













Módulo Pandas de Python
- Pandas es una biblioteca de código abierto en Python. Proporciona estructuras de datos listas para usar de alto rendimiento y herramientas de análisis de datos.
- El módulo Pandas se ejecuta sobre NumPy y es ampliamente utilizado para ciencia de datos y análisis de datos.
- NumPy es una estructura de datos de bajo nivel que admite matrices multidimensionales y una amplia gama de operaciones matemáticas en matrices. Pandas tiene una interfaz de nivel superior. También proporciona alineación simplificada de datos tabulares y una funcionalidad poderosa de series temporales.
- El DataFrame es la estructura de datos clave en Pandas. Nos permite almacenar y manipular datos tabulares como una estructura de datos 2-D.
- Pandas proporciona un conjunto de funciones completo en el DataFrame. Por ejemplo, alineación de datos, estadísticas de datos, corte, agrupación, fusión, concatenación de datos, etc.
Instalación e Inicio con Pandas
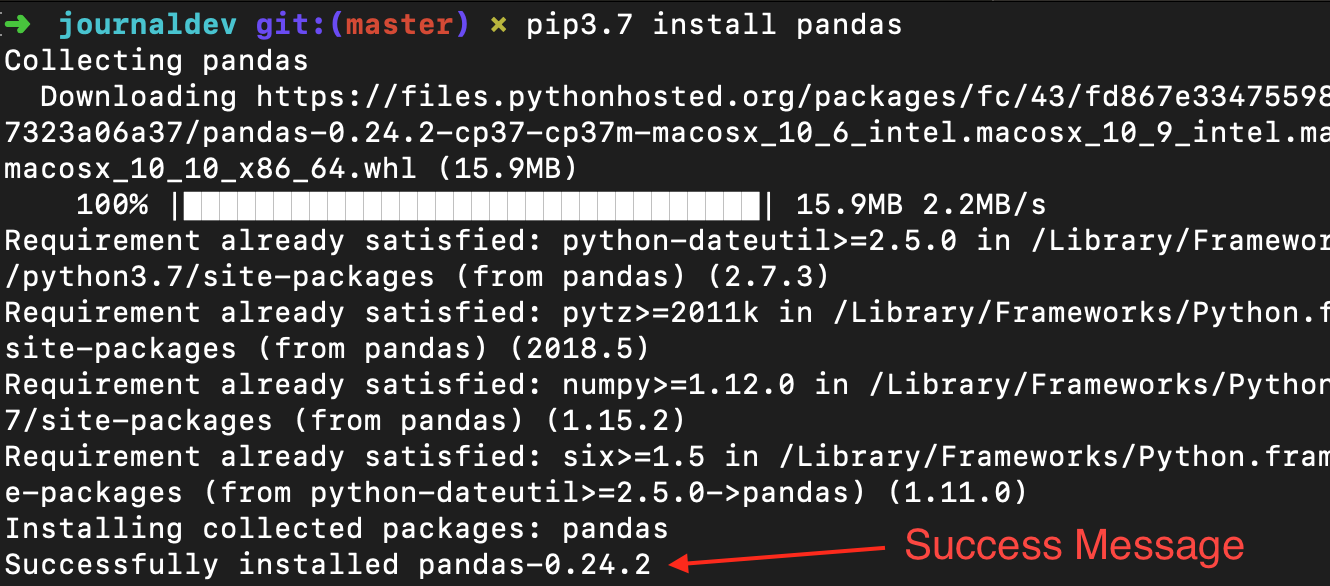
Necesitas tener Python 2.7 o superior para instalar el módulo Pandas. Si estás utilizando conda, entonces puedes instalarlo usando el siguiente comando.
conda install pandas
Si estás utilizando PIP, entonces ejecuta el siguiente comando para instalar el módulo pandas.
pip3.7 install pandas
Para importar Pandas y NumPy en tu script de Python, añade el siguiente fragmento de código:
import pandas as pd
import numpy as np
Dado que Pandas depende de la biblioteca NumPy, necesitamos importar esta dependencia.
Estructuras de datos en el módulo Pandas
El módulo Pandas proporciona 3 estructuras de datos, que son las siguientes:
- Serie: Es una estructura de tipo array inmutable de 1 dimensión con datos homogéneos.
- DataFrames: Es una estructura tabular de 2 dimensiones y tamaño mutable con columnas de tipos heterogéneos.
- Panel: Es un array de 3 dimensiones y tamaño mutable.
DataFrames de Pandas
El DataFrame es la estructura de datos más importante y ampliamente utilizada. Es una forma estándar de almacenar datos con alineación en filas y columnas, similar a una tabla SQL o una base de datos de hojas de cálculo. Podemos insertar datos en un DataFrame de forma estática o importar un archivo CSV, archivo tsv, archivo Excel, tabla SQL, etc. Podemos utilizar el siguiente constructor para crear un objeto DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
A continuación, se presenta una breve descripción de los parámetros:
- datos – crear un objeto DataFrame a partir de los datos de entrada. Puede ser una lista, un diccionario, una serie, ndarrays de Numpy o incluso cualquier otro DataFrame.
- índice – tiene las etiquetas de fila
- columnas – se utilizan para crear etiquetas de columna
- dtype – se utiliza para especificar el tipo de datos de cada columna, parámetro opcional
- copia – se utiliza para copiar datos, si los hay
Hay muchas formas de crear un DataFrame. Podemos crear un objeto DataFrame a partir de diccionarios o una lista de diccionarios. También podemos crearlo a partir de una lista de tuplas, CSV, archivo Excel, etc. Ejecutemos un código simple para crear un DataFrame a partir de la lista de diccionarios.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Salida:  El primer paso es crear un diccionario. El segundo paso es pasar el diccionario como argumento en el método DataFrame(). El paso final es imprimir el DataFrame. Como puedes ver, el DataFrame se puede comparar con una tabla que tiene valores heterogéneos. Además, el tamaño del DataFrame se puede modificar. Hemos suministrado los datos en forma del mapa y las claves del mapa son consideradas por Pandas como las etiquetas de fila. El índice se muestra en la columna más a la izquierda y tiene las etiquetas de fila. El encabezado de columna y los datos se muestran de manera tabular. También es posible crear DataFrames indexados. Esto se puede hacer configurando el parámetro de índice en el método
El primer paso es crear un diccionario. El segundo paso es pasar el diccionario como argumento en el método DataFrame(). El paso final es imprimir el DataFrame. Como puedes ver, el DataFrame se puede comparar con una tabla que tiene valores heterogéneos. Además, el tamaño del DataFrame se puede modificar. Hemos suministrado los datos en forma del mapa y las claves del mapa son consideradas por Pandas como las etiquetas de fila. El índice se muestra en la columna más a la izquierda y tiene las etiquetas de fila. El encabezado de columna y los datos se muestran de manera tabular. También es posible crear DataFrames indexados. Esto se puede hacer configurando el parámetro de índice en el método DataFrame().
Importando datos desde CSV a DataFrame
También podemos crear un DataFrame importando un archivo CSV. Un archivo CSV es un archivo de texto con un registro de datos por línea. Los valores dentro del registro están separados utilizando el carácter “coma”. Pandas proporciona un método útil, llamado read_csv() para leer el contenido del archivo CSV en un DataFrame. Por ejemplo, podemos crear un archivo llamado ‘ciudades.csv’ que contenga detalles de ciudades indias. El archivo CSV se almacena en el mismo directorio que contiene los scripts de Python. Este archivo se puede importar utilizando:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Nuestro objetivo es cargar datos y analizarlos para sacar conclusiones. Por lo tanto, podemos usar cualquier método conveniente para cargar los datos. En este tutorial, estamos codificando los datos del DataFrame.
Inspección de datos en DataFrame
Ejecutar el DataFrame usando su nombre muestra la tabla completa. En tiempo real, los conjuntos de datos para analizar tendrán miles de filas. Para analizar datos, necesitamos inspeccionar datos de grandes volúmenes de conjuntos de datos. Pandas proporciona muchas funciones útiles para inspeccionar solo los datos que necesitamos. Podemos usar df.head(n) para obtener las primeras n filas o df.tail(n) para imprimir las últimas n filas. Por ejemplo, el siguiente código imprime las primeras 2 filas y la última fila del DataFrame.
