













Introducción
En este artículo, construiremos una de las primeras redes neuronales convolucionales que se hayan presentado, (LeNet5). Construiremos esta CNN desde cero en PyTorch y también veremos cómo funciona con un conjunto de datos real.
Empezaremos explorando la arquitectura de LeNet5. A continuación, cargaremos y analizaremos nuestro conjunto de datos, MNIST, utilizando la clase proporcionada desde torchvision. Utilizando PyTorch, construiremos nuestra LeNet5 desde cero y la entrenaremos en nuestros datos. Finalmente, veremos cómo se comporta el modelo en los datos de prueba no vistos.
Prerrequisitos
Un conocimiento de las redes neuronales será útil para entender este artículo. Esto significa estar familiarizado con las diferentes capas de redes neuronales (capa de entrada, capas ocultas, capa de salida), funciones de activación, algoritmos de optimización (variantes del descenso de gradiente), funciones de pérdida, etc. Además, una familiaridad con la sintaxis de Python y la biblioteca PyTorch es essential para entender los fragmentos de código presentados en este artículo.
También se recomienda un entendimiento de las CNNs. Esto incluye el conocimiento de las capas convolucionales, las capas de pooling y su papel en la extracción de características de los datos de entrada. Entender conceptos como la tasa de avance, el relleno y el impacto de la dimensión del kernel/filtro es beneficioso.
LeNet5
LeNet5 se utilizó para la reconocición de caracteres manuscritos y fue propuesto por Yann LeCun y otros en 1998 con el artículo,Gradient-Based Learning Applied to Document Recognition.
Vamos a comprender la arquitectura de LeNet5 como se muestra en la figura de abajo:
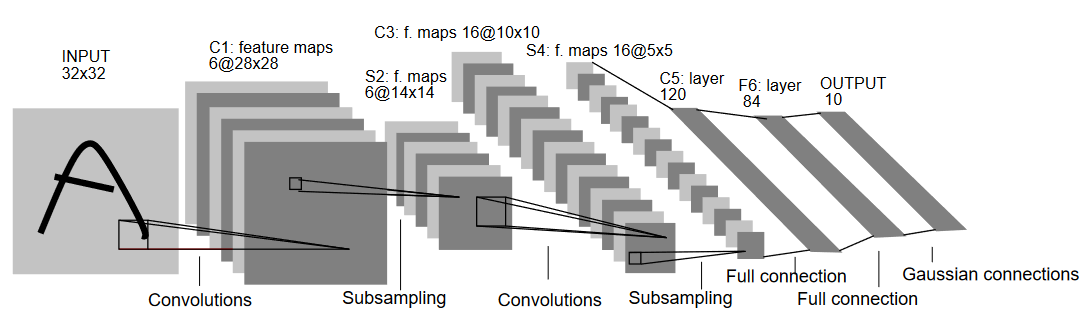
Como indica el nombre, LeNet5 tiene 5 capas, dos convolucionales y tres capas completamente conectadas. Comencemos con la entrada. LeNet5 acepta como entrada una imagen en escala de grises de 32×32, lo que indica que la arquitectura no es adecuada para imágenes RGB (multiples canales). Por lo tanto, la imagen de entrada debe contener solo un canal. Después de esto, empezamos con nuestras capas convolucionales
La primera capa convolucional tiene un tamaño de filtro de 5×5 con 6 filtros de este tipo. Esto reducirá la anchura y la altura de la imagen mientras que aumenta la profundidad (número de canales). La salida sería de 28x28x6. Después de esto, se aplica el pooling para disminuir el mapa de características por la mitad, es decir, 14x14x6. Se aplica ahora el mismo tamaño de filtro (5×5) con 16 filtros al resultado seguido de una capa de pooling. Esto reduce el mapa de características de salida a 5x5x16.
Después de esto, se aplica una capa convolucional de tamaño 5×5 con 120 filtros para aplanar la representación de características a 120 valores. A continuación, viene la primera capa completamente conectada, con 84 neuronas. Finalmente, tenemos la capa de salida que tiene 10 neuronas de salida, ya que los datos de MNIST tienen 10 clases para cada uno de los 10 dígitos numéricos representados.
Carga de Datos
Vamos a comenzar cargando y analizando los datos. Utilizaremos el conjunto de datos MNIST. El conjunto de datos MNIST contiene imágenes de dígitos numéricos escritos a mano. Las imágenes son en escala de grises, todas con un tamaño de 28×28, y está compuesto por 60,000 imágenes de entrenamiento y 10,000 imágenes de prueba.
Puede ver algunos de los ejemplos de imágenes aquí abajo:

Importando las Bibliotecas
Vamos a comenzar importando las bibliotecas necesarias y definiendo algunas variables (parámetros hiperparámetros y device también se detallan para ayudar al paquete a determinar si se debe entrenar en GPU o CPU):
# Cargar bibliotecas relevantes y asignar alias cuando sea apropiado
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Definir variables relevantes para la tarea de ML
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# El dispositivo determinará si se ejecuta el entrenamiento en GPU o CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Carga y Transformación de los Datos
Usando torchvision, cargaremos el conjunto de datos ya que esto nos permitirá realizar fácilmente cualquier paso de preprocesamiento.
#Cargando el conjunto de datos y preprocesamiento
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
Vamos a entender el código:
- Primero, los datos de MNIST no se pueden utilizar tal cual para la arquitectura LeNet5. La arquitectura LeNet5 acepta que la entrada sea de 32×32 y las imágenes de MNIST son de 28×28. Podemos solucionar esto reescalando las imágenes, normalizándolas utilizando la media y la desviación estándar predeterminadas (disponibles en línea) y almacenándolas finalmente como tensores.
- Establecemos
download=Trueen caso de que los datos no hayan sido descargados ya. - A continuación, hacemos uso de cargadores de datos. Esto puede no afectar el rendimiento en el caso de un conjunto de datos pequeño como MNIST, pero realmente puede impedir el rendimiento en caso de grandes conjuntos de datos y generalmente se considera una buena práctica. Los cargadores de datos nos permiten iterar por los datos en lotes y los datos se cargaron mientras iteramos y no todo a la vez al inicio.
- Especificamos el tamaño de lote y mezclamos el conjunto de datos al cargar para que cada lote tenga alguna variación en los tipos de etiquetas que tiene. Esto aumentará la eficacia de nuestro modelo final.
LeNet5 desde cero
Vamos a echar un vistazo primero al código:
# Definición de la red neuronal convolucional
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
Definición del Modelo LeNet5
Explicaré el código linealmente:
- En PyTorch, definimos una red neuronal creando una clase que hereda de
nn.Moduleya que contiene muchos de los métodos que necesitaremos para utilizarlos. - Después de eso, hay dos pasos principales. El primero es inicializar las capas que vamos a usar en nuestra CNN dentro de
__init__, y el otro es definir la secuencia en la que esas capas procesarán la imagen. Esto se define dentro de la funciónforward. - Para la arquitectura en sí, primero definimos las capas convolucionales usando la función
nn.Conv2Dcon el tamaño de kernel apropiado y los canales de entrada/salida. También aplicamos max pooling usando la funciónnn.MaxPool2D. Lo bueno de PyTorch es que podemos combinar la capa convolucional, función de activación y max pooling en una sola capa (se aplicarán por separado, pero ayuda con la organización) usando la funciónnn.Sequential. - Definemos entonces las capas completamente conectadas. Observe que podemos usar
nn.Sequentialaquí también y combinar las funciones de activación y las capas lineales, pero quise mostrar que cualquiera de las dos opciones es posible. - Finalmente, nuestra última capa emite 10 neuronas, que son nuestras predicciones finales para los dígitos.
Estableciendo Hiperparámetros
Antes de entrenar, necesitamos establecer algunos hiperparámetros, como la función de pérdida y el optimizador que se utilizará.
model = LeNet5(num_classes).to(device)
#Estableciendo la función de pérdida
cost = nn.CrossEntropyLoss()
#Estableciendo el optimizador con los parámetros del modelo y la tasa de aprendizaje
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#esto está definido para imprimir cuántos pasos quedan durante el entrenamiento
total_step = len(train_loader)
Empezamos inicializando nuestro modelo usando el número de clases como argumento, que en este caso es 10. Luego definimos nuestra función de costo como pérdida de entropía cruzada y el optimizador como Adam. Hay muchas opciones para estos, pero estos suelen dar buenos resultados con el modelo y los datos dados. Finalmente, definimos total_step para mantener un mejor seguimiento de los pasos durante el entrenamiento.
Entrenamiento del Modelo
Ahora, podemos entrenar nuestro modelo:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#Paso hacia adelante
outputs = model(images)
loss = cost(outputs, labels)
#Hacia atrás y optimizar
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
Veamos qué hace el código:
- Empezamos iterando por el número de épocas, y luego por los lotes en nuestra data de entrenamiento.
- Convertimos las imágenes y las etiquetas según el dispositivo que estamos utilizando, es decir, GPU o CPU.
- En el paso forward, hacemos predicciones usando nuestro modelo y calculamos la pérdida basada en esas predicciones y nuestras etiquetas reales.
- A continuación, hacemos el paso hacia atrás donde actualmente actualizamos nuestros pesos para mejorar nuestro modelo
- Luego, establecemos las gradientes en cero antes de cada actualización usando la función
optimizer.zero_grad(). - A continuación, calculamos los nuevos gradientes usando la función
loss.backward(). - Y finalmente, actualizamos los pesos con la función
optimizer.step().
Podemos ver la salida como sigue:
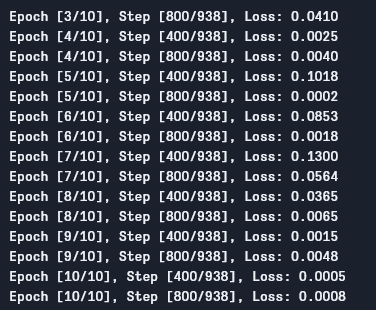
Como podemos ver, la pérdida disminuye con cada época, lo que muestra que nuestro modelo está aprendiendo realmente. Tenga en cuenta que esta pérdida es en el conjunto de entrenamiento y, si la pérdida es demasiado pequeña (como en nuestro caso), puede indicar sobreajuste. Hay múltiples maneras de resolver este problema, como regularización, ampliación de datos y así sucesivamente, pero no entraremos en eso en este artículo. Vamos a probar ahora nuestro modelo para ver cómo funciona.
Prueba del Modelo
Vamos a probar nuestro modelo ahora:
# Prueba del modelo
# En fase de prueba, no necesitamos calcular gradientes (para eficiencia de memoria)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
Como puede ver, el código no es tan diferente al del entrenamiento. La única diferencia es que no estamos calculando gradientes (utilizando with torch.no_grad()), y tampoco estamos calculando la pérdida porque aquí no necesitamos backpropagar. Para calcular la precisión resultante del modelo, simplemente podemos calcular el número total de predicciones correctas sobre el número total de imágenes.
Usando este modelo, obtenemos unas precisión de alrededor del 98,8%, lo cual es bastante bueno:

Precisión de Prueba
Tenga en cuenta que el conjunto de datos MNIST es bastante básico y pequeño para los estándares de hoy en día, y es difícil de obtener resultados similares para otros conjuntos de datos. No obstante, es un buen punto de partida para aprender aprendizaje profundo y CNNs.
Conclusión
Ahora vamos a concluir lo que hicimos en este artículo:
- Empezamos aprendiendo la arquitectura de LeNet5 y los diferentes tipos de capas que hay en ella.
- A continuación, exploramos el conjunto de datos MNIST y cargamos los datos utilizando
torchvision. - Después, construimos LeNet5 desde cero junto con la definición de parámetros del modelo.
- Finalmente, entrenamos y probamos nuestro modelo en el conjunto de datos MNIST, y el modelo pareció funcionar bien en el conjunto de prueba.
Trabajo Futuro
Aunque esto parece una introducción realmente buena a la aprendizaje profundo en PyTorch, también puede ampliar este trabajo para aprender más:
- Puede intentar usar diferentes conjuntos de datos, pero para este modelo necesitará conjuntos de datos en escala de grises. Uno de estos conjuntos de datos es FashionMNIST.
- Puede experimentar con diferentes hiperparámetros y ver la mejor combinación de ellos para el modelo.
- Finalmente, puede intentar agregar o eliminar capas del conjunto de datos para ver su impacto en la capacidad del modelo.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python