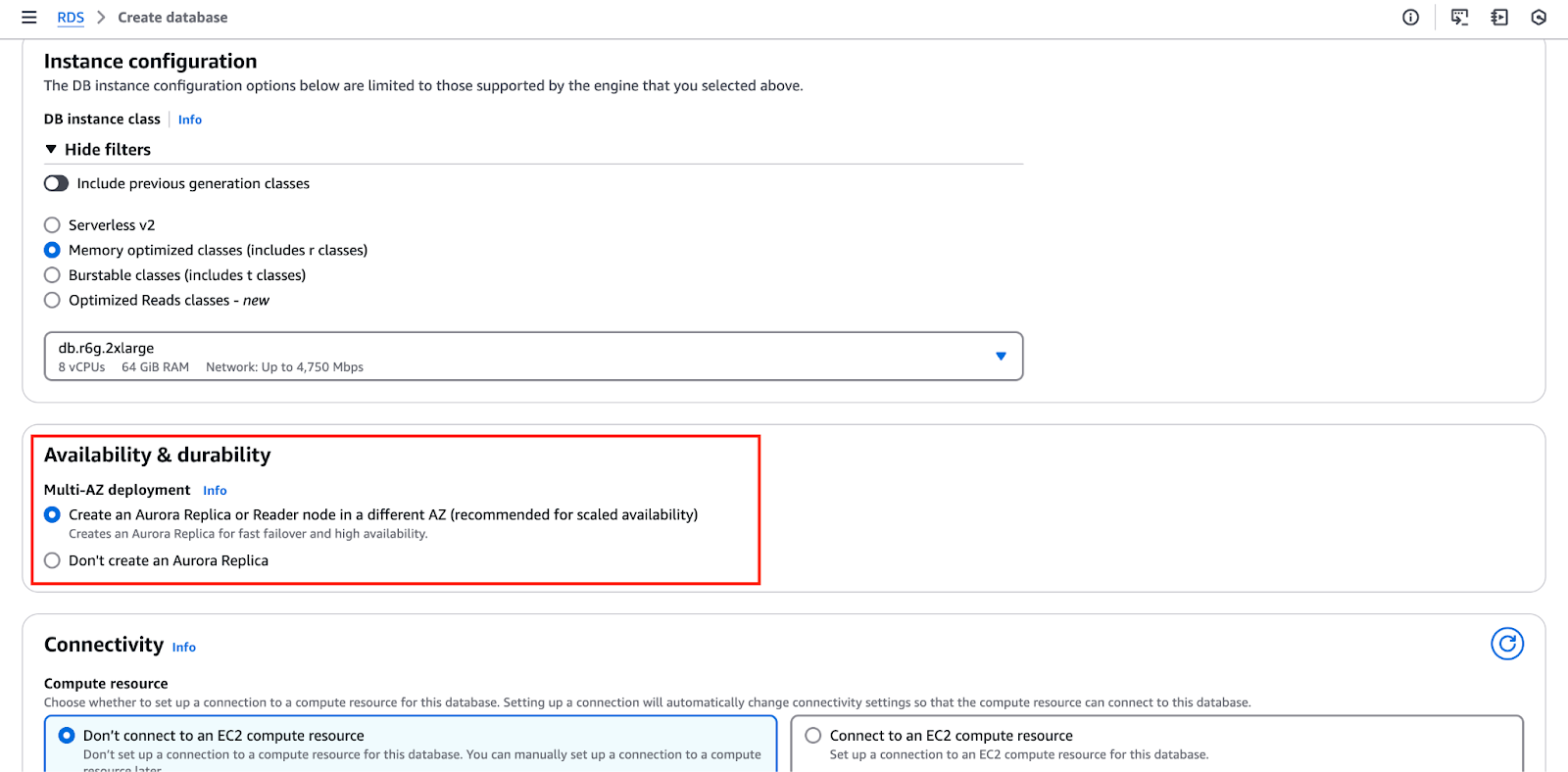
- El siguiente paso es definir la configuración de replicación. Puedes optar por un despliegue de instancia única o habilitar réplicas de lectura para distribuir el tráfico de la base de datos de manera más efectiva.
- Usar réplicas de lectura también mejora la disponibilidad y la tolerancia a fallos, lo que asegura una mayor durabilidad en caso de fallos.
La imagen a continuación resalta la“Disponibilidad y durabilidad” sección, donde puedes configurar estos ajustes.
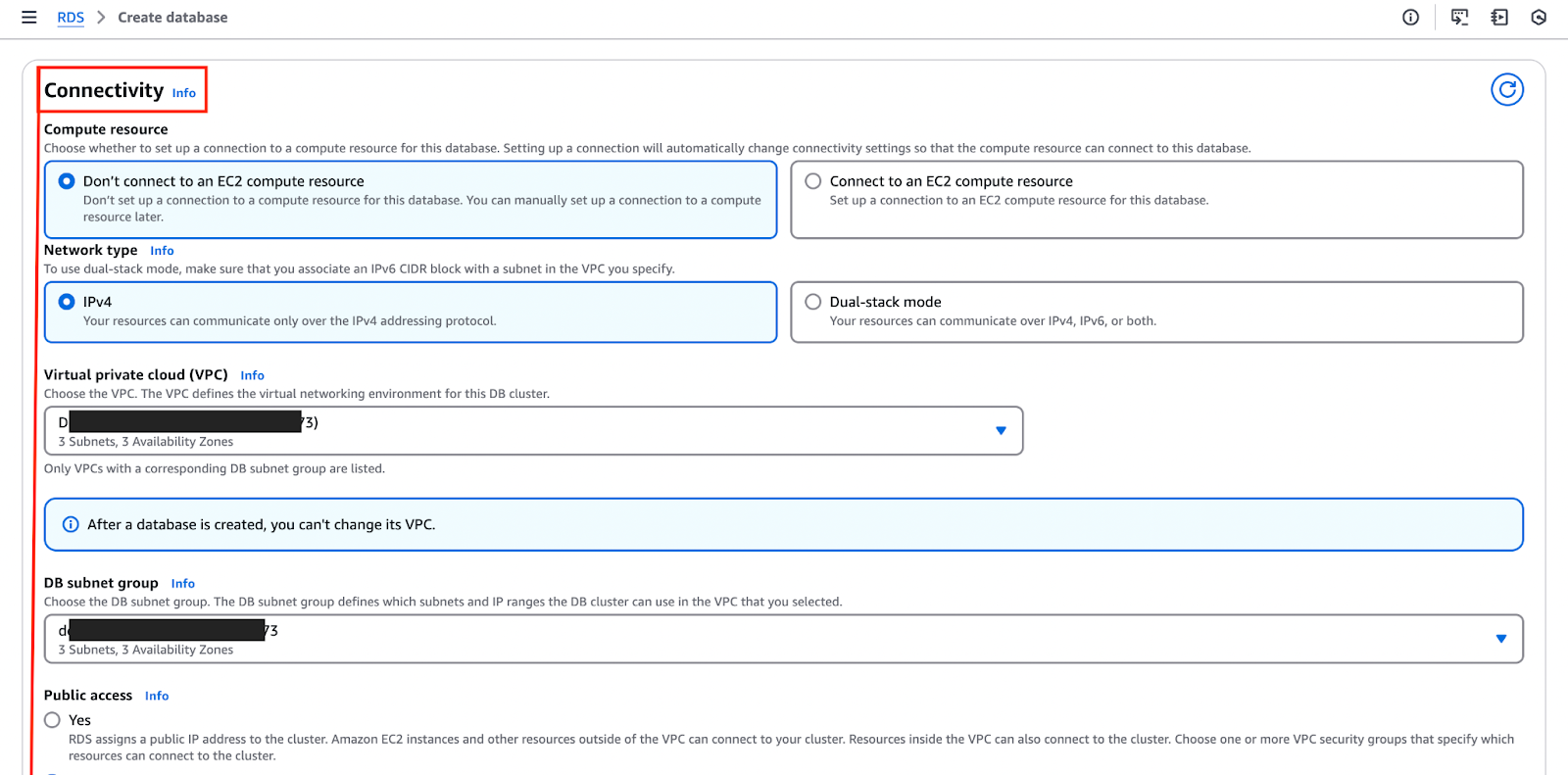
- La etapa de configuración de red es crucial, ya que implica configurar la Nube Privada Virtual (VPC), seleccionar un grupo de seguridad y definir los controles de acceso.
- Un grupo de seguridad actúa como un firewall que regula el tráfico de base de datos entrante y saliente. Para mejorar la seguridad, se recomienda que solo se permita el acceso desde direcciones IP y aplicaciones de confianza.
La imagen a continuación destaca la sección “Conectividad”, donde puedes configurar y personalizar estas configuraciones.
- Las credenciales de la base de datos también deben configurarse durante la instalación, donde asignas un nombre de usuario principal y una contraseña que se utilizarán para autenticar las conexiones.
- Aurora permite habilitar copias de seguridad automáticas y opciones de recuperación punto en el tiempo. Esto asegura que se creen instantáneas de la base de datos de manera consistente para prevenir la pérdida de datos.
Después de revisar todas las configuraciones, puedes proceder con la creación del clúster de Aurora. La imagen a continuación muestra el botón “Crear base de datos” que puedes hacer clic para iniciar el proceso de creación.
El proceso de aprovisionamiento puede tardar varios minutos, dependiendo del tamaño de instancia seleccionado y de la configuración de red.
> Si eres nuevo en los servicios de AWS, revisar el curso de tecnología y servicios en la nube de AWS puede ayudarte a entender los conceptos clave de AWS relevantes para la configuración de Aurora.Configurar la red y la seguridad puede ayudarte a comprender los conceptos clave de AWS relevantes para la configuración de Aurora.
Configuración de red y seguridad
La seguridad es fundamental para gestionar una base de datos de Aurora, y AWS proporciona múltiples herramientas para aplicar controles de acceso sólidos.
- El primer paso para asegurar una instancia de Aurora es configurar los grupos de seguridad de VPC. Estos grupos de seguridad determinan qué direcciones IP y servicios pueden interactuar con la base de datos.
- Debes limitar el acceso a servidores de aplicaciones específicos y administradores para evitar conexiones no autorizadas.
- Identity and Access Management (IAM) de AWS también se puede utilizar para definir permisos detallados para operaciones de base de datos.
- La integración de roles de IAM te permite adaptar el acceso a la base de datos de acuerdo a los roles y responsabilidades específicos del usuario.
- Por ejemplo, a los desarrolladores de aplicaciones solo se les puede conceder acceso de lectura, mientras que los administradores tendrán control total sobre las modificaciones de la base de datos.
- La encriptación también debe estar habilitada para proteger los datos sensibles. AWS Aurora admite encriptación en reposo y en tránsito utilizando el Servicio de Gestión de Claves de AWS (KMS).
- Encriptar datos en reposo asegura que, incluso si los medios de almacenamiento se ven comprometidos, los datos sigan siendo inaccesibles sin la clave de desencriptación adecuada.
- De manera similar, habilitar la encriptación de Capa de Sockets Seguros (SSL) para datos en tránsito previene la interceptación no autorizada de las comunicaciones de la base de datos.
> Para una inmersión más profunda en la seguridad de los entornos de AWS, echa un vistazo al curso de Seguridad y Gestión de Costos de AWS. Si deseas aprender más sobre cómo funciona IAM y cómo implementarlo de manera efectiva, consulta esta guía sobre la Gestión de Identidad y Acceso de AWS (IAM).
Conexión a AWS Aurora
Conectarse a AWS Aurora es esencial para interactuar con la base de datos. Puedes hacerlo a través de herramientas de cliente o aplicaciones. ¡Veamos cómo en esta sección!
Conexión a Aurora MySQL
Una vez que la base de datos Aurora está en funcionamiento, necesitas establecer una conexión para comenzar a interactuar con la base de datos.
Para Aurora MySQL, se pueden utilizar clientes de base de datos comunes como MySQL Workbench y HeidiSQL para conectarse. Alternativamente, se puede usar interfaces de línea de comandos.
La conexión requiere especificar el punto final de la base de datos, que se puede encontrar en la Consola de administración de AWS.
Usando la CLI de MySQL, la conexión se puede establecer con el siguiente comando:
mysql -h your-cluster-endpoint -u admin -p
Después de ingresar la contraseña principal, deberías poder ejecutar consultas SQL, crear tablas y gestionar datos.
Conectando a Aurora PostgreSQL
Para Aurora PostgreSQL, puedes conectarte utilizando herramientas como pgAdmin o la interfaz de línea de comandos de PostgreSQL (psql).
El comando de conexión en psql sigue este formato:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
Al igual que con MySQL, se deben ingresar las credenciales correctas para acceder a la base de datos.
Una vez que hayas obtenido acceso, deberías poder ejecutar consultas SQL, crear tablas y gestionar datos.
Configurando la conectividad de la aplicación
Las aplicaciones que necesitan interactuar con Aurora deben configurarse con cadenas de conexión a la base de datos apropiadas. Por lo general, estas cadenas de conexión consisten en el nombre de usuario, la contraseña, el número de puerto y el punto de conexión.
Se recomienda utilizar agrupamiento de conexiones para optimizar el rendimiento y reducir el costo de establecer nuevas conexiones para cada solicitud.
Bibliotecas populares como SQLAlchemy para Python o JDBC para Java proporcionan maneras eficientes de gestionar conexiones en un entorno de aplicación.
Gestión de AWS Aurora
Gestionar eficazmente AWS Aurora implica asegurar la protección de datos, monitorear el rendimiento y escalar recursos según sea necesario. En esta sección, revisaremos estas prácticas.
Copias de seguridad y instantáneas
AWS Aurora ofrece copias de seguridad automatizadas que capturan y almacenan continuamente los cambios de la base de datos en Amazon S3. Estas copias de seguridad se conservan según la configuración definida por el usuario, lo que permite la restauración a cualquier punto dentro del período de retención.
Además de las copias de seguridad automatizadas, también puedes crear instantáneas manuales que persisten más allá de la ventana de retención. Las instantáneas manuales son particularmente útiles para el archivo a largo plazo o antes de realizar actualizaciones importantes en la base de datos.
Cuando trabajé en un proyecto con una aplicación crítica, programamos copias de seguridad automatizadas cada dos horas. Sin embargo, antes de realizar cualquier cambio o actualización en la aplicación, creábamos manualmente una copia de seguridad para asegurarnos de que pudiéramos revertir si era necesario. Esto demuestra cómo se pueden utilizar eficazmente juntas las copias de seguridad automatizadas y manuales.
La imagen a continuación muestra cómo AWS Backup puede ser utilizado para la recuperación ante desastres con Amazon Aurora.
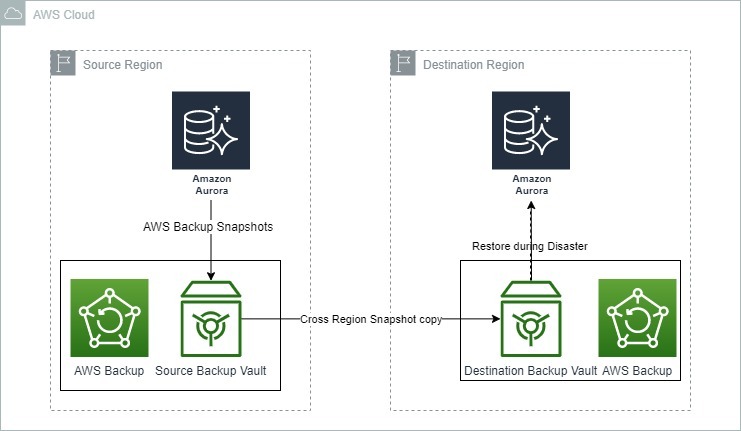
Opciones de respaldo y recuperación para Amazon Aurora. Fuente: Blogs de AWS
Monitoreo de Aurora con CloudWatch
El monitoreo del rendimiento es esencial para mantener una base de datos saludable.
AWS CloudWatch proporciona métricas en tiempo real que rastrean la utilización de CPU, el uso de memoria, el I/O de disco y el tráfico de red.
Configurar alarmas de CloudWatch puede ayudar a los administradores a ser notificados cuando se superan los umbrales de rendimiento, permitiendo una gestión proactiva de la base de datos.
Además de esto, AWS Performance Insights ofrece análisis detallados de consultas para identificar y optimizar consultas que se ejecutan lentamente.
La imagen a continuación demuestra cómo AWS Performance Insights proporciona información sobre el rendimiento de la base de datos.
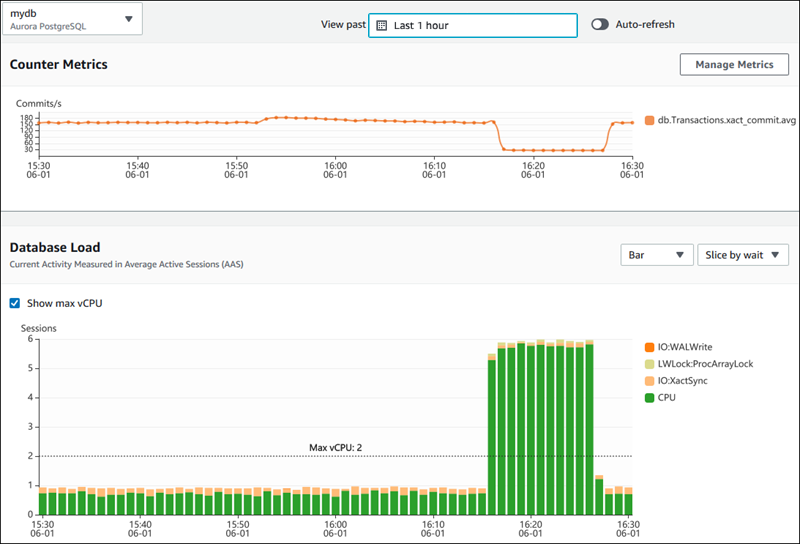
Tablero de AWS Performance Insights que muestra métricas de rendimiento de la base de datos. Fuente: Documentos de AWS
Escalando Aurora
Aurora está diseñado para escalar automáticamente ajustando la capacidad de almacenamiento según sea necesario. Sin embargo, los recursos de cómputo, como CPUs y memoria, pueden necesitar ser ajustados manualmente dependiendo de la carga de trabajo.
Aurora ofrece opciones para escalar la capacidad de lectura añadiendo réplicas de lectura, que distribuyen el tráfico de lectura y mejoran el rendimiento.
Cuando la alta disponibilidad es crítica, un clúster de Aurora se puede configurar con múltiples réplicas en diferentes Zonas de Disponibilidad para garantizar la redundancia en caso de fallo.
Optimización del rendimiento en AWS Aurora
Optimizar el rendimiento en Amazon Aurora asegura una ejecución eficiente de consultas y escalabilidad. Vamos a repasar algunas mejores prácticas en esta sección.
Indexación y optimización de consultas
Optimizar el rendimiento de las consultas en Amazon Aurora es crucial para mantener una base de datos de alto rendimiento.
- La indexación es una de las formas más efectivas de reducir el tiempo de ejecución de consultas y mejorar la eficiencia de la base de datos.
- Crear índices en columnas consultadas con frecuencia puede ayudar a localizar datos rápidamente, minimizando la necesidad de escaneos completos de la tabla.
- Deberías utilizar estratégicamente índices primarios y secundarios para alinearte con los patrones de consulta y las demandas de carga de trabajo.
- Además de lo anterior, puedes emplear índices compuestos para consultas que involucren múltiples columnas para mejorar aún más los tiempos de búsqueda.
- La optimización de consultas también juega un papel significativo en el rendimiento de la base de datos. Escribir consultas SQL eficientes asegura que Aurora procese las solicitudes más rápido con un consumo mínimo de recursos.
- Usar
EXPLAIN o EXPLAIN ANALYZEen consultas SQL ayuda a identificar cuellos de botella y proporciona información sobre los planes de ejecución. - Técnicas como evitar
SELECT *(que recupera datos innecesarios), normalizar el esquema de la base de datos para reducir la redundancia y aprovechar estrategias de particionamiento pueden llevar a ganancias en el rendimiento. - El optimizador de planes de consulta de Aurora refina continuamente los planes de ejecución, realizando ajustes en función de los patrones de carga de trabajo de la base de datos, mejorando así la eficiencia general.
Usar réplicas de lectura de Aurora
Para manejar cargas de tráfico alto, Amazon Aurora admite réplicas de lectura que ayudan a distribuir consultas intensivas en lectura entre múltiples instancias.
Las réplicas de lectura reducen la carga en la instancia de base de datos principal procesando las solicitudes de lectura por separado, lo que mejora la capacidad de respuesta y reduce la latencia.
Para configurar una réplica de lectura de Aurora, deberás seleccionar un clúster de Aurora existente y habilitar la replicación con una configuración mínima. Aurora sincroniza automáticamente los datos entre la instancia principal y sus réplicas, garantizando la consistencia de los datos sin intervención manual.
El mecanismo de replicación de Aurora es altamente eficiente, permitiendo una sincronización de datos casi en tiempo real con un retraso de replicación de menos de un segundo.
Las aplicaciones que realizan operaciones de lectura frecuentes, como paneles de informes o servicios de análisis, pueden beneficiarse significativamente de las réplicas de lectura al dirigir consultas pesadas de lectura a estas instancias.
En caso de falla de la instancia primaria, una réplica de lectura puede ser promovida para convertirse en la nueva instancia primaria con un tiempo de inactividad mínimo, asegurando alta disponibilidad y continuidad del negocio.
La imagen a continuación muestra cómo las réplicas de Aurora entre regiones pueden ayudar con la recuperación ante desastres y la alta disponibilidad.
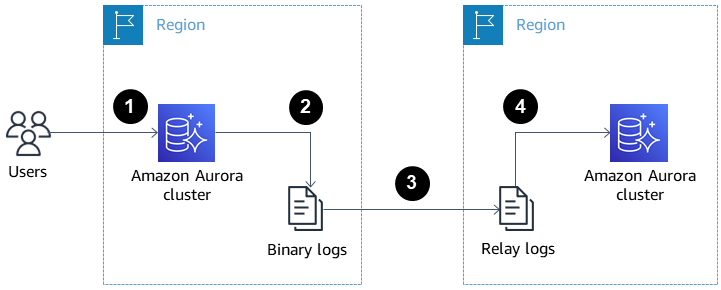
Réplicas de lectura de Aurora entre regiones para recuperación ante desastres y alta disponibilidad. Fuente: AWS Docs
Estrategias de cacheo para Aurora
El cacheo es una técnica poderosa para mejorar el rendimiento de la base de datos al reducir las cargas de consultas directas en Aurora. Una capa de cacheo puede acelerar significativamente la recuperación de datos para consultas de acceso frecuente.
Amazon ElastiCache, que admite Redis y Memcached, se usa comúnmente junto con Aurora para almacenar resultados de consultas y evitar consultas redundantes a la base de datos.
Integrar el almacenamiento en caché en la arquitectura de una aplicación puede ayudar a mejorar los tiempos de respuesta mientras se preservan los recursos informáticos de la base de datos.
Estrategias de almacenamiento en caché como el almacenamiento en caché de escritura a través (donde los datos se escriben tanto en la caché como en Aurora simultáneamente) y la carga diferida (donde los datos solo se almacenan en caché cuando se solicitan) ayudan a optimizar el rendimiento según los patrones de uso.
Configurar un tiempo de vida útil (TTL) apropiado para los datos almacenados en caché asegura que la caché se mantenga fresca y evita la recuperación de datos obsoletos.
Seguridad y Cumplimiento en AWS Aurora
Asegurar tu base de datos de Aurora es crucial para proteger datos sensibles y garantizar el cumplimiento normativo. Revisemos las mejores prácticas en esta sección.
Encriptación de datos
La seguridad de los datos es fundamental para la gestión de bases de datos, y AWS Aurora proporciona mecanismos de encriptación sólidos para proteger datos sensibles.
- Aurora encripta datos en reposo utilizando el Servicio de Gestión de Claves (KMS) de AWS, lo que garantiza que la información almacenada permanezca segura incluso si el almacenamiento subyacente se ve comprometido.
- Al habilitar el cifrado durante la creación de la base de datos, se asegura de que todas las copias de seguridad automatizadas, instantáneas y réplicas hereden la misma configuración de cifrado.
- Para datos en tránsito, Aurora admite cifrado SSL/TLS, que asegura las conexiones de la base de datos y previene el acceso no autorizado o la interceptación de transmisiones de datos.
- Las aplicaciones que se conectan a Aurora deben configurarse para utilizar certificados SSL para mantener la comunicación segura.
Estas medidas de cifrado pueden ayudarte a cumplir con las mejores prácticas de seguridad y los requisitos normativos.
La imagen a continuación demuestra cómo AWS KMS se integra con Amazon Aurora para cifrar tu base de datos.
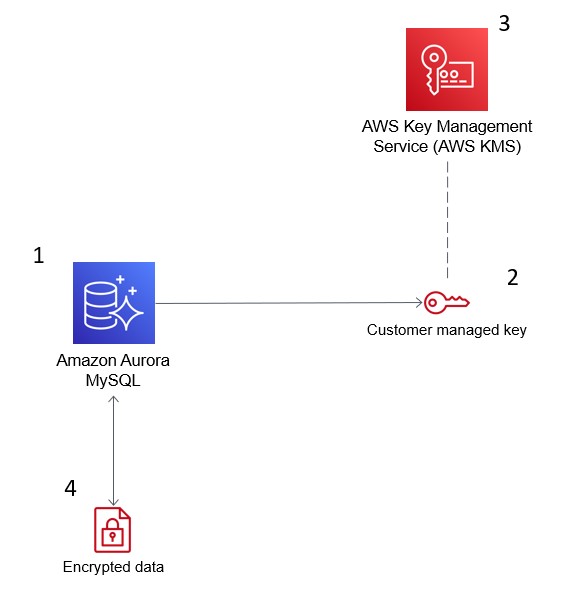
El Servicio de Gestión de Claves de AWS (KMS) cifra datos en Amazon Aurora para cumplir con los requisitos de seguridad. Fuente: Blogs de AWS
Integración de IAM para control de acceso
El control de acceso en Aurora se gestiona a través de AWS IAM, que permite a los administradores definir permisos granulares basados en los roles de usuario.
- Las políticas de IAM se pueden utilizar para restringir el acceso a las instancias de base de datos, evitando que usuarios no autorizados realicen operaciones críticas como modificaciones de datos o tareas administrativas.
- La autenticación IAM proporciona una alternativa más segura a la autenticación basada en contraseñas tradicionales. Permite que las aplicaciones se conecten usando credenciales de seguridad temporales. Esto elimina la necesidad de almacenar y administrar contraseñas de bases de datos, reduciendo el riesgo de exposición de credenciales.
Deberías hacer cumplir los principios de acceso de menor privilegio, que minimizan los riesgos de seguridad y mantienen un estricto control sobre el acceso a la base de datos.
La imagen a continuación muestra cómo se puede configurar la autenticación IAM para asegurar el acceso a la base de datos Amazon Aurora PostgreSQL.
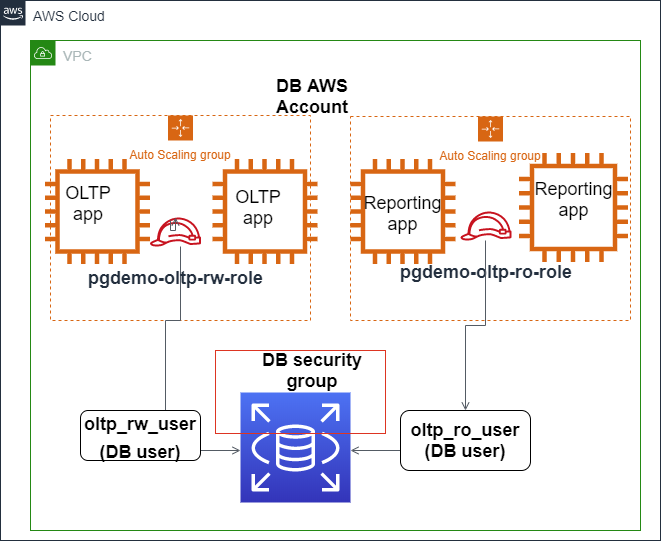
La autenticación IAM se integra con Amazon Aurora PostgreSQL. Fuente: Blogs de AWS
Auditoría con los registros de Aurora
Monitorear y auditar la actividad de la base de datos es esencial para el cumplimiento de la seguridad y la solución de problemas.
Aurora proporciona varios mecanismos de registro, incluidos registros de errores, registros de consultas lentas y registros generales, que ayudan a los administradores a rastrear la actividad de la base de datos e identificar posibles problemas. Estos registros se pueden habilitar a través de la Consola de Administración de AWS y almacenarse en Amazon CloudWatch para un análisis centralizado.
- Registros de errores capturan errores y advertencias del motor de la base de datos.
- Los registros de consultas lentas ayudan a identificar consultas ineficientes que pueden afectar el rendimiento.
Analizar estos registros puede ayudar a los administradores a optimizar la ejecución de consultas, detectar intentos de acceso no autorizados y garantizar la estabilidad de la base de datos.
Administración de costos y optimización en AWS Aurora
Para gestionar y optimizar de manera efectiva los costos en Amazon Aurora, es necesario comprender su estructura de precios. ¡Veámoslo juntos!
Comprensión de la estructura de precios de Aurora
El modelo de precios de Amazon Aurora se basa en varios factores, incluidas las horas de instancia, el consumo de almacenamiento, las solicitudes de E/S y la transferencia de datos.
A diferencia de las bases de datos tradicionales que requieren aprovisionamiento de infraestructura por adelantado, el modelo de pago por uso de Aurora permite a las empresas pagar solo por los recursos que consumen.
Las instancias de cómputo se facturan en función de la clase de instancia y el tiempo de actividad, mientras que el almacenamiento se ajusta dinámicamente, eliminando la necesidad de ajustes manuales.
La imagen a continuación proporciona un desglose de los diferentes componentes de precios para Amazon Aurora. Sin embargo, ten en cuenta que los precios pueden cambiar, por lo que siempre es mejor consultar la página de precios de Aurora para obtener la información más actualizada.
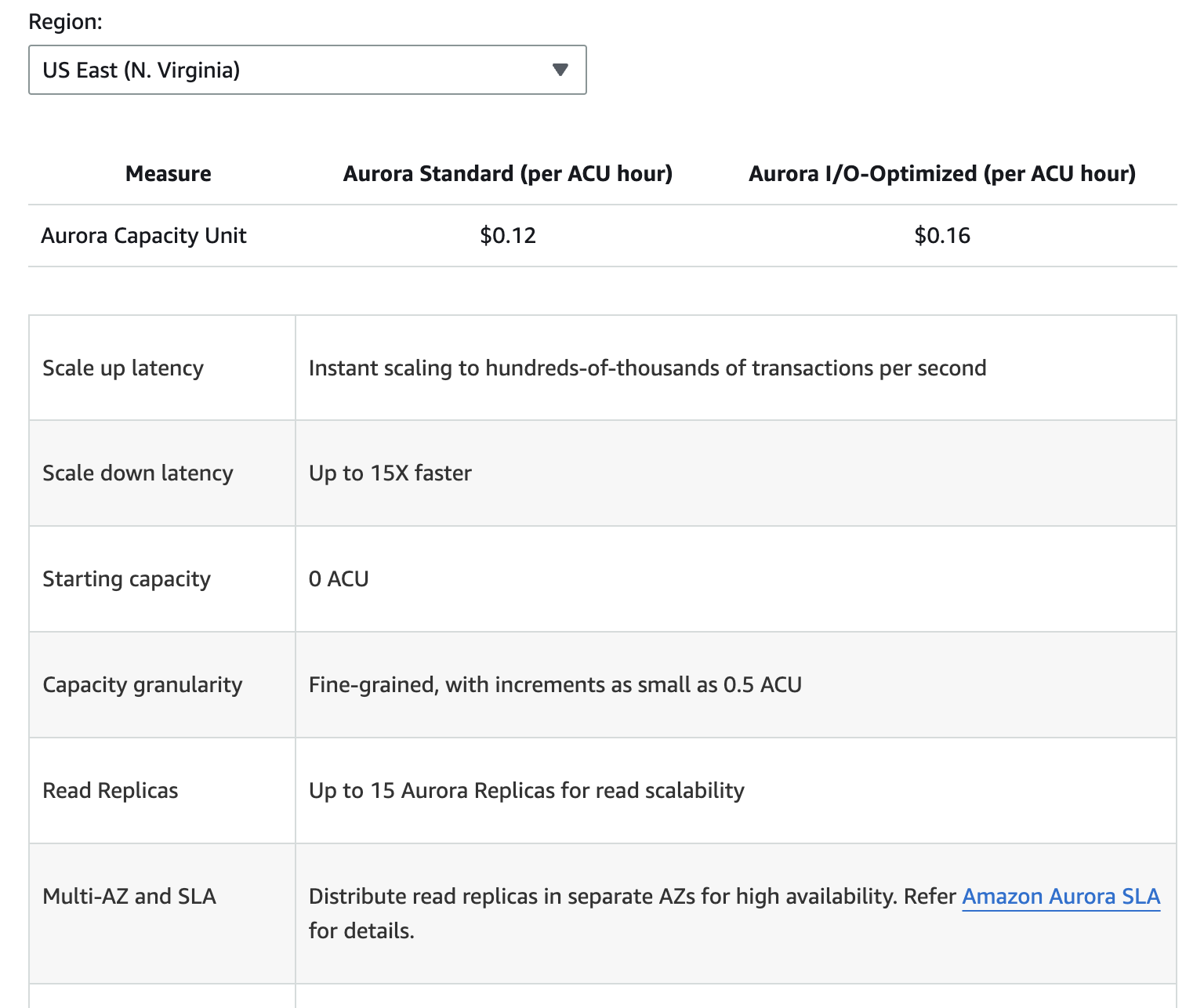
Los costos adicionales incluyen el almacenamiento de copias de seguridad más allá del nivel gratuito asignado, solicitudes de E/S de lectura y escritura, y tarifas de transferencia de datos para la replicación entre regiones.
Comprender estos componentes de precios puede ayudarte a prever gastos y tomar decisiones informadas sobre el uso de la base de datos.
Optimizando costos con Aurora
Para gestionar los costos de manera efectiva, las organizaciones pueden implementar varias estrategias de optimización.
Seleccionar el tamaño de instancia adecuado garantizará que los recursos de la base de datos se alineen con las demandas de carga de trabajo sin sobreaprovisionamiento.
- Si tienes una carga de trabajo predecible, utiliza Instancias Reservadas ya que ofrecen ahorros significativos en comparación con la tarificación bajo demanda.
- Técnicas de optimización de almacenamiento, como el monitoreo de recursos no utilizados o infrautilizados, ayudan a reducir costos.
- La función de escalado automático de Aurora ajusta el almacenamiento de manera dinámica, previniendo gastos innecesarios en almacenamiento.
- Además, la implementación de replicas de lectura puede aliviar las consultas en la instancia principal, reduciendo potencialmente la necesidad de instancias de mayor nivel.
- Aproveche Aurora Serverless, ya que es otra opción rentable para aplicaciones con cargas de trabajo variables. Aurora Serverless escala automáticamente los recursos informáticos según la demanda, lo que garantiza que las empresas solo paguen por el uso real en lugar de mantener una instancia en funcionamiento continuo.
> Si deseas obtener más información sobre la gestión de costos, consulta el curso Seguridad y Gestión de Costos de AWS.
Conclusión
Después de trabajar con Amazon Aurora en varias empresas durante bastante tiempo, puedo decir con confianza que es una solución de base de datos poderosa y escalable que facilita la gestión sin comprometer el rendimiento; probablemente estarás de acuerdo después de pasar por este tutorial.
Aurora merece ser considerada si estás buscando una base de datos relacional nativa de la nube que soporte MySQL y PostgreSQL mientras reduce la sobrecarga operativa. Ha sido revolucionaria en algunos de mis proyectos, y recomiendo encarecidamente explorar sus capacidades si estás trabajando con bases de datos de AWS.
Si eres nuevo en las bases de datos de AWS, aprender conceptos fundamentales a través de cursos como AWS Cloud Practitioner (CLF-C02) puede ser beneficioso!