













في 11 ديسمبر 2024، تعرضت خدمات OpenAI لفترات توقف كبيرة بسبب مشكلة ناتجة عن نشر خدمة جديدة للتلميتري. تأثرت هذه الحادثة بخدمات API وChatGPT وSora، مما أدى إلى اضطرابات في الخدمة استمرت لساعات عدة. كشركة تهدف إلى توفير حلول ذكية وفعالة، قامت OpenAI بمشاركة تقرير مفصل بعد الحادث لمناقشة بصفافة ما حدث وكيف يخططون لمنع حوادث مماثلة في المستقبل.
في هذه المقالة، سأصف الجوانب التقنية للحادث، وأفصل أسباب الجذر، وأستكشف الدروس الرئيسية التي يمكن للمطورين والمؤسسات التي تدير أنظمة موزعة أن تستفيد من هذا الحدث.
جدول الحادث
إليك لمحة عن كيف تطورت الأحداث في 11 ديسمبر 2024:
| Time (PST) | Event |
|---|---|
| 3:16 مساءً |
بدأ التأثير الطفيف على العملاء؛ لاحظ تدهور الخدمة |
| 3:27 مساءً | بدأ المهندسون بتوجيه حركة المرور من العناقيد المتأثرة |
| 3:40 مساءً | سُجل أقصى تأثير على العملاء؛ انقطاع كبير على جميع الخدمات |
| 4:36 مساءً | بدأت العناقيد الأولى لـ Kubernetes في الاسترداد |
| 5:36 مساءً | بدأت الاسترداد الكبير لخدمات API |
| 5:45 مساءً | لوحظ الاسترداد الكبير لـ ChatGPT |
| 7:38 مساءً | تم استعادة جميع الخدمات بالكامل عبر جميع العناقيد |
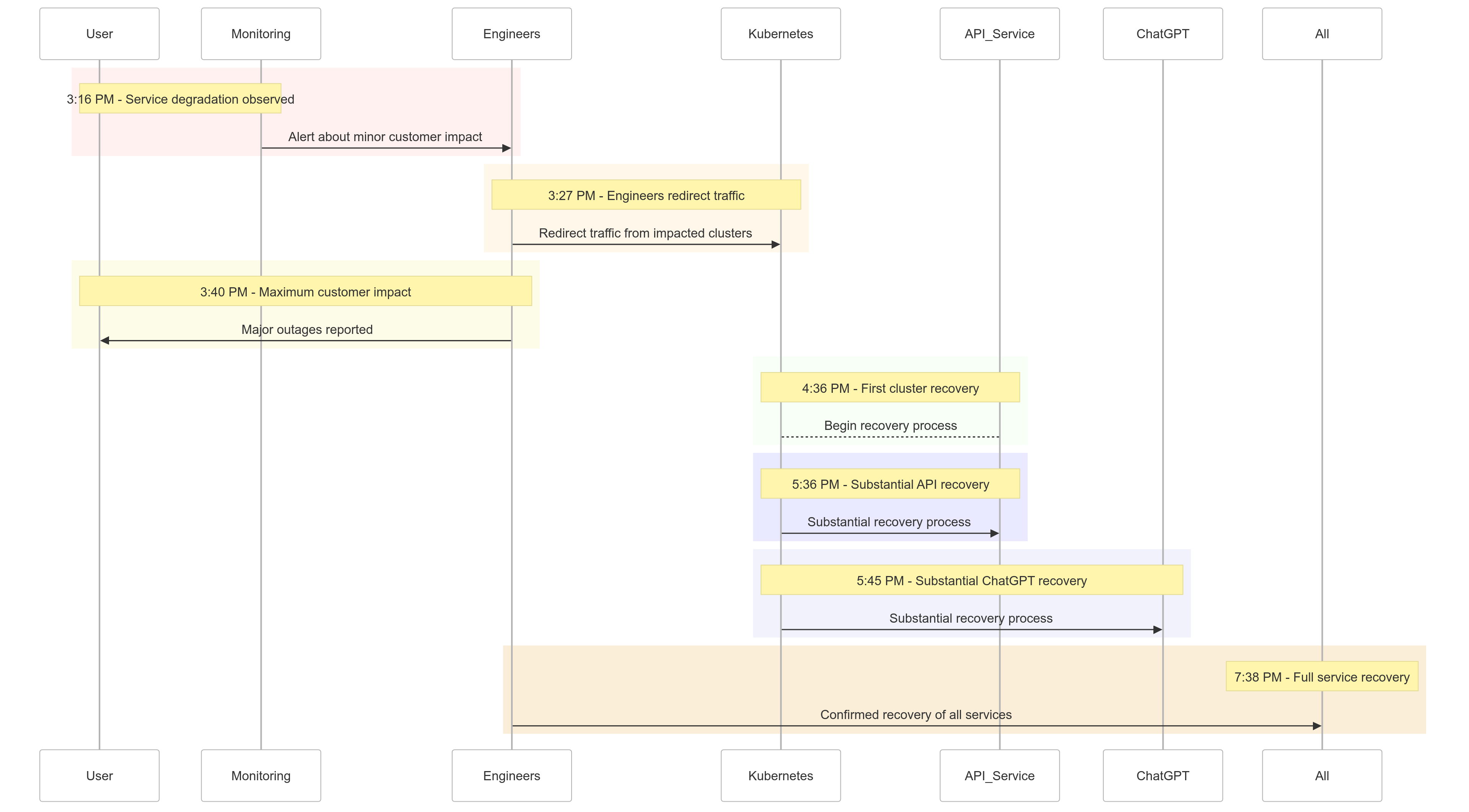
الشكل 1: الجدول الزمني لحادث OpenAI – تدهور الخدمة إلى التعافي الكامل.
تحليل السبب الجذري
كان جوهر الحادث يكمن في خدمة قياس جديدة تم نشرها في الساعة 3:12 مساءً بتوقيت المحيط الهادئ لتحسين قابلية مراقبة خطط التحكم في Kubernetes. وقد أدت هذه الخدمة عن غير قصد إلى إغراق خوادم API الخاصة بـ Kubernetes عبر عدة مجموعات، مما أدى إلى فشل متسلسل.
تفصيل المشكلة
نشر خدمة القياس
تم تصميم خدمة القياس لجمع مقاييس تفصيلية عن خطط التحكم في Kubernetes، لكن تكوينها أثار عن غير قصد عمليات API كثيفة الاستخدام للموارد عبر آلاف العقد في نفس الوقت.
زيادة الحمل على خطة التحكم
أصبحت خطة التحكم في Kubernetes، المسؤولة عن إدارة المجموعات، مثقلة بالأعباء. بينما ظلت خطة البيانات (التي تتعامل مع طلبات المستخدمين) عاملة جزئيًا، كانت تعتمد على خطة التحكم من أجل حل أسماء النطاقات. مع انتهاء صلاحية سجلات DNS المخزنة، بدأت الخدمات التي تعتمد على حل DNS في الوقت الحقيقي بالفشل.
اختبارات غير كافية
تم اختبار النشر في بيئة اختبار، لكن مجموعات الاختبار لم تعكس نطاق مجموعات الإنتاج. ونتيجة لذلك، لم يتم اكتشاف مشكلة تحميل خادم API خلال الاختبار.
كيفية التخفيف من المشكلة
عندما بدأ الحادث، تمكن مهندسو OpenAI بسرعة من تحديد سبب الجذر ولكنهم واجهوا تحديات في تنفيذ إصلاح لأن الخادم الرئيسي المفرط في العبء Kubernetes حال دون الوصول إلى خوادم الـAPI. تم اعتماد نهج متعدد الجوانب:
- تقليص حجم العقدة: بتقليل عدد العقد في كل عقدة تم تخفيض حمل خادم الـAPI.
- حظر الوصول إلى شبكة Kubernetes Admin APIs: منع الطلبات الإضافية للـAPI مما سمح للخوادم بالاستعادة.
- توسيع خوادم Kubernetes API: توفير موارد إضافية ساعد على تنظيف الطلبات المعلقة.
هذه التدابير سمحت للمهندسين باستعادة الوصول إلى الخوادم الرئيسية وإزالة خدمة التلميتري المشكلة، مما استعاد وظائف الخدمة.
الدروس المستفادة
يسلط هذا الحادث الضوء على أهمية الاختبار القوي والمراقبة وآليات الحماية في الأنظمة الموزعة. ها هي الدروس التي تعلمها OpenAI (ونفذتها) من الانقطاع:
1. نشر تدريجي قوي
سيتبع الآن جميع التغييرات في البنية التحتية نهج النشر التدريجي مع المراقبة المستمرة. يضمن هذا الكشف المبكر عن المشاكل والتصدي لها قبل التوسع إلى كامل الأسطول.
2. اختبار حقن الأخطاء
من خلال محاكاة الأخطاء (على سبيل المثال، تعطيل الخادم الرئيسي أو تنفيذ تغييرات سيئة)، ستتحقق OpenAI من قدرة أنظمتها على الاسترداد تلقائيًا والكشف عن المشاكل قبل أن تؤثر على العملاء.
3. الوصول إلى خطة التحكم الطارئة
ستضمن آلية “كسر الزجاج” أن يتمكن المهندسون من الوصول إلى خوادم API الخاصة بكوبرنيتس حتى تحت ضغط كبير.
4. فصل خطط التحكم والبيانات
لتقليل الاعتماديات، ستقوم OpenAI بفصل خطة بيانات كوبرنيتس (تعامل مع الأحمال) عن خطة التحكم (المسؤولة عن التنسيق)، مما يضمن استمرار الخدمات الحيوية في العمل حتى أثناء انقطاع خطة التحكم.
5. آليات استرداد أسرع
ستعمل استراتيجيات التخزين المؤقت وتحديد المعدلات الجديدة على تحسين أوقات بدء التشغيل للعنقود، مما يضمن استرداد أسرع أثناء حدوث الأعطال.
عينة من الشيفرة: مثال على التوزيع المرحلي
إليك مثال على تنفيذ توزيع مرحلي لكوبرنيتس باستخدام هيلم وبروميثيوس للمراقبة.
نشر هيلم مع التوزيعات المرحلية:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
استعلام بروميثيوس لمراقبة حمل خادم API:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
يساعد هذا الاستعلام على تتبع أوقات الاستجابة لطلبات خادم API، مما يضمن الكشف المبكر عن ارتفاعات الحمل.
مثال على حقن الأخطاء
باستخدام chaos-mesh، يمكن أن تحاكي OpenAI انقطاع الخدمة في خطة التحكم الخاصة بكوبرنيتس.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
تقوم هذه التكوينات عمداً بإنهاء حاوية خادم API للتحقق من مرونة النظام.
ما يعنيه هذا بالنسبة لك
هذا الحادث يبرز أهمية تصميم أنظمة مرنة واعتماد منهجيات اختبار صارمة. سواء كنت تدير أنظمة موزعة على نطاق واسع أو تقوم بتنفيذ Kubernetes لحمولات العمل الخاصة بك، إليك بعض النقاط المهمة:
- محاكاة الفشل بانتظام: استخدم أدوات هندسة الفوضى مثل Chaos Mesh لاختبار متانة النظام تحت ظروف العالم الحقيقي.
- المراقبة على مستويات متعددة: تأكد من أن مجموعة المراقبة الخاصة بك تتعقب كل من مقاييس مستوى الخدمة ومقاييس صحة الكتلة.
- فصل الاعتماديات الحرجة: قلل الاعتماد على نقاط الفشل الفردية، مثل اكتشاف الخدمة المعتمد على DNS.
الاستنتاج
بينما لا يوجد نظام محصن ضد الفشل، فإن الحوادث مثل هذه تذكرنا بقيمة الشفافية، والتصحيح السريع، والتعلم المستمر. إن نهج OpenAI الاستباقي في مشاركة هذا التحليل يوفر نموذجًا للمنظمات الأخرى لتحسين ممارساتها التشغيلية وموثوقيتها.
من خلال إعطاء الأولوية للإطلاقات المرحلية القوية، واختبار إدخال الأخطاء، وتصميم الأنظمة المرنة، تضع OpenAI مثالاً قويًا حول كيفية التعامل مع الانقطاعات الكبيرة والتعلم منها.
بالنسبة للفرق التي تدير أنظمة موزعة، فإن هذا الحادث يعد دراسة حالة رائعة حول كيفية التعامل مع إدارة المخاطر وتقليل فترة التوقف لعمليات الأعمال الأساسية.
لنستخدم هذه الفرصة لبناء أنظمة أفضل وأكثر مرونة معًا.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident