













مقدمة
في هذه المقالة سنبني واحدة من أوائل الشبكات العصبية التي تم إدلاءها من قبل، (LeNet5). سنبني هذه الشبكة العصبية التي تقلص من الصفر في PyTorch، وسنرى أيضًا كيف تقوم بالأداء على مجموعة بيانات عالمية.
سنبدأ باستكشاف هندسة LeNet5. سنقوم بتحميل وتحليل مجموعة بياناتنا، MNIST، باستخدام الفئة الموجودة في torchvision. باستخدام PyTorch، سنبني من جديد LeNet5 ون entrainer على معلوماتنا. وأخيرًا، سنرى كيف يقوم النموذج بالأداء على البيانات الاختبارية المعدنية.
المقادمات
سيساعد المعرفة بالشبكات العصبية في فهم هذا المقال. هذا يستطيع أن يعني التأكد من معرفة الأطباق المختلفة للشبكات العصبية (طبقة الإدخال، الطبقات السريعة، طبقة الخروج)، والممارسات الفعالية، والخوارزميات التحسينية (أنواع الهداية التي تنطوي على المسافة الجانبية)، والمعاملات الخام، وما إلى ذلك. بالإضافة إلى ذلك، يتوجب أيضًا المعرفة بالسياق البرمجي للبيانات ومكتبة PyTorch لفهم القطع البرمجية التي تقدم في هذا المقال.
وتوصيل فهم الأنظمة التعلمية التصاعدية (CNNs) أيضًا. هذا يشمل معرفة الطبقات المكونة، والطبقات التخفيفية، ودورهم في توليد الخصائص من البيانات المدخلة. فهم المفاهيم مثل المسار، التكافؤ، وتأثير حجم المجال/المرشد مفائد.
LeNet5
تم استخدام LeNet5 لتمييز الحروف المكتوبة يدويًا وقد قام يان ليكون وآخرون بتقديمها في عام 1998 مع المقالة Gradient-Based Learning Applied to Document Recognition.
دعونا نفهم هيكل LeNet5 وكما يبدو في رسم التالي:
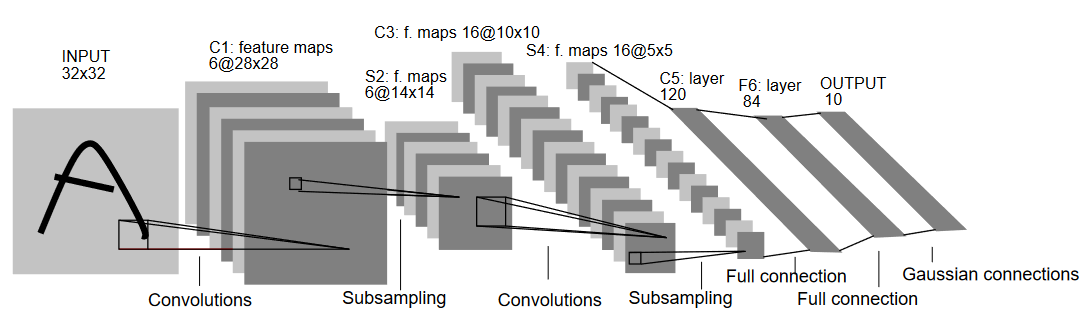
وكما يبدو في الإسم، LeNet5 تحتوي على خمس طوابق ومن ثم تكون من الطوابق التصاعدية الثانية وثلاثة طوابق متصلة بشكل كامل. دعونا نبدأ مع المعلومات المدخلة. LeNet5 تقبل معلومات الصورة الرمادية الصغيرة 32×32، ما يعني أن هذه البنية غير مناسبة للصور الRGB (أعداد متعددة). لذلك يجب أن تحتوي الصورة المدخلة على خانة واحدة فقط. بعد هذا، نبدأ بطبقاتنا المكونة
الطبقة الأولية للمكونات تمتلك حجم 5×5 مع 6 مرشدًا من هذا النوع. ستقلل عرض وعمود الصورة بينما يزداد عمق (عدد القنوات). النتيجة ستكون 28x28x6. بعد ذلك، يتم تطبيق التجزئة لخفض خاصية الخريطة بالنصف، أي 14x14x6. نفس حجم المرشد (5×5) مع 16 مرشدًا يتم تطبيقه على الناتج من خلال طبقة تجزئة. ستقلل خاصية نتيجة المرشد إلى 5x5x16.
بعد هذا، تطبق طبقة كونولوزية بحجم 5×5 مع 120 مرشح لتصاعد الخريطة الخاصة إلى 120 قيمة. ومن ثم يأتي الطبقة المتصلة بالكل للمرشد الأول مع 84 خلية. وأخيرًا، لدينا الطبقة الخاصة بالخريطة الخاصة بـ10 خلية للخروج، لأن يوجد 10 فئة في البيانات الموجودة في MNIST لكل من الأرقام العشر التي تم تمثيلها.
تحميل البيانات
دعونا نبدأ بتحميل وتحليل البيانات. سنستخدم مجموعة MNIST. تحتوي مجموعة MNIST على صور لرقمات كتابية بين الأصول. الصور شبه أسودة، كلها بحجم 28×28، وتتكون من 60,000 صور تدريبية و10,000 صور اختبارية.
يمكنك رؤية بعض عينات الصور هنا:

استيراد المكتبات
دعونا نبدأ باستيراد المكتبات المطلوبة وتعريف بعض المتغيرات الرئيسية (المتغيرات الجبرية والـdevice تم تفسيرها أيضًا لمساعدة الحزمة على تحديد ما إذا كان على التمويل المعين على الGPU أو الCPU).
# تحميل المكتبات المرتبطة وتسميةها بالمناسبة
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# تعريف المتغيرات المرتبطة بالمهمة التعلمية المتقدمة
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# الـdevice سيحدد ما إذا كان على التمويل المعين على الGPU أو الCPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
تحميل وتحويل البيانات
باستخدام torchvision سوف نحمل المجموعة البيانات لأن هذا سيسمح لنا بأن نقوم بأي خطوات التحضير المسبقة بسهولة.
#تحميل المجموعة والتحضير
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
دعونا نفهم الكود:
- أولاً، لا يمكن الاستخدام المباشر لبيانات MNIST لهياكل LeNet5. الهيكل LeNet5 يتقبل المعلومات الداخلية كونها 32×32 والصور التي يتم إلتقاءها معها 28×28. يمكننا تصحيح هذا عن طريق تغيير حجم الصور، وتعديلها بواسطة المعدلات السائدة والضخامة المسبقاً حسب المعلومات التي تتوفر على شبكة الويب، وأخيرًا تخزينها كعباديات.
- نضع
download=Trueفي حال لم يتم تحميل البيانات بالفعل. - من ثم، نستخدم محركات البيانات. قد لا يؤثر هذا على الأداء في حالة المجموعة الصغيرة مثل MNIST، لكنه يمكن أن يهدر الأداء بشكل كبير في حالة المجموعات الكبيرة وهو ما يعتبر من الممارسات الجيدة. تسمح محركات البيانات لنا بتتبع البيانات في أكوان والبيانات تتحمل خلال التتبع وليس من بداية التحميل.
- نحدد الحجم الأساسي للكوارت ونترامز المجموعة عند التحميل حتى يكون لكل كوارت بعض التنوع في أنواع التسميات التي تتضمنها. سيزيد كفاءة نموذجنا النهائي.
LeNet5 من الصفر
دعونا ننظر أولا إلى البرمجيات:
# تعريف الشبكة العصبية التصاعدية
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
تعريف نموذج LeNet5
سأشرح البرمجيات بشكل خطي:
- في PyTorch، نحن نتعرف شبكة عصبية بعمل صف يختلف من
nn.Moduleلأنه يحتوي على العديد من الطرق التي سنحتاج إليها للاستخدام. - هناك خطوات اثنتين بعد ذلك. الأول هو تكوين الطوابق التي سنستخدمها في شبكتنا التصاعدية داخل
__init__، والآخر هو تعريف التسلسل الذي ستقوم به هذه الطوابق بمعالجة الصورة. يتم تعريفه داخل وظيفةforward. - في بنية الشبكة نحن نتعرف أولاً على الطوابق التصاعدية باستخدام وظيفة
nn.Conv2Dمع حجم النافذة المناسب والقنوات المدخلية/الخارجية. نقوم أيضًا بتطبيق التصاعد الأقصى بواسطة وظيفةnn.MaxPool2D. أحد الأمور الجيدة عند PyTorch هو أنه يمكننا تركيب الطوابق التصاعدية، والمؤلف الحركي، والتصاعد الأقصى في طوق واحد واحد (سيتم تطبيقهم بشكل منفصل، لكن هذا يساعد في التنظيم) بواسطة وظيفةnn.Sequential. - نحن نعرف ال层次 المتصلة بالكامل. تلاحظ أننا يمكننا استخدام
nn.Sequentialهنا أيضًا وتراكم المتغيرات التفاعلية والطباع الخطية، لكنني أردت أن أبرهم أن أمكن أي من الاحتمالات. - فinally، تولد أخيرًا لمستوياتنا ال10 التي تمثل تخمينا النهائي للأرقام.
تعديل المتغيرات الرئيسية
قبل التدريب، يتوجب علينا تعديل بعض المتغيرات الرئيسية، مثل المعاملة والمحاكد التي سنستخدمها.
model = LeNet5(num_classes).to(device)
#تعديل المعاملة
cost = nn.CrossEntropyLoss()
#تعديل المحاكد مع معلومات النموذج ومعدل التعلم
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#هذا معروف للطريقة التي يمكننا معرفة كم من الخطوات تبقى أثناء التدريب
total_step = len(train_loader)
نبدأ بتكوين نموذجنا من خلال عدد الأقسام كما ما تلك المعاملة المفردة هي خسارة التضاريسية والمحاكد الخاصة بـ Adam. هناك الكثير من الخيارات لهذه، لكنها تساهم في توفير نتائج جيدة مع النموذج والبيانات المعطاة. أخيرًا، نحن نعرف total_step للتعرف على الخطوات بشكل أفضل أثناء التدريب.
تدريب النموذج
حاليًا، يمكننا تدريب نموذجنا:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#المرور الأمامي
outputs = model(images)
loss = cost(outputs, labels)
#الخطأ الخلفي والتكامل
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
بإنشاء شكل(العقدة+1, عدد_العقود, i+1, الخطوة_الكلية, قيمة_الخسارة)
لنرى ما يفعل الكود:
- نبدأ بالتنقل من خلال عدد العقود، ومن ثم الحزم في بيانات التدريب.
- نحول الصور والتسميات وفقاً للجهاز الذي نستخدمه، أي إما الGPU أو الCPU.
- في المرور الأمامي، نقوم بالتنبؤات باستخدام نموذجنا ونحسب الخسارة بناء على تلك التنبؤات وتسمياتنا الفعلية.
- ثم، نقوم بالمرور الخلفي حيث نحقق فعلا تحديث وزناتنا لتحسين نموذجنا
- ثم نضع التدرجات إلى صفر قبل كل تحديث باستخدام دالة
optimizer.zero_grad(). - ثم، نحسب التدرجات الجديدة باستخدام دالة
loss.backward(). - وأخيرا، نقوم بتحديث الوزنات بواسطة دالة
optimizer.step().
يمكننا رؤية النتيجة كما يلي:
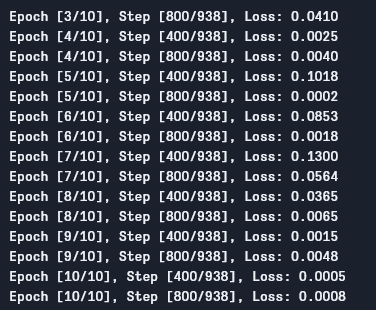
كما نرى، الخسارة تنخفض بكل عقدة وهذا يظهر بأن نموذجنا يتعلم بالفعل. لاحظ أن هذه الخسارة على مجموعة التدريب، وإذا كانت الخسارة سيئة جداً (كما هو الحال في حالتنا)، قد تشير إلى التعبير. وهناك العديد من الطرق لحل هذه المشكلة، مثل التنظيم، تحسين البيانات، وهلم جراً، ولكننا لن نتحدث عن ذلك في هذه المقالة. دعونا نختبر نموذجنا لرؤية كيفية عمله.
اختبار النموذج
دعونا نختبر نموذجنا الآن:
# اختبار النموذج
# في مرحلة الاختبار، لا يتوجب علينا حاسبة المسافرات (لكفاءة الذاكرة)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
وكما ترون، لا يختلف الكود كثيراً عن التعلم. الفرق الوحيد هو أننا لا نحاسب المسافرات (باستخدام with torch.no_grad()),ولا نحاسب أي خسائر لأننا لا نحتاج للتغذيف هنا. لحساب دقة ناتجة للنموذج، يمكننا ببساطة حساب عدد التخمينات الصحيحة بالمجموع عن عدد الصور الكلي.
وباستخدام هذا النموذج، نحصل على دقة تقريبًا 98.8% وهي جيدة جدًا:

دقة الاختبار
تنظر إلى أن قاعدة MNIST بسيطة وصغيرة جدًا بمقاربة اليوم، ومن الصعب أن نحصل على نتائج مماثلة لأخرى قاعدات. ومع ذلك، هي من المناهج الجيدة البدءية حين التعلم عن التعلم العميق والأنظمة التصويرية العميقة.
الخلاصة
دعونا ننتهي الآن بما فعلناه في هذا المقال:
- بدأنا بتعلم هيكل LeNet5 وأنواع الطبقات المختلفة فيه.
- من ثم، Explored قاعدة MNIST وتحميل البيانات باستخدام
torchvision. - ثم، قمنا ببناء LeNet5 من الصفر وتعريف خيارات النموذج للنموذج.
- وأخيرًا، تم تدريب واختبار نموذجنا على قاعدة بيانات MNIST، وبدأ يظهر نموذجنا بشكل جيد على القاعدة التجريبية.
العمل المستقبلي
على الرغم من أن هذا يبدو من المقدمات الجيدة الأولي للتعلم العميق في PyTorch، يمكنك توسيع هذا العمل لتتعلم المزيد أيضًا:
- يمكنك محاولة استخدام قواعد بيانات مختلفة ولكن لهذا النموذج سيتوجب عليك استخدام قواعد بيانات بالأسود. واحدة من هذه القواعد هي FashionMNIST.
- يمكنك تجربة مختلف المادة الفرعية ورؤية أفضل مزيج منها للنموذج.
- أخيرًا، يمكنك محاولة إضافة أو إزالة طبقات من القاعدة لرؤية تأثيرها على قدرات النموذج.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python