













يعد Grafana Loki نظام تجميع سجلات قابل للتوسيع أفقيًا وذو توافرية عالية. تم تصميمه ليكون بسيطًا وفعالًا من حيث التكلفة. تم إنشاؤه بواسطة شركة Grafana Labs في عام 2018، وقد ظهر Loki بسرعة كبديل مقنع لأنظمة تسجيل السجلات التقليدية، خاصة لبيئات السحابة و Kubernetes.
يمكن لـ Loki توفير رحلة سجل شاملة. يمكننا تحديد تيارات السجلات الصحيحة ومن ثم تصفية التركيز على السجلات ذات الصلة. يمكننا بعد ذلك تحليل البيانات المهيكلة لتنسيقها وفقًا لاحتياجات تحليلنا المخصصة. يمكن أيضًا تحويل السجلات بشكل مناسب للعرض، على سبيل المثال، أو معالجة الأنابيب بشكل أكثر تقدمًا.
يتكامل Loki بسلاسة مع النظام البيئي الأوسع لـ Grafana. يمكن للمستخدمين استعلام السجلات باستخدام LogQL – لغة استعلام تم تصميمها بشكل متعمد لتشابه لغة PromQL في Prometheus. يوفر ذلك تجربة مألوفة للمستخدمين الذين يعملون بالفعل مع مقاييس Prometheus ويمكنهم بذلك التحقق من الترابط القوي بين المقاييس والسجلات داخل لوحات التحكم الخاصة بـ Grafana.
يبدأ هذا المقال بمفاهيم Loki، تليها نظرة عامة أساسية على الهندسة المعمارية. تليها أساسيات LogQL، ونختتم بالتناقضات المتضمنة.
أساسيات Loki
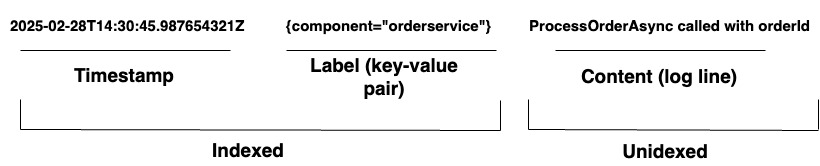
للمؤسسات التي تدير أنظمة معقدة، يوفر “لوكي” حلاً موحدًا لتسجيل الأحداث. يدعم تلقي السجلات من أي مصدر من خلال مجموعة واسعة من الوكلاء أو واجهة برمجة التطبيقات الخاصة به، مضمنًا تغطية شاملة لمجموعة متنوعة من الأجهزة والبرامج. يقوم “لوكي” بتخزين سجلاته كتيارات سجلات، كما هو موضح في الرسم البياني رقم ١. كل إدخال يحتوي على:
- الـطابع زمني بدقة النانوثانية
- أزواج القيم المسماة بـالعلامات تُستخدم للبحث عن السجلات. توفر العلامات البيانات الوصفية لسطر السجل. يتم استخدامها لتحديد واسترداد البيانات. تشكل الفهرس لتيارات السجلات وتنظم تخزين السجلات. كل تركيبة فريدة من العلامات وقيمها تعرف تيار سجل مميز. تُجمع وتُضغط وتُخزن إدخالات السجل ضمن تيار.
- الـمحتوى السجل الفعلي. هذا هو سطر السجل الخام. لا يتم فهرسة ويتم تخزينه في شظايا مضغوطة.
البنية
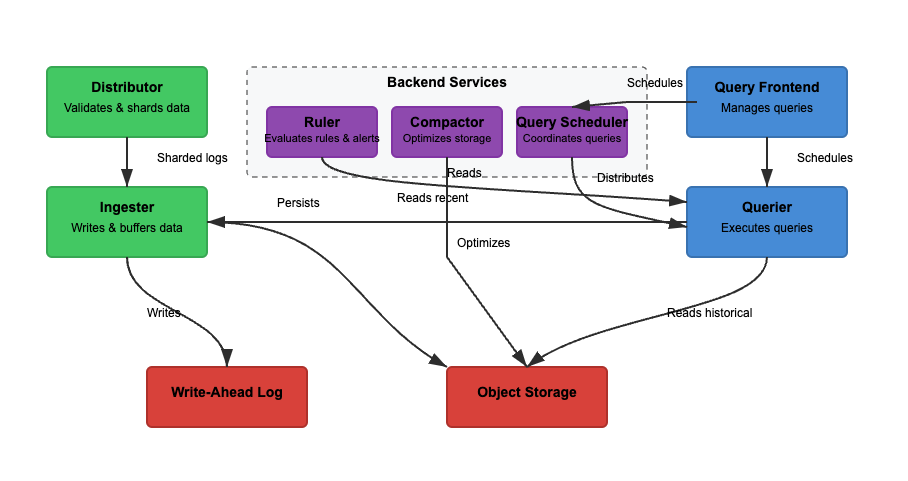
سنحلل بنية “لوكي” استنادًا إلى ثلاث ميزات أساسية. القراءة، الكتابة، وتخزين السجلات. يمكن لـ “لوكي” أن يعمل في وضع موحد (ثنائي النظام) أو وضع الخدمات المصغرة، حيث يتم فصل المكونات للتوسيع المستقل. يمكن توسيع وظيفة القراءة والكتابة بشكل مستقل لتناسب حالات الاستخدام الخاصة. دعونا ننظر في كل مسار بمزيد من التفصيل.
الكتابة
في الرسم البياني 2، مسار الكتابة هو المسار الأخضر. عند دخول السجلات إلى لوكي، يقوم الموزع بتجزئة السجلات بناءً على التسميات. ثم يقوم المُدخِل بتخزين السجلات في الذاكرة، ويعمل المُجمع على تحسين التخزين. الخطوات الرئيسية المعنية هي كما يلي.
الخطوة 1: دخول السجلات إلى لوكي
تصل الكتابات للسجلات الواردة إلى الموزع. يتم هيكلة السجلات كسلاسل، مع تسميات (مثل {job="nginx", level="error"}). يقوم الموزع بتجزئة السجلات، وتقسيم السجلات، وإرسال السجلات إلى المدخلات. يقوم بتجزئة تسميات كل سلسلة ويعينها إلى مُدخِل باستخدام التجزئة المتسقة. يتحقق الموزعون من صحة السجلات ويمنعون البيانات غير الصحيحة. يمكن أن تضمن التجزئة المتسقة توزيع السجلات بشكل عادل عبر المدخلات.
الخطوة 2: التخزين قصير الأمد
يقوم المدخل بتخزين السجلات في الذاكرة لاسترجاع سريع. يتم تجميع السجلات وكتابتها في سجلات الكتابة المسبقة (WAL) لمنع فقدان البيانات. تساعد سجلات الكتابة المسبقة في المتانة لكنها ليست قابلة للاستعلام مباشرة – لا يزال يجب على المدخلات البقاء متصلة للبحث في السجلات الحديثة.
بشكل دوري، تُفرغ السجلات من المدخلات إلى تخزين الكائنات. يقرأ المستفسر والقائد المدخل للوصول إلى البيانات الأكثر حداثة. يمكن للمستفسر أيضًا الوصول إلى بيانات تخزين الكائنات.
الخطوة 3: انتقال السجلات إلى التخزين طويل الأمد
يقوم المدمج دوريًا بمعالجة السجلات المخزنة من التخزين طويل الأجل (object-storage). تعتبر تخزين الكائنات رخيصة وقابلة للتوسيع. يسمح لوكي بتخزين كميات ضخمة من السجلات دون تكاليف عالية. يقوم المدمج بإزالة السجلات المتكررة وضغط السجلات لزيادة كفاءة التخزين، وحذف السجلات القديمة استنادًا إلى إعدادات الاحتفاظ. يتم تخزين السجلات بتنسيق مجزأ (غير مفهرس بالنص الكامل).
القراءة
في الرسم التخطيطي رقم 2، المسار الأزرق هو مسار القراءة. تذهب الاستعلامات إلى واجهة الاستعلام، والمستعلم يسترد السجلات. يتم تصفية السجلات وتحليلها باستخدام LogQL. الخطوات الرئيسية المعنية هي كالتالي.
الخطوة 1: واجهة الاستعلام تحسن الطلبات
يستعلم المستخدمون عن السجلات باستخدام LogQL في Grafana. تقسم واجهة الاستعلام الاستعلامات الكبيرة إلى شظايا صغيرة وتوزعها عبر عدة مستعلمين نظرًا لأن التنفيذ المتوازي يسرع الاستعلامات. إنها مسؤولة عن تسريع تنفيذ الاستعلام وضمان إعادة المحاولات في حالة الفشل. تساعد واجهة الاستعلام في تجنب مهلات الانتظار والأعباء الزائدة، بينما يتم إعادة محاولة الاستعلامات التي فشلت تلقائيًا.
الخطوة 2: المستعلم يسترد السجلات
يحلل المستعلمون LogQL ويستعلمون المحققين وتخزين الكائنات. يتم استرداد السجلات الحديثة من المحققين، ويتم استرداد السجلات القديمة من تخزين الكائنات. يتم إزالة السجلات ذات الطابع الزمني والعلامات والمحتوى نفسه.
تُستخدم مرشحات بلوم وعلامات الفهرس للعثور على السجلات بكفاءة. تعمل الاستعلامات التجميعية، مثل count_over_time() بشكل أسرع لأن لوكي لا تفهرس السجلات بالكامل. على عكس إليستيكسيرتش، لوكي لا يفهرس محتوى السجل بالكامل.
بدلاً من ذلك، يقوم بفهرسة علامات البيانات الوصفية ({app="nginx", level="error"})، مما يساعد على العثور على السجلات بكفاءة وبتكلفة منخفضة. يتم إجراء عمليات البحث النصي الكامل فقط على شظايا السجل ذات الصلة، مما يقلل من تكاليف التخزين.
أساسيات LogQL
LogQL هي لغة الاستعلام المستخدمة في Grafana Loki للبحث وتصفية وتحويل السجلات بكفاءة. تتكون من مكونين أساسيين:
- محدد التيار – يختار تيارات السجلات بناءً على مطابقات العلامات
- التصفية والتحويل – يستخرج أسطر السجل ذات الصلة، ويحلل البيانات المنظمة، وينسق نتائج الاستعلام
من خلال دمج هذه الميزات، يتيح LogQL للمستخدمين استرداد السجلات بكفاءة، واستخراج الأفكار، وإنشاء مقاييس مفيدة من بيانات السجل.
محدد التيار
محدد التيار هو الخطوة الأولى في كل استعلام LogQL. يختار تيارات السجلات بناءً على مطابقات العلامات. يمكننا استخدام العمليات الأساسية لتصفية حسب علامات Loki وبالتالي تحسين دقة اختيار تيارات السجل الخاصة بنا لتقليل حجم التيارات المفحوصة، وبالتالي زيادة سرعة الاستعلام.
أمثلة
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobمرشحات الأسطر
بمجرد اختيار السجلات، تقوم مرشحات الأسطر بتحسين النتائج من خلال البحث عن نص محدد أو تطبيق شروط منطقية. تعمل مرشحات الأسطر على محتوى السجل، وليس العلامات.
أمثلة
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)محللون
يمكن لـ Loki قبول السجلات غير المهيكلة أو شبه المهيكلة أو المهيكلة. ومع ذلك، فإن فهم تنسيقات السجلات التي نعمل بها أمر حاسم عند تصميم وبناء حلول الرؤية. بهذه الطريقة، يمكننا استيعاب بيانات السجلات، وتخزينها، وتحليلها لاستخدامها بفعالية. يدعم Loki محللات JSON و logfmt و pattern و regexp و unpack.
أمثلة
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesتصفية العلامات
بمجرد تحليلها، يمكن تصفية السجلات حسب الحقول المستخرجة. يمكن استخراج العلامات كجزء من خط السجل باستخدام تعابير المحلل والمنسق. يمكن بعد ذلك استخدام تعبير تصفية العلامة لتصفية سطر السجل الخاص بنا باستخدام إحدى هذه العلامات.
أمثلة
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminتنسيق السطر
يستخدم لتعديل إخراج السجل عن طريق استخراج الحقول وتنسيقها. يحدد هذا كيفية عرض السجلات في Grafana.
مثال
{app="nginx"} | json | line_format "User {user} encountered {status} error"تنسيق العلامة
يستخدم لإعادة تسمية أو تعديل أو إنشاء أو إسقاط العلامات. يقبل قائمة مفصولة بفاصلة من عمليات المساواة، مما يسمح بإجراء عمليات متعددة في نفس الوقت.
أمثلة
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level التضحيات
Grafana Loki يقدم حلاً لتسجيل السجلات فعال من حيث التكلفة ويمكن توسيعه، يخزن السجلات في قطع مضغوطة مع فهرسة دنيا. يأتي هذا مع تضحيات في أداء الاستعلام وسرعة الاسترداد. على عكس أنظمة إدارة السجلات التقليدية التي تفهرس المحتوى الكامل للسجل، فإن التفهرس القائم على العلامات في Loki يسرع عملية التصفية.
ومع ذلك، قد يبطئ الأمر بحث النصوص المعقدة. بالإضافة إلى ذلك، على الرغم من أن لوكي متميز في التعامل مع بيئات عالية الإنتاجية والموزعة، إلا أنه يعتمد على تخزين الكائنات للتوسع. يمكن أن يؤدي هذا إلى زيادة التأخير ويتطلب اختيار العلامات بعناية لتجنب مشاكل القائمة الكبيرة.
التوسعية والتعددية
صمم لوكي للتوسع والتعددية. ومع ذلك، تأتي التوسعية مع تنازلات معمارية. يمكن توسيع الكتابات (المدخلون) بسهولة بسبب القدرة على تجزئة السجلات استنادًا إلى التقسيم بناءً على العلامات. يعتبر توسيع القراءات (المستعلمون) أمرًا أكثر صعوبة لأن الاستعلام عن مجموعات بيانات كبيرة من تخزين الكائنات يمكن أن يكون بطيئًا. يتم دعم التعددية، ولكن يتطلب إدارة الحصص الخاصة بالمستأجر، وانفجار العلامات، والأمان (عزل البيانات حسب المستأجر) تكوينًا دقيقًا.
الاستيعاب البسيط بدون تحليل مسبق
لا يتطلب لوكي تحليلاً مسبقًا لأنه لا يفهرس محتوى السجل الكامل. يخزن السجلات في تنسيق غير معالج بشكل مضغوط. نظرًا لعدم توفر لوكي لفهرسة النصوص الكاملة، يتطلب استعلام السجلات المهيكلة (على سبيل المثال، JSON) تحليل LogQL. وهذا يعني أن أداء الاستعلام يعتمد على كيفية تهيئة السجلات بشكل جيد قبل الاستيعاب. بدون توفر السجلات المهيكلة، يعاني كفاءة الاستعلام لأن عملية التصفية يجب أن تحدث في وقت الاسترجاع، وليس في وقت الاستيعاب.
التخزين في مستودع الكائنات
يفرغ لوكي شظايا السجلات إلى تخزين الكائنات (على سبيل المثال، S3، GCS، Azure Blob). وهذا يقلل من الاعتماد على تخزين الكتل المكلف مثلما يتطلب Elasticsearch، على سبيل المثال.
ومع ذلك، يمكن أن تكون قراءة السجلات من تخزين الكائنات بطيئة مقارنة بالاستعلام مباشرة من قاعدة بيانات. يعوض لوكي ذلك من خلال الاحتفاظ بالسجلات الأخيرة في مدمجات لاسترجاع أسرع. يقلل التضغيط من التكلفة الزائدة للتخزين، ولكن يمكن أن يكون تأخر استرجاع السجلات مشكلة للاستعلامات على نطاق واسع.
العلامات والتعداد
نظرًا لأن العلامات تُستخدم للبحث عن السجلات، فهي حرجة للاستعلامات الفعالة. يمكن أن تؤدي التسمية السيئة إلى مشاكل في التعداد العالي. استخدام العلامات ذات التعداد العالي (على سبيل المثال، user_id، session_id) يزيد من استخدام الذاكرة ويبطئ الاستعلامات. يقوم لوكي بتجزئة العلامات لتوزيع السجلات عبر المدمجات، لذا يمكن أن يسبب تصميم العلامة السيء توزيعًا غير متساوي للسجلات.
التصفية المبكرة
نظرًا لأن لوكي يخزن السجلات الخام المضغوطة في تخزين الكائنات، فمن المهم تصفية بشكل مبكر إذا كنا نريد أن تكون استعلاماتنا سريعة. سيزيد معالجة التحليل المعقد على مجموعات بيانات أصغر من وقت الاستجابة. ووفقًا لهذه القاعدة، يكون الاستعلام الجيد هو الاستعلام 1، والاستعلام السيء هو الاستعلام 2.
الاستعلام 1
{job="nginx", status_code=~"5.."} | jsonالاستعلام 1 يقوم بتصفية السجلات حيث job="nginx" وحالة الرمز status_code تبدأ برقم 5 (أخطاء 500-599). ثم، يستخرج الحقول المنظمة JSON باستخدام | json. وهذا يقلل من عدد السجلات التي يتم معالجتها بواسطة محلل JSON، مما يجعله أسرع.
الاستعلام 2
{job="nginx"} | json | status_code=~"5.."الاستعلام 2 يسترد أولاً جميع السجلات من nginx. ويمكن أن يكون هذا ملايين الإدخالات. ثم، يحلل JSON لكل إدخال سجل فردي قبل التصفية بواسطة status_code. وهذا غير فعال وأبطأ بشكل كبير.
الختام
غرفانا لوكي هو نظام قوي وفعال من حيث التكلفة لتجميع السجلات مصمم للتوسع والسهولة. من خلال فهرسة البيانات الوصفية فقط، يحافظ على انخفاض تكاليف التخزين بينما يمكّن من استعلامات سريعة باستخدام LogQL.
يدعم هيكل الخدمات المصغرة الخاص به نشرات مرنة، مما يجعله مثاليًا للبيئات السحابية الأصلية. تناولت هذه المقالة أساسيات لوكي ولغته للاستعلام. من خلال التنقل عبر الميزات البارزة لهيكل لوكي، يمكننا الحصول على فهم أفضل للمقايضات المعنية.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture