













Am 11. Dezember 2024 kam es bei den OpenAI-Diensten aufgrund eines Problems im Zusammenhang mit der Bereitstellung eines neuen Telemetriedienstes zu erheblichen Ausfallzeiten. Dieser Vorfall beeinträchtigte die API-, ChatGPT- und Sora-Dienste und führte zu Serviceunterbrechungen, die mehrere Stunden dauerten. Als Unternehmen, das genaue und effiziente KI-Lösungen anbieten möchte, hat OpenAI einen detaillierten Post-Mortem-Bericht geteilt, um transparent zu erörtern, was schief gelaufen ist und wie sie ähnliche Vorfälle in Zukunft verhindern wollen.
In diesem Artikel werde ich die technischen Aspekte des Vorfalls beschreiben, die Ursachen analysieren und wichtige Lehren herausarbeiten, die Entwickler und Organisationen, die verteilte Systeme verwalten, aus diesem Ereignis mitnehmen können.
Der Vorfall-Zeitplan
Hier ist ein Überblick darüber, wie sich die Ereignisse am 11. Dezember 2024 entwickelt haben:
| Time (PST) | Event |
|---|---|
| 15:16 Uhr |
Geringfügige Kundenbeeinträchtigung begann; Serviceverschlechterung festgestellt |
| 15:27 Uhr | Ingenieure begannen, den Verkehr von betroffenen Clustern umzuleiten |
| 15:40 Uhr | Maximale Kundenbeeinträchtigung verzeichnet; schwere Ausfälle bei allen Diensten |
| 16:36 Uhr | Das erste Kubernetes-Cluster begann sich zu erholen |
| 17:36 Uhr | Erhebliche Erholung bei den API-Diensten begann |
| 17:45 Uhr | Erhebliche Erholung bei ChatGPT beobachtet |
| 19:38 Uhr | Alle Dienste vollständig wiederhergestellt in allen Clustern |
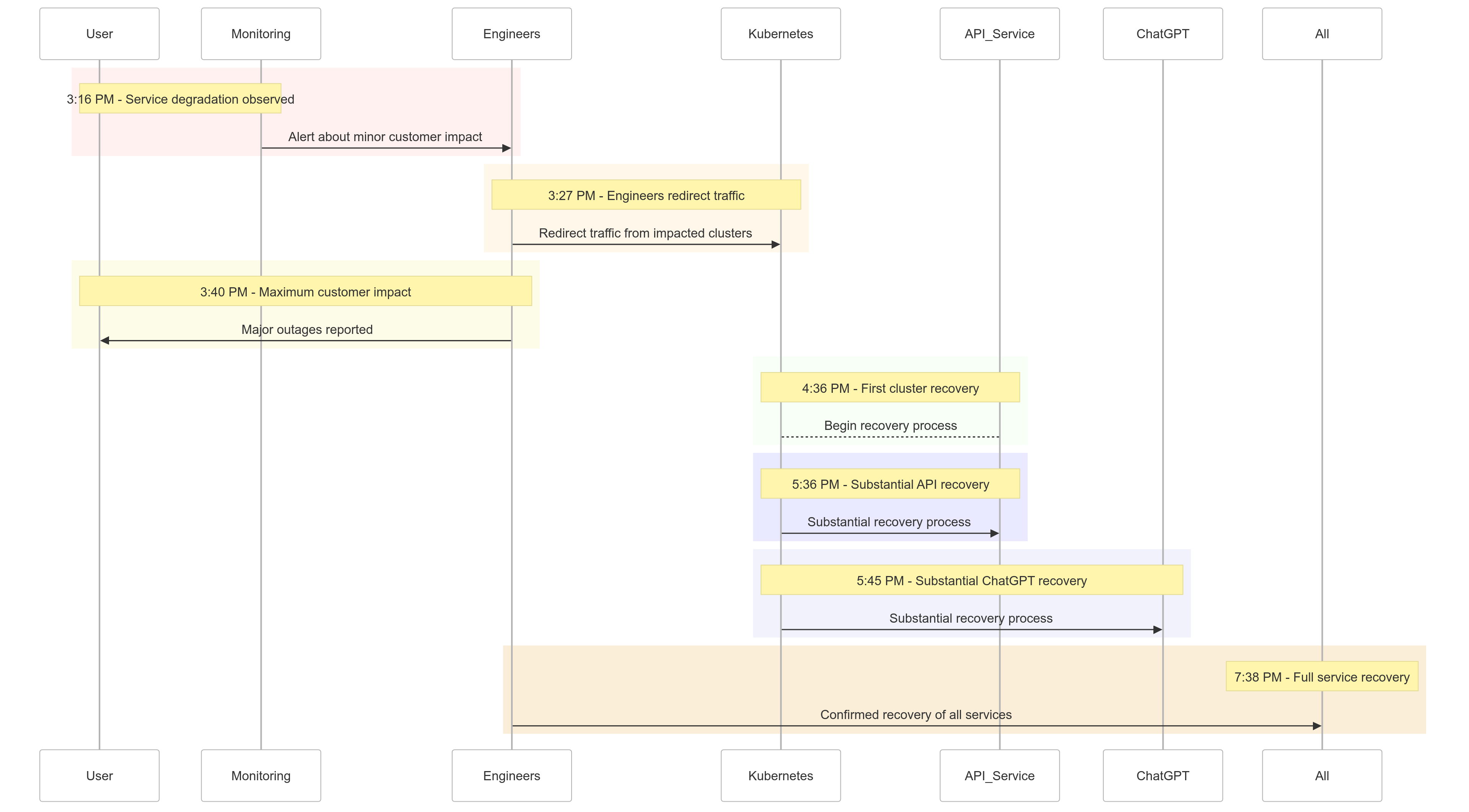
Abbildung 1: OpenAI Vorfall-Zeitleiste – Serviceverschlechterung bis zur vollständigen Wiederherstellung.
Ursachenanalyse
Die Wurzel des Vorfalls lag in einem neuen Telemetriedienst, der um 15:12 Uhr PST eingeführt wurde, um die Beobachtbarkeit von Kubernetes-Steuerungsebenen zu verbessern. Dieser Dienst überwältigte unabsichtlich die Kubernetes-API-Server über mehrere Cluster hinweg, was zu kaskadierenden Ausfällen führte.
Aufschlüsselung
Bereitstellung des Telemetriedienstes
Der Telemetriedienst wurde entwickelt, um detaillierte Metriken der Kubernetes-Steuerungsebene zu sammeln, aber seine Konfiguration löste unbeabsichtigt ressourcenintensive Kubernetes-API-Operationen über tausende von Knoten gleichzeitig aus.
Überlastete Steuerungsebene
Die Kubernetes-Steuerungsebene, die für die Clusterverwaltung zuständig ist, wurde überfordert. Während die Datenebene (die Benutzeranfragen verarbeitet) teilweise funktionsfähig blieb, war sie auf die Steuerungsebene für die DNS-Auflösung angewiesen. Als die zwischengespeicherten DNS-Einträge abliefen, begannen die Dienste, die auf die Echtzeit-DNS-Auflösung angewiesen waren, auszufallen.
Unzureichende Tests
Die Bereitstellung wurde in einer Testumgebung getestet, aber die Testcluster spiegelten nicht den Umfang der Produktionscluster wider. Infolgedessen blieb das Problem mit der API-Serverlast während der Tests unentdeckt.
Wie das Problem gemildert wurde
Als der Vorfall begann, identifizierten OpenAI-Ingenieure schnell die Ursache, sahen sich jedoch Herausforderungen bei der Implementierung einer Lösung gegenüber, da der überlastete Kubernetes-Steuerungsbereich den Zugriff auf die API-Server verhinderte. Ein mehrgleisiger Ansatz wurde angenommen:
- Reduzierung der Clustergröße: Die Verringerung der Anzahl der Knoten in jedem Cluster senkte die Last der API-Server.
- Blockierung des Netzwerkzugriffs auf Kubernetes-Admin-APIs: Verhinderte zusätzliche API-Anfragen, sodass die Server sich erholen konnten.
- Skalierung der Kubernetes-API-Server: Die Bereitstellung zusätzlicher Ressourcen half, ausstehende Anfragen zu bearbeiten.
Diese Maßnahmen ermöglichten es den Ingenieuren, wieder Zugriff auf die Steuerungsbereiche zu erhalten und den problematischen Telemetriedienst zu entfernen, wodurch die Funktionsfähigkeit des Dienstes wiederhergestellt wurde.
Gelerntes
Dieser Vorfall hebt die Bedeutung robuster Tests, Überwachung und Sicherheitsmechanismen in verteilten Systemen hervor. Hier ist, was OpenAI aus dem Ausfall gelernt (und implementiert) hat:
1. Robuste phasenweise Rollouts
Alle Infrastrukturänderungen werden jetzt phasenweise mit kontinuierlicher Überwachung durchgeführt. Dies stellt sicher, dass Probleme frühzeitig erkannt und gemindert werden, bevor sie auf die gesamte Flotte ausgeweitet werden.
2. Fehlereinfügungstests
Durch die Simulation von Ausfällen (z. B. Deaktivierung des Steuerungsbereichs oder Ausrollen fehlerhafter Änderungen) wird OpenAI überprüfen, dass ihre Systeme automatisch wiederhergestellt werden können und Probleme erkannt werden, bevor sie Kunden beeinträchtigen.
3. Notfallzugang zum Steuerungsnetzwerk
Ein „Break-Glass“-Mechanismus wird sicherstellen, dass Ingenieure auch unter hoher Last auf Kubernetes-API-Server zugreifen können.
4. Entkopplung von Steuerungs- und Datenebenen
Um Abhängigkeiten zu reduzieren, wird OpenAI die Kubernetes-Datenebene (die Arbeitslasten verarbeitet) von der Steuerungsebene (zuständig für die Orchestrierung) entkoppeln, sodass kritische Dienste auch während Ausfällen der Steuerungsebene weiterlaufen können.
5. Schnellere Wiederherstellungsmechanismen
Neue Caching- und Ratenbegrenzungsstrategien werden die Startzeiten der Cluster verbessern und eine schnellere Wiederherstellung bei Ausfällen gewährleisten.
Beispielcode: Phasenweises Rollout-Beispiel
Hier ist ein Beispiel für die Implementierung eines phasenweisen Rollouts für Kubernetes unter Verwendung von Helm und Prometheus zur Beobachtbarkeit.
Helm-Bereitstellung mit phasenweisen Rollouts:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Prometheus-Abfrage zur Überwachung der Last auf dem API-Server:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Diese Abfrage hilft, die Antwortzeiten für API-Server-Anfragen zu verfolgen und ermöglicht eine frühe Erkennung von Lastspitzen.
Beispiel für Fehlereinbringung
Mit chaos-mesh könnte OpenAI Ausfälle im Kubernetes-Steuerungsnetzwerk simulieren.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Diese Konfiguration beendet absichtlich ein API-Server-Pod, um die Systemresilienz zu überprüfen.
Was das für Sie bedeutet
Dieser Vorfall unterstreicht die Bedeutung der Entwicklung robuster Systeme und der Anwendung rigoroser Testmethoden. Egal, ob Sie verteilte Systeme im großen Maßstab verwalten oder Kubernetes für Ihre Arbeitslasten implementieren, hier sind einige Erkenntnisse:
- Fehler regelmäßig simulieren: Verwenden Sie Chaos-Engineering-Tools wie Chaos Mesh, um die Robustheit des Systems unter realen Bedingungen zu testen.
- Auf mehreren Ebenen überwachen: Stellen Sie sicher, dass Ihr Beobachtungs-Stack sowohl Dienstleistungsmetriken als auch Cluster-Gesundheitsmetriken verfolgt.
- Kritische Abhängigkeiten entkoppeln: Reduzieren Sie die Abhängigkeit von einzelnen Ausfallpunkten, wie z.B. DNS-basiertes Service-Discovery.
Fazit
Während kein System gegen Ausfälle immun ist, erinnern uns Vorfälle wie dieser an den Wert von Transparenz, schneller Behebung und kontinuierlichem Lernen. Der proaktive Ansatz von OpenAI, diesen Nachbericht zu teilen, bietet eine Blaupause für andere Organisationen zur Verbesserung ihrer Betriebspraktiken und Zuverlässigkeit.
Indem OpenAI robuste phasenweise Rollouts, Fehlereinspritztests und ein resilienter Systemdesign priorisiert, setzt es ein starkes Beispiel dafür, wie man mit großflächigen Ausfällen umgeht und daraus lernt.
Für Teams, die verteilte Systeme verwalten, ist dieser Vorfall eine großartige Fallstudie dafür, wie man Risikomanagement angeht und Ausfallzeiten für zentrale Geschäftsprozesse minimiert.
Lassen Sie uns diese Gelegenheit nutzen, um gemeinsam bessere, resilientere Systeme zu bauen.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident