













在計算的早期,應用程式按順序處理任務。隨著用戶數量達到數百萬,這種方法變得不切實際。非同步處理允許同時處理多個任務,但在單一機器上管理執行緒/進程會導致資源限制和複雜性。
這就是分散式並行處理的用武之地。通過將工作負載分散到多台機器上,每台機器專注於任務的一部分,它提供了一個可擴展且高效的解決方案。如果你有一個函數要處理大量文件,你可以將工作負載劃分到多台機器上,同時處理文件,而不是在一台機器上按順序處理。此外,它還通過利用結合的資源來提高性能,並提供可擴展性和容錯能力。隨著需求的增加,你可以添加更多的機器以增加可用資源。
在規模上建立和運行分散式應用程式是具有挑戰性的,但有幾個框架和工具可以幫助你。在這篇博客文章中,我們將檢視一個開源的分散式計算框架:Ray。我們還會看看KubeRay,一個Kubernetes運營商,能夠在雲原生環境中實現Ray與Kubernetes集群的無縫整合。但首先,讓我們了解分散式並行處理在哪些方面提供幫助。
分散式並行處理在哪裡提供幫助?
任何受益於將工作負載分散到多台機器上的任務都可以利用分散式並行處理。這種方法尤其適用於網路爬蟲、大規模數據分析、機器學習模型訓練、即時流處理、基因組數據分析和視頻渲染等情境。通過將任務分佈到多個節點上,分散式並行處理顯著提升性能,減少處理時間,並優化資源利用,使其對需要高吞吐量和快速數據處理的應用至關重要。
當不需要分散式並行處理
- 小規模應用:對於小數據集或處理需求較小的應用程序,管理分散系統的開銷可能無法自圓其說。
- 數據依賴性強:如果任務高度相互依賴且難以並行化,分散式處理可能帶來較少好處。
- 實時限制:一些實時應用(例如金融和訂票網站)需要極低的延遲,而加入分散系統的複雜性可能無法實現這種要求。
- 資源有限:如果現有基礎設施無法支持分散系統的開銷(例如網路頻寬不足、節點數量有限),優化單機性能可能更為合適。
Ray 如何幫助分散式並行處理
Ray是一個分散式平行處理框架,封裝了分散式計算的所有優勢以及我們討論過的挑戰解決方案,如容錯、可擴展性、上下文管理、通訊等等。它是一個Pythonic框架,允許使用現有的庫和系統來與之協作。在Ray的幫助下,程式設計師不需要處理平行處理計算層的各個部分。Ray將根據指定的資源需求負責排程和自動擴展。
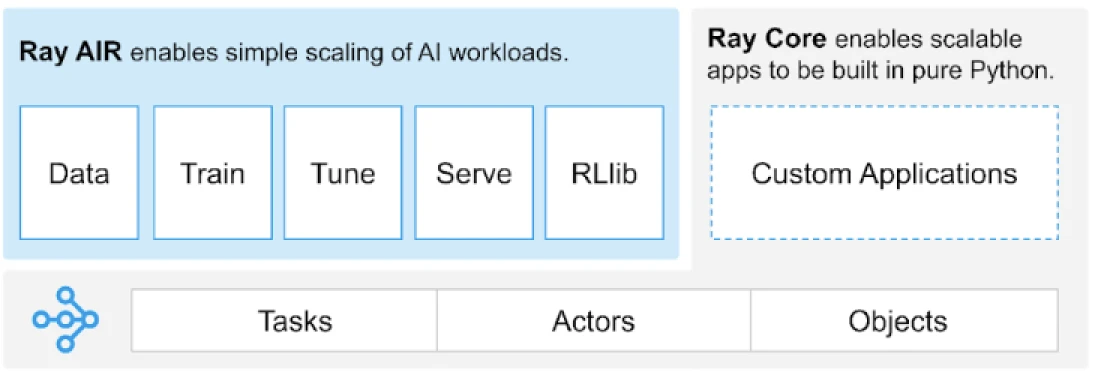
Ray提供了一個通用的任務、演員和物件的API,用於構建分散式應用程式。
(圖片來源)
Ray提供了一組構建在核心原語上的庫,即任務、演員、物件、驅動程式和作業。這些提供了一個多功能的API來幫助構建分散式應用程式。讓我們來看看核心原語,也就是Ray Core。
Ray Core原語
- 任務: Ray 任務是在 Ray 集群節點上異步執行的任意 Python 函數。用戶可以根據 CPU、GPU 和自定義資源指定其資源需求,集群調度程序將使用這些需求來分發任務以進行並行執行。
- 演員: 對於函數而言有任務,對於類而言有演員。演員是具有狀態的工作程序,演員的方法被安排在特定的工作程序上執行,並且可以訪問和改變該工作程序的狀態。與任務一樣,演員支持 CPU、GPU 和自定義資源需求。
- 對象: 在 Ray 中,任務和演員創建和計算對象。這些遠程對象可以存儲在 Ray 集群中的任何地方。對象引用用於引用它們,並且它們被緩存在 Ray 的分佈式共享內存對象存儲中。
- 驅動程序: 程序的根,或者“主”程序: 這是運行
ray.init()的程式碼。 - 工作: 來自同一驅動程序及其運行時環境的任務、對象和演員的集合(遞歸)。
有關原始信息,您可以閱讀 Ray 核心文檔。
Ray 核心關鍵方法
以下是常用的 Ray 核心關鍵方法:
-
ray.init()– 啟動 Ray 運行時並連接到 Ray 集群。import ray ray.init()
-
@ray.remote– 裝飾器,用於指定一個 Python 函數或類別在不同的進程中作為任務(遠程函數)或演員(遠程類別)執行@ray.remote def remote_function(x): return x * 2
-
.remote– 遠程函數和類別的後綴;遠程操作是異步的result_ref = remote_function.remote(10)
-
ray.put()– 將對象放入內存對象存儲中;返回一個對象引用,用於將對象傳遞給任何遠程函數或方法調用。data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– 通過指定對象引用從對象存儲中獲取遠程對象。result = ray.get(result_ref) original_data = ray.get(data_ref)
這裡是使用大多數基本關鍵方法的示例:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# 使用 .remote 創建任務
future = calculate_square.remote(5)
# 獲取結果
result = ray.get(future)
print(f"The square of 5 is: {result}")Ray 是如何工作的?
Ray 集群就像是一組計算機,共同分享運行程序的工作。它由一個主節點和多個工作節點組成。主節點管理集群狀態和調度,而工作節點執行任務並管理演員
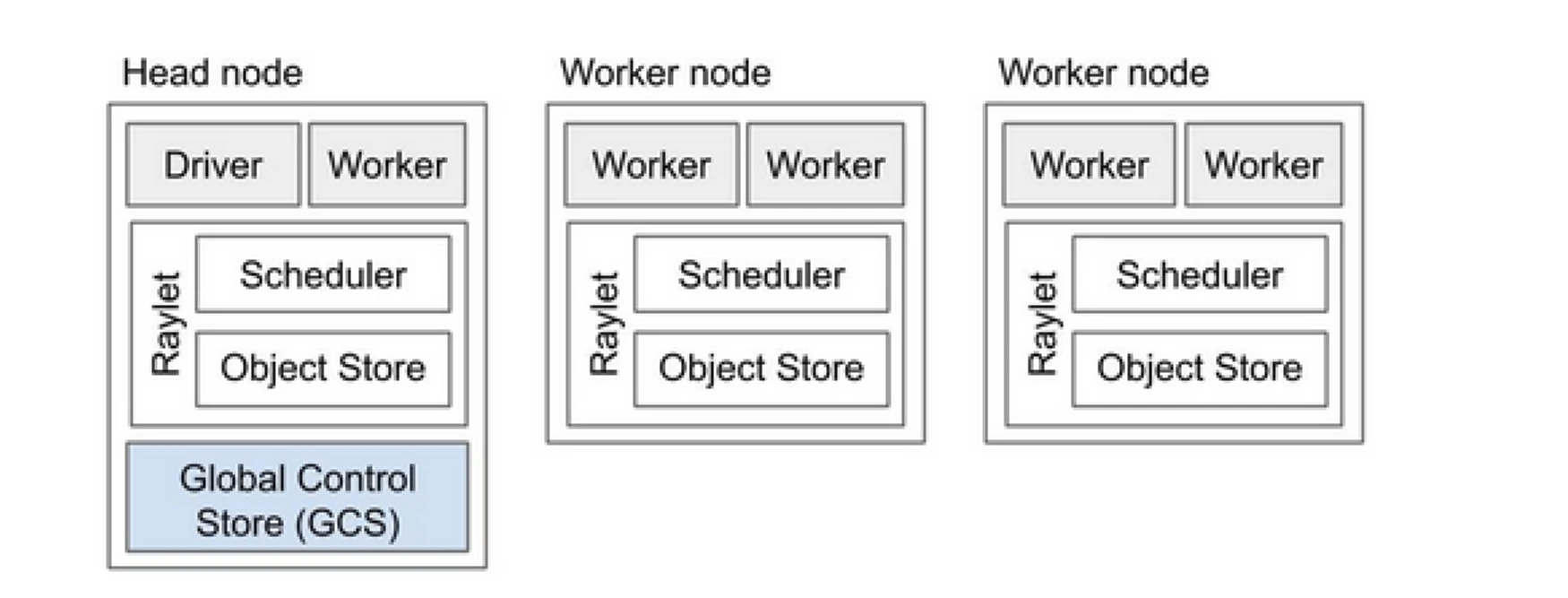
Ray 集群組件
- 全局控制存儲 (GCS):GCS 管理 Ray 集群的元數據和全局狀態。它跟踪任務、演員和資源可用性,確保所有節點對系統有一致的視圖。
- 調度器:調度器將任務和演員分配到可用的節點。它通過考慮資源需求和任務依賴關係來確保資源的有效利用和負載平衡。
- 主節點:主節點協調整個 Ray 集群。它運行 GCS,處理任務調度,並監控工作節點的健康狀況。
- 工作節點:工作節點執行任務和演員。它們進行實際計算並在其本地內存中存儲對象。
- Raylet:它管理每個節點上的共享資源,並在所有同時運行的作業之間共享。
您可以查看 Ray v2 架構文檔以獲取更詳細的信息。
與現有的 Python 應用程式合作不需要太多變更。所需的變更主要圍繞著需要自然分發的函數或類別。您可以添加裝飾器,並將其轉換為任務或演員。讓我們看一個例子。
將 Python 函數轉換為 Ray 任務
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
將 Python 類轉換為 Ray 演員
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
在 Ray 對象中儲存信息
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
要了解更多關於其概念,請前往 Ray Core Key Concept 文件。
Ray 與傳統分佈式並行處理方法的比較
以下是傳統(不使用 Ray)方法與在 Kubernetes 上使用 Ray 進行分佈式並行處理的比較分析。
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| 部署 | 手動設置和配置 | 使用 KubeRay Operator 自動化 |
| 擴展 | 手動擴展 | 使用 RayAutoScaler 和 Kubernetes 自動擴展 |
| 容錯 | 自定義容錯機制 | 使用 Kubernetes 和 Ray 內建容錯 |
| 資源管理 | 手動資源分配 | 自動化資源分配和管理 |
| 負載均衡 | 自定義負載均衡解決方案 | 內建負載平衡與 Kubernetes |
| 依賴管理 | 手動依賴安裝 | 使用 Docker 容器的一致環境 |
| 集群協調 | 複雜且手動 | 透過 Kubernetes 服務發現和協調簡化 |
| 開發開銷 | 高,需自定義解決方案 | 減少,Ray 和 Kubernetes 處理許多方面 |
| 靈活性 | 對變化的工作負載適應性有限 | 具有高靈活性,支持動態擴展和資源分配 |
Kubernetes 提供了運行分散式應用程式如 Ray 的理想平台,因為它擁有強大的編排能力。以下是運行 Ray 在 Kubernetes 上的關鍵要點:
- 資源管理
- 可擴展性
- 編排
- 與生態系統的整合
- 易於部署和管理
KubeRay Operator 使得在 Kubernetes 上運行 Ray 成為可能。
什麼是 KubeRay?
KubeRay Operator 透過自動化部署、擴展和維護等任務,簡化了在 Kubernetes 上管理 Ray 集群的過程。它使用 Kubernetes 自定義資源定義(CRDs)來管理特定於 Ray 的資源。
KubeRay CRDs
它有三個不同的 CRD:
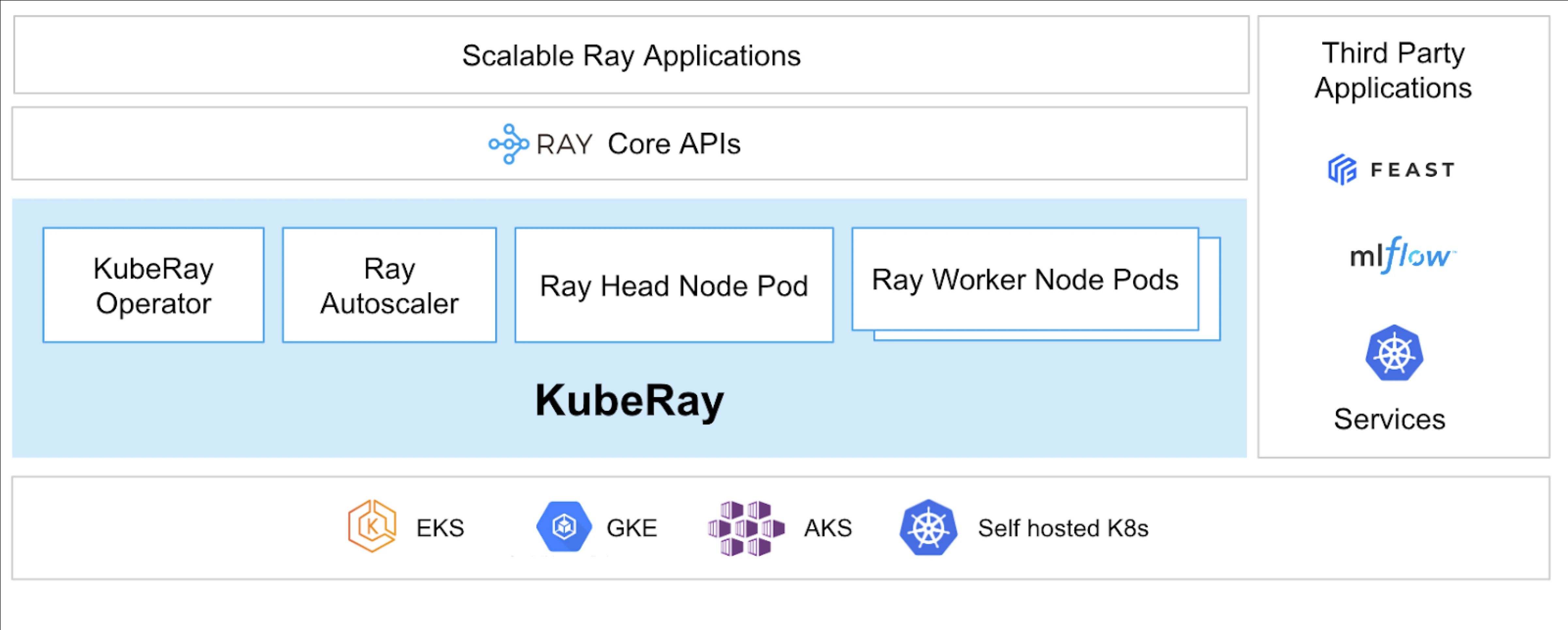
- RayCluster:此 CRD 有助於管理 RayCluster 的生命週期,並根據定義的配置處理自動擴展。
- RayJob:當有一次性的任務需要執行,而不是始終保持待命的 RayCluster 時,這個 CRD 是非常有用的。它會在準備好時創建一個 RayCluster 並提交任務。任務完成後,它會刪除 RayCluster。這有助於自動回收 RayCluster。
- RayService:這個 CRD 也會創建一個 RayCluster,但會在其上部署 RayServe 應用程式。這使得可以對應用程式進行原地更新,提供零停機時間的升級和更新,以確保應用程式的高可用性。
KubeRay 的使用案例
使用 RayService 部署按需模型
RayService 允許您在 Kubernetes 環境中按需部署模型。這對於像是影像生成或文本提取的應用特別有用,因為模型僅在需要時才會部署。
以下是穩定擴散的示例。一旦在 Kubernetes 中應用,它將創建 RayCluster 並運行 RayService,該服務將持續提供模型,直到您刪除此資源。它允許用戶掌控資源。
在GPU集群上使用RayJob訓練模型
RayService為用戶提供不同需求,它會將模型或應用部署,直到手動刪除。相反,RayJob允許一次性作業,例如訓練模型、預處理數據或根據固定數量的提示進行推理。
在Kubernetes上運行推理伺服器使用RayService或RayJob
通常,我們在部署中運行應用程序,進行滾動更新而無需停機。同樣,在KubeRay中,可以使用RayService實現此目標,它部署模型或應用程序並處理滾動更新。
然而,有時您可能只想進行批量推理,而不是長時間運行推理伺服器或應用程序。這就是您可以利用RayJob的地方,它類似於Kubernetes Job資源。
使用Huggingface Vision Transformer進行圖像分類批量推理是RayJob的一個示例,用於批量推理。
這些是KubeRay的用例,使您能夠在Kubernetes集群上做更多事情。借助KubeRay的幫助,您可以在相同的Kubernetes集群上運行混合工作負載,並將基於GPU的工作負載調度卸載到Ray。
結論
分散式平行處理提供了一個可擴展的解決方案,以處理大規模、高資源需求的任務。Ray 簡化了構建分散式應用程序的複雜性,而 KubeRay 則將 Ray 與 Kubernetes 整合,以實現無縫的部署和擴展。這種組合增強了性能、可擴展性和容錯能力,使其非常適合用於網頁爬蟲、數據分析和機器學習任務。通過利用 Ray 和 KubeRay,您可以高效地管理分散式計算,輕鬆滿足當今數據驅動世界的需求。
不僅如此,隨著我們的計算資源類型從 CPU 轉變為基於 GPU,擁有高效且可擴展的雲基礎設施變得至關重要,無論是 AI 還是大型數據處理的各種應用。
如果您覺得這篇文章信息豐富且吸引人,我很想聽聽您對這篇文章的看法,因此請在 LinkedIn 上開始一場對話。
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray