













Scikit Learn
 Scikit-learn es una biblioteca de aprendizaje automático para Python. Presenta varios algoritmos de regresión, clasificación y agrupamiento, incluidos SVM, aumento de gradiente, k-means, bosques aleatorios y DBSCAN. Está diseñado para trabajar con Python Numpy y SciPy. El proyecto scikit-learn comenzó como un proyecto de Google Summer of Code (también conocido como GSoC) por David Cournapeau como scikits.learn. Recibe su nombre de “Scikit”, una extensión de terceros separada para SciPy.
Scikit-learn es una biblioteca de aprendizaje automático para Python. Presenta varios algoritmos de regresión, clasificación y agrupamiento, incluidos SVM, aumento de gradiente, k-means, bosques aleatorios y DBSCAN. Está diseñado para trabajar con Python Numpy y SciPy. El proyecto scikit-learn comenzó como un proyecto de Google Summer of Code (también conocido como GSoC) por David Cournapeau como scikits.learn. Recibe su nombre de “Scikit”, una extensión de terceros separada para SciPy.
Python Scikit-learn
Scikit está escrito en Python (la mayor parte) y algunos de sus algoritmos principales están escritos en Cython para obtener un rendimiento aún mejor. Scikit-learn se utiliza para construir modelos y no se recomienda utilizarlo para leer, manipular y resumir datos, ya que hay mejores marcos disponibles para ese propósito. Es de código abierto y se publica bajo la licencia BSD.
Instalar Scikit Learn
Scikit asume que tienes una plataforma de Python 2.7 o superior en funcionamiento con los paquetes NumPY (1.8.2 y superior) y SciPY (0.13.3 y superior) en tu dispositivo. Una vez que tengamos estos paquetes instalados, podemos proceder con la instalación. Para la instalación con pip, ejecuta el siguiente comando en la terminal:
pip install scikit-learn
Si prefieres conda, también puedes utilizar conda para la instalación del paquete, ejecuta el siguiente comando:
conda install scikit-learn
Usando Scikit-Learn
Una vez que hayas terminado con la instalación, puedes usar scikit-learn fácilmente en tu código de Python importándolo como:
import sklearn
Cargando Conjunto de Datos de Scikit Learn
Comencemos cargando un conjunto de datos para jugar. Carguemos un conjunto de datos simple llamado Iris. Es un conjunto de datos de una flor, contiene 150 observaciones sobre diferentes medidas de la flor. Veamos cómo cargar el conjunto de datos usando scikit-learn.
# Importar scikit learn
from sklearn import datasets
# Cargar datos
iris= datasets.load_iris()
# Imprimir forma de los datos para confirmar que los datos han sido cargados
print(iris.data.shape)
Estamos imprimiendo la forma de los datos para mayor facilidad, también puedes imprimir todos los datos si lo deseas, ejecutar los códigos da una salida como esta: 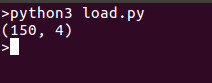
Scikit Learn SVM – Aprendizaje y Predicción
Ahora que hemos cargado los datos, intentemos aprender de ellos y predecir en nuevos datos. Para este propósito, tenemos que crear un estimador y luego llamar a su método fit.
from sklearn import svm
from sklearn import datasets
# Cargar conjunto de datos
iris = datasets.load_iris()
clf = svm.LinearSVC()
# Aprender de los datos
clf.fit(iris.data, iris.target)
# Predecir para datos no vistos
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Los parámetros del modelo pueden ser cambiados usando los atributos que terminan con un guion bajo
print(clf.coef_ )
Esto es lo que obtenemos cuando ejecutamos este script: 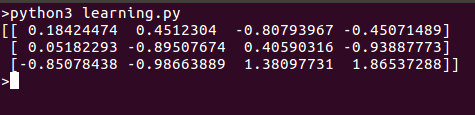
Regresión Lineal de Scikit Learn
Crear varios modelos es bastante simple usando scikit-learn. Comencemos con un ejemplo simple de regresión.
#importar el modelo
from sklearn import linear_model
reg = linear_model.LinearRegression()
# usarlo para ajustar datos
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Veamos los datos ajustados
print(reg.coef_)
Al ejecutar el modelo debería devolver un punto que se puede trazar en la misma línea: 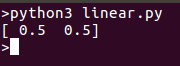
k-Nearest neighbour classifier
Vamos a probar un algoritmo de clasificación simple. Este clasificador utiliza un algoritmo basado en árboles de bolas para representar las muestras de entrenamiento.
from sklearn import datasets
# Cargar conjunto de datos
iris = datasets.load_iris()
# Crear y ajustar un clasificador de vecinos más cercanos
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Predecir e imprimir el resultado
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
Vamos a ejecutar el clasificador y verificar los resultados, el clasificador debería devolver 0. Vamos a probar el ejemplo: 
K-means clustering
Este es el algoritmo de agrupamiento más simple. El conjunto se divide en ‘k’ grupos y cada observación se asigna a un grupo. Esto se hace de forma iterativa hasta que los grupos convergen. Crearemos un modelo de agrupamiento de este tipo en el siguiente programa:
from sklearn import cluster, datasets
# cargar datos
iris = datasets.load_iris()
# crear grupos para k=3
k=3
k_means = cluster.KMeans(k)
# ajustar datos
k_means.fit(iris.data)
# imprimir resultados
print( k_means.labels_[::10])
print( iris.target[::10])
Al ejecutar el programa veremos grupos separados en la lista. Aquí está la salida para el fragmento de código anterior: 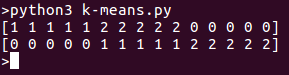
Conclusión
En este tutorial, hemos visto que Scikit-Learn facilita el trabajo con varios algoritmos de aprendizaje automático. Hemos visto ejemplos de Regresión, Clasificación y Agrupamiento. Scikit-Learn aún está en fase de desarrollo y está siendo desarrollado y mantenido por voluntarios, pero es muy popular en la comunidad. Ve y prueba tus propios ejemplos.
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial