













El 11 de diciembre de 2024, los servicios de OpenAI experimentaron una caída significativa debido a un problema derivado de la implementación de un nuevo servicio de telemetría. Este incidente afectó a los servicios de API, ChatGPT y Sora, lo que resultó en interrupciones del servicio que duraron varias horas. Como empresa que tiene como objetivo proporcionar soluciones de IA precisas y eficientes, OpenAI ha compartido un informe detallado post-mortem para discutir de manera transparente lo que salió mal y cómo planean prevenir situaciones similares en el futuro.
En este artículo, describiré los aspectos técnicos del incidente, desglosaré las causas raíz y exploraré las lecciones clave que los desarrolladores y las organizaciones que gestionan sistemas distribuidos pueden aprender de este evento.
Cronología del Incidente
Aquí hay un resumen de cómo se desarrollaron los eventos el 11 de diciembre de 2024:
| Time (PST) | Event |
|---|---|
| 3:16 PM |
Comenzaron los impactos menores en los clientes; se observó degradación del servicio |
| 3:27 PM | Los ingenieros comenzaron a redirigir el tráfico de los clústeres afectados |
| 3:40 PM | Se registró el máximo impacto en los clientes; se produjeron cortes importantes en todos los servicios |
| 4:36 PM | El primer clúster de Kubernetes comenzó a recuperarse |
| 5:36 PM | Comenzó la recuperación sustancial de los servicios de API |
| 5:45 PM | Se observó una recuperación sustancial en ChatGPT |
| 7:38 PM | Todos los servicios se recuperaron por completo en todos los clústeres. |
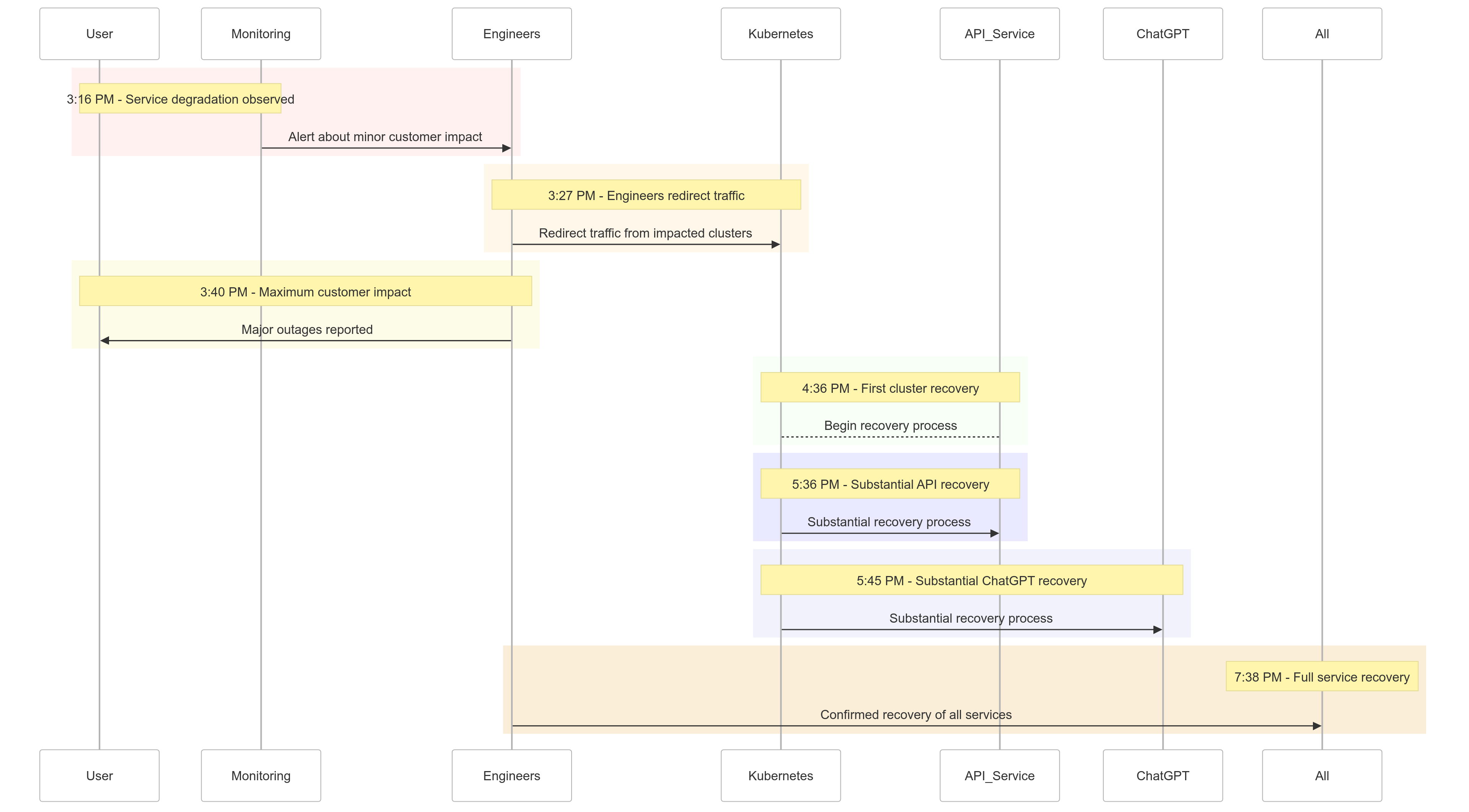
Figura 1: Cronología del Incidente de OpenAI – Degradación del Servicio a Recuperación Completa.
Análisis de la Causa Raíz
La raíz del incidente se encontraba en un nuevo servicio de telemetría desplegado a las 3:12 PM PST para mejorar la observabilidad de los planos de control de Kubernetes. Este servicio abrumó inadvertidamente a los servidores API de Kubernetes en múltiples clústeres, lo que llevó a fallos en cascada.
Desglosándolo
Despliegue del Servicio de Telemetría
El servicio de telemetría fue diseñado para recopilar métricas detalladas del plano de control de Kubernetes, pero su configuración activó accidentalmente operaciones API de Kubernetes que consumen muchos recursos en miles de nodos simultáneamente.
Plano de Control Sobrecargado
El plano de control de Kubernetes, responsable de la administración del clúster, se volvió abrumado. Mientras que el plano de datos (que maneja las solicitudes de los usuarios) permaneció parcialmente funcional, dependía del plano de control para la resolución DNS. A medida que los registros DNS en caché expiraron, los servicios que dependían de la resolución DNS en tiempo real comenzaron a fallar.
Pruebas Insuficientes
El despliegue fue probado en un entorno de preproducción, pero los clústeres de preproducción no reflejaron la escala de los clústeres de producción. Como resultado, el problema de carga del servidor API no fue detectado durante las pruebas.
Cómo se Mitigó el Problema
Cuando comenzó el incidente, los ingenieros de OpenAI identificaron rápidamente la causa raíz, pero enfrentaron desafíos para implementar una solución porque el plano de control de Kubernetes sobrecargado impedía el acceso a los servidores de API. Se adoptó un enfoque multiprongado:
- Reducir el Tamaño del Clúster: Reducir el número de nodos en cada clúster disminuyó la carga en los servidores de API.
- Bloquear el Acceso a la Red a las APIs Administrativas de Kubernetes: Se impidieron solicitudes adicionales a la API, lo que permitió a los servidores recuperarse.
- Aumentar los Servidores de API de Kubernetes: Proveer recursos adicionales ayudó a despejar las solicitudes pendientes.
Estas medidas permitieron a los ingenieros recuperar el acceso a los planos de control y eliminar el servicio de telemetría problemático, restaurando la funcionalidad del servicio.
Lecciones Aprendidas
Este incidente destaca la criticidad de las pruebas robustas, la monitorización y los mecanismos de seguridad en sistemas distribuidos. Esto es lo que OpenAI aprendió (y aplicó) de la interrupción:
1. Implementaciones Faseadas Robustas
Todos los cambios en la infraestructura ahora seguirán implementaciones faseadas con monitoreo continuo. Esto asegura que los problemas se detecten temprano y se mitiguen antes de escalar a toda la flota.
2. Pruebas de Inyección de Fallos
Al simular fallos (por ejemplo, deshabilitar el plano de control o implementar cambios incorrectos), OpenAI verificará que sus sistemas puedan recuperarse automáticamente y detectar problemas antes de afectar a los clientes.
3. Acceso de Emergencia al Plano de Control
Un mecanismo de “romper el cristal” garantizará que los ingenieros puedan acceder a los servidores de la API de Kubernetes incluso bajo una carga pesada.
4. Desacoplar los Planos de Control y Datos
Para reducir dependencias, OpenAI desacoplará el plano de datos de Kubernetes (manejo de cargas de trabajo) del plano de control (responsable de la orquestación), asegurando que los servicios críticos puedan seguir funcionando incluso durante las interrupciones del plano de control.
5. Mecanismos de Recuperación más Rápidos
Nuevas estrategias de almacenamiento en caché y limitación de velocidad mejorarán los tiempos de inicio del clúster, asegurando una recuperación más rápida durante las fallas.
Ejemplo de Código: Ejemplo de Implementación Gradual
Aquí tienes un ejemplo de implementación de una implementación gradual para Kubernetes usando Helm y Prometheus para observabilidad.
Implementación de Helm con implementaciones graduales:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Consulta de Prometheus para monitorear la carga del servidor API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Esta consulta ayuda a rastrear los tiempos de respuesta para las solicitudes del servidor API, asegurando la detección temprana de picos de carga.
Ejemplo de Inyección de Falla
Usando chaos-mesh, OpenAI podría simular interrupciones en el plano de control de Kubernetes.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Esta configuración mata intencionalmente un pod del servidor API para verificar la resistencia del sistema.
Lo que Esto Significa para Ti
Este incidente subraya la importancia de diseñar sistemas resilientes y adoptar metodologías de prueba rigurosas. Ya sea que administres sistemas distribuidos a gran escala o estés implementando Kubernetes para tus cargas de trabajo, aquí hay algunas conclusiones:
- Simula Fallos Regularmente: Utiliza herramientas de ingeniería del caos como Chaos Mesh para probar la robustez del sistema bajo condiciones del mundo real.
- Monitorea en Múltiples Niveles: Asegúrate de que tu pila de observabilidad rastree tanto métricas a nivel de servicio como métricas de salud del clúster.
- Desacopla Dependencias Críticas: Reduce la dependencia de puntos únicos de fallo, como el descubrimiento de servicios basado en DNS.
Conclusión
Aunque ningún sistema es inmune a fallos, incidentes como este nos recuerdan el valor de la transparencia, la rápida remediación y el aprendizaje continuo. El enfoque proactivo de OpenAI para compartir este análisis post-mortem proporciona un esquema para que otras organizaciones mejoren sus prácticas operativas y confiabilidad.
Al priorizar implementaciones robustas por fases, pruebas de inyección de fallos y diseño de sistemas resilientes, OpenAI está dando un fuerte ejemplo de cómo manejar y aprender de interrupciones a gran escala.
Para los equipos que gestionan sistemas distribuidos, este incidente es un gran estudio de caso sobre cómo abordar la gestión de riesgos y minimizar el tiempo de inactividad de los procesos comerciales fundamentales.
Utilicemos esto como una oportunidad para construir juntos sistemas mejores y más resilientes.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident