













Python Pandas Modul
- Pandas ist eine Open-Source-Bibliothek in Python. Es bietet sofort einsatzbereite, leistungsstarke Datenstrukturen und Tools zur Datenanalyse.
- Das Pandas-Modul läuft auf Basis von NumPy und wird häufig für Data Science und Datenanalyse verwendet.
- NumPy ist eine Low-Level-Datenstruktur, die mehrdimensionale Arrays und eine Vielzahl mathematischer Arrayoperationen unterstützt. Pandas bietet eine höhere Schnittstelle. Es bietet auch eine optimierte Ausrichtung tabellarischer Daten und leistungsstarke Funktionen für Zeitreihen.
- DataFrame ist die Schlüssel-Datenstruktur in Pandas. Es ermöglicht uns, tabellarische Daten als 2-D-Datenstruktur zu speichern und zu manipulieren.
- Pandas bietet einen umfangreichen Funktionsumfang für den DataFrame. Zum Beispiel Datenabgleich, Datenstatistiken, Slicing, Gruppierung, Zusammenführen, Verknüpfen von Daten usw.
Installation und Einstieg in Pandas
Sie benötigen Python 2.7 und höher, um das Pandas-Modul zu installieren. Wenn Sie conda verwenden, können Sie es mit dem folgenden Befehl installieren.
conda install pandas
Wenn Sie PIP verwenden, führen Sie den folgenden Befehl aus, um das Pandas-Modul zu installieren.
pip3.7 install pandas
Um Pandas und NumPy in Ihr Python-Skript zu importieren, fügen Sie den folgenden Code hinzu:
import pandas as pd
import numpy as np
Da Pandas von der NumPy-Bibliothek abhängt, müssen wir diese Abhängigkeit importieren.
Datenstrukturen im Pandas-Modul
Das Pandas-Modul bietet 3 Datenstrukturen, die wie folgt sind:
- Series: Es ist eine 1-D-Größe-unveränderliche Array-ähnliche Struktur mit homogenen Daten.
- DataFrames: Es ist eine 2-D-Größe-veränderliche tabellarische Struktur mit heterogen getypten Spalten.
- Panel: Es ist ein 3-D, Größe-veränderliches Array.
Pandas DataFrame
DataFrame ist die wichtigste und weit verbreitete Datenstruktur und ist eine Standardmethode zum Speichern von Daten. DataFrame hat Daten in Zeilen und Spalten ausgerichtet, ähnlich wie eine SQL-Tabelle oder eine Tabellenkalkulationsdatenbank. Wir können entweder Daten in einen DataFrame einfügen oder eine CSV-Datei, tsv-Datei, Excel-Datei, SQL-Tabelle usw. importieren. Wir können den folgenden Konstruktor verwenden, um ein DataFrame-Objekt zu erstellen.
pandas.DataFrame(data, index, columns, dtype, copy)
Hier ist eine kurze Beschreibung der Parameter:
- Daten – erstellt ein DataFrame-Objekt aus den Eingabedaten. Es kann eine Liste, ein Dictionary, eine Serie, Numpy-Arrays oder sogar ein anderes DataFrame sein.
- Index – enthält die Zeilenbeschriftungen
- Spalten – werden verwendet, um Spaltenbeschriftungen zu erstellen
- Datentyp – wird verwendet, um den Datentyp jeder Spalte anzugeben, optionales Parameter
- Kopieren – wird verwendet, um Daten zu kopieren, falls vorhanden
Es gibt viele Möglichkeiten, ein DataFrame zu erstellen. Wir können ein DataFrame-Objekt aus Wörterbüchern oder einer Liste von Wörterbüchern erstellen. Es kann auch aus einer Liste von Tupeln, CSV, Excel-Datei usw. erstellt werden. Lassen Sie uns einen einfachen Code ausführen, um ein DataFrame aus der Liste von Wörterbüchern zu erstellen.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Ausgabe:  Der erste Schritt besteht darin, ein Wörterbuch zu erstellen. Der zweite Schritt besteht darin, das Wörterbuch als Argument in die Methode DataFrame() zu übergeben. Der letzte Schritt besteht darin, das DataFrame zu drucken. Wie Sie sehen, kann das DataFrame mit einer Tabelle verglichen werden, die heterogene Werte hat. Auch die Größe des DataFrames kann geändert werden. Wir haben die Daten in Form der Map geliefert, und die Schlüssel der Map werden von Pandas als Zeilenbeschriftungen betrachtet. Der Index wird in der linken Spalte angezeigt und enthält die Zeilenbeschriftungen. Die Spaltenüberschrift und die Daten werden tabellarisch angezeigt. Es ist auch möglich, indizierte DataFrames zu erstellen. Dies kann durch Konfigurieren des Indexparameters in der Methode
Der erste Schritt besteht darin, ein Wörterbuch zu erstellen. Der zweite Schritt besteht darin, das Wörterbuch als Argument in die Methode DataFrame() zu übergeben. Der letzte Schritt besteht darin, das DataFrame zu drucken. Wie Sie sehen, kann das DataFrame mit einer Tabelle verglichen werden, die heterogene Werte hat. Auch die Größe des DataFrames kann geändert werden. Wir haben die Daten in Form der Map geliefert, und die Schlüssel der Map werden von Pandas als Zeilenbeschriftungen betrachtet. Der Index wird in der linken Spalte angezeigt und enthält die Zeilenbeschriftungen. Die Spaltenüberschrift und die Daten werden tabellarisch angezeigt. Es ist auch möglich, indizierte DataFrames zu erstellen. Dies kann durch Konfigurieren des Indexparameters in der Methode DataFrame() erfolgen.
Importieren von Daten aus CSV in DataFrame
Wir können auch einen DataFrame erstellen, indem wir eine CSV-Datei importieren. Eine CSV-Datei ist eine Textdatei mit einem Datensatz pro Zeile. Die Werte innerhalb des Datensatzes sind durch das Zeichen „Komma“ getrennt. Pandas bietet eine nützliche Methode namens read_csv(), um den Inhalt der CSV-Datei in einen DataFrame zu lesen. Zum Beispiel können wir eine Datei namens ‚cities.csv‘ erstellen, die Details zu indischen Städten enthält. Die CSV-Datei wird im gleichen Verzeichnis wie die Python-Skripte gespeichert. Diese Datei kann importiert werden mit:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Unser Ziel ist es, Daten zu laden und zu analysieren, um Schlussfolgerungen zu ziehen. Daher können wir eine beliebige geeignete Methode verwenden, um die Daten zu laden. In diesem Tutorial codieren wir die Daten des DataFrames direkt.
Daten im DataFrame inspizieren
Die Ausführung des DataFrame unter Verwendung seines Namens zeigt die gesamte Tabelle an. In Echtzeit werden die zu analysierenden Datensätze Tausende von Zeilen haben. Um Daten zu analysieren, müssen wir Daten aus großen Datenmengen inspizieren. Pandas bietet viele nützliche Funktionen, um nur die Daten zu inspizieren, die wir benötigen. Wir können df.head(n) verwenden, um die ersten n Zeilen zu erhalten, oder df.tail(n), um die letzten n Zeilen auszugeben. Zum Beispiel druckt der folgende Code die ersten 2 Zeilen und die letzte 1 Zeile des DataFrames.
print(df.head(2))
Output: 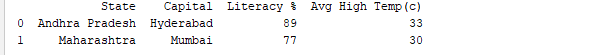
print(df.tail(1))
Output: 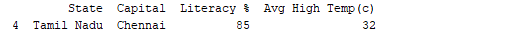 Ebenso gibt
Ebenso gibt print(df.dtypes) die Datentypen aus. Ausgabe: 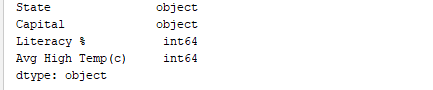
print(df.index) gibt den Index aus. Ausgabe: 
print(df.columns) gibt die Spalten des DataFrames aus. Ausgabe: 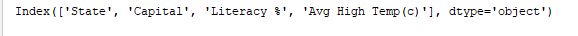
print(df.values) zeigt die Tabellenwerte an. Ausgabe: 
1. Statistische Zusammenfassung der Datensätze
Wir können eine statistische Zusammenfassung (Anzahl, Mittelwert, Standardabweichung, Minimum, Maximum usw.) der Daten mithilfe der Funktion df.describe() erhalten. Jetzt verwenden wir diese Funktion, um die statistische Zusammenfassung der Spalte „Alphabetisierung %“ anzuzeigen. Dazu können wir den folgenden Code hinzufügen:
print(df['Literacy %'].describe())
Ausgabe: 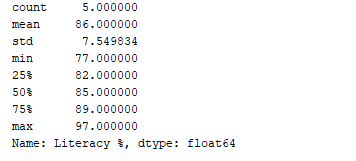 Die Funktion
Die Funktion df.describe() zeigt die statistische Zusammenfassung zusammen mit dem Datentyp an.
2. Datensätze sortieren
Wir können Datensätze nach jeder Spalte mit der Funktion df.sort_values() sortieren. Zum Beispiel sortieren wir die Spalte „Alphabetisierung %“ in absteigender Reihenfolge.
print(df.sort_values('Literacy %', ascending=False))
Ausgabe: 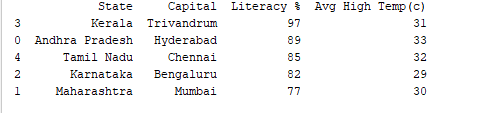
3. Datensätze ausschneiden
Es ist möglich, Daten einer bestimmten Spalte durch Verwendung des Spaltennamens zu extrahieren. Zum Beispiel verwenden wir
df['Capital']
oder
(df.Capital)
Ausgabe:  Es ist auch möglich, mehrere Spalten zu schneiden. Dies wird durch das Einschließen mehrerer Spaltennamen in 2 eckigen Klammern erreicht, wobei die Spaltennamen durch Kommas getrennt sind. Der folgende Code schneidet die Spalten ‚State‘ und ‚Capital‘ des DataFrame.
Es ist auch möglich, mehrere Spalten zu schneiden. Dies wird durch das Einschließen mehrerer Spaltennamen in 2 eckigen Klammern erreicht, wobei die Spaltennamen durch Kommas getrennt sind. Der folgende Code schneidet die Spalten ‚State‘ und ‚Capital‘ des DataFrame.
print(df[['State', 'Capital']])
Ausgabe:  Es ist auch möglich, Zeilen zu schneiden. Mehrere Zeilen können mit dem Operator „:“ ausgewählt werden. Der folgende Code gibt die ersten 3 Zeilen zurück.
Es ist auch möglich, Zeilen zu schneiden. Mehrere Zeilen können mit dem Operator „:“ ausgewählt werden. Der folgende Code gibt die ersten 3 Zeilen zurück.
df[0:3]
Ausgabe:  Ein interessantes Merkmal der Pandas-Bibliothek ist die Auswahl von Daten basierend auf ihren Zeilen- und Spaltenbezeichnungen mit der Funktion
Ein interessantes Merkmal der Pandas-Bibliothek ist die Auswahl von Daten basierend auf ihren Zeilen- und Spaltenbezeichnungen mit der Funktion iloc[0]. Oft benötigen wir nur wenige Spalten zur Analyse. Wir können auch nach Index auswählen, indem wir loc['index_one']) verwenden. Zum Beispiel können wir die zweite Zeile auswählen, indem wir df.iloc[1,:] verwenden. Angenommen, wir müssen das zweite Element der zweiten Spalte auswählen. Dies kann durch Verwendung der Funktion df.iloc[1,1] erfolgen. In diesem Beispiel zeigt die Funktion df.iloc[1,1] „Mumbai“ als Ausgabe an.
4. Daten filtern
Es ist auch möglich, nach Spaltenwerten zu filtern. Zum Beispiel filtert der folgende Code die Spalten mit einer Alphabetisierungsrate über 90%.
print(df[df['Literacy %']>90])
Jeder Vergleichsoperator kann verwendet werden, um basierend auf einer Bedingung zu filtern. Ausgabe:  Eine weitere Möglichkeit, Daten zu filtern, ist die Verwendung von
Eine weitere Möglichkeit, Daten zu filtern, ist die Verwendung von isin. Hier ist der Code, um nur 2 Bundesländer ‚Karnataka‘ und ‚Tamil Nadu‘ zu filtern.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Ausgabe: 
5. Spalte umbenennen
Es ist möglich, die Funktion df.rename() zu verwenden, um eine Spalte umzubenennen. Die Funktion nimmt den alten Spaltennamen und den neuen Spaltennamen als Argumente. Zum Beispiel, lassen Sie uns die Spalte ‚Literalität%‘ in ‚Literalitätsprozentsatz‘ umbenennen.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
Das Argument `inplace=True` führt die Änderungen am DataFrame durch. Ausgabe: 
6. Datenbearbeitung
Data Science beinhaltet die Verarbeitung von Daten, damit die Daten gut mit den Datenalgorithmen funktionieren können. Data Wrangling ist der Prozess der Datenverarbeitung, wie das Zusammenführen, Gruppieren und Verketten. Die Pandas-Bibliothek stellt nützliche Funktionen wie merge(), groupby() und concat() zur Unterstützung von Data Wrangling-Aufgaben bereit. Lassen Sie uns 2 DataFrames erstellen und die Data Wrangling-Funktionen anzeigen, um sie besser zu verstehen.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Ausgabe:  Lassen Sie uns das zweite DataFrame mit dem folgenden Code erstellen:
Lassen Sie uns das zweite DataFrame mit dem folgenden Code erstellen:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Ausgabe: 
a. Merging
Jetzt fusionieren wir die 2 erstellten DataFrames entlang der Werte von ‚Employee_id‘ mithilfe der Funktion merge():
print(pd.merge(df1, df2, on='Employee_id'))
Ausgabe:  Wir können sehen, dass die merge()-Funktion die Zeilen aus beiden DataFrames zurückgibt, die denselben Spaltenwert haben, der beim Zusammenführen verwendet wurde.
Wir können sehen, dass die merge()-Funktion die Zeilen aus beiden DataFrames zurückgibt, die denselben Spaltenwert haben, der beim Zusammenführen verwendet wurde.
b. Grouping
Gruppierung ist ein Prozess des Sammelns von Daten in verschiedene Kategorien. Zum Beispiel hat das Feld „Employee_Name“ im folgenden Beispiel den Namen „Meera“ zweimal. Lassen Sie uns es nach der Spalte „Employee_name“ gruppieren.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Das Feld ‚Employee_name‘ mit dem Wert ‚Meera‘ wird nach der Spalte „Employee_name“ gruppiert. Die Beispielausgabe lautet wie folgt: Ausgabe: 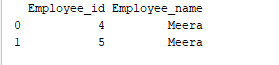
c. Concatenating
Concatenieren von Daten beinhaltet das Hinzufügen eines Datensatzes zu einem anderen. Pandas bietet eine Funktion namens concat() zum Zusammenführen von DataFrames. Zum Beispiel, lassen Sie uns die DataFrames df1 und df2 zusammenführen, indem wir verwenden:
print(pd.concat([df1, df2]))
Ergebnis: 
Erstellen eines DataFrame durch Übergeben eines Dictionarys von Serien
Um eine Serie zu erstellen, können wir die Methode pd.Series() verwenden und ihr ein Array übergeben. Lassen Sie uns eine einfache Serie wie folgt erstellen:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Ergebnis:  Wir haben eine Serie erstellt. Sie können sehen, dass 2 Spalten angezeigt werden. Die erste Spalte enthält die Indexwerte, die von 0 beginnen. Die zweite Spalte enthält die als Serie übergebenen Elemente. Es ist möglich, einen DataFrame zu erstellen, indem man ein Dictionary von `Series` übergibt. Lassen Sie uns einen DataFrame erstellen, der durch Vereinigung und Übergeben der Indizes der Serie gebildet wird. Beispiel
Wir haben eine Serie erstellt. Sie können sehen, dass 2 Spalten angezeigt werden. Die erste Spalte enthält die Indexwerte, die von 0 beginnen. Die zweite Spalte enthält die als Serie übergebenen Elemente. Es ist möglich, einen DataFrame zu erstellen, indem man ein Dictionary von `Series` übergibt. Lassen Sie uns einen DataFrame erstellen, der durch Vereinigung und Übergeben der Indizes der Serie gebildet wird. Beispiel
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Beispielausgabe 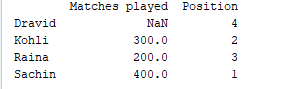 Für Serie eins wird, da wir das Label ‚d‘ nicht angegeben haben, NaN zurückgegeben.
Für Serie eins wird, da wir das Label ‚d‘ nicht angegeben haben, NaN zurückgegeben.
Auswahl, Hinzufügen, Löschen von Spalten
Es ist möglich, eine bestimmte Spalte aus dem DataFrame auszuwählen. Zum Beispiel können wir nur die erste Spalte anzeigen, indem wir den obigen Code wie folgt umschreiben:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
Der obige Code gibt nur die Spalte „Spiele gespielt“ des DataFrame aus. Ausgabe 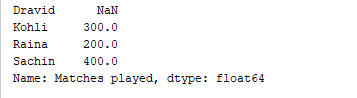 Es ist auch möglich, Spalten einem vorhandenen DataFrame hinzuzufügen. Zum Beispiel fügt der folgende Code eine neue Spalte namens „Runrate“ zum obigen DataFrame hinzu.
Es ist auch möglich, Spalten einem vorhandenen DataFrame hinzuzufügen. Zum Beispiel fügt der folgende Code eine neue Spalte namens „Runrate“ zum obigen DataFrame hinzu.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Ausgabe:  Wir können Spalten mithilfe der Funktionen `delete` und `pop` löschen. Zum Beispiel können wir die Spalte „Spiele gespielt“ im obigen Beispiel auf eine der folgenden beiden Arten löschen:
Wir können Spalten mithilfe der Funktionen `delete` und `pop` löschen. Zum Beispiel können wir die Spalte „Spiele gespielt“ im obigen Beispiel auf eine der folgenden beiden Arten löschen:
del df['Matches played']
oder
df.pop('Matches played')
Ausgabe: 
Fazit
Im diesem Tutorial hatten wir eine kurze Einführung in die Python Pandas-Bibliothek. Wir haben auch praktische Beispiele durchgeführt, um die Leistung der Pandas-Bibliothek zu entfesseln, die im Bereich der Datenwissenschaft verwendet wird. Außerdem haben wir die verschiedenen Datenstrukturen in der Python-Bibliothek durchgegangen. Referenz: Pandas Offizielle Webseite
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial