













Introducción
En ciencia de datos, y especialmente en Procesamiento de Lenguaje Natural, la resumición ha sido y siempre ha sido un tema de gran interés. Aunque los métodos de resumición de texto han existido por algún tiempo, los últimos años han visto desarrollos significativos en procesamiento de lenguaje natural y aprendizaje profundo. Existe un pujamiento de publicaciones en el tema por parte de gigantes de internet, como el reciente ChatGPT. Si bien se está realizando una gran cantidad de trabajo en este tema de estudio, hay muy poco escrito sobre implementaciones prácticas de resumición driven por AI. La dificultad de analizar declaraciones amplias y generalizadas es un obstáculo para la resumición efectiva.
Resumir un artículo de noticias y un informe de ganancias financieras son dos tareas diferentes. Cuando se trata de texturas de texto que varían en longitud o tema (tecnología, deportes, finanzas, viajes, etc.), la resumición se convierte en una tarea de ciencia de datos desafiante. Es fundamental cubrir algunos fundamentos en la teoría de resumir antes de adentrarse en un resumen de aplicaciones.
Resumición Extractiva
El proceso de resumen extractivo implica seleccionar las oraciones más relevantes de un artículo y organizarlas sistemáticamente. Las oraciones que componen el resumen son tomadas literalmente del material de origen.
Los sistemas de resumen extractivo, como los conocemos actualmente, giran en torno a tres operaciones fundamentales:
Construcción de una representación intermedia del texto de entrada
Las representaciones basadas en representación, por ejemplo, incluyen representación de tema e representación de indicador. Para entender los temas mencionados en el texto, la representación de tema convierte el texto en una representación intermedia.
Calificando las oraciones en base a la representación
Al momento de la generación de la representación intermedia, cada oración recibe una puntuación de importancia. Al utilizar un método que depende de la representación de tema, la puntuación de una oración refleja la eficiencia con la que ilustra los conceptos críticos del texto. En representación de indicador, la puntuación se calcula agregando la evidencia de diferentes indicadores ponderados.
Selección de un resumen que comprende varias oraciones
Para generar un resumen, el software de resumen selecciona las k oraciones más importantes. Por ejemplo, algunos métodos utilizan algoritmos voraces para elegir y seleccionar las oraciones más relevantes, mientras que otros pueden transformar la selección de oraciones en un problema de optimización en el que se selecciona un conjunto de oraciones bajo la condición de que debe maximizar la importancia y la coherencia general mientras mínima la información redundante.
Vamos a profundizar un poco más en los métodos que mencionamos:
Enfoques de representación de temas
Palabras de tema: Mediante este método, se pueden encontrar términos relacionados con el tema en un documento de entrada. La importancia de una oración se puede calcular de dos maneras: primero, como una función del número de firmas de tema que incluye; segundo, como una fracción de las firmas de tema que contiene. Mientras que el primer método da puntuaciones más altas a las oraciones más largas con más palabras, el segundo mide la densidad de las palabras de tema.
Enfoques basados en frecuencia: Mediante este método, se le asigna importancia relativa a las palabras. Si la palabra corresponde al tema, obtiene 1 punto; de lo contrario, llega a cero. Dependiendo de cómo se implementen, los pesos pueden ser continuos. Las representaciones de los temas se pueden lograr utilizando una de dos maneras:
Probabilidad de Palabra: Solo toma la frecuencia de una palabra para indicar su importancia. Para calcular la probabilidad de una palabra w, dividimos la frecuencia con la que aparece, f(w), por el número total de palabras, N.
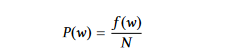
La media de importancia de las palabras en una oración da la importancia de la oración al utilizar probabilidades de palabra.
TFIDF (Termino Frecuencia Inverso Documento Frecuencia): Este método es una mejora sobre el enfoque de probabilidad de palabra. Aquí, los pesos se determinan utilizando el enfoque TF-IDF. La técnica de Termino Frecuencia Inverso Documento Frecuencia (TFIDF) da menos importancia a términos que aparecen frecuentemente en la mayoría de los documentos. El peso de cada palabra w en el documento d se calcula de la siguiente manera:
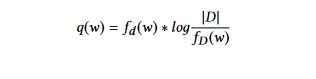
donde fd(w) es la frecuencia del término w en el documento d,
fD(w) es el número de documentos que contienen la palabra w, y |D| es el número de documentos en la colección D.
Análisis Semántico Latente: El análisis semántico latente (LSA) es un método no supervisado para extraer una representación de la semántica del texto basada en palabras observadas. El proceso del LSA comienza con la construcción de una matriz de término-oración (n por m), donde cada fila representa una palabra de entrada (n-palabras) y cada columna representa una oración (m oraciones). En la matriz, el peso de la palabra i en la oración j se define por la entrada aij. De acuerdo con la técnica TFIDF, cada palabra en una oración se le asigna un cierto peso, con cero siendo asignado a términos que no están incluidos en la oración.
Aproximaciones de Representación de Indicador
Métodos basados en grafos
Los métodos gráficos, influenciados por el algoritmo PageRank, representan los documentos como un grafo conectado. Las oraciones forman los vértices del grafo, y las aristas que conectan las oraciones muestran el grado de relación entre dos oraciones. Un método frecuentemente utilizado para enlazar dos vértices es evaluar la similitud entre dos oraciones, y si el grado de similitud es mayor que un cierto umbral, los vértices se conectan. Ambos resultados son posibles con esta representación gráfica. Primero, las particiones del grafo (sub-grafos) definen categorías individuales de información cubiertas por los documentos. El segundo resultado es que las oraciones clave del documento se han destacado. Las oraciones conectadas a muchas otras oraciones en la partición pueden ser el centro del grafo y son más propensas a incluirse en el resumen. Tanto la resumisión de documentos individuales como la de documentos múltiples pueden beneficiarse del uso de técnicas basadas en grafos.
Aprendizaje Automático
Las técnicas de aprendizaje automático consideran el problema de resumir como un reto de clasificación. Los modelos intentan categorizar las oraciones en categorías de resumen y no resumen basadas en sus características. Tenemos un conjunto de entrenamiento constituido por documentos y resumidos humanamente revisados de los cuales entrenar nuestros algoritmos. Normalmente se hace usando Naive Bayes, Árbol de Decisión o Máquina de Soporte Vectorial.
Resumen abstractivo
A diferencia de la resumen extractivo, el resumen abstractivo es un método más efectivo. La capacidad para crear frases únicas que transmiten información vital de las fuentes de texto ha contribuido a este creciente interés.
Un resumen abstractivo presenta el material en una forma lógica, bien organizada y sintácticamente correcta. La calidad de un resumen puede mejorarse significativamente haciéndolo más legible o mejorando su calidad lingüística. (incluir imagen).
Hay dos enfoques: el enfoque basado en estructuras y el enfoque basado en semántica.
ENFOQUE BASADO EN ESTRUCTURAS
En un enfoque basado en estructuras primero, la información más importante del documento (s) se codifica utilizando schemas de características psicológicas como plantillas, reglas de extracción y estructuras alternativas, incluyendo árbol, ontología, cabecera y cuerpo, regla y estructura basada en gráfico. A continuación, leerá acerca de algunos de los varios métodos que se integran en esta estrategia.
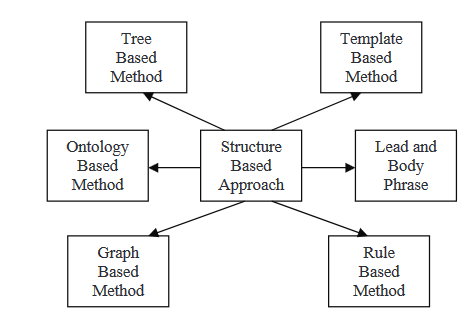
Métodos basados en árboles
En este método, el contenido de un documento se representa como un árbol de dependencias. La selección de contenido para un esquema puede realizarse mediante varias otras técnicas, como un programa de algoritmo de intersección de temas o uno que utiliza alineación nativa intentada a través de oraciones parseadas. Esta aproximación emplea ya sea un generador de lenguaje o un algoritmo asociado para la generación de esquemas. En este documento, los autores ofrecen un método de fusión de oraciones que utiliza alineación local múltiple de secuencias bottom-up para encontrar las frases de información común. Los sistemas de resumen de multigénero utilizan una técnica llamada fusión de oraciones.
En este método, se utiliza un conjunto de documentos como entradas, procesado utilizando un algoritmo de selección de tema para extraer el tema central, y luego se utiliza un algoritmo de agrupamiento para clasificar las frases por importancia. Después de que las oraciones se han organizado, se fusionan utilizando la fusión de oraciones, y se genera un resumen estadístico. El método estructurado codifica la información más importante del documento(s) utilizando esquemas de características psicológicas como plantillas, reglas de extracción y estructuras alternativas como árbol, ontología, cuerpo y cabeza, regla y estructura basada en grafo.
Métodos basados en plantillas
En este método, se utiliza una guía para representar un documento entero. Se comparan patrones lingüísticos o criterios de extracción para identificar fragmentos de texto que se pueden mapear a guías de slots. Estos fragmentos de texto son indicadores de unidades de área de contenido de la estructura de contenido. Este documento propuso dos métodos (resumir un solo documento y resumir multiples documentos) para resumir documentos. Para crear extractos y resúmenes de los documentos, siguieron los métodos descritos en GISTEXTER.
Implementado para la extracción de información, GISTEXTER es un sistema de resumen que identifica información relacionada con el tema en el texto de entrada y la convierte en entradas de base de datos; las oraciones se añaden entonces al resumen dependiendo de las solicitudes del usuario.

Métodos basados en ontología
Muchos investigadores han intentado mejorar la eficacia de los resúmenes utilizando ontologías (bases de conocimiento). La mayoría de los documentos en Internet tienen un mismo campo de aplicación, es decir, se ocupan todos del mismo asunto general. La ontología representa poderosamente la estructura de información única de cada dominio.
Este documento propone utilizar la ontología模糊, que modela la incertidumbre y describe precisamente el conocimiento del dominio, para resumir noticias chinas. En este método, los expertos del dominio primero definen la ontología de dominio para los eventos noticiosos, y luego la fase de preparación de documentos extrae palabras semánticas del corpus noticioso y del diccionario de noticias chinas.
Método de frase inicial y frase principal
Este enfoque implica reescribir la frase inicial realizando operaciones en frases (inserción y sustitución) con el mismo fragmento de cabeza sintáctica en la frase inicial y en el cuerpo de la frase. Utilizando la análisis sintáctico de los fragmentos de frase, Tanaka propuso una técnica para resumir noticias de transmisión. Se utilizan los métodos de fusión de oraciones para inferir el concepto básico de esta propuesta.
Resumir emisiones de noticias implica ubicar frases compartidas entre los fragmentos de inicio y cuerpo, luego insertar y reemplazar esas frases para producir un resumen mediante la revisión de frases. Primero, se aplica un analizador sintáctico a los fragmentos de inicio y cuerpo. Después, se identifican pares de búsqueda de disparadores y, finalmente, se alinean frases utilizando varias Criterios de similaridad y alineación. La última etapa puede ser tanto una inserción como una sustitución o ambas.
El proceso de inserción implica elegir un punto de inserción, comprobar la redundancia y comprobar el discurso para asegurar coherencia y eliminar la redundancia. El paso de sustitución proporciona información adicional sustituyendo la frase del cuerpo en el fragmento de inicio.
Método basado en reglas
En esta técnica, los documentos a resumir se representan en términos de clases y de listado de aspectos. El módulo de selección de contenido elige el candidato más efectivo entre aquellos generados por las reglas de extracción de datos para responder a uno o varios aspectos de una categoría. Finalmente, se utilizan patrones de generación para la generación de frases de esquema.
Para identificar sustantivos y verbos semanticamente relacionados, Pierre-Etienne et al. propuso un conjunto de criterios para la extracción de información. Una vez extraída la información, los datos se envían al paso de selección de contenido, que hace un esfuerzo para filtrar candidatos mezclados. Se utiliza para la estructura de oración y palabras en un patrón de generación directa. Después de la generación, se realiza una resumisión guiada por contenido.
Métodos basados en grafos
Muchos investigadores utilizan una estructura de datos de grafo para representar documentos lingüísticos. Los grafos son una opción popular para representar documentos en la comunidad de estudios lingüísticos. Cada nodo en el sistema representa una unidad léxica que, junto con las aristas dirigidas, define la estructura de una oración. Para mejorar el rendimiento de la Summarization, Dingding Wang et al. propuso sistemas de resumen de documentos multiples que utilizan una amplia gama de estrategias, como el método basado en el centroide, el método basado en grafos, etc., para evaluar varios métodos de combinación de líneas base, como la puntuación media, la posición media, el conteo de Borda, la agregación de medianas, etc.
Se desarrolló una metodología de consenso ponderada única para recolectar los resultados de diferentes estrategias de resumen. En un enfoque semántico, se utiliza una ilustración lingüística de un documento o documentos para alimentar un sistema de generación de lenguaje natural (NLG). Esta técnica se especializa en la identificación de frases nominales y frases verbales a través de datos lingüísticos.
ENFOQUE BASADO EN SEMÁNTICA
Los enfoques basados en semántica utilizan la ilustración lingüística de un documento para alimentar un sistema de generación de lenguaje natural (NLG). Este método procesa datos lingüísticos para identificar frases nominales y verbales.
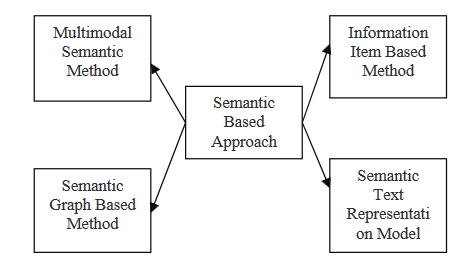
- Modelo semántico multimodal: En este método, se crea un modelo lingüístico que captura conceptos y relaciones entre ideas para describir el contenido de documentos multimodales como texto e imágenes. Se evalúan las ideas clave utilizando varios criterios, y luego se expresan los conceptos seleccionados como oraciones para formar un resumen.
- Método basado en elementos de información: En este enfoque, en lugar de utilizar oraciones de los documentos de suministro, se utiliza una representación abstracta de estos documentos para generar el contenido del resumen. La representación abstracta es un elemento de información, la parte más pequeña de la información coherente en un texto.
- Modelo de gráfico semántico: Esta técnica busca resumir un documento construyendo un gráfico semántico rico (RSG) para el documento inicial, reduciendo posteriormente el gráfico lingüístico creado y generando el resumen abstractivo final a partir del gráfico lingüístico reducido.
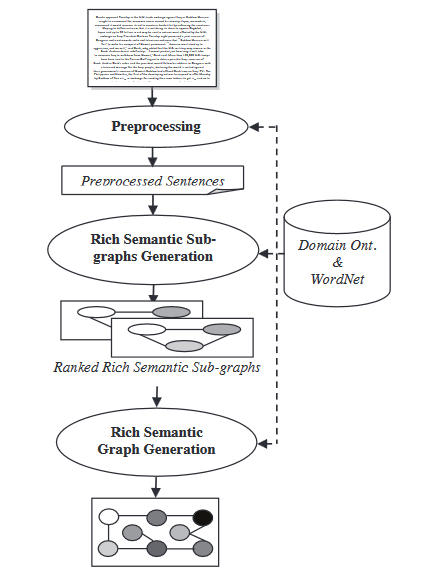
Durante el módulo de generación de gráfico semántico rico, se aplican una serie de reglas heurísticas al gráfico semántico rico generado para reducirlo mediante la fusión, eliminación o consolidación de los nodos del gráfico.
- Modelo de representación textual semántica: Esta técnica analiza el texto de entrada utilizando la semántica de las palabras en lugar de la sintaxis/estructura del texto.
Estudios de caso en negocios
- Programación de lenguajes informáticos: Ha habido múltiples esfuerzos para desarrollar tecnología IA capaz de escribir código y desarrollar sitios web de manera independiente. En el futuro, los programadores podrían ser capaces de confiar en especializados “resumidores de código” para extraer los elementos esenciales de proyectos novedosos.
- Asistir a personas con discapacidad física: Las personas que tienen dificultades auditivas pueden encontrar que el resumen les ayuda a seguir mejor el contenido a medida que avance la tecnología voz-texto.
- Conferencias y otras reuniones en video: Con la expansión del trabajo telemático, se requiere cada vez más la capacidad de grabar ideas y contenido importantes de las interacciones. Sería fantástico que las sesiones de equipo pudieran resumirse utilizando un método de voz-texto.
- La búsqueda de patentes: Encontrar información de patentes relevante puede ser tiempo consumido. Un generador de resumen de patentes podría ahorrarle tiempo tanto si está haciendo investigación de inteligencia de mercado como si está preparando para registrar una nueva patente.
- Libros y literatura: Los resúmenes son útiles porque proporcionan a los lectores una visión concisa del contenido que pueden esperar de un libro antes de decidir si comprarlo.
- Publicidad a través de redes sociales: Organizaciones que crean informes blancos, libros electrónicos y blogs de la compañía pueden utilizar el resumen para hacer que su trabajo sea más digerible y compartible en plataformas como Twitter y Facebook.
- Estudio económico: La industria de banca de inversiones invierte grandes sumas de dinero en adquisición de datos para usarlos en decisiones, como la negociación de acciones automatizada. Cualquier analista financiero que dedica todo el día a revisar datos del mercado y noticias eventualmente llegará a un sobrecarga de información. Los documentos financieros, como informes de resultados y noticias financieras, podrían beneficiarse de sistemas de resumen que permitan a los analistas extraer señales del mercado de los contenidos rápidamente.
- Fomentar su negocio utilizando Optimización para Buscadores: Las evaluaciones de optimización para buscadores (SEO) necesitan un conocimiento detallado de los temas discutidos en el contenido de los competidores. Es de suma importancia considerando las recientes modificaciones del algoritmo de Google y el énfasis posterior en la autoridad del tema. La capacidad para resumir rápidamente varios documentos, identificar comunes y buscar información crucial puede ser una herramienta de investigación poderosa.
Conclusión
Aunque el resumen abstractivo es menos fiable que los métodos extractivos, ofrece más promesas increíbles para producir resúmenes que se ajustan a la manera en que los humanos escriben. Como resultado, es probable que emerjan una gran cantidad de técnicas computacionales, cognitivas y lingüísticas nuevas en este área.
Referencias
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques