













Einführung
In der Datenwissenschaft und insbesondere im Bereich der natürlichen Sprachverarbeitung ist Zusammenfassung ein Thema, das seit jeher intensive Interesse weckt. Obwohl Textzusammenfassungsmethoden schon seit some time existieren, hat die letztere Zeit eine Reihe von bedeutenden Entwicklungen in der natürlichen Sprachverarbeitung und Deep Learning gebracht. Es gibt eine Fülle von Arbeiten, die zu diesem Thema veröffentlicht werden, u.a. durch Internetriesen wie die jüngste ChatGPT. Obwohl eine Menge Arbeit an diesem Studienthema geleistet wird, gibt es sehr wenig Schrift über praktische Implementierungen von AI-gesteuerter Zusammenfassung. Der Schwierigkeiten, große, allgemeine Aussagen zu parsen, ist ein Hindernis für wirksame Zusammenfassung.
Zusammenfassen einer Nachrichtenartikel und eines Finanzertrag-Berichts sind zwei unterschiedliche Aufgaben. Bei der Behandlung textueller Merkmale, die in Länge oder Thematik variieren (Tech, Sport, Finanzen, Reise etc.), wird Zusammenfassung zu einer Herausforderung der Datenwissenschaft. Es ist wichtig, dass man einige Grundlagen in der Zusammenfassungstheorie abdeckt, bevor man sich eine Übersicht über Anwendungen verschafft.
Extraktaive Zusammenfassung
Der Prozess der extraktiven Zusammenfassung besteht darin, die relevantesten Sätze aus einem Artikel auszuwählen und systematisch zu organisieren. Die Sätze, die die Zusammenfassung bilden, werden direkt aus der Quellmaterialität entnommen.
Extraktive Zusammenfassungssysteme, wie wir sie kennen, kreisen um drei grundlegende Operationen:
Bau einer Zwischenrepräsentation des Eingabetextes
Themenrepräsentation und Indikatorerepräsentation sind Beispiele von repräsentationbasierten Methoden. Um das Thema(n) auszuarbeiten, das im Text erwähnt wird, wandelt die Themenrepräsentation den Text in eine Zwischenrepräsentation ein.
Bewertung der Sätze basierend auf der Repräsentation
Bei der Generierung der Zwischenrepräsentation erhält jeder Satz einen Bedeutungsscore. Beim Einsatz eines auf Themenrepräsentation basierenden Verfahrens reflektiert ein Satzs Score, wie effektiv er Schlüsselbegriffe im Text aufzeigt. Bei Indikatorerepräsentation wird der Wert durch die Aggregation der Beweise von verschiedenen gewichteten Indikatoren berechnet.
Auswahl eines Zusammenfassungsinhalts aus mehreren Sätzen
Um eine Zusammenfassung zu generieren, wählt das Zusammenfassungswerkzeug die k wichtigsten Sätze aus. Einige Methoden verwendengreedy-Algorithmen, um zu entscheiden, welche Sätze am relevantesten sind, während andere die Sentsellection in ein Optimierungsproblem verwandeln könnten, in dem eine Reihe von Sätzen ausgewählt wird, unter der Vorgabe, dass sie die Gesamtbedeutung und die Kohärenz maximieren und die Menge der redundanten Informationen minimieren müssen.
Lassen Sie uns tiefer in die Methoden einsteigen, die wir bereits erwähnt haben:
Thematische Repräsentationsansätze
Thematische Wörter: Mit dieser Methode können Sie in dem Eingabedokument thematisch verwandte Begriffe finden. Die Bedeutung eines Satzes kann auf zwei Weise berechnet werden: Erstens als eine Funktion des Anteils von thematischen Signaturen, die er enthält; zweitens als Bruchteil der thematischen Signaturen, die er enthält. Während die erste Methode längeren Sätzen mit mehr Wörtern höhere Scores verleiht, misst die zweite die Dichte der thematischen Wörter.
Frequenzgetriebene Ansätze: Mit diesem Verfahren werden Wörter relative Bedeutung zugeordnet. Erhält ein Begriff thematischen Zusammenhang, erhält er 1 Punkt; andernfalls geht er auf null zurück. Je nach der Implementierung können die Gewichte kontinuierlich sein. Thematische Repräsentationen können mit einem von zwei Methoden erreicht werden:
Wortwahrscheinlichkeit: Diese Methode nimmt nur die Häufigkeit eines Wortes auf, um ihre Bedeutung anzuzeigen. Um die Wahrscheinlichkeit eines Wortes w zu berechnen, teilen wir seine Häufigkeit f(w) durch die Gesamtzahl der Wörter N.
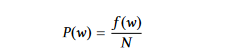
Die mittlere Bedeutung der Wörter in einer Sentence gibt die Bedeutung der Sentence bei der Verwendung von Wortwahrscheinlichkeiten an.
TFIDF (Term Frequency Inverse Document Frequency): Diese Methode ist eine Verbesserung des Wortwahrscheinlichkeitsansatzes. Hier wird die Gewichtung durch die Nutzung des TF-IDF-Verfahrens bestimmt. Die Technik der Term Frequency Inverse Document Frequency (TFIDF) gibt weniger Bedeutung an Begriffe, die in den meisten Dokumenten oft auftreten. Der Gewichtungskoeffizient jedes Wortes w in Dokument d wird wie folgt berechnet:
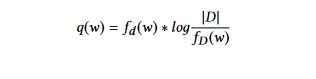
wobei fd (w) die Term-Frequenz von Wort w in Dokument d ist,
fD (w) die Anzahl der Dokumente, die das Wort w enthalten, und |D| die Anzahl der Dokumente in der Sammlung D ist.
Latent Semantic Analyse: Latent semantic analysis (LSA) ist ein unsupervisierte Methode zur Extraktion einer Textsemantikdarstellung, die auf beobachteten Wörtern basiert. Der LSA-Prozess beginnt mit der Erstellung einer Begriff-Satzmatrix (n mal m), wobei jeder Zeile ein Wort aus der Eingabe (n Wörter) und jeder Spalte ein Satz (m Sätze) entspricht. In der Matrix ist der Gewichtungswert des Wortes i in dem Satz j durch die Eintragung aij definiert. Gemäß der TFIDF-Technik wird jedem Wort in einem Satz eine bestimmte Gewichtung zugeordnet, wobei Null für Begriffe verwendet wird, die nicht im Satz enthalten sind.
Indikatordarstellungsansätze
Graphbasierte Methoden
Graphdarstellungen, die von dem PageRank-Algorithmus beeinflusst sind, stellen Dokumente als verbundenes Graphen dar. Satz bilden die Knoten des Graphen, und die Kanten, die die Sätze miteinander verbinden, zeigen die Grad der Beziehung zwischen zwei Sätzen. Eine häufig verwendete Methode, um zwei Knoten miteinander zu verknüpfen, besteht darin, zu bestimmen, wie ähnlich zwei Sätze sind, und falls der Grad der Ähnlichkeit über einen bestimmten Schwellenwert hinausgeht, werden die Knoten verbunden. Mit dieser Graphdarstellung sind beide Ausgaben möglich. Erstens definieren die Teilungen des Graphen (Untergraphen) einzelne Kategorien von Informationen, die von den Dokumenten abgedeckt werden. Der zweite Ergebnis ist die Markierung wesentlicher Sätze im Dokument. Sätze, die zu vielen anderen Sätzen in der Teilung verbunden sind, könnten möglicherweise die Mitte des Graphen sein und werden wahrscheinlicherweise im Zusammenfassungsdokument enthalten. Sowohl ein- als auch mehrdokumentale Zusammenfassungen können von der Verwendung graphbasierter Techniken profitieren.
Maschinelles Lernen
Maschinelles Lernen versteht die Zusammenfassungsaufgabe als Klassifikationschallenge. Modelle versuchen, Sätze aufgrund ihrer Merkmale in Zusammenfassungskategorien und Nicht-Zusammenfassungskategorien einzustufen. Wir verfügen über ein Trainings集, das aus Dokumenten und von Menschen revidierter extrahierter Zusammenfassungen besteht, auf dem wir unsere Algorithmen trainieren können. Dies wird oft mit Naive Bayes, Entscheidungsbaum oder Unterstützungsmaschine durchgeführt.
Abstractives Zusammenfassung
Im Gegensatz zur extraktiven Zusammenfassung ist die abstrakte Zusammenfassung ein effizienter Ansatz. Die Fähigkeit, eigene Sätze zu schaffen, die wichtige Informationen aus Textquellen vermitteln, hat zu dieser steigenden Popularität beigetragen.
Ein abstrakter Zusammenfassungsverfahren präsentiert den Inhalt in logisch aufgebautem, gut organisiertem und grammatisch korrektem Form. Die Qualität einer Zusammenfassung kann durch Verbesserung der Lesbarkeit oder der sprachlichen Qualität erheblich verbessert werden. (enthalten Bild).
Es gibt zwei Ansätze: Der strukturbasierte Ansatz und der semantikbasierte Ansatz.
STRUKTURBASIERTER ANSATZ
Beim strukturiert basierten Ansatz ist die wichtigste Information aus dem Dokument (s) mithilfe von psychologischen Merkmalen Schemas wie Vorlagen, Extraktionsregeln und alternative Strukturen kodiert, einschließlich von Baum, Ontologie, Überschrift und Körper, Regel und grafisch basierten Strukturen. Im Folgenden lesen wir über einige der verschiedenen Methoden, die in diese Strategie integriert sind.
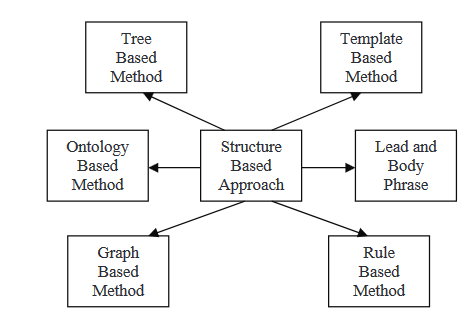
Baumbasierte Methoden
In dieser Methode wird der Inhalt eines Dokuments als Abhängigkeitsbaum repräsentiert. Der Inhalt für einen Outline kann mittels verschiedener Techniken ausgewählt werden, wie z.B. ein Thema-Schnittmenge Algorithmus oder einer, der die native Ausrichtung versucht, über parsierte Sätze. Dieser Ansatz verwendet entweder einen Sprachgenerator oder ein assoziates Grad-Verfahren für die Generierung des Outlines. In diesem Papier bieten die Autoren eine Methode der Satzfusion an, die aus dem Bottom-up lokalen Mehrsequenz-Alignment die gemeinsamen Informationen sucht. Multigene Zusammenfassungssysteme verwenden eine Technik namens Satzfusion.
In dieser Methode werden ein Satz und ein Satz als Eingaben verwendet, verarbeitet mit einem Themaauswahlalgorithmus, um den zentralen thema herauszuschälen, und dann ein Clusteringalgorithmus, um die Phrasen entsprechend ihrer Bedeutung zu sortieren. Nachdem die Sätze geordnet wurden, verwendet man Satzfusion, um sie zu verschmelzen und generiert eine statistische Zusammenfassung. Die strukturierte Methode codiert die wichtigsten Daten aus dem Dokument(en) mit mentale Schema wie Vorlagen, Extraktionsregeln und alternative Strukturen wie Baum, Ontologie, Überschrift und Körper, Regel und grafische Struktur.
Vorlagenbasierte Methoden
In dieser Methode wird ein Leitfaden verwendet, um einen gesamten Text zu repräsentieren. Sprachliche Muster oder Extraktionskriterien werden verglichen, um Textabschnitte zu identifizieren, die in die Leitfaden-Slots eingeordnet werden können. Diese Textabschnitte sind die Indikatoren für die Untereinheiten des umfassenden Inhalts. In diesem Papier wurde eine Methode vorgeschlagen (einzelnes und mehrdokumentales Zusammenfassung), um Zusammenfassungen und Abstrakte aus Dokumenten zu erstellen. Sie folgten den in GISTEXTER beschriebenen Methoden zur Erstellung von Extrakten und Abstrakten.
GISTEXTER ist ein Zusammenfassungssystem, das themenbezogene Informationen im Eingabetext erkennt und in Datenbankeinträge umwandelt; die Sätze werden dann je nach Benutzeranforderung zur Zusammenfassung hinzugefügt.

Ontologiebasierte Methoden
Viele Forscher haben versucht, die Zusammenfassungseffektivität mittels Ontologie (Wissensbasis) zu verbessern. Die meisten Internetdokumente haben einen gemeinsamen Bereich, das heißt, sie behandeln alle das gleiche allgemeine Thema. Ontologie ist eine kraftvolles Abbildung der einzigartigen Informationstruktur jedes Bereichs.
Dieser Artikel schlägt vor, die fuzzy Ontologie zu verwenden, die Unsicherheiten modelliert und den Domänenwissen exakt beschreibt, um chinesische Nachrichten zu zusammenzufassen. In diesem Verfahren definieren Domain-Experten zunächst die Domänen-Ontologie für Nachrichtenereignisse und dann der Dokumentenerstellungsphase werden semantische Wörter aus der Nachrichtenkorpus und dem chinesischen Nachrichtenwörterbuch extrahiert.
Leit- und Hauptphrasenmethode
Diese Methode beinhaltet die Umformulierung der Leitzeile durch Operationen auf Phrasen (Einfügen und Ersetzen) mit dem gleichen syntaktischen Kopfbaustein in der Leitzeile und im Hauptteil des Satzes. Mit der syntaktischen Analyse von Phrasenbausteinen schlug Tanaka eine Technik für die Zusammenfassung von Hörfunksendungen vor. Satzfusionmethoden werden verwendet, um die Grundlage dieses Konzepts abzuleiten.
Zusammenfassung von Nachrichtensendungen besteht darin, Phrasen zu finden, die zwischen der Überschrift und dem Hauptteil gemeinsam sind, und anschließend diese Phrasen einzufügen und zu ersetzen, um eine Zusammenfassung durch die Revision von Sätzen zu produzieren. Zuerst wird ein syntaktischer Parser auf der Überschrift und dem Hauptteil angewendet. Anschließend werden Trigger-Suchpaare identifiziert und schließlich Phrasen mit verschiedenen Ähnlichkeits- und Alignierungs kriterien abgestimmt. Der letzte Schritt kann entweder eine Eingliederung oder eine Substitution oder beides sein.
Der Eingliederungsprozess beinhaltet die Wahl eines Eingliederungspunkts, die Überprüfung auf Redundanz und die Überprüfung des Diskurses für interne Kohärenz, um Kohärenz und Redundanz zu gewährleisten. Der Substitutionsschritt liefert zusätzliche Informationen, indem die Phrase im Hauptteil durch eine im Überschriftsteil ersetzt wird.
Regelbasierte Methode
In dieser Technik werden die zu zusammenfassenden Dokumente in Bezug auf Klassen und Aspekte dargestellt. Der Inhaltswahlmodul wählt den effektivsten Kandidaten aus den durch Datenextraktionsregeln generierten, um eine oder mehrere Aspekte einer Kategorie zu beantworten. Schließlich werden Generierungsmustern zur Generierung von Rückschlagsätzen verwendet.
Um Substantive und Verben zu identifizieren, die semantisch verwandt sind, haben Pierre-Etienne et al. ein Set von Kriterien für die Informationsexraktion vorgeschlagen. Nach der Extraktion werden die Daten an den Schritt der Inhaltsauswahl weitergeleitet, der versucht, gemischte Kandidaten herauszuschälen. Dies wird für die Satzstruktur und die Wörter in einem direkten Generationsmuster verwendet. Nach der Generierung wird eine Inhaltsanleitete Zusammenfassung durchgeführt.
Graphbasierte Methoden
Viele Forscher verwenden eine Graphdatenstruktur, um Sprachdokumente abzubilden. Graphdatenstrukturen sind eine populäre Wahl zur Darstellung von Dokumenten in der Sprachwissenschaftsgemeinschaft. Jeder Knoten im System steht für ein Wortelement, das durch konzentrierte Kanten die Struktur einer Satzfläche definiert. Um die Leistung der Zusammenfassung zu verbessern, hat Dingding Wang und andere vorgeschlagen, Mehrfachdokumentenzusammenfassungssysteme zu entwickeln, die eine Vielzahl von Strategien verwenden, wie z.B. das auf dem Mittelpunkt basierte Verfahren, das Graphbasierte Verfahren usw., um verschiedene Basiskombinationsmethoden zu bewerten, wie z.B. Durchschnittspunktzahl, Durchschnittsreihenfolge, Bordacount, Medianaggregation usw. Eine einzigartige gewichtete Konsensmethode wurde entwickelt, um die Ergebnisse verschiedener Zusammenfassungsstrategien zu sammeln. In einer semantisch basierten Methode wird eine sprachliche Illustration the Dokument oder der Dokumente verwendet, um ein Natursprachgenerierungs (NLG) System zu versorgen. Diese Technik konzentriert sich auf die Identifizierung von Substantivphrasen und Verbphrasen durch sprachliche Daten.
SEMANTISCHE BERECHNUNG
Semantische Verfahren verwenden eine sprachliche Illustration eines Dokuments, um ein Natur-Sprach-Generierungs-System (NLG) zu versorgen. Diese Methode verarbeitet sprachliche Daten, um Substantivphrasen und Verbphrasen zu identifizieren.
- Mehrdimensionales Semantikmodell: In diesem Verfahren wird ein sprachwissenschaftliches Modell geschaffen, das Konzepte und Beziehungen zwischen Ideen erfasst, um den Inhalt von mehrdimensionalen Dokumenten wie Text und Bildern zu beschreiben. Die Schlüsselideen werden anhand verschiedener Kriterien bewertet, und die ausgewählten Konzepte werden dann als Sätze formuliert, um einen Zusammenfassung zu bilden.
- Informationspunktbasierte Methode: In diesem Ansatz wird stattdessen nicht der Text der Quelldokumente verwendet, um den Inhalt der Zusammenfassung zu generieren, sondern eine abstrakte Repräsentation dieser Dokumente. Die abstrakte Darstellung ist ein Informationspunkt, der kleinste abgeschlossene Informationseinheit in einem Text.
- Semantisches Graphmodell: Diese Technik zielt auf die Zusammenfassung eines Dokuments ab, indem ein reicher semantischer Graph (RSG) für das ursprüngliche Dokument erstellt wird, anschließend der erstellte sprachwissenschaftliche Graph verringert wird und die abschließende reduzierte Zusammenfassung aus dem verringerten sprachwissenschaftlichen Graph generiert wird.
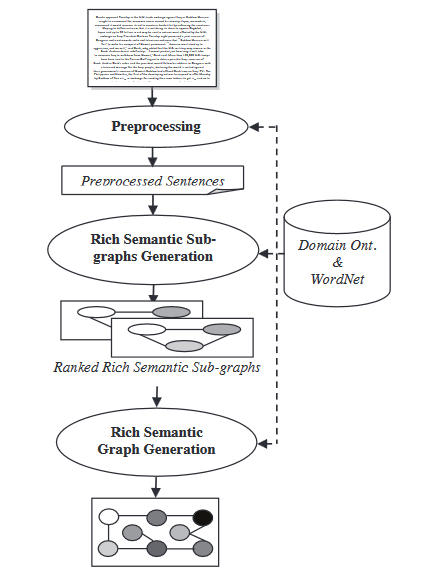
Während des Moduls für die Generierung von reichen semantischen Gittern werden zu dem erstellten reichen semantischen Graphen eine Reihe von heuristischen Regeln angewendet, um ihn durch Zusammenführung, Löschung oder Konsolidierung der Graphenknoten zu verringern.
- Semantisches Textdarstellungsmodell: Diese Technik analysiert Eingabetexte mit der Semantik von Wörtern anstatt mit der Syntax/Struktur des Textes.
Geschäftsfallstudien
- Informatikprogrammierung: Es wurden verschiedene Bemühungen unternommen, um AI-Technologie zu entwickeln, die in der Lage ist, selbst Code zu schreiben und Webseiten zu entwickeln. In Zukunft könnten Programmierer auf spezialisierte „Code-Zusammenfassungen“ vertrauen, um die Essenz aus neuen Projekten herauszuprobieren.
- Hilfe für Menschen mit physischen Einschränkungen: Menschen, die Schwierigkeiten beim Hören haben, könnten erleichtert werden, Inhalte zu verfolgen, indem die Zusammenfassung hilft, mit dem Fortschritt der Sprach-zu-Text-Technologie.
- Konferenzen und andere Video-Besuche: Mit der Expansion des Teleforschungsbereichs ist die Fähigkeit, wichtige Ideen und Inhalte aus Interaktionen aufzunehmen, zunehmend erforderlich. Es wäre fantastisch, wenn Ihre Team-Sitzungen mit einer Sprach-zu-Text-Methode zusammengefasst werden könnten.
- Patent suchen: Der Fund relevanter Patentsinformationen kann Zeit in Anspruch nehmen. Ein Patentsummarisierer könnte Ihnen Zeit sparen, egal ob Sie Marktintelligenzforschung durchführen oder sich auf die Registrierung eines neuen Patents vorbereiten.
- Bücher und Literatur: Zusammenfassungen sind hilfreich, weil sie Lesern eine konzise Übersicht über den Inhalt geben, der sie von einem Buch erwarten könnten, bevor sie sich entscheiden, ob sie es kaufen wollen.
- Social Media-Marketing: Organisationen, die Weißpapiere, E-Books und Unternehmensblogs erstellen, könnten Zusammenfassungen verwenden, um ihre Arbeit auf Platformen wie Twitter und Facebook verständlicher und verbreitbarer zu machen.
- Wirtschaftsforschung: Die Investmentbankensektor investiert erhebliche Summen in die Datenerwerbung für Entscheidungen, wie den computerbasierten Handel mit Aktien. Jeder Finanzanalytiker, der den ganzen Tag damit verbringt, durchbrochene Marktdaten und Nachrichten zu durchsuchen, wird irgendwann an Informationsoverload stoßen. Finanzdokumente, wie z.B. Gewinnberichte und Finanznachrichten, könnten von Zusammenfassungssystemen profitieren, die Analysten dabei behilflich sind, Marktsignale aus dem Inhalt schnell zu extrahieren.
-
Ihre Geschäfte mit dem Search Engine Optimization fördern: Suchmaschinenoptimierung (SEO) Evaluierungen erfordern eine gründliche Vertrautheit mit den Themen, die in den Inhalten der Konkurrenten behandelt werden. Dies ist von zentraler Bedeutung, insbesondere angesichts der jüngsten Algorithmusänderungen bei Google und dem anschließenden Akzent auf die Themaautorität. Die Fähigkeit, mehrere Dokumente schnell zu zusammenfassen, Gemeinsamkeiten zu erkennen und wichtige Informationen aufzuspüren, könnte ein kraftvolles Recherchetool sein.
Schlussfolgerung
Obwohl abstraktive Zusammenfassungen weniger zuverlässig sind als extraktive Methoden, bietet sie eine größere Versprechen für die Erstellung von Zusammenfassungen, die dem menschlichen Schreibstil entsprechen. Daher ist es wahrscheinlich, dass in diesem Bereich eine Vielzahl von neuen komplementären, kognitiven und linguistischen Techniken aufkommen wird.
Quellen
- Eine Umfrage über abstrakte Textsummarisierung
- Zur automatischen Textsummarisierung. Teil 2. Abstrakte Methoden
- 20 Anwendungen von automatischer Textsummarisierung in der Unternehmenswelt
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques