













在一個數據生成指數性增長的時代,組織必須有效利用這些信息的財富來維持其競爭優勢。高效搜尋和分析客戶數據——例如識別用戶對電影推薦的偏好或情感分析——在促進知情決策和提升用戶體驗方面扮演著至關重要的角色。例如,流媒體服務可以利用向量搜尋來推薦符合個別觀看歷史和評分的電影,而零售品牌則可以分析客戶情感,以微調營銷策略。
作為數據工程師,我們的任務是實施這些複雜的解決方案,確保組織能從龐大的數據集中獲取可行的洞察。本文探討了使用Elasticsearch的向量搜尋的複雜性,重點介紹有效技術和最佳實踐以優化性能。通過研究個性化營銷的圖像檢索和客戶情感聚類的文本分析案例,我們展示了如何優化向量搜尋以促進客戶互動和顯著的業務增長。
什麼是向量搜尋?
向量搜索是一種強大的方法,通過在高維空間中將數據點表示為向量來識別它們之間的相似性。這種方法特別適用於需要根據屬性迅速檢索相似項目的應用程序。
向量搜索示例
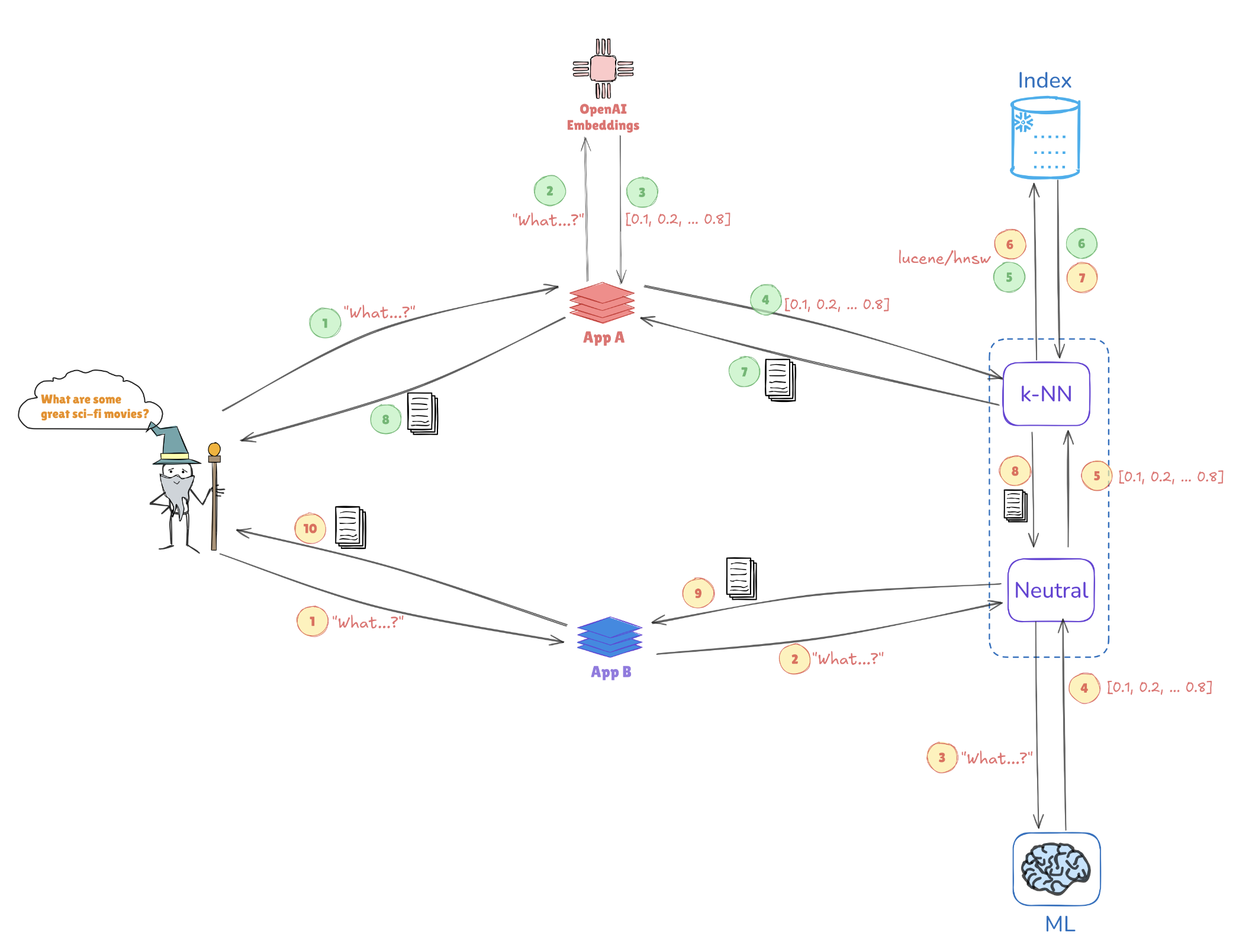
考慮下面的示例,它展示了向量表示如何實現相似性搜索:
- 查詢嵌入:查詢“一些很棒的科幻電影是什麼?”轉換為向量表示,例如[0.1, 0.2, …, 0.4]。
- 索引:將該向量與存儲在Elasticsearch中的預先索引的向量進行比較(例如,來自AppA和AppB等應用程序),以查找相似的查詢或數據點。
- k-NN搜索:使用像k-最近鄰居(k-NN)這樣的算法,Elasticsearch有效地從索引的向量中檢索出前幾個匹配項,幫助快速識別最相關的信息。
這種機制使Elasticsearch在推薦系統、圖像搜索和自然語言處理等用例中表現出色,其中理解上下文和相似性至關重要。
使用Elasticsearch進行向量搜索的主要優勢
高維度支持
Elasticsearch 在管理複雜數據結構方面表現出色,這對於 AI 和 機器學習 應用至關重要。當處理多面向數據類型,例如圖像或文本數據時,這一能力尤為重要。
擴展性
其架構支持水平擴展,使企業能夠處理不斷增長的數據集而不影響性能。隨著數據量的持續增長,這一點至關重要。
整合
Elasticsearch 與 Elastic stack 無縫協作,提供了一個全面的數據攝取、分析和可視化解決方案。這種整合確保數據工程師能夠利用統一的平台進行各種數據處理任務。
優化向量搜索性能的最佳實踐
1. 減少向量維度
減少向量的維度可以顯著提升搜索性能。像 PCA(主成分分析)或 UMAP(均勻流形近似和投影)等技術有助於保持基本特徵,同時簡化數據結構。
範例:使用 PCA 進行維度減少
以下是如何在 Python 中使用 Scikit-learn 實現 PCA:
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. 高效索引
利用近似最近鄰(ANN)算法可以顯著加快搜索時間。考慮使用:
- HNSW(層次可導航小世界):以其性能和準確性的平衡而聞名。
- FAISS(Facebook AI 相似性搜索):針對大型數據集進行優化,並能利用 GPU 加速。
範例:在 Elasticsearch 中實施 HNSW
您可以在 Elasticsearch 中定義索引設置以使用 HNSW,如下所示:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. 批量查詢
為了提高效率,在單個請求中批量處理多個查詢以最小化開銷。這對於用戶流量高的應用特別有用。
範例:在 Elasticsearch 中的批處理
您可以使用 _msearch 端點來進行批量查詢:
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. 使用快取
實施快取策略以應對經常訪問的查詢,以減少計算負擔並提高響應時間。
5. 監控性能
定期分析性能指標對於識別瓶頸至關重要。Kibana 等工具可以幫助可視化這些數據,使您能夠對 Elasticsearch 配置進行明智的調整。
在 HNSW 中調整參數以提高性能
優化 HNSW 涉及調整某些參數以在大型數據集上實現更好的性能:
M(最大連接數):增加此值可以提高召回率,但可能需要更多內存。EfConstruction(建構期間的動態列表大小):較高的值會導致圖形更準確,但可能會增加索引時間。EfSearch(在搜索過程中動態列表大小):調整此參數會影響速度與準確度的取捨;較大的值會提高召回率,但計算所需時間更長。
範例:調整 HNSW 參數
您可以在創建索引時這樣調整 HNSW 參數:
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
個案研究:降維對 HNSW 在客戶數據應用中性能的影響
個性化行銷的圖像檢索
降維技術在優化客戶數據應用中的圖像檢索系統中扮演著關鍵角色。在一項研究中,研究人員使用主成分分析(PCA)進行降維,然後使用層次可導航小型世界(HNSW)網絡對圖像進行索引。PCA 顯著提高了檢索速度——對於處理大量客戶數據的應用至關重要——儘管這也帶來了由於資訊減少而導致的輕微精度損失。為了解決這個問題,研究人員還考察了均勻流形近似與投影(UMAP)作為替代方案。UMAP 更有效地保留了局部數據結構,維護了個性化行銷推薦所需的細緻細節。儘管 UMAP 需要比 PCA 更大的計算能力,但它在搜索速度和高精度之間取得了平衡,使其成為對準確性要求高的任務的可行選擇。
客戶情感聚類的文本分析
在客戶情感分析領域,另一項研究發現UMAP在聚類相似文本數據方面優於PCA。UMAP使HNSW模型能夠以更高的準確性聚類客戶情感——這對於理解客戶反饋並提供更個性化的回應是種優勢。使用UMAP促進了HNSW中較小的EfSearch值,提高了搜索速度和精確度。這種改進的聚類效率使得更快地識別相關客戶情感成為可能,進而增強了針對性的市場行銷努力和基於情感的客戶細分。
整合自動化優化技術
優化降維和HNSW參數對於最大化客戶數據系統的性能至關重要。自動化優化技術簡化了這一調整過程,確保所選配置在多種應用中有效:
- 網格和隨機搜索:這些方法提供了廣泛且系統的參數探索,能有效識別合適的配置。
- 貝葉斯優化:這種技術以較少的評估聚焦於最佳參數,節省計算資源。
- 交叉驗證:交叉驗證幫助在各種數據集上驗證參數,確保其在不同客戶數據上下文中的泛化能力。
應對自動化中的挑戰
將自動化整合到降維和HNSW工作流程中可能會引入挑戰,特別是在管理計算需求和避免過度擬合方面。克服這些挑戰的策略包括:
- 降低計算開銷:使用並行處理來分配工作量可以減少優化時間,提高工作流效率。
- 模塊化整合:模塊化方法有助於將自動化系統無縫整合到現有工作流程中,降低複雜性。
- 防止過度擬合:通過交叉驗證進行強健驗證,確保優化參數在不同數據集上始終表現一致,減少過度擬合,增強客戶數據應用的可擴展性。
結論
為了充分利用Elasticsearch中的向量搜索性能,採用結合降維、高效索引和周到參數調整的策略至關重要。通過整合這些技術,數據工程師可以創建一個高度響應和精確的數據檢索系統。自動優化方法進一步提升了這一過程,允許對搜索參數和索引策略進行持續精煉。隨著組織越來越多地依賴來自海量數據的實時洞察,這些優化可以顯著增強決策能力,提供更快速、更相關的搜索結果。採用這種方法為未來的擴展性和改進響應性奠定了基礎,使搜索能力與不斷演變的業務需求和數據增長保持一致。
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch