













正規表現とは何ですか?
A regular expression can be defined as strings that represent several sequences of characters. One of the most important things about regular expressions is that they allow you to filter the output of a command or file, edit a section of a text or configuration file, and so on.
正規表現の特徴
正規表現は次のように構成されています:
- 普通の文字(スペース、アンダースコア(_)、A-Z、a-z、0-9など)
- メタ文字は、普通の文字に展開される文字で、次のようになります:
(.)それは改行以外の任意の一文字に一致します。(*)直前の文字のゼロ回以上の出現に一致します。[文字(たち)]指定された文字(たち)のいずれかに一致します。文字の範囲を表すためにハイフン(-)を使用することもできます。[a-f]、[1-5]など。^ファイル内の行の先頭に一致します。$ファイル内の行の末尾に一致します。\それはエスケープ文字です。
テキストをフィルタリングするには、awkのようなテキストフィルタリングツールを使用する必要があります。 awkは独自のプログラミング言語と考えることができますが、このawkの使用ガイドの範囲では、それを単純なコマンドラインフィルタリングツールとしてカバーします。
awkの一般的な構文は次のとおりです:
awk 'script' filename
ここで、'script'はawkによって理解され、ファイル名で実行される一連のコマンドです。
これは、ファイル内の指定された行を読み取り、その行のコピーを作成し、次にスクリプトを行に対して実行することによって機能します。これはファイル内のすべての行に対して繰り返されます。
'script'は'/pattern/ action'の形式であり、patternは正規表現であり、actionはawkが行内の指定されたパターンを見つけたときに行う動作です。
LinuxでAwkフィルタリングツールを使用する方法
次の例では、上記で議論したメタ文字に焦点を当てます。
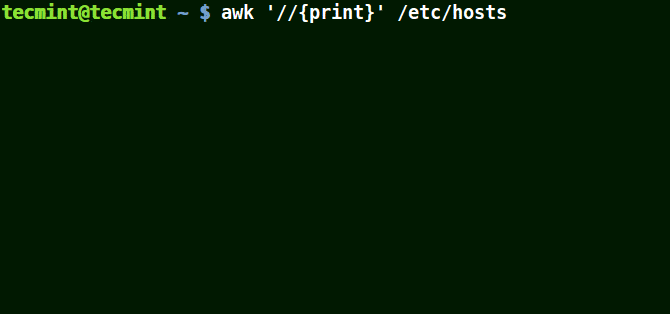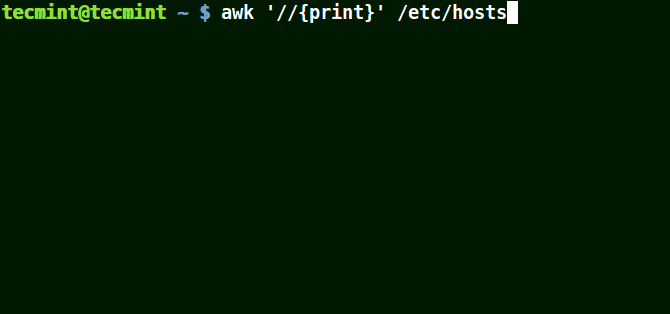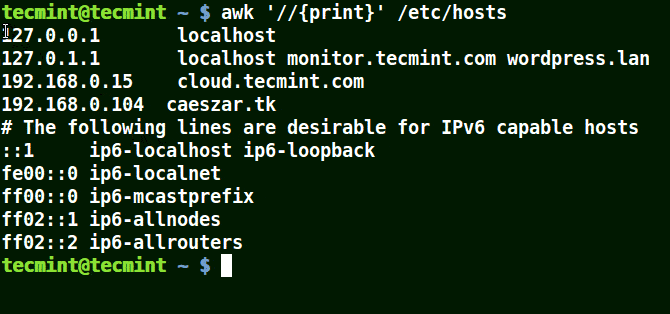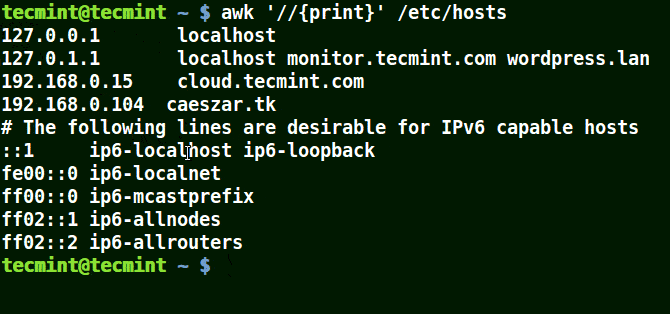
Awkを使用してファイル内のすべての行を印刷する
以下の例では、パターンが指定されていないため、ファイル/etc/hosts内のすべての行が印刷されます。
awk '//{print}'/etc/hosts
Awkパターンの使用:ファイル内の ‘localhost’ に一致する行
/etc/hosts ファイルに localhost を含む行が一致します。
awk '/localhost/{print}' /etc/hosts

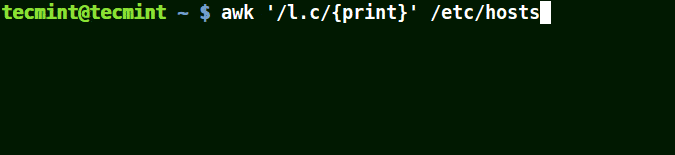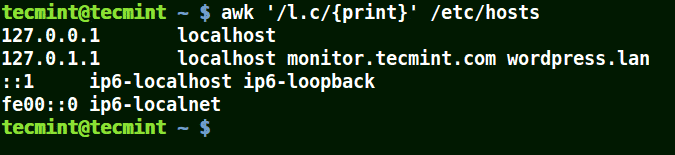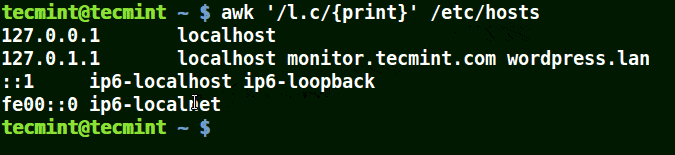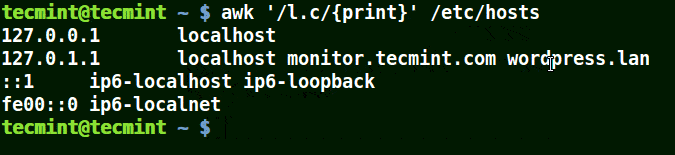
パターンに (.) ワイルドカードを使用する
(.) は、以下の例に示すように、loc、localhost、localnet を含む文字列に一致します。
つまり、* l 1文字のみ c * です。
awk '/l.c/{print}' /etc/hosts
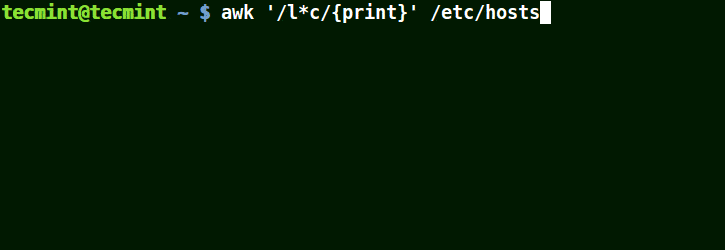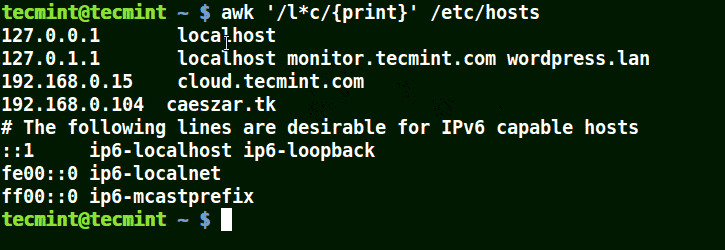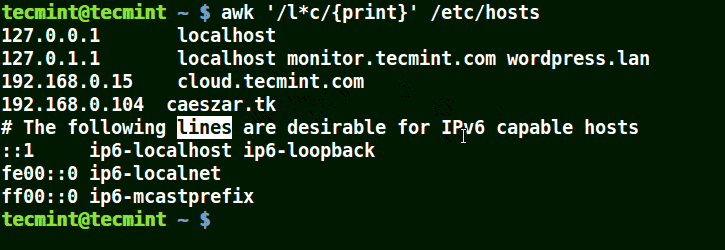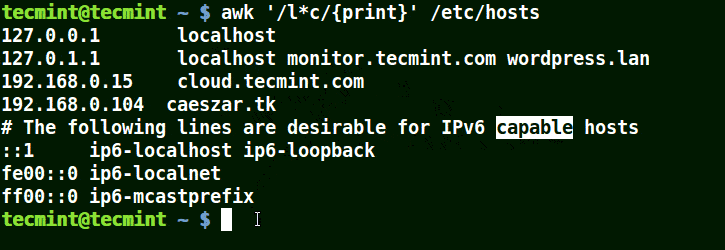
パターンに (*) 文字を使用する Awk
以下の例に示すように、localhost、localnet、lines、capable を含む文字列に一致します。
awk '/l*c/{print}' /etc/localhost
また、(*) は可能な限り最長の一致を取得しようとします。
これを示すケースを見てみましょう。以下の行で、t で始まり t で終わる文字列に一致する正規表現 t*t を取り上げます。
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint.
パターン /t*t/ を使用すると、次の可能性が得られます:
this is t this is tecmint this is tecmint, where you get t this is tecmint, where you get the best good t this is tecmint, where you get the best good tutorials, how t this is tecmint, where you get the best good tutorials, how tos, guides, t this is tecmint, where you get the best good tutorials, how tos, guides, tecmint
そして、/t*t/ の (*) ワイルドカード文字は Awk に最後のオプションを選択させます。
this is tecmint, where you get the best good tutorials, how to's, guides, tecmint
セット [ 文字 ] を使用する Awk
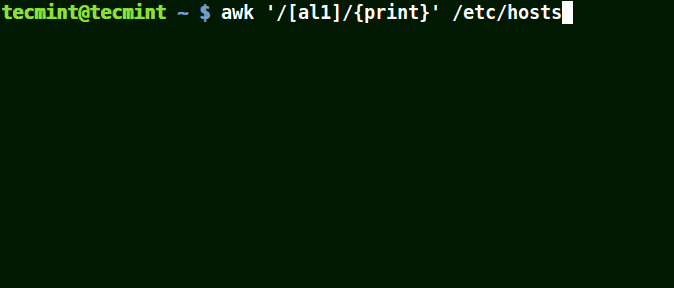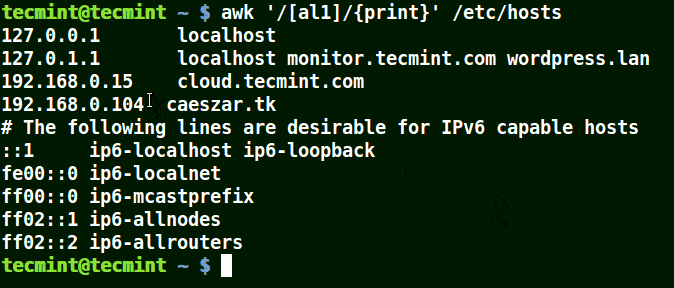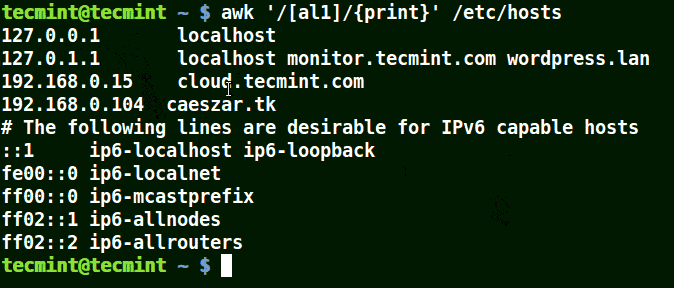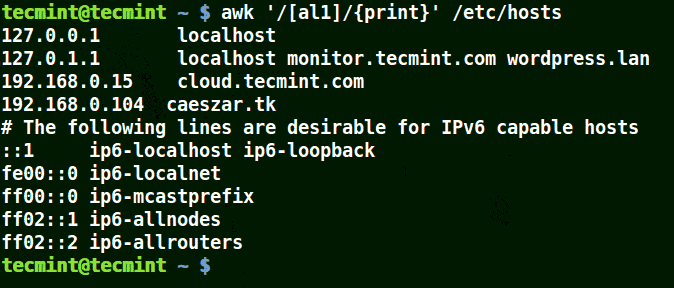
たとえばセット [al1] を取り上げると、ここでは a または l または 1 を含むすべての文字列に一致します。/etc/hosts ファイルの行。
awk '/[al1]/{print}' /etc/hosts
次の例は、K または k で始まり、その後に T が続く文字列に一致します:
# awk '/[Kk]T/{print}' /etc/hosts

範囲内の文字の指定
[0-9]は単一の数字を意味します[a-z]は単一の小文字を一致させます[A-Z]は単一の大文字を一致させます[a-zA-Z]は単一の文字を一致させます[a-zA-Z 0-9]は単一の文字または数字を一致させます
以下は例です:
awk '/[0-9]/{print}' /etc/hosts
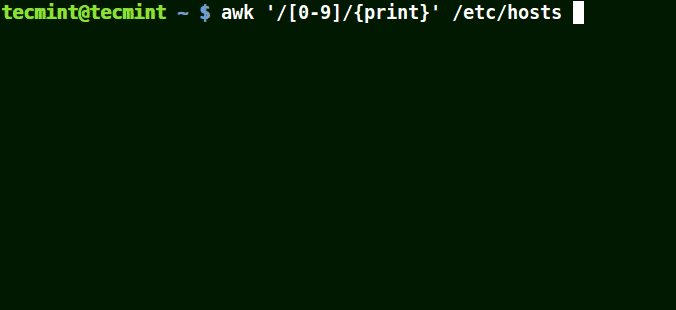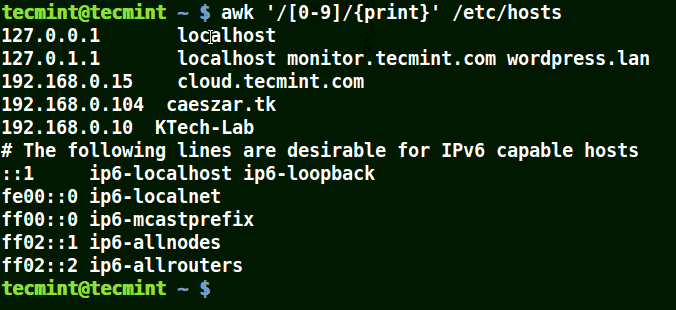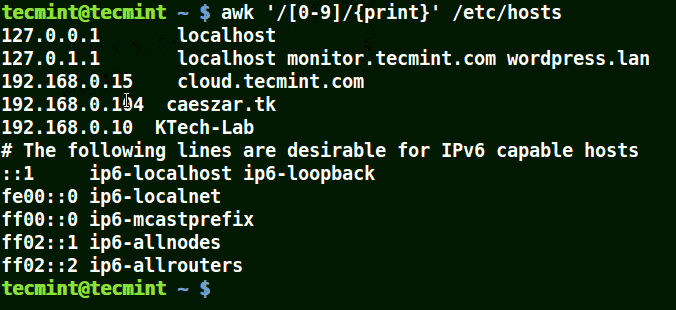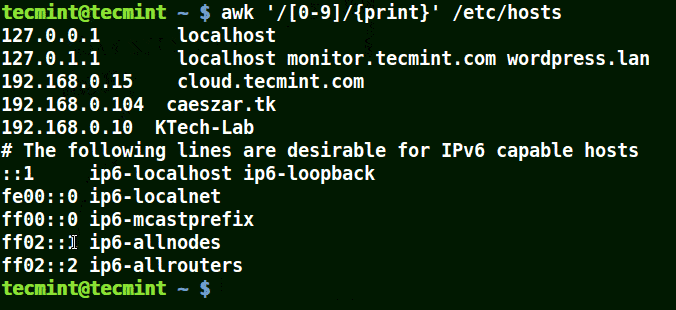
ファイル/etc/hostsからのすべての行は、上記の例では少なくとも単一の数字[0-9]を含みます。
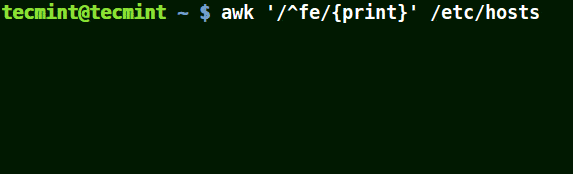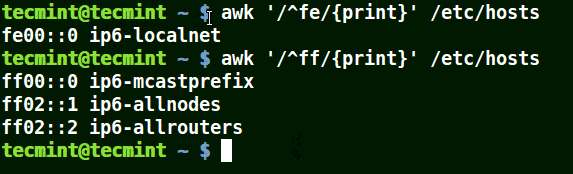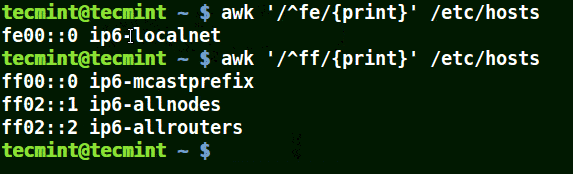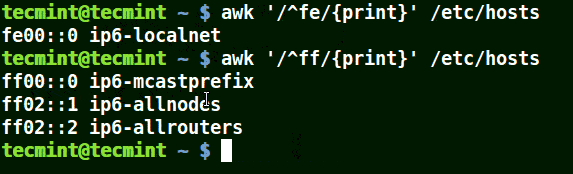
先頭に(^)メタキャラクタを使用する
提供されたパターンで始まるすべての行に一致します。以下の例をご覧ください:
# awk '/^fe/{print}' /etc/hosts
# awk '/^ff/{print}' /etc/hosts
(?)メタキャラクタを使用する
提供されたパターンで終わるすべての行に一致します:
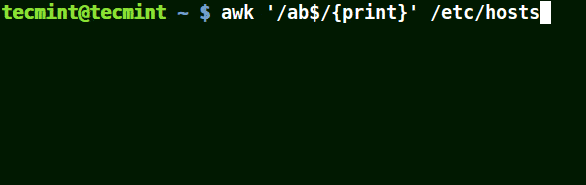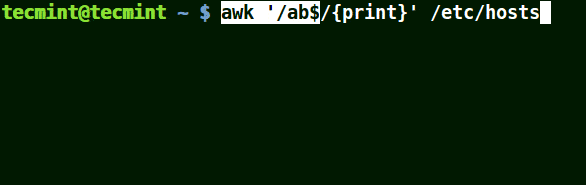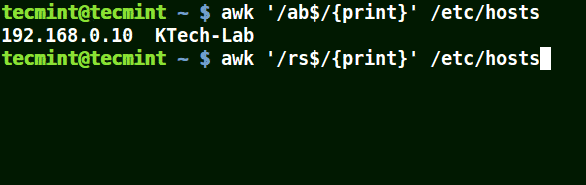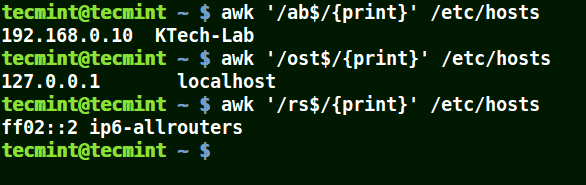
awk '/ab$/{print}' /etc/hosts
awk '/ost$/{print}' /etc/hosts
awk '/rs$/{print}' /etc/hosts
(\)エスケープキャラクタを使用する
後続する文字をそのままのリテラルとして扱い、そのままとして考慮します。
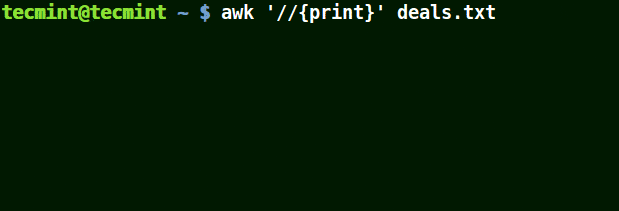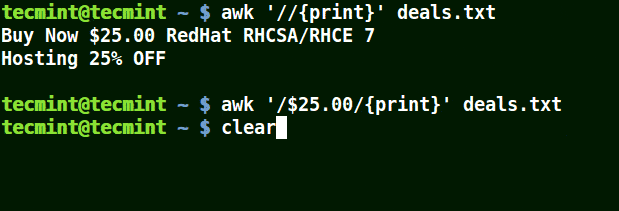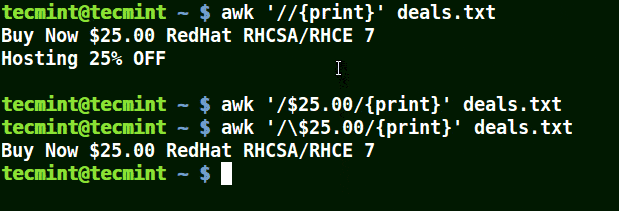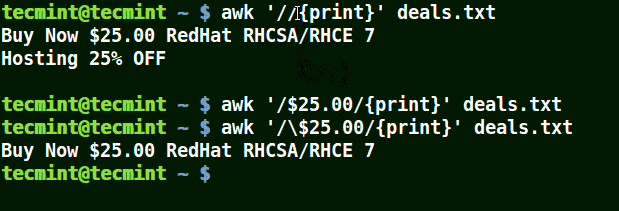
以下の例では、最初のコマンドはファイル内のすべての行を表示し、2番目のコマンドは$25.00を含む行に一致させたいが、エスケープ文字が使用されていないため、何も表示しません。
3番目のコマンドは正しいです、なぜなら、エスケープ文字が使用されているため、$をそのまま読み取ります。
awk '//{print}' deals.txt
awk '/$25.00/{print}' deals.txt
awk '/\$25.00/{print}' deals.txt
要約
awkコマンドラインフィルタリングツールについて、上記の例はawkの基本操作です。次の部分では、awkの複雑な機能の使用方法について詳しく説明します。
ありがとうございます。追加や説明があれば、コメント欄にコメントを投稿してください。
Source:
https://www.tecmint.com/use-linux-awk-command-to-filter-text-string-in-files/