













當我們在Linux中運行特定命令以從字符串或文件中讀取或編輯文本時,我們經常會嘗試將輸出過濾到感興趣的特定部分。這就是使用正則表達式的地方。
什么是正则表达式?
A regular expression can be defined as strings that represent several sequences of characters. One of the most important things about regular expressions is that they allow you to filter the output of a command or file, edit a section of a text or configuration file, and so on.
正则表达式的特点
正则表达式由以下内容组成:
- 普通字符,如空格、下划线(_)、A-Z、a-z、0-9。
- 元字符,被扩展为普通字符,包括:
(.)它匹配除换行符外的任何单个字符。(*)它匹配其前面的字符的零个或多个存在。[字符(们)]它匹配字符(们)中指定的任何一个字符,也可以使用连字符(-)表示字符范围,如[a-f]、[1-5]等。^它匹配文件中一行的开头。$它匹配文件中一行的结尾。\它是转义字符。
为了过滤文本,人们必须使用诸如 awk 这样的文本过滤工具。您可以将 awk 视为一种独立的编程语言。但是在本指南中使用 awk,我们将把它介绍为一个简单的 命令行过滤工具。
awk 的一般语法是:
awk 'script' filename
其中 'script' 是一组由 awk 理解并在文件 filename 上执行的命令。
它通过读取文件中给定的一行,复制该行,然后在该行上执行脚本来工作。这在文件中的所有行上重复进行。
脚本的形式为 '/pattern/ action' 其中 pattern 是一个正则表达式,action 是当 awk 在一行中找到给定模式时将执行的操作。
如何在 Linux 中使用 Awk 过滤工具
在以下示例中,我们将专注于上面讨论的 awk 特性下的元字符。
使用 Awk 打印文件中的所有行
以下示例打印文件 /etc/hosts 中的所有行,因为没有给出模式。
awk '//{print}'/etc/hosts
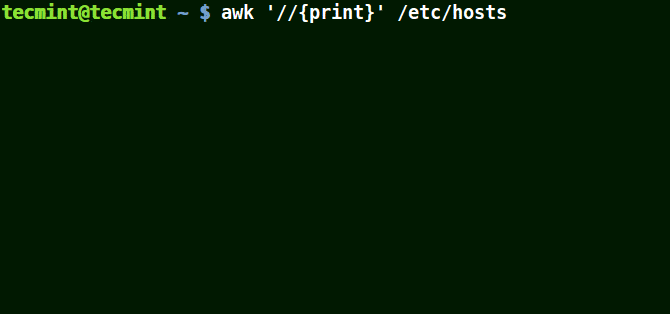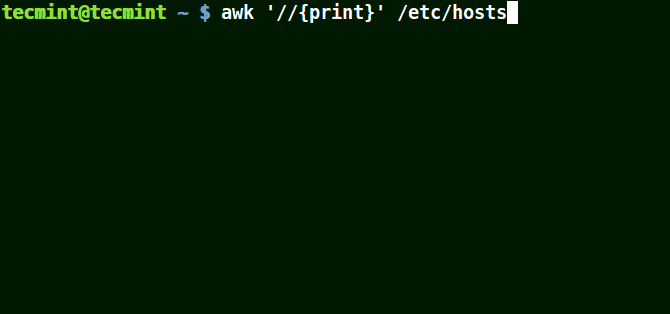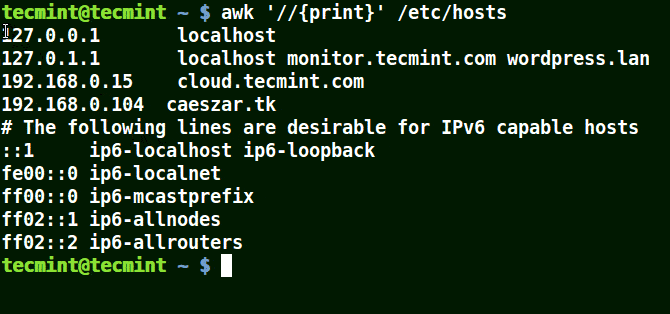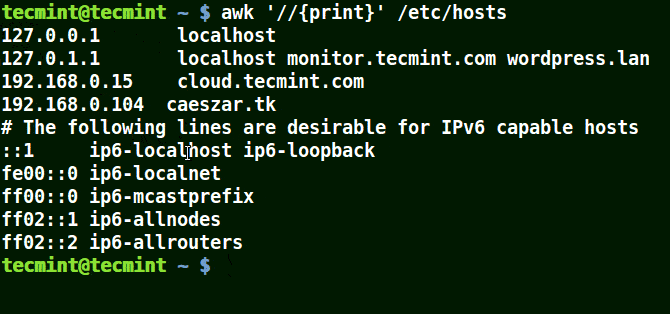
使用 Awk 模式:匹配文件中含有“localhost”的行
在下面的例子中,模式localhost已经给出,所以awk将匹配在/etc/hosts文件中包含localhost的行。
awk '/localhost/{print}' /etc/hosts

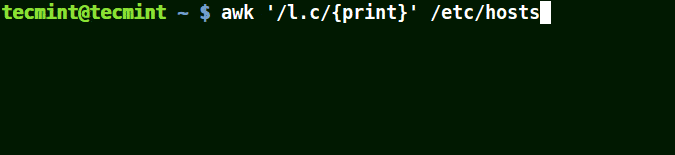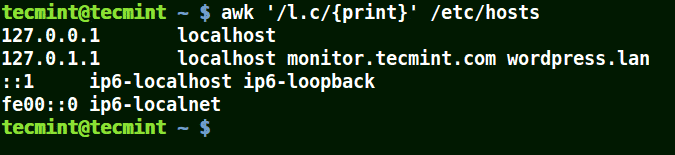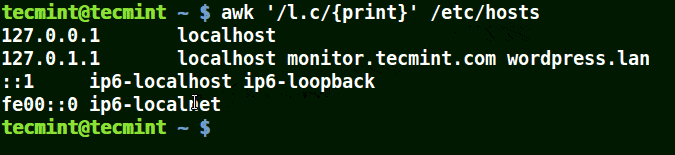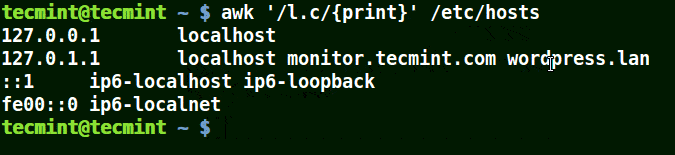
在模式中使用(.)通配符
(.)将匹配包含loc、localhost、localnet的字符串,如下例所示。
也就是说* l some_single_character c *。
awk '/l.c/{print}' /etc/hosts
在模式中使用(*)字符
它将匹配包含localhost、localnet、lines、capable的字符串,如下例所示:
awk '/l*c/{print}' /etc/localhost
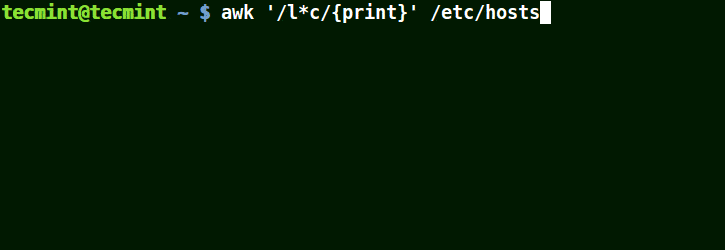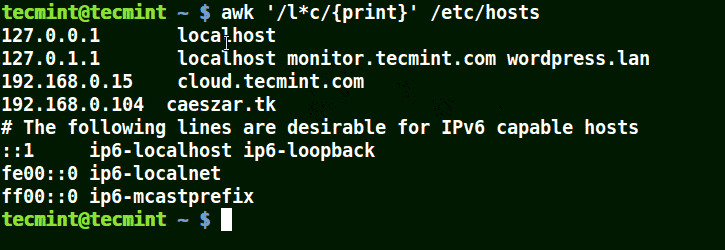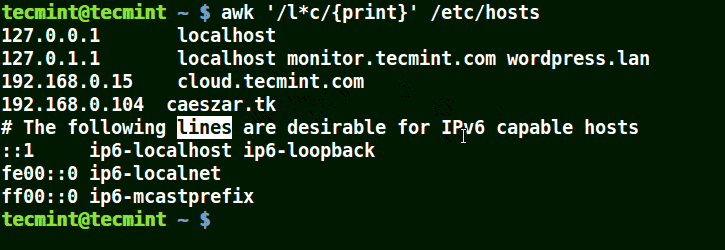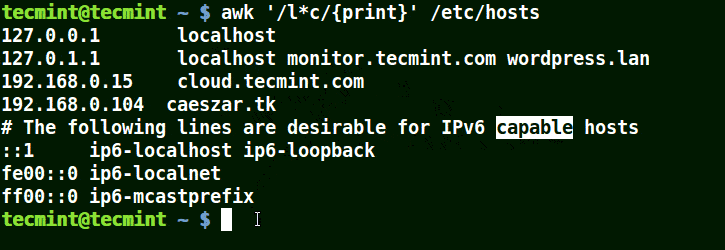
您还会意识到,(*)试图提供尽可能长的匹配。
让我们看一个演示这一点的案例,拿下面这行的正则表达式t*t来说,它意味着匹配以字母t开头并以t结尾的字符串:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
当您使用模式/t*t/时,您会得到以下可能性:
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
而/t*t/中的(*)通配符允许awk选择最后一种选项:
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
使用带有集合[字符]的Awk
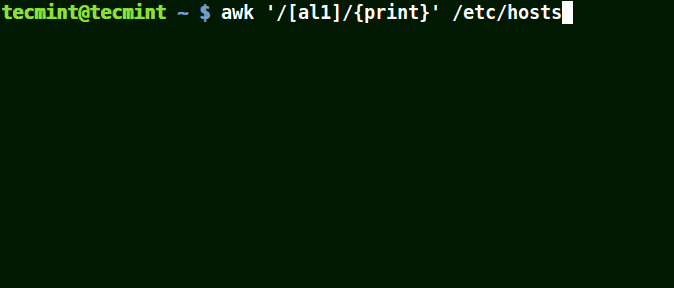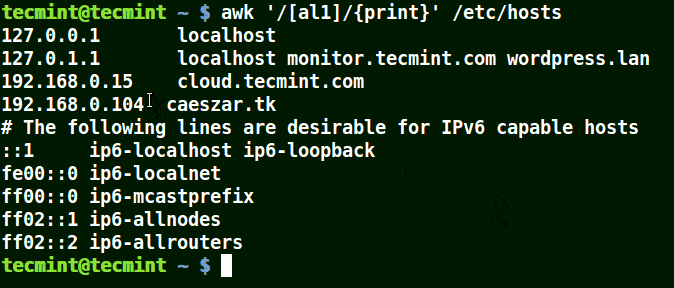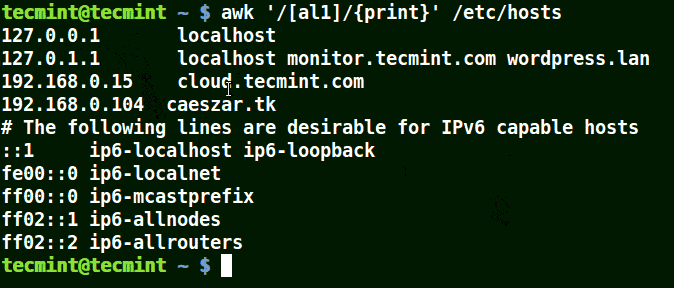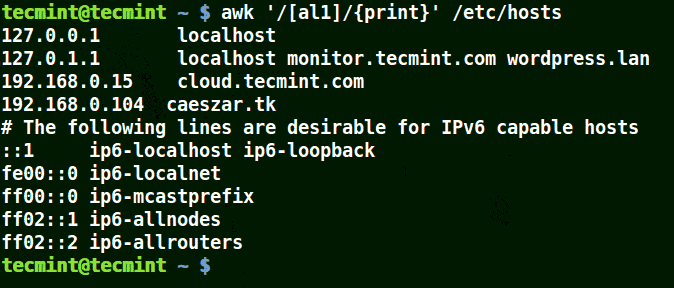
以集合[al1]为例,在这里awk将匹配文件/etc/hosts中包含字符a、l或1的所有字符串。
awk '/[al1]/{print}' /etc/hosts
下一个例子匹配以K或k开头,后跟T的字符串:
# awk '/[Kk]T/{print}' /etc/hosts

範圍內指定字符
理解 awk 中的字符:
[0-9]意味著單個數字[a-z]意味著匹配單個小寫字母[A-Z]意味著匹配單個大寫字母[a-zA-Z]意味著匹配單個字母[a-zA-Z 0-9]意味著匹配單個字母或數字
讓我們看一個例子:
awk '/[0-9]/{print}' /etc/hosts
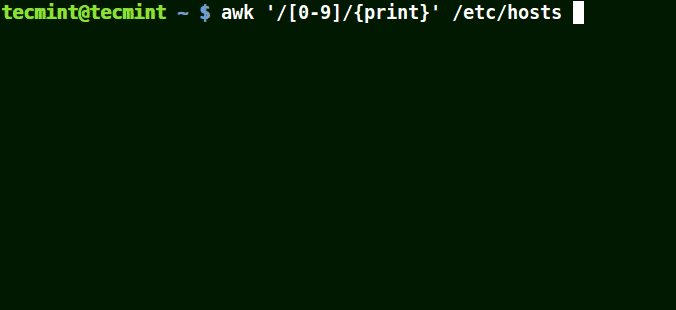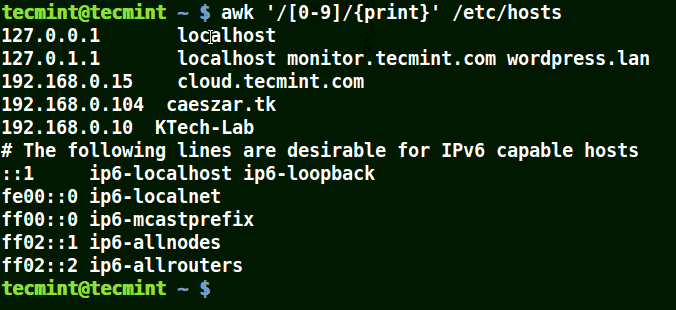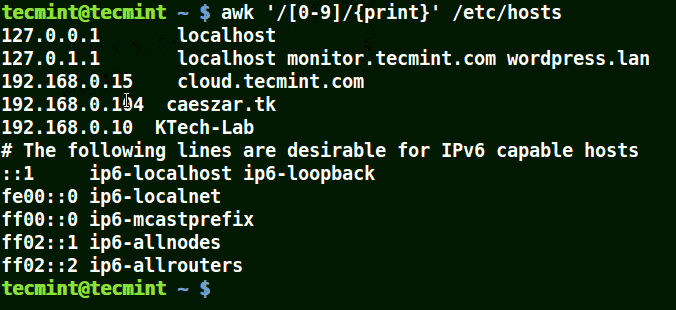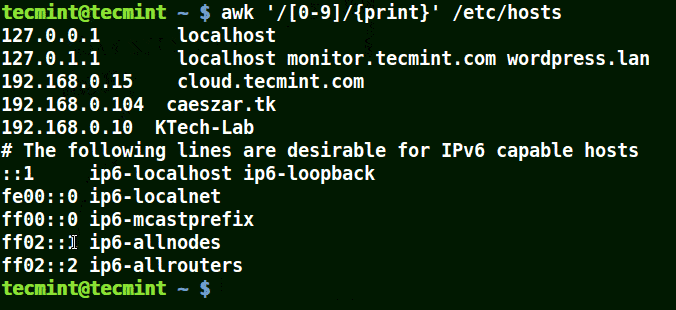
在上面的例子中,文件/etc/hosts中的所有行至少包含一個數字[0-9]。
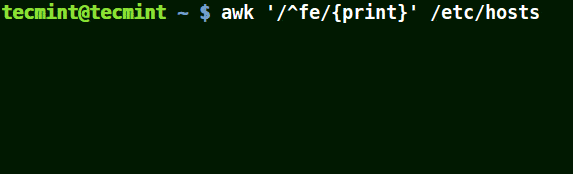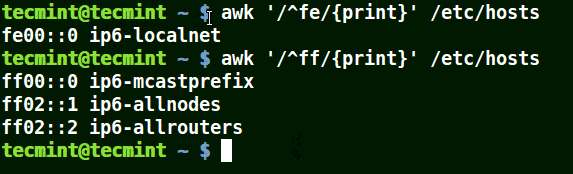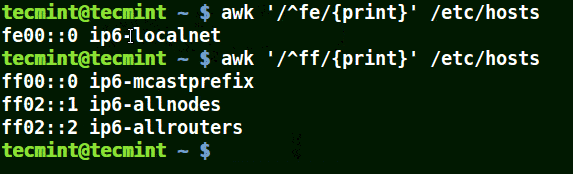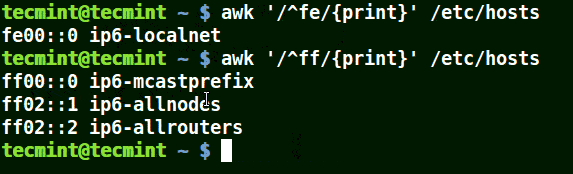
使用帶有 (^) 元字符的 Awk
它匹配所有以提供的模式開頭的行,如下例所示:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
使用帶有 ($) 元字符的 Awk
它匹配所有以提供的模式結尾的行:
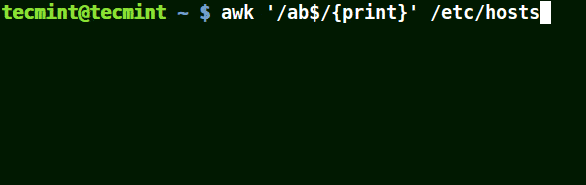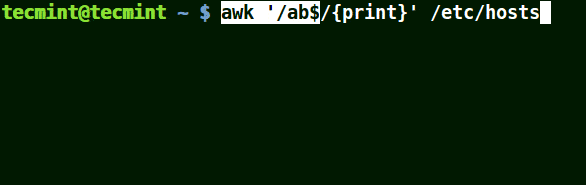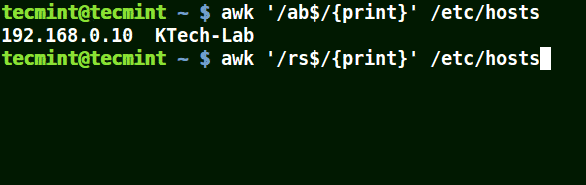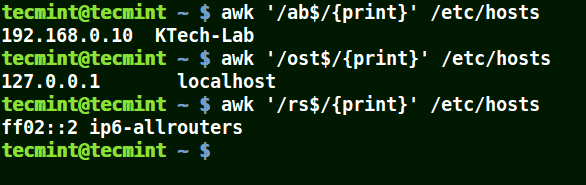
awk '/ab$/{print}' /etc/hosts
awk '/ost$/{print}' /etc/hosts
awk '/rs$/{print}' /etc/hosts
使用帶有 (\) 轉義字符的 Awk
它允許您將其後的字符視為字面上的,即將其視為原樣。
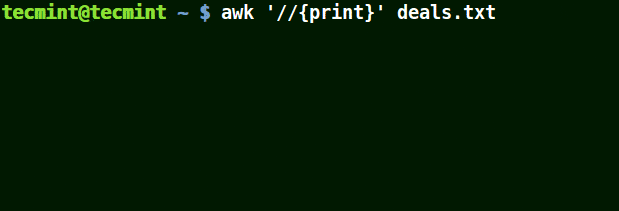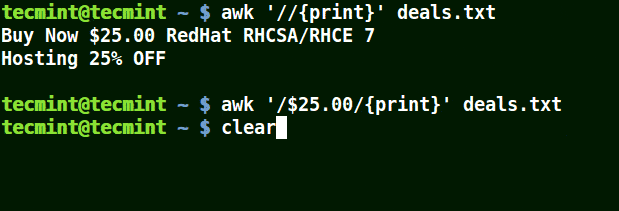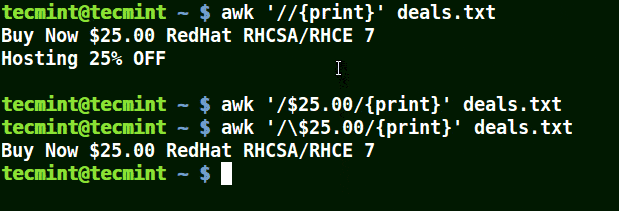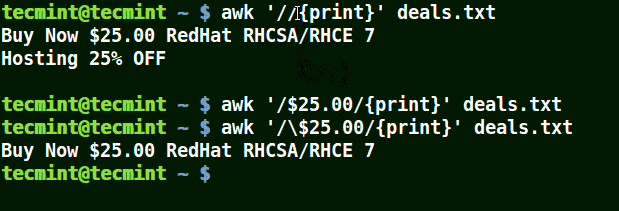
在下面的例子中,第一個命令打印文件中的所有行,第二個命令不打印任何內容,因為我想匹配包含 $25.00 的行,但未使用轉義字符。
第三個命令是正確的,因為已使用轉義字符來讀取 $ 如其所示。
awk '//{print}' deals.txt
awk '/$25.00/{print}' deals.txt
awk '/\$25.00/{print}' deals.txt
摘要
這還不是所有的 awk 命令行篩選工具,上面的例子是 awk 的基本操作。在接下來的部分中,我們將深入探討如何使用 awk 的複雜功能。
感謝您的閱讀,請在評論部分發表任何補充或澄清。
Source:
https://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/