













Scikit Learn
 Scikit-Learn ist eine Machine-Learning-Bibliothek für Python. Es enthält mehrere Regressions-, Klassifikations- und Clustering-Algorithmen, darunter SVMs, Gradient Boosting, K-Means, Random Forests und DBSCAN. Es ist so konzipiert, dass es mit Python Numpy und SciPy funktioniert. Das Scikit-Learn-Projekt begann als Google Summer of Code (auch bekannt als GSoC) Projekt von David Cournapeau als scikits.learn. Es hat seinen Namen von „Scikit“, einer separaten Drittanbietererweiterung zu SciPy.
Scikit-Learn ist eine Machine-Learning-Bibliothek für Python. Es enthält mehrere Regressions-, Klassifikations- und Clustering-Algorithmen, darunter SVMs, Gradient Boosting, K-Means, Random Forests und DBSCAN. Es ist so konzipiert, dass es mit Python Numpy und SciPy funktioniert. Das Scikit-Learn-Projekt begann als Google Summer of Code (auch bekannt als GSoC) Projekt von David Cournapeau als scikits.learn. Es hat seinen Namen von „Scikit“, einer separaten Drittanbietererweiterung zu SciPy.
Python Scikit-learn
Scikit ist größtenteils in Python geschrieben, und einige seiner Kernalgorithmen sind in Cython geschrieben, um eine noch bessere Leistung zu erzielen. Scikit-Learn wird verwendet, um Modelle zu erstellen, und es wird nicht empfohlen, es zum Lesen, Manipulieren und Zusammenfassen von Daten zu verwenden, da es bessere Frameworks für diesen Zweck gibt. Es ist Open Source und unter der BSD-Lizenz veröffentlicht.
Scikit Learn installieren
Scikit geht davon aus, dass Sie eine laufende Python 2.7-Plattform oder höher mit den Paketen NumPY (1.8.2 und höher) und SciPY (0.13.3 und höher) auf Ihrem Gerät haben. Sobald diese Pakete installiert sind, können wir mit der Installation fortfahren. Für die pip-Installation führen Sie den folgenden Befehl im Terminal aus:
pip install scikit-learn
Wenn Sie conda bevorzugen, können Sie auch conda für die Paketinstallation verwenden. Führen Sie den folgenden Befehl aus:
conda install scikit-learn
Scikit-Learn verwenden
Nach Abschluss der Installation können Sie Scikit-Learn einfach in Ihrem Python-Code verwenden, indem Sie es importieren:
import sklearn
Scikit Learn Datensatz laden
Lassen Sie uns mit dem Laden eines Datensatzes beginnen, mit dem Sie arbeiten können. Laden wir einen einfachen Datensatz namens Iris. Es handelt sich um einen Datensatz einer Blume und enthält 150 Beobachtungen zu verschiedenen Messungen der Blume. Schauen wir uns an, wie man den Datensatz mit Scikit-Learn lädt.
# Importiere scikit-learn
from sklearn import datasets
# Lade Daten
iris= datasets.load_iris()
# Drucke die Form der Daten, um zu bestätigen, dass die Daten geladen sind
print(iris.data.shape)
Wir drucken die Form der Daten zur Vereinfachung aus. Du kannst auch die gesamten Daten ausdrucken, wenn du möchtest. Das Ausführen des Codes gibt eine Ausgabe wie folgt: 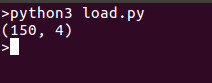
Scikit-Learn SVM – Lernen und Vorhersagen
Jetzt haben wir die Daten geladen, lassen uns versuchen, daraus zu lernen und Vorhersagen für neue Daten zu treffen. Dafür müssen wir einen Schätzer erstellen und dann seine Fit-Methode aufrufen.
from sklearn import svm
from sklearn import datasets
# Lade Datensatz
iris = datasets.load_iris()
clf = svm.LinearSVC()
# Lerne aus den Daten
clf.fit(iris.data, iris.target)
# Vorhersage für unbekannte Daten
clf.predict([[ 5.0, 3.6, 1.3, 0.25]])
# Die Parameter des Modells können durch die Verwendung von Attributen, die mit einem Unterstrich enden, geändert werden
print(clf.coef_ )
Hier ist das Ergebnis, wenn wir dieses Skript ausführen: 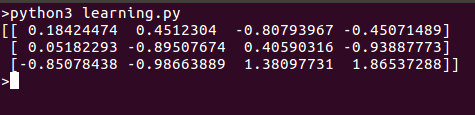
Scikit-Learn Lineare Regression
Das Erstellen verschiedener Modelle ist mit scikit-learn recht einfach. Fangen wir mit einem einfachen Beispiel für Regression an.
#import das Modell
from sklearn import linear_model
reg = linear_model.LinearRegression()
# verwenden Sie es, um Daten anzupassen
reg.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2])
# Schauen wir uns die angepassten Daten an
print(reg.coef_)
Das Ausführen des Modells sollte einen Punkt zurückgeben, der auf derselben Linie geplottet werden kann: 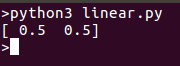
k-Nearest neighbour classifier
Lassen Sie uns einen einfachen Klassifikationsalgorithmus ausprobieren. Dieser Klassifikator verwendet einen Algorithmus auf der Basis von Ballbäumen, um die Trainingsbeispiele darzustellen.
from sklearn import datasets
# Datensatz laden
iris = datasets.load_iris()
# Einen k-NN-Klassifikator erstellen und anpassen
from sklearn import neighbors
knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target)
# Vorhersagen treffen und das Ergebnis ausgeben
result=knn.predict([[0.1, 0.2, 0.3, 0.4]])
print(result)
Lassen Sie uns den Klassifikator ausführen und die Ergebnisse überprüfen, der Klassifikator sollte 0 zurückgeben. Lassen Sie uns das Beispiel ausprobieren: 
K-means clustering
Dies ist der einfachste Clustering-Algorithmus. Die Menge wird in ‚k‘ Cluster unterteilt und jeder Beobachtung wird ein Cluster zugewiesen. Dies geschieht iterativ, bis die Cluster konvergieren. Wir werden ein solches Clustering-Modell im folgenden Programm erstellen:
from sklearn import cluster, datasets
# Daten laden
iris = datasets.load_iris()
# Cluster für k=3 erstellen
k=3
k_means = cluster.KMeans(k)
# Daten anpassen
k_means.fit(iris.data)
# Ergebnisse anzeigen
print( k_means.labels_[::10])
print( iris.target[::10])
Wenn wir das Programm ausführen, sehen wir separate Cluster in der Liste. Hier ist die Ausgabe für obigen Code-Schnipsel: 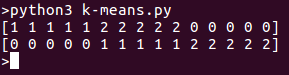
Schlussfolgerung
Im Tutorial haben wir gesehen, dass es mit Scikit-Learn einfach ist, mit mehreren maschinellen Lernalgorithmen zu arbeiten. Wir haben Beispiele für Regression, Klassifikation und Clustering gesehen. Scikit-Learn befindet sich noch in der Entwicklungsphase und wird von Freiwilligen entwickelt und gepflegt, ist jedoch in der Community sehr beliebt. Probieren Sie Ihre eigenen Beispiele aus.
Source:
https://www.digitalocean.com/community/tutorials/python-scikit-learn-tutorial