













將您的原始數據轉換為有組織且可操作的信息可能聽起來很複雜。嗯,當您擁有快速高效的解決方案時就不是這樣了。不用擔心!這個適合初學者的 AWS Glue 教程會幫助您。
在這個教程中,您將學習配置和執行使用 AWS Glue 進行數據轉換的關鍵步驟。
探索並簡化雲端分析的數據準備工作!
先決條件
在使用 AWS Glue 之前,請確保您有一個已啟用計費功能的活動 Amazon Web Services(AWS)帳戶。這個教程所需的 免費帳戶就足夠了。
為 AWS Glue 創建 IAM 角色
在執行轉換作業之前,您必須創建一個身份和訪問管理(IAM)角色,該角色授予 AWS Glue 服務許可權。此角色定義了 AWS Glue 可以在您的 AWS 帳戶中訪問哪些類型的資源。
要創建 IAM 角色,請按照以下步驟操作:
1. 打開您偏好的 Web 瀏覽器,並登錄 AWS 管理控制台。
2. 在結果列表中搜索並選擇IAM,以訪問 IAM 控制台。
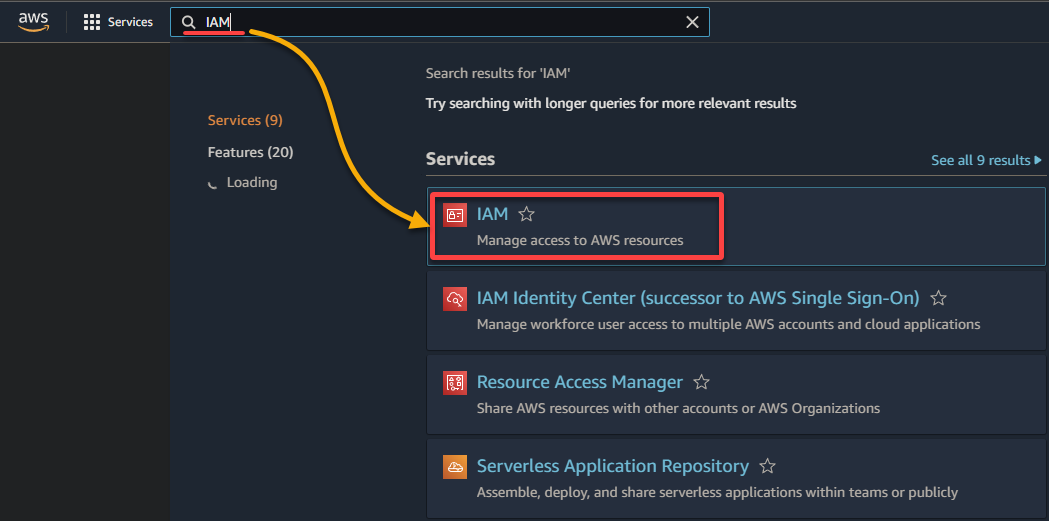
3. 在 IAM 控制台中,導航至角色(左窗格)並點擊創建角色(右上方),將您的瀏覽器重定向到專門用於配置角色的新頁面。

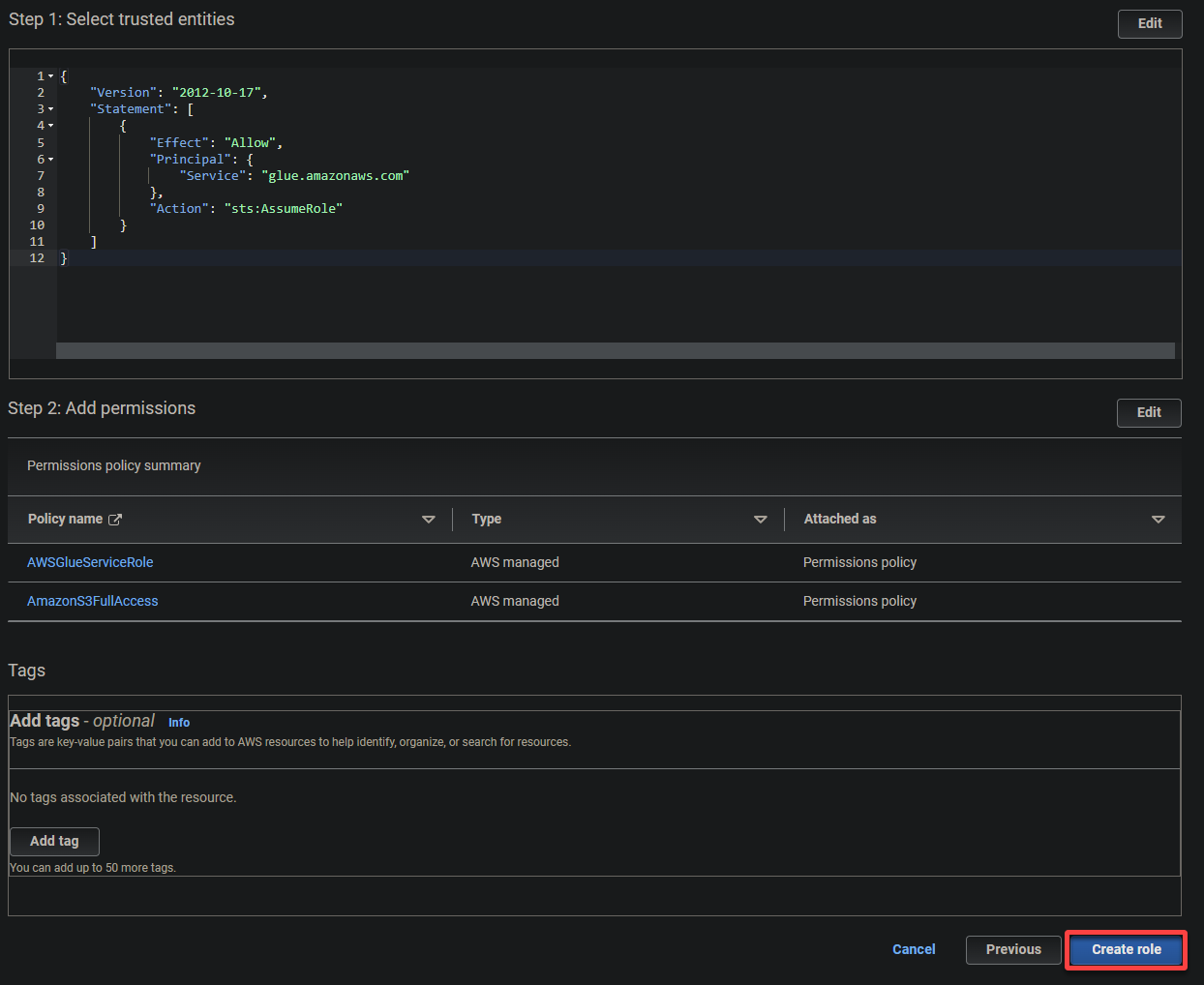
4. 現在,為角色配置以下設置:
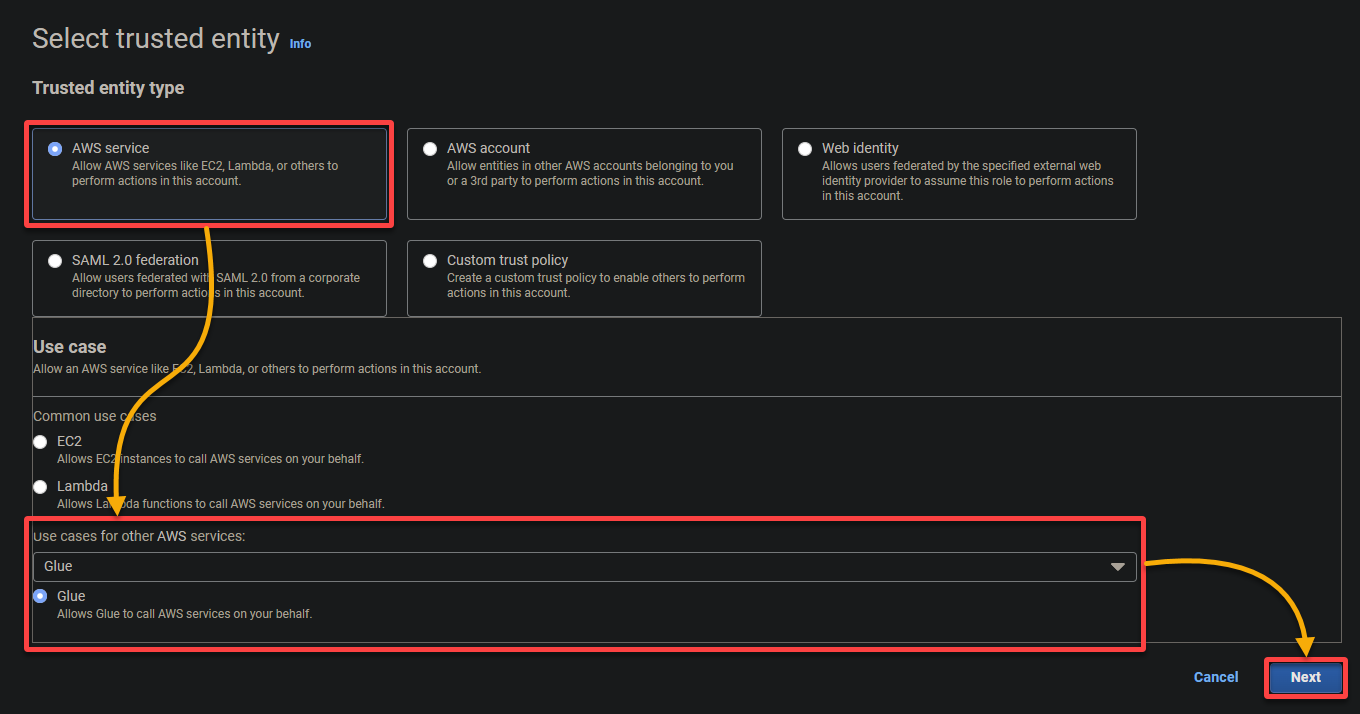
- 信任的實體類型 – 選擇 AWS 服務,以便 AWS 服務信任該角色。這樣做可以讓該服務假設角色並代表您採取行動。
- 用例 – 在其他 AWS 服務部分的用例下選擇 Glue,因為您將專門為 AWS Glue 創建 IAM 角色,然後點擊下一步。
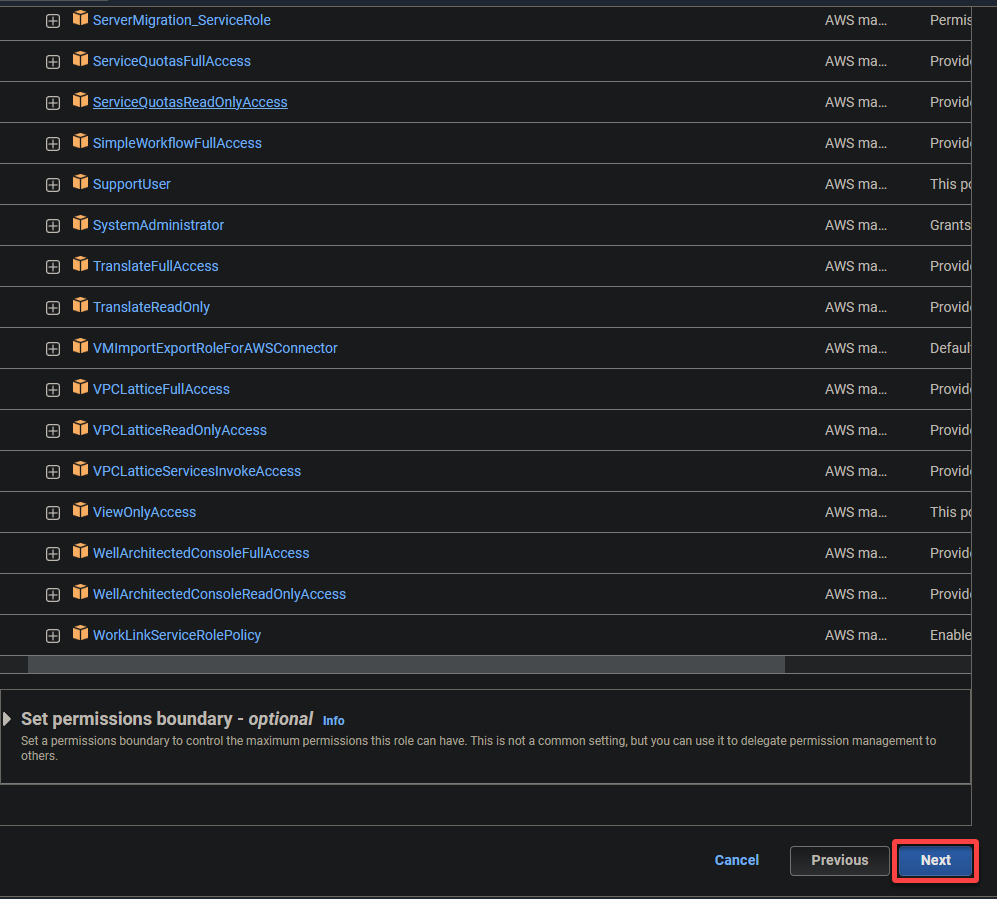
5. 搜索並選擇以下策略,然後點擊下一步。
- AWSGlueServiceRole – 授予 AWS Glue 服務執行其操作所需的權限。
- S3FullAccess – 授予對 S3 資源的完全訪問權限,允許 AWS Glue 讀取和寫入 S3 存儲桶。
AWS Glue 需要對 S3 存儲桶進行廣泛的權限以有效地執行其數據提取、轉換和加載(ETL)任務。
? 避免授予不必要的過多權限,因為這可能帶來安全風險。
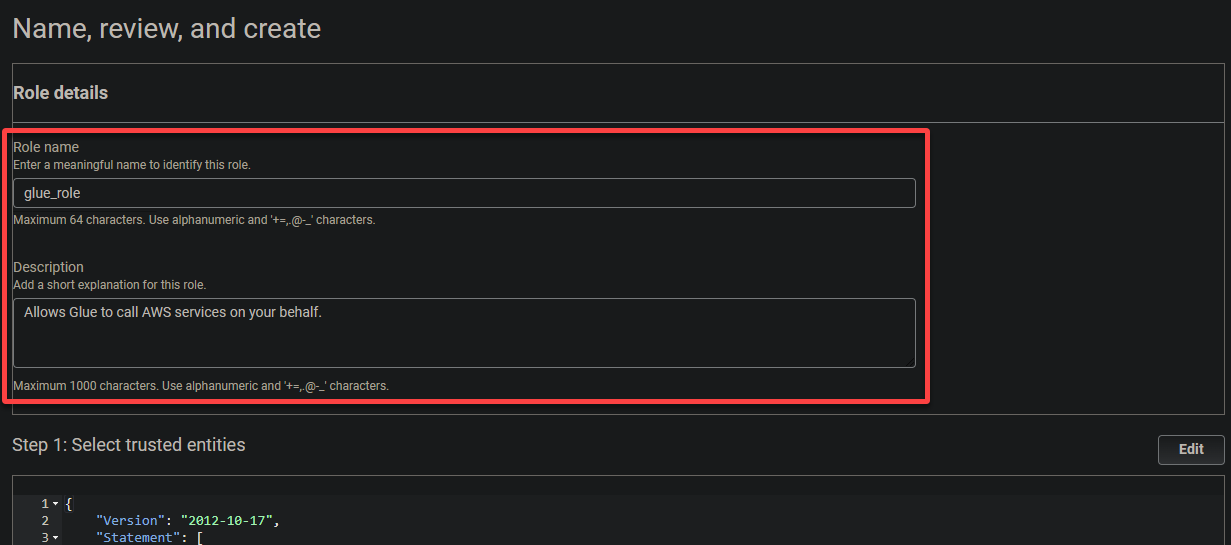
6. 為角色提供一個描述性名稱(即glue_role)和一個描述。
7. 最後,向下滾動,檢閱您的設置,然後點擊 創建角色(右下角)以完成角色的創建。
創建 S3 存儲桶並上傳示例文件
現在,您已經為 AWS Glue 創建了 IAM 角色,您需要一個地方來存儲您的數據,具體來說,就是一個 S3 存儲桶。S3 存儲桶提供了一個集中存儲 AWS Glue 將處理的數據的地方。
在此示例中,AWS Glue 將使用 AWS S3 作為各種操作的數據存儲,例如數據提取、轉換和加載(ETL)任務。
要創建 S3 存儲桶並上傳示例文件,請按照以下步驟進行:
1. 下載 樣本數據文件(例如 Every Politician 數據集)到您的本地計算機。此文件包含一組非結構化的記錄,用作 AWS Glue 轉換作業的輸入。
2. 搜索並選擇 S3 服務以訪問 S3 控制台。
3. 點擊 創建存儲桶 開始創建新的 S3 存儲桶。

4. 現在,為您的存儲桶提供一個唯一的名稱(即,sampledata54675)並選擇存儲桶應該位於的區域。
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
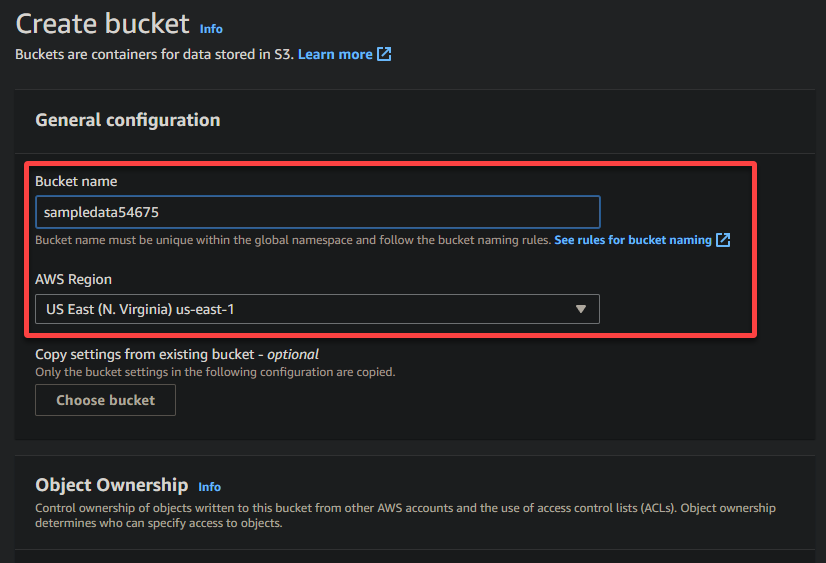
5. 向下滾動,將其他選項保持不變,然後點擊 創建存儲桶 以創建存儲桶。

6. 創建後,點擊新創建的 S3 存儲桶的超鏈接以進入存儲桶。

7. 點擊 上傳 並找到要上傳的示例文件。
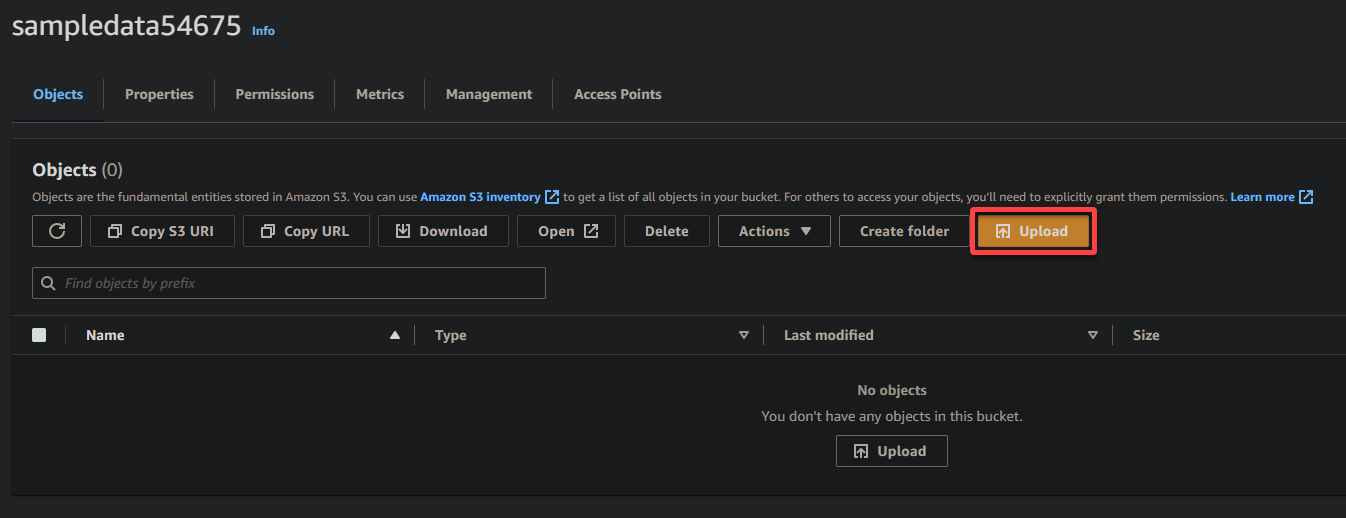
最後,保持其他設置不變,並點擊 上傳 將樣本文件上傳到新建立的存儲桶。
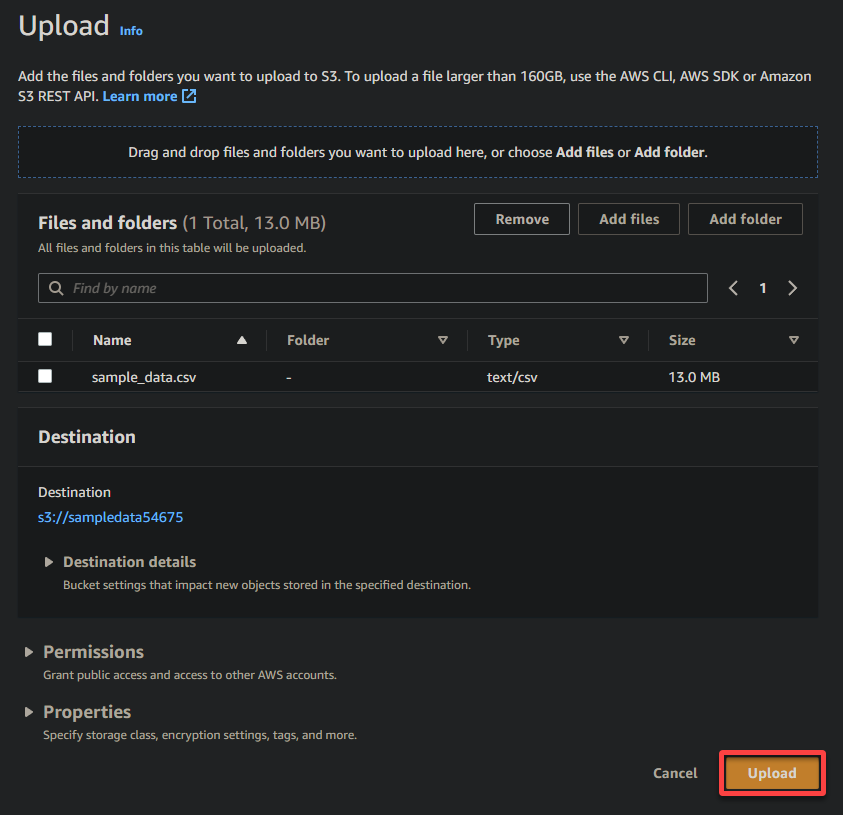
如果成功,您將在存儲桶中看到您新上傳的文件,如下所示。
創建一個 Glue 爬蟲來掃描和整理數據
您剛剛將樣本數據上傳到您的 S3 存儲桶,但由於它目前是非結構化的,您需要一種方法來讀取數據並建立元數據目錄。 如何?通過創建一個自動掃描和整理數據的 Glue 爬蟲。
要創建 Glue 爬蟲,請按照以下步驟進行:
1. 通過 AWS 管理控制台進入 AWS Glue 控制台,如下所示。
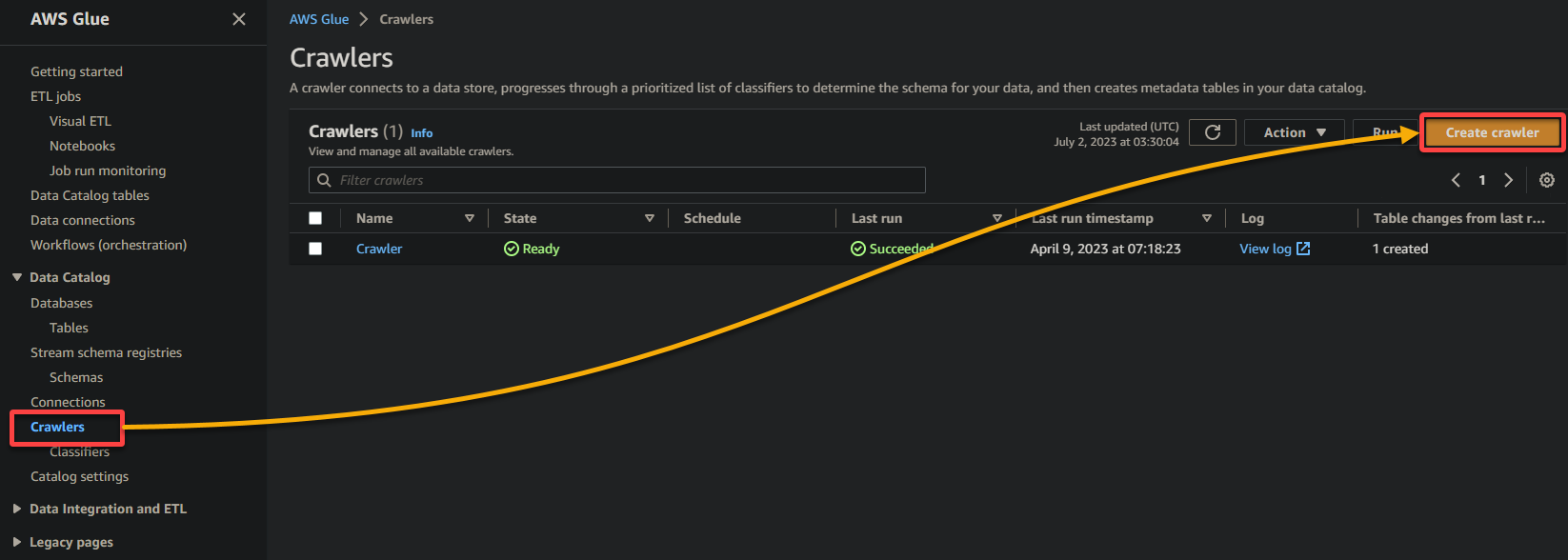
2. 接下來,切換到 爬蟲(左側窗格),並點擊 添加爬蟲(右上角)來開始創建新的 Glue 爬蟲。
3. 提供一個描述性名稱(即 glue_crawler)和爬蟲的描述,保持其他設置不變,並點擊 下一步。
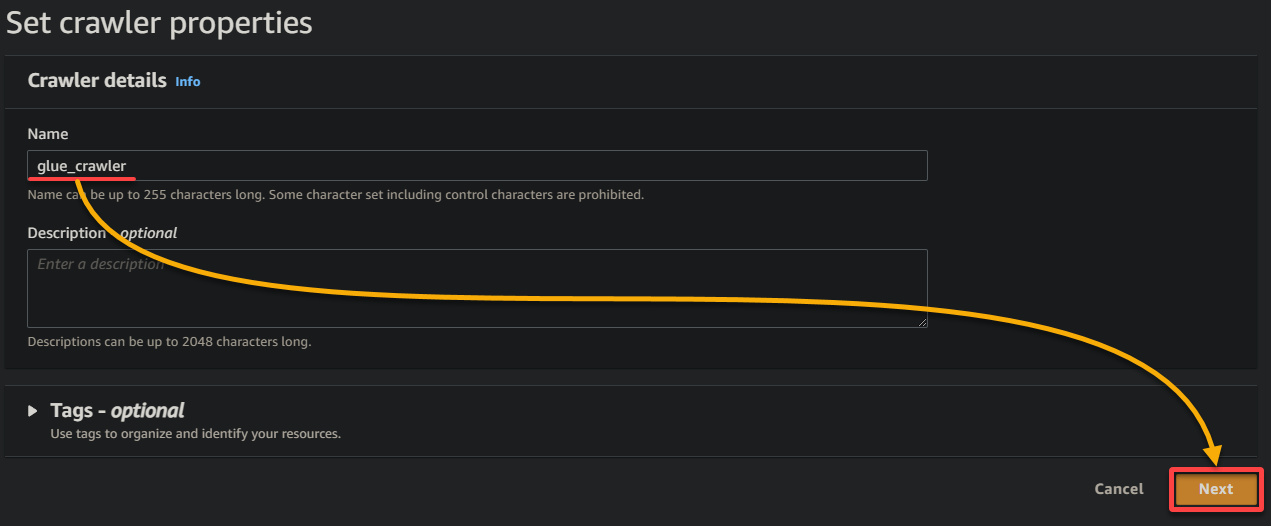
4. 現在,點擊 添加數據源 在 數據源 下開始添加爬蟲的新數據源。
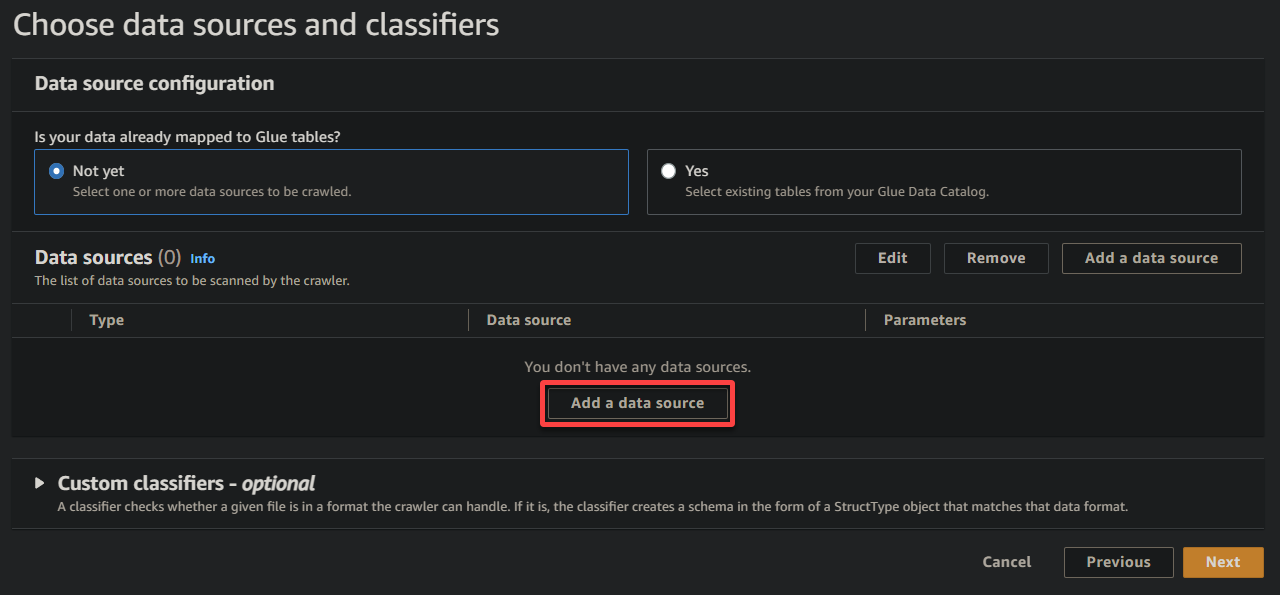
5. 在彈出窗口上,配置數據源如下:
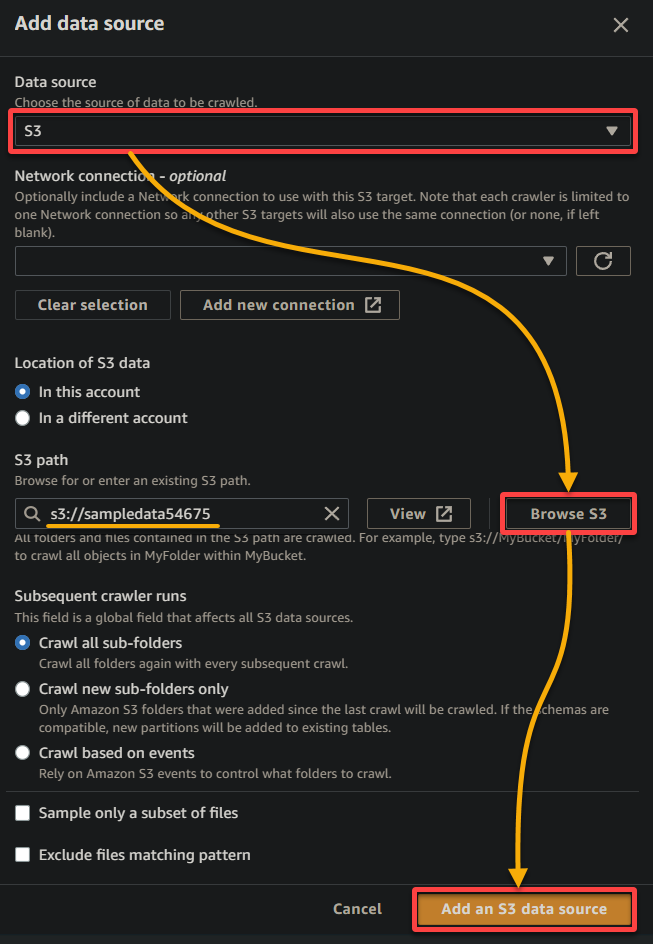
- 數據源 – 選擇 S3 因為您的數據在 S3 存儲桶中。
- S3 路徑 – 點擊 瀏覽 S3,並選擇包含您上傳的示例數據(sampledata54675)的存儲桶。
- 保持其他設置不變,然後點擊 添加 S3 數據源 將示例數據添加到爬蟲中。
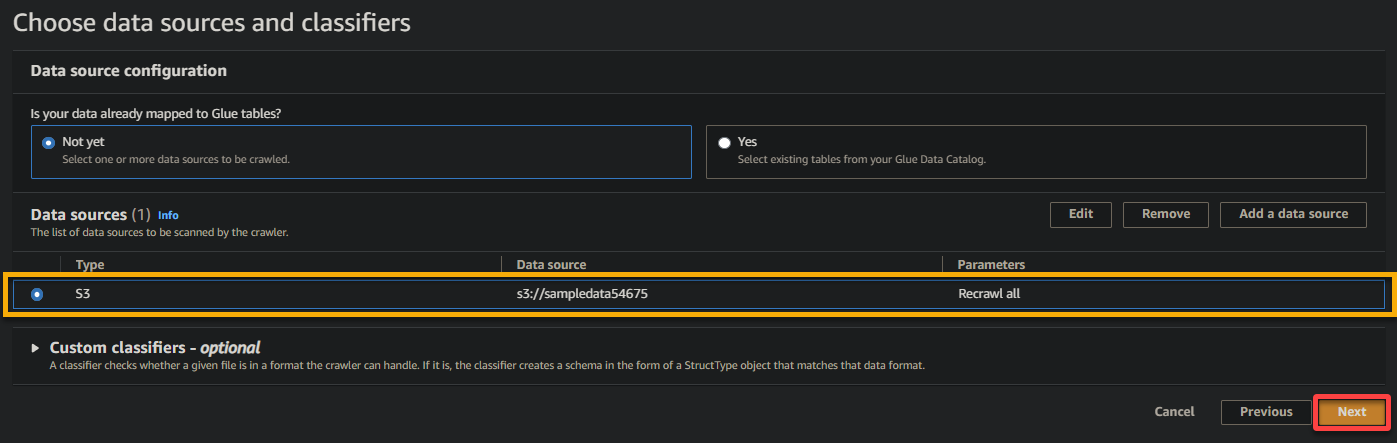
6. 配置完成後,驗證數據源,如下圖所示,然後點擊 下一步 繼續。
7. 在下一個畫面上,選擇您之前創建的 IAM 角色(glue_role),保持其他設置不變,然後點擊 下一步。
8. 在輸出和排程下,點擊 添加數據庫 開始添加新的數據庫,用於存儲您的 Glue 爬蟲生成的處理數據和元數據。此操作將打開一個新的瀏覽器選項卡,在那裡您將配置數據庫詳細信息(第八步)。
此數據庫提供了數據的結構化表示形式,以供查詢和分析使用。
9. 在新的瀏覽器選項卡上,提供一個描述性的數據庫名稱(即,glue_database),然後點擊 創建數據庫 來創建該數據庫。
10. 切換回之前的瀏覽器選項卡,從下拉菜單中選擇新創建的數據庫(glue_database),保持其他設置不變,然後點擊 下一步。
11. 最終,在最終畫面上審查您的設置以確保準確性,然後點擊 創建爬蟲(右下角)來創建新的爬蟲。
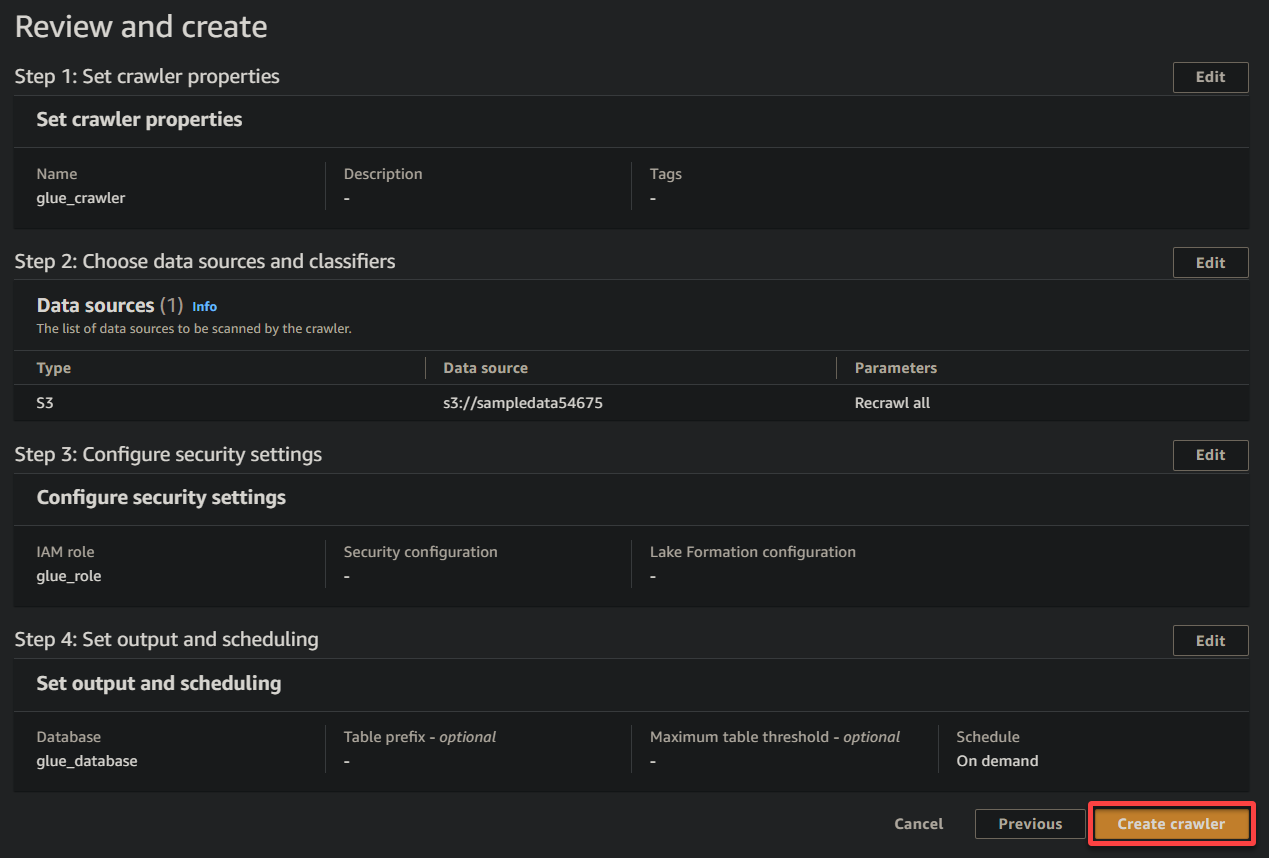
如果一切順利,您將看到一個屏幕確認爬蟲已成功創建。請不要立即關閉此屏幕;您將在下一節中運行此爬蟲。
運行Glue爬蟲以構建元數據目錄
擁有一個新的爬蟲,運行該爬蟲是啟動掃描和目錄化過程的關鍵。您的Glue爬蟲將構建一個元數據目錄,為查詢和分析提供結構化的數據表示。
運行您新創建的Glue爬蟲的步驟:
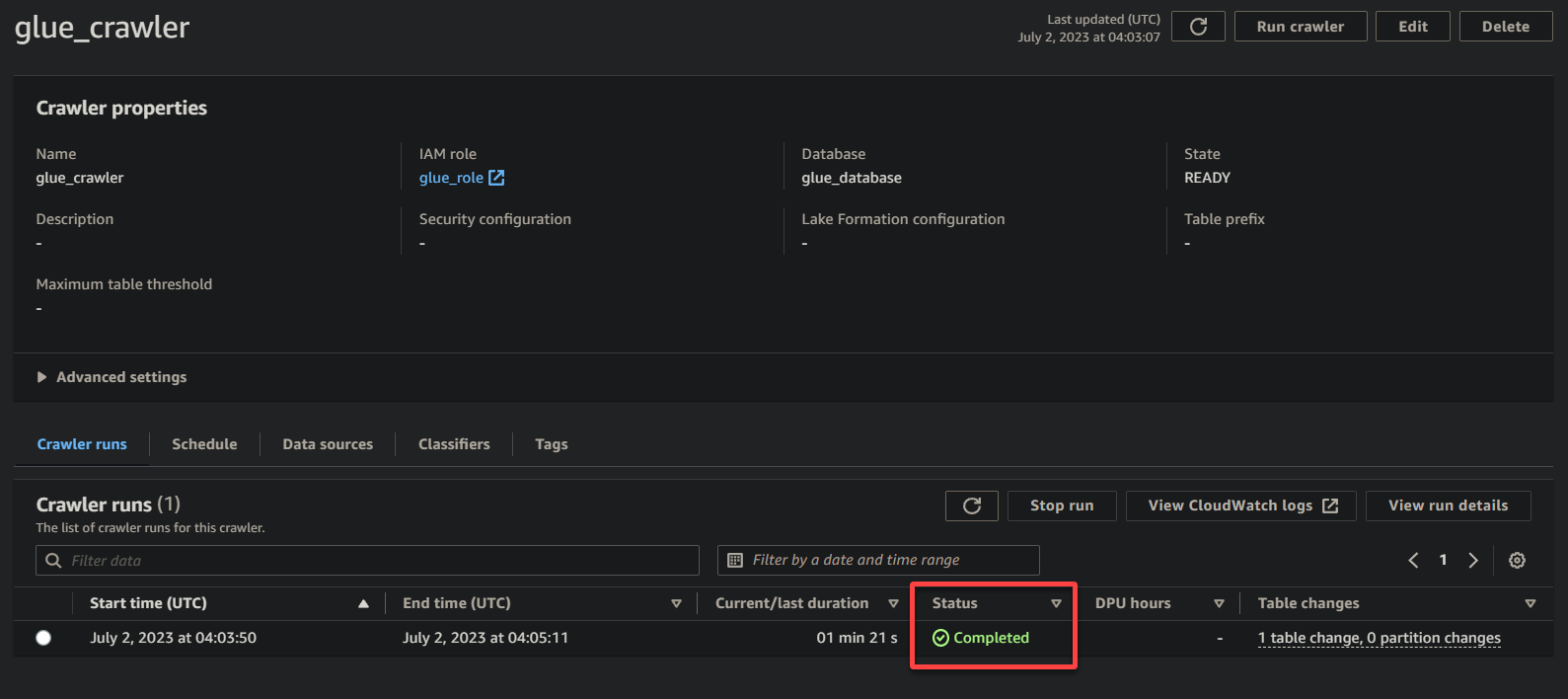
1. 在爬蟲詳細信息頁面上,單擊“ 運行爬蟲”位於“ 爬蟲運行”選項卡下,以啟動爬蟲的執行。
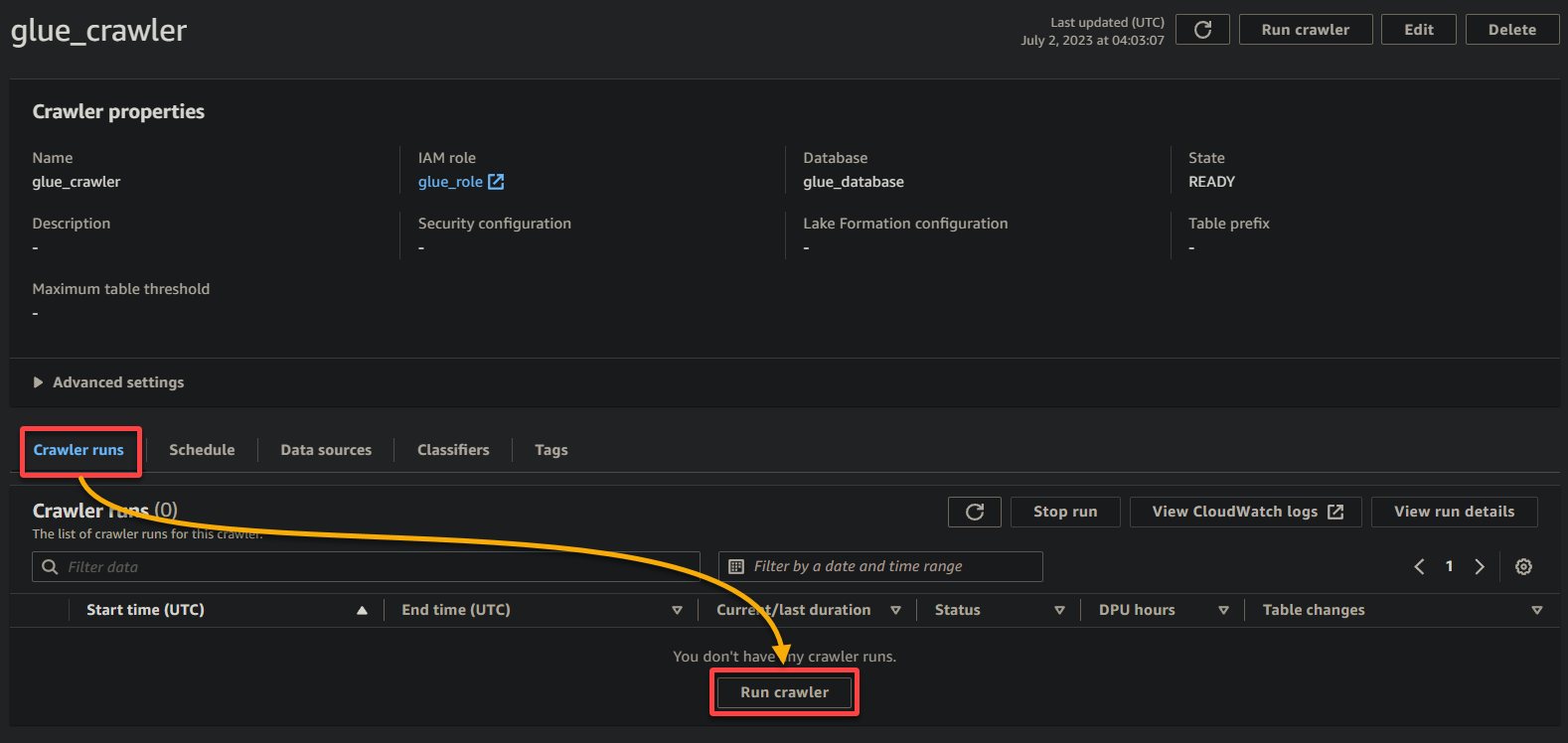
一旦爬蟲開始運行,您將在爬蟲詳細信息頁面上看到其狀態和進度。
根據您的數據大小和複雜性,爬蟲可能需要一些時間來完成執行。您可以定期刷新頁面以查看爬蟲的更新狀態。
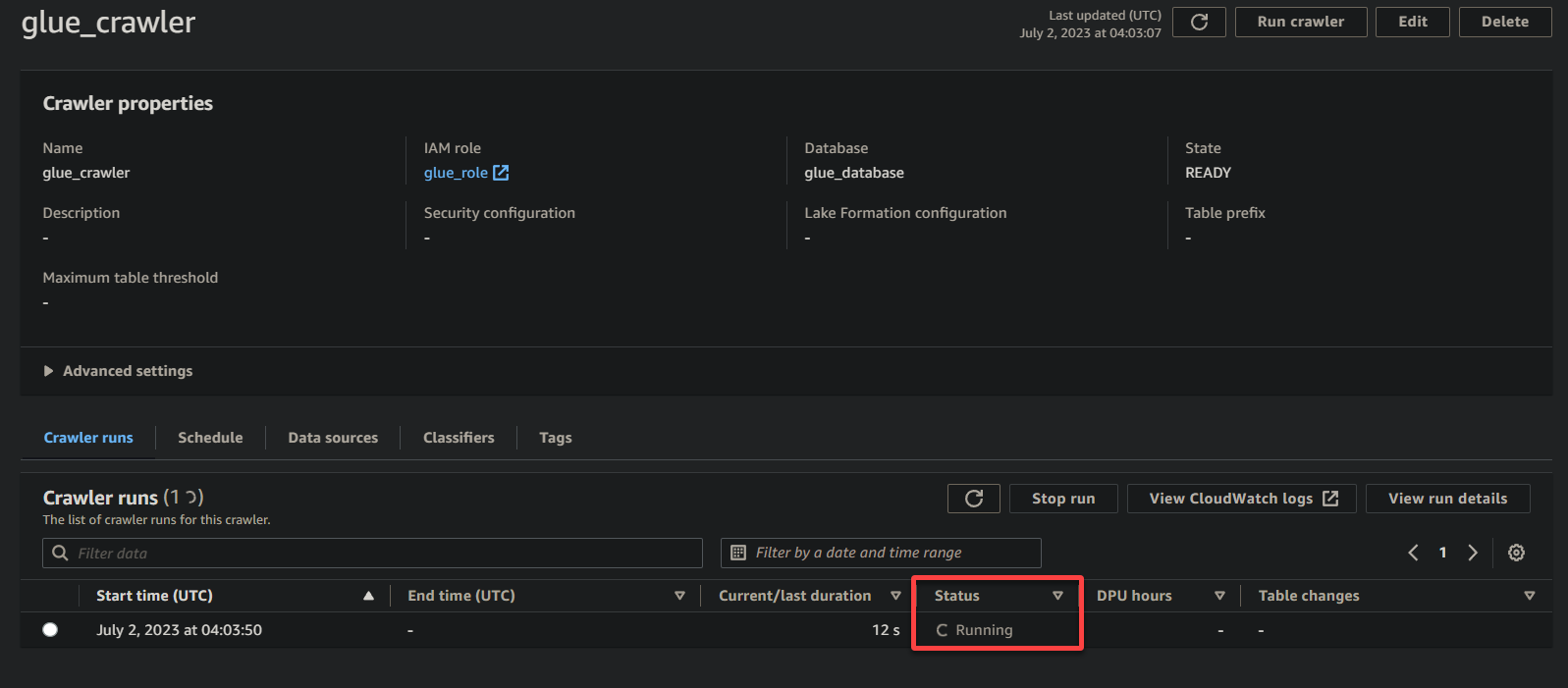
一旦爬蟲完成執行,其狀態將更改為已完成,如下圖所示。此時,您可以繼續查詢您的數據。
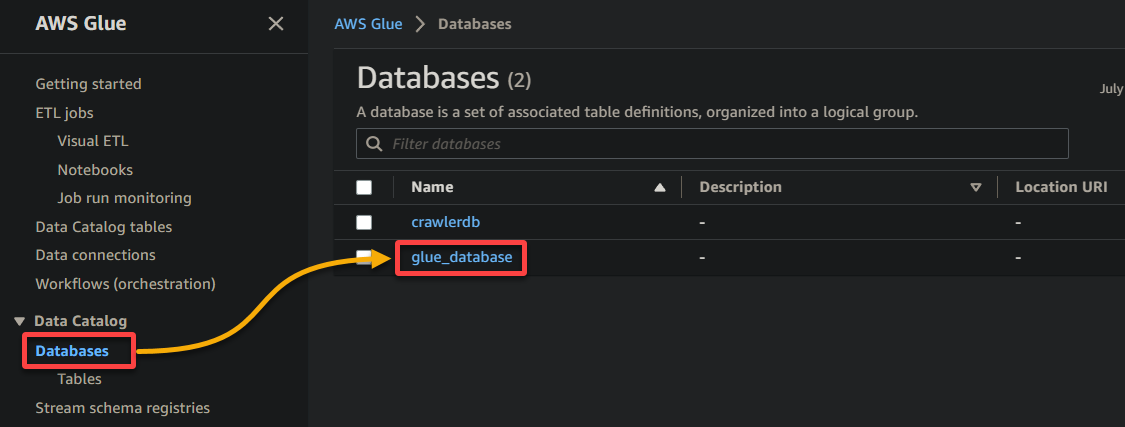
2. 接下來,切換到“ 數據庫”(左窗格),並點擊數據庫以訪問其屬性和表格。
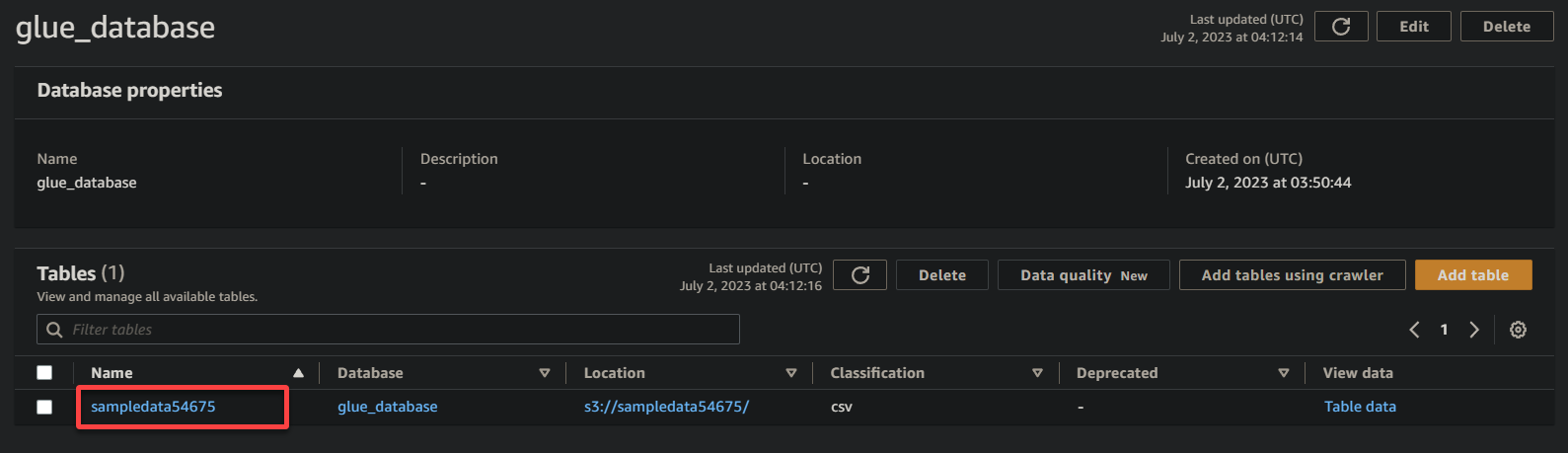
3. 最後,單擊您的存儲桶名稱(sampledata54675),現在是一個表,以查看其中存儲的數據。
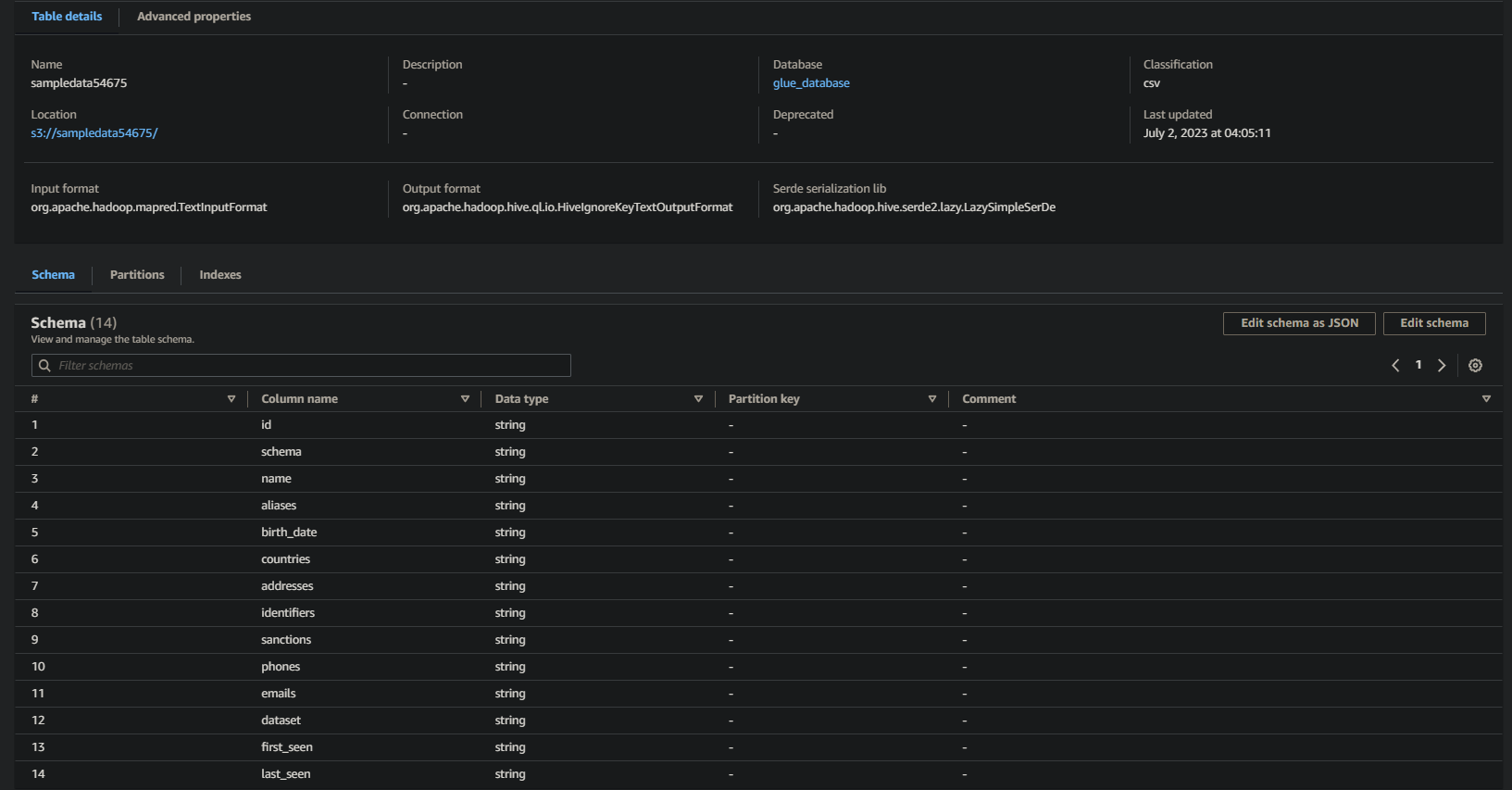
如果成功,您將看到以下類似的信息。此信息證實數據已成功轉換為數據庫表,提供有價值的詳細信息。
通過AWS Athena查詢已編目的數據
現在您的數據已經在AWS Glue數據目錄中可用,您可以使用各種工具查詢和分析您的數據。其中一個工具是AWS Athena,這是一個互動式查詢服務,可以使用標準SQL在雲中分析數據。
要使用AWS Athena查詢數據,請按照以下步驟進行:
1. 搜索並訪問Athena控制台。
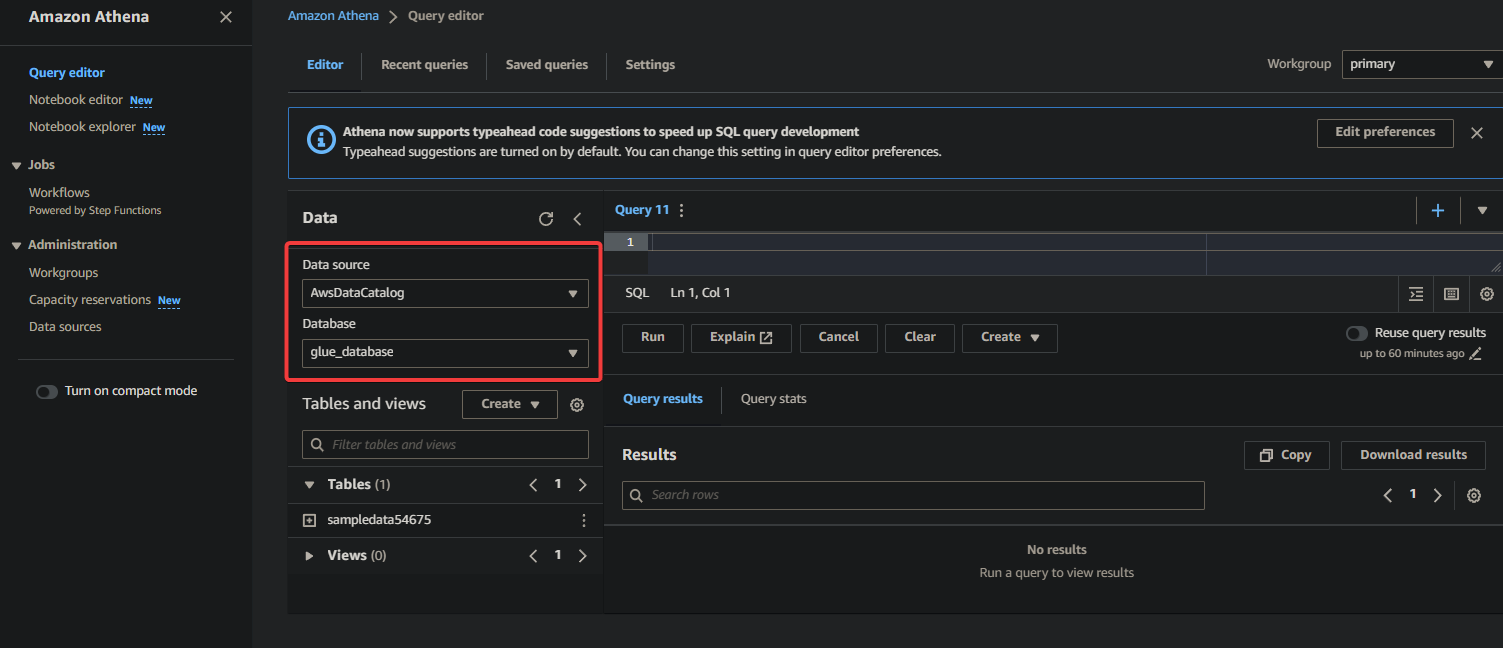
2. 選擇數據庫,在Data部分下目錄化您的數據,如下:
- 數據源 – 選擇AwsDataCatalog表示您要查詢在AWS Glue中目錄化的數據。
- 數據庫 – 從下拉字段中選擇適當的數據庫(即glue_database)。
? 如果在下拉列表中未看到所需的數據庫,請確保爬蟲已完成執行並目錄化數據。
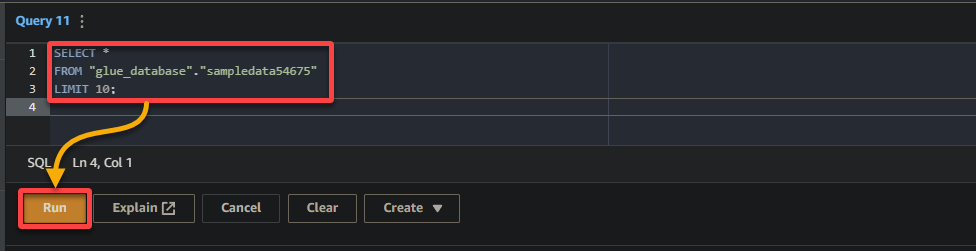
3. 最後,在右側的查詢編輯器中填寫並運行以下查詢。
此查詢將返回glue_database數據庫中sampledata54675表的前10行。隨時修改查詢以滿足您的具體要求。
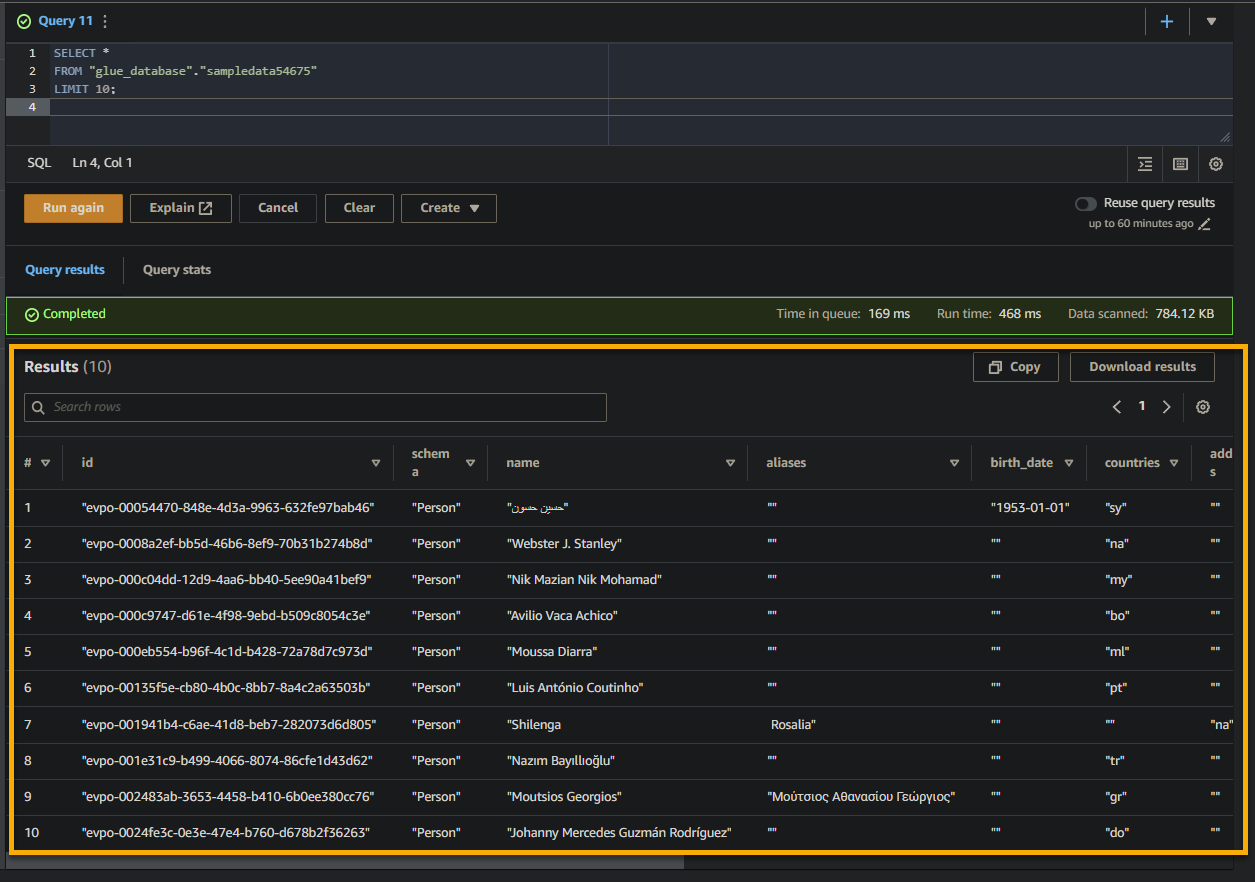
如果查詢成功,您將在結果窗格中看到結果,如下所示。結果包含有關根據您的SQL查詢存儲在表中的記錄的信息。
請注意查詢結果中的列名稱、數據類型和值。這些信息有助於您理解所查詢數據的結構和內容。
結論
在這個教程中,您已經學會了使用 AWS Glue 基本操作的基礎知識,包括創建 Glue Crawler、編目您的數據以及使用 AWS Athena 查詢數據。數據準備和分析對於任何數據驅動的應用程序都是至關重要的。而像 AWS Glue 這樣的工具提供了一種從各種來源提取、轉換和加載 (ETL) 數據到數據庫表中的快速方法。
有了 AWS Glue,您現在可以快速管理和組織數據,使您能夠更專注於分析和從數據中獲取見解。但是您所看到的僅僅是冰山一角。探索 AWS Glue 可提供的廣泛功能和功能!
為什麼不利用 AWS Glue 連接 與其他 AWS 服務(例如 Amazon RDS 或 Amazon Redshift)無縫集成呢?這種集成使您能夠構建復雜的 ETL 流水線,實現更大的數據分析能力。