print(df.head(2))
Output: 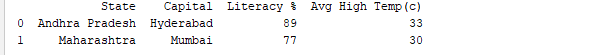
print(df.tail(1))
Output: 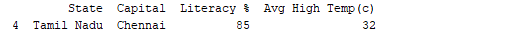 De manera similar,
De manera similar, print(df.dtypes) imprime los tipos de datos. Output: 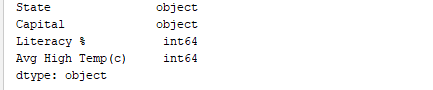
print(df.index) imprime el índice. Output: 
print(df.columns) imprime las columnas del DataFrame. Output: 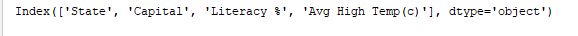
print(df.values) muestra los valores de la tabla. Output: 
1. Obteniendo un resumen estadístico de los registros
Podemos obtener un resumen estadístico (conteo, media, desviación estándar, mínimo, máximo, etc.) de los datos utilizando la función df.describe(). Ahora, usemos esta función para mostrar el resumen estadístico de la columna “Porcentaje de alfabetización”. Para hacer esto, podemos agregar el siguiente fragmento de código:
print(df['Literacy %'].describe())
Salida: 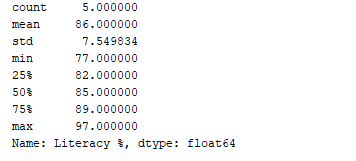 La función
La función df.describe() muestra el resumen estadístico, junto con el tipo de datos.
2. Ordenar registros
Podemos ordenar registros por cualquier columna utilizando la función df.sort_values(). Por ejemplo, vamos a ordenar la columna “Porcentaje de alfabetización” en orden descendente.
print(df.sort_values('Literacy %', ascending=False))
Salida: 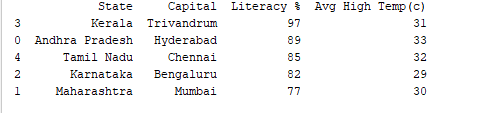
3. Cortar registros
Es posible extraer datos de una columna particular utilizando el nombre de la columna. Por ejemplo, para extraer la columna ‘Capital’, usamos:
df['Capital']
o
(df.Capital)
Salida:  También es posible dividir varias columnas. Esto se hace encerrando los nombres de varias columnas entre 2 corchetes, con los nombres de las columnas separados por comas. El siguiente código divide las columnas ‘Estado’ y ‘Capital’ del DataFrame.
También es posible dividir varias columnas. Esto se hace encerrando los nombres de varias columnas entre 2 corchetes, con los nombres de las columnas separados por comas. El siguiente código divide las columnas ‘Estado’ y ‘Capital’ del DataFrame.
print(df[['State', 'Capital']])
Salida:  También es posible dividir filas. Se pueden seleccionar varias filas utilizando el operador “:”. El siguiente código devuelve las primeras 3 filas.
También es posible dividir filas. Se pueden seleccionar varias filas utilizando el operador “:”. El siguiente código devuelve las primeras 3 filas.
df[0:3]
Salida:  Una característica interesante de la biblioteca Pandas es seleccionar datos según las etiquetas de sus filas y columnas mediante la función
Una característica interesante de la biblioteca Pandas es seleccionar datos según las etiquetas de sus filas y columnas mediante la función iloc[0]. Muchas veces, solo necesitamos algunas columnas para analizar. También podemos seleccionar por índice utilizando loc['index_one']). Por ejemplo, para seleccionar la segunda fila, podemos usar df.iloc[1,:]. Supongamos que necesitamos seleccionar el segundo elemento de la segunda columna. Esto se puede hacer usando la función df.iloc[1,1]. En este ejemplo, la función df.iloc[1,1] muestra “Mumbai” como resultado.
4. Filtrar datos
También es posible filtrar según los valores de las columnas. Por ejemplo, el siguiente código filtra las columnas con un porcentaje de alfabetización superior al 90%.
print(df[df['Literacy %']>90])
Cualquier operador de comparación puede usarse para filtrar, basado en una condición. Salida:  Otra forma de filtrar datos es utilizando el
Otra forma de filtrar datos es utilizando el isin. A continuación se muestra el código para filtrar solo 2 estados, ‘Karnataka’ y ‘Tamil Nadu’.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Salida: 
5. Renombrar columna
Es posible utilizar la función df.rename() para renombrar una columna. La función toma el nombre antiguo de la columna y el nuevo nombre como argumentos. Por ejemplo, renombremos la columna ‘Literacy %’ a ‘Literacy percentage’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
El argumento `inplace=True` realiza los cambios en el DataFrame. Salida: 
6. Manipulación de datos
La ciencia de datos implica el procesamiento de datos para que estos funcionen bien con los algoritmos de datos. La manipulación de datos es el proceso de procesar datos, como la fusión, agrupación y concatenación. La biblioteca Pandas proporciona funciones útiles como `merge()`, `groupby()` y `concat()` para respaldar las tareas de manipulación de datos. Creemos 2 DataFrames y mostremos las funciones de manipulación de datos para entenderlo mejor.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Salida:  Creemos el segundo DataFrame usando el siguiente código:
Creemos el segundo DataFrame usando el siguiente código:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Salida: 
a. Merging
Ahora, fusionemos los 2 DataFrames que creamos, a lo largo de los valores de ‘Employee_id’ usando la función `merge()`:
print(pd.merge(df1, df2, on='Employee_id'))
Salida:  Podemos ver que la función `merge()` devuelve las filas de ambos DataFrames que tienen el mismo valor de columna, que se utilizó durante la fusión.
Podemos ver que la función `merge()` devuelve las filas de ambos DataFrames que tienen el mismo valor de columna, que se utilizó durante la fusión.
b. Grouping
Agrupar es un proceso de recolección de datos en diferentes categorías. Por ejemplo, en el siguiente ejemplo, el campo “Employee_Name” tiene el nombre “Meera” dos veces. Entonces, agrupémoslo por la columna “Employee_name”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
El campo ‘Employee_name’ con valor ‘Meera’ se agrupa por la columna “Employee_name”. La salida de muestra es la siguiente: Salida: 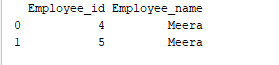
c. Concatenating
La concatenación de datos implica agregar un conjunto de datos a otro. Pandas proporciona una función llamada concat() para concatenar DataFrames. Por ejemplo, vamos a concatenar los DataFrames df1 y df2, usando:
print(pd.concat([df1, df2]))
Salida:
Crear un DataFrame pasando un Diccionario de Series
Para crear una Serie, podemos usar el método pd.Series() y pasarle un array. Creemos una Serie simple de la siguiente manera:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Salida: Hemos creado una Serie. Puedes ver que se muestran 2 columnas. La primera columna contiene los valores de índice comenzando desde 0. La segunda columna contiene los elementos pasados como series. Es posible crear un DataFrame pasando un diccionario de `Series`. Creemos un DataFrame que está formado por la unión y el paso de los índices de las series.Ejemplo
Hemos creado una Serie. Puedes ver que se muestran 2 columnas. La primera columna contiene los valores de índice comenzando desde 0. La segunda columna contiene los elementos pasados como series. Es posible crear un DataFrame pasando un diccionario de `Series`. Creemos un DataFrame que está formado por la unión y el paso de los índices de las series.Ejemplo
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Salida de muestra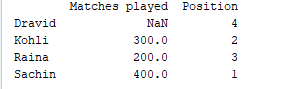 Para la serie uno, como no hemos especificado la etiqueta ‘d’, se devuelve NaN.
Para la serie uno, como no hemos especificado la etiqueta ‘d’, se devuelve NaN.
Selección, Adición, Eliminación de Columnas
Es posible seleccionar una columna específica del DataFrame. Por ejemplo, para mostrar solo la primera columna, podemos reescribir el código anterior de la siguiente manera:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
El código anterior imprime solo la columna “Partidos jugados” del DataFrame. Resultado 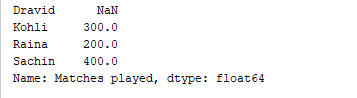 También es posible agregar columnas a un DataFrame existente. Por ejemplo, el siguiente código agrega una nueva columna llamada “Runrate” al DataFrame anterior.
También es posible agregar columnas a un DataFrame existente. Por ejemplo, el siguiente código agrega una nueva columna llamada “Runrate” al DataFrame anterior.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Resultado:  Podemos eliminar columnas utilizando las funciones `delete` y `pop`. Por ejemplo, para eliminar la columna ‘Partidos jugados’ en el ejemplo anterior, podemos hacerlo de cualquiera de las siguientes dos formas:
Podemos eliminar columnas utilizando las funciones `delete` y `pop`. Por ejemplo, para eliminar la columna ‘Partidos jugados’ en el ejemplo anterior, podemos hacerlo de cualquiera de las siguientes dos formas:
del df['Matches played']
o
df.pop('Matches played')
Resultado: 
Conclusión
En este tutorial, tuvimos una breve introducción a la biblioteca Python Pandas. También realizamos ejemplos prácticos para desatar el poder de la biblioteca Pandas utilizada en el campo de la ciencia de datos. También revisamos las diferentes estructuras de datos en la biblioteca Python. Referencia: Sitio web oficial de Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial