













Einleitung
In diesem Artikel werden wir eine der ursprünglichen Konvolutionsneuronalen Netze, die LeNet5 genannt wurde, errichten. Wir bauen dieses CNN von Grund auf in PyTorch und beobachten auch, wie es auf einem realeinstellbaren Datensatz performt.
Wir werden beginnen, die Architektur von LeNet5 zu erkunden. Dann laden und analysieren wir unser Datensatz MNIST mit der bereitgestellten Klasse aus torchvision. Mit PyTorch bauen wir unsere LeNet5 von Grund auf auf und trainieren sie auf unseren Daten. Schließlich werden wir sehen, wie das Modell auf unbekanntem Testdaten performt.
Voraussetzungen
Knowledge of neural networks will be helpful in understanding this article. This translates to being familiar with the different layers of neural networks (input layer, hidden layers, output layer), activation functions, optimization algorithms (variants of gradient descent), loss functions, etc. Additionally, familiarity with Python syntax and the PyTorch library is essential for understanding the code snippets presented in this article.
Ein Verständnis von CNNs ist ebenfalls empfehlenswert. Dies beinhaltet das Wissen um Konvolutionsobjekte, Pooling-Schichten und ihre Rolle beim Extraktion von Merkmalen aus Eingabedaten. Der Verständnis von Konzepten wie Stride, Padding und der Auswirkung der Kernel/Filtergröße ist hilfreich.
LeNet5
LeNet5 wurde zur Erkennung von handschriftlichen Zeichen verwendet und von Yann LeCun und anderen 1998 mit dem Paper,Gradientenbasierte Lernverfahren angewendet auf die Dokumenterkennung, vorgeschlagen.
Lass uns die Architektur von LeNet5 verstehen, wie in der unteren Abbildung gezeigt:
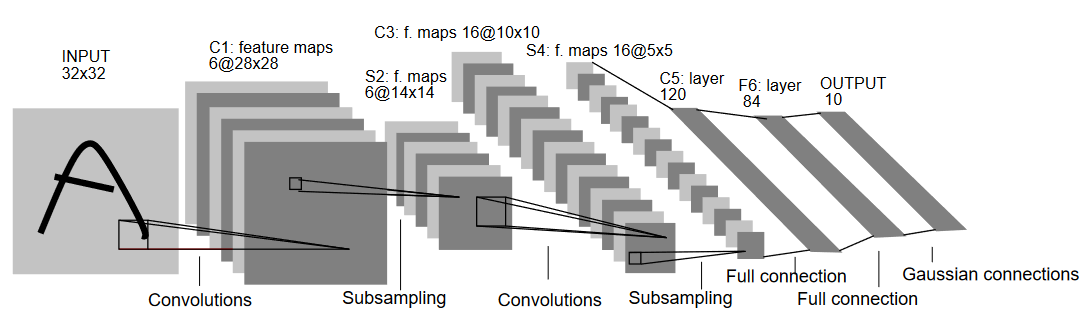
Wie der Name vermuten lässt, hat LeNet5 fünf Schichten mit zwei Konvolutionsobjekten und drei vollständig verknüpften Schichten. Beginnen wir mit dem Eingang. LeNet5 nimmt ein Grauwertbild von 32×32 an, was bedeutet, dass die Architektur nicht für RGB-Bilder (mehrere Kanäle) geeignet ist. Daher sollte das Eingangsbild nur einen Kanal enthalten. Nach diesem folgen unsere Konvolutionsobjekte
Die erste Konvolutionsobjekt hat eine Filtergröße von 5×5 mit 6 solcher Filter. Dies wird die Breite und Höhe des Bildes verringern, während die Tiefe (Anzahl der Kanäle) erhöht. Der Output wäre 28x28x6. Danach wird Pooling angewendet, um das Feature-Map um die Hälfte zu verringern, d.h., 14x14x6. Ein gleicher Filtergröße (5×5) mit 16 Filter ist nun auf das Ergebnis angewendet, gefolgt von einer Pooling-Schicht. Dies verringert das Output-Feature-Map auf 5x5x16.
Nach diesem Schritt wird eine Convolutional Layer mit einer Größe von 5×5 und 120 Filtern angewendet, um das Feature Map auf 120 Werte zu flachen. Danach folgt die erste vollständig verknüpfte Schicht mit 84 Neuronen. Schließlich haben wir die Ausgabeschicht, die 10 Ausgabenerven hat, da die MNIST-Daten 10 Klassen für jedes der dargestellten 10 numerischen Zeichen enthalten.
Daten Laden
Lassen Sie uns mit dem Laden und Analyse der Daten beginnen. Wir werden das MNIST-Datensatz verwenden. Der MNIST-Datensatz enthält Bilder von handschriftlichen numerischen Ziffern. Die Bilder sind Grauwertbilder, alle mit einer Größe von 28×28 und bestehen aus 60.000 Trainingsbildern und 10.000 Testbildern.
Sie können einige Beispiele der Bilder unten sehen:

Bibliotheken importieren
Beginnen wir mit dem Import der notwendigen Bibliotheken und der Definition einiger Variablen (Hyperparameter und device werden ebenfalls detailliert erläutert, um dem Paket zu helfen, zu entscheiden, ob die Ausbildung auf der GPU oder CPU durchgeführt wird):
# Laden Sie relevante Bibliotheken ein und verwenden Sie die entsprechenden Alias-Befehle
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Definieren Sie relevante Variablen für die maschinellenlernende Aufgabe
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# Gerät bestimmt, ob die Ausbildung auf der GPU oder CPU durchgeführt wird.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Daten Laden und Umwandeln
Mit torchvision werden wir die Datenmenge geladen, da dies uns die Durchführung von einfachen Prüfungs- und Verarbeitungsschritten ermöglicht.
#Datenmenge laden und vorverarbeiten
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
Lassen Sie uns das Code verstehen:
- Zuerst ist die MNIST-Datenmenge nicht verwendbar, um die LeNet5-Architektur zu nutzen. Die LeNet5-Architektur erlaubt nur Eingaben von 32×32, während die MNIST-Bilder 28×28 sind. Wir können dies beheben, indem wir die Bilder skalieren, sie normalisieren, indem wir die vorher berechnete Mean und Standardabweichung verwenden (verfügbar online) und schließlich als Tensoren speichern.
- Wir setzen
download=True, falls die Daten noch nicht heruntergeladen wurden. - Danach nutzen wir Datenloader. Dies kann die Leistung bei kleinen Datensätzen wie MNIST nicht beeinträchtigen, kann aber bei großen Datensätzen die Leistung stark behindern und ist generell eine gute Praxis. Datenloader ermöglichen es uns, über die Daten in Batches iterieren zu können, und die Daten werden während der Iteration geladen und nicht einmal am Anfang auf einmal.
- Wir legen die Batchgröße fest und vermischen die Datenmenge beim Laden, sodass jeder Batch eine Variation in den Typen der Labels enthält. Dies wird die Effizienz unseres letzten Modells erhöhen.
LeNet5 von Grund auf
Lassen Sie uns zunächst die Codeansicht anschauen:
# Definieren der convolutiven neuronalen Netzwerke
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
LeNet5-Modell definieren
Ich erkläre den Code linear:
- In PyTorch definieren wir ein neuronales Netz, indem wir eine Klasse erzeugen, die von
nn.Moduleerbt, da es viele Methoden enthält, die wir verwenden müssen. - Daraufhin gibt es zwei HauptSchritte. Der erste Schritt besteht in der Initialisierung der Schichten, die wir in unserem CNN verwenden, innerhalb des
__init__-Befehls, und der zweite Schritt besteht darin, die Reihenfolge zu definieren, in der diese Schichten das Bild verarbeiten werden. Dies wird innerhalb derforward-Funktion definiert. - Für die Architektur selbst definieren wir zunächst die konvolutionellen Schichten mit der
nn.Conv2D-Funktion mit der passenden Kernelgröße und den Eingangs-/Ausgabekanälen. Wir verwenden auch Max-Pooling mit dernn.MaxPool2D-Funktion. Die schönen Dinge an PyTorch ist, dass wir die konvolutionelle Schicht, die Aktivierungsfunktion und das Max-Pooling in eine einzige Schicht (sie werden separat angewendet, aber es hilft bei der Organisation) kombinieren können, indem wir dienn.Sequential-Funktion verwenden. - Wir definieren die vollständig verbundenen Schichten. Beachten Sie, dass wir
nn.Sequentialhier ebenfalls verwenden könnten und die Aktivierungsfunktionen und die linearen Schichten kombinieren, aber ich habe gezeigt, dass entweder eine oder die andere Möglichkeit möglich ist. - Schließlich erzeugt unsere letzte Schicht 10 Neuronen, die unsere Endvoraussagen für die Ziffern sind.
Hyperparameter Einstellungen
Vor der Trainingsphase müssen wir einige Hyperparameter einstellen, wie z.B. die Verlustfunktion und den zu verwendenden Optimierer.
model = LeNet5(num_classes).to(device)
#Einstellen der Verlustfunktion
cost = nn.CrossEntropyLoss()
#Einstellen des Optimizers mit den Modellparametern und Lernrate
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#dies ist definiert, um anzugeben, wie viele Schritte bei der Trainingszeit übrig sind
total_step = len(train_loader)
Wir beginnen mit der Initialisierung unseres Modells, indem wir die Anzahl der Klassen als Argument verwenden, die in diesem Fall 10 ist. Dann definieren wir unseren Kostenfunktions als Kreuzentropenverlust und den Optimierer als Adam. Es gibt viele Möglichkeiten für diese, aber diese tendieren dazu, gute Ergebnisse mit dem Modell und den gegebenen Daten zu liefern. Schließlich definieren wir total_step, um bessere Überwachung der Schritte während der Trainingsphase zu ermöglichen.
Modelleinstellungen
Nun können wir unser Modell trainieren:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#Forward Pass
outputs = model(images)
loss = cost(outputs, labels)
#Rückwärtspass und Optimierung
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
Schauen wir uns an, was der Code tut:
- Wir beginnen mit der Iteration durch die Anzahl der Epochen und dann durch die Batches in unseren Trainingsdaten.
- Wir konvertieren die Bilder und die Labels gemäß dem Gerät, das wir verwenden, d.h. GPU oder CPU.
- Im Vorwärtsdurchlauf machen wir Vorhersagen mit unserem Modell und berechnen den Verlust basierend auf diesen Vorhersagen und unseren tatsächlichen Labels.
- Anschließend führen wir den Rückwärtsdurchlauf durch, in dem wir tatsächlich unsere Gewichte aktualisieren, um unser Modell zu verbessern.
-
Dann setzen wir die Gradienten vor jedem Update auf Null, indem wir die Funktion
optimizer.zero_grad()verwenden. -
Danach berechnen wir die neuen Gradienten mit der Funktion
loss.backward(). -
Und schließlich aktualisieren wir die Gewichte mit der Funktion
optimizer.step().
Wir können die Ausgabe wie folgt sehen:
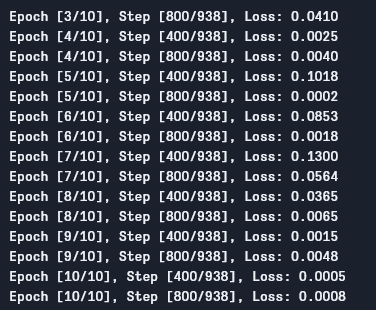
Wie wir sehen können, verringert sich der Verlust mit jeder Epoche, was zeigt, dass unser Modell tatsächlich lernt. Beachte, dass dieser Verlust auf dem Trainingsset ist, und wenn der Verlust zu klein ist (wie in unserem Fall), kann dies auf Overfitting hinweisen. Es gibt mehrere Wege, dieses Problem zu lösen, wie Regularisierung, Datenverstärkung und so weiter, aber wir werden hierauf in diesem Artikel nicht eingehen. Testen wir nun unser Modell, um zu sehen, wie es performt.
Modelltest
Testen wir jetzt unser Modell:
# Model testen
# Im Testmodus müssen wir keine Gradienten berechnen (um Speicher effizient zu nutzen)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
Wie Sie sehen können, unterscheidet sich die Code-Struktur nicht allzu stark von der des Trainings. Der einzige Unterschied besteht darin, dass wir Gradienten nicht berechnen (indem wir with torch.no_grad() verwenden), und auch keinen Verlust berechnen, da wir hier kein Backpropagation durchführen müssen. Um die Ergebnisgenauigkeit des Modells zu berechnen, können wir einfach die Anzahl der korrekten Vorhersagen dividiert durch die Gesamtzahl der Bilder ausrechnen.
Mit diesem Modell erreichen wir eine Genauigkeit von etwa 98,8%, was recht gut ist:

Testgenauigkeit
Beachten Sie, dass das MNIST-Datensatz relativ grundständig und klein für heutige Standards ist und dass vergleichbare Ergebnisse für andere Datensätze schwer zu erzielen sind. Dennoch ist es ein guter Startpunkt, wenn Sie Deep Learning und CNNs lernen.
Fazit
Lassen Sie uns nun zusammenfassen, was wir in diesem Artikel taten:
- Wir haben zunächst die Architektur von LeNet5 gelernt und die verschiedenen Arten von Schichten in dieser.
- Dann haben wir das MNIST-Datensatz untersucht und die Daten mit
torchvisiongeladen. - Danach haben wir LeNet5 von Grund auf erstellt und Hyperparameter für das Modell definiert.
- Schließlich haben wir unser Modell auf dem MNIST-Datensatz trainiert und getestet, und das Modell scheint auf dem Testdatensatz gut zu funktionieren.
Zukünftige Arbeiten
Obwohl dies eine sehr gute Einführung in das Deep Learning mit PyTorch ist, können Sie diese Arbeit auch erweitern, um mehr zu lernen:
- Sie können versuchen, verschiedene Datensätze zu verwenden, aber für dieses Modell werden Sie Graustufendatensätze brauchen. Ein solcher Datensatz ist FashionMNIST.
- Sie können mit verschiedenen Hyperparametern experimentieren und die beste Kombination von ihnen für das Modell herausfinden.
- Schließlich können Sie versuchen, Schichten hinzuzufügen oder zu entfernen, um deren Auswirkungen auf die Fähigkeiten des Modells zu untersuchen.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python