













À une époque caractérisée par une augmentation exponentielle de la génération de données, les organisations doivent tirer efficacement parti de cette richesse d’informations pour maintenir leur avantage concurrentiel. La recherche et l’analyse efficaces des données clients — comme l’identification des préférences des utilisateurs pour les recommandations de films ou l’analyse des sentiments — jouent un rôle crucial dans la prise de décisions éclairées et l’amélioration des expériences utilisateur. Par exemple, un service de streaming peut utiliser la recherche vectorielle pour recommander des films adaptés aux historiques de visionnage et aux évaluations individuelles, tandis qu’une marque de détail peut analyser les sentiments des clients pour affiner ses stratégies marketing.
En tant qu’ingénieurs de données, nous avons la tâche de mettre en œuvre ces solutions sophistiquées, en veillant à ce que les organisations puissent tirer des informations exploitables de vastes ensembles de données. Cet article explore les subtilités de la recherche vectorielle utilisant Elasticsearch, en se concentrant sur des techniques efficaces et des meilleures pratiques pour optimiser les performances. En examinant des études de cas sur la récupération d’images pour le marketing personnalisé et l’analyse de texte pour le regroupement des sentiments des clients, nous démontrons comment l’optimisation de la recherche vectorielle peut conduire à de meilleures interactions avec les clients et à une croissance significative des affaires.
Qu’est-ce que la recherche vectorielle ?
La recherche vectorielle est une méthode puissante pour identifier les similitudes entre des points de données en les représentant sous forme de vecteurs dans un espace de haute dimension. Cette approche est particulièrement utile pour les applications qui nécessitent une récupération rapide d’éléments similaires en fonction de leurs attributs.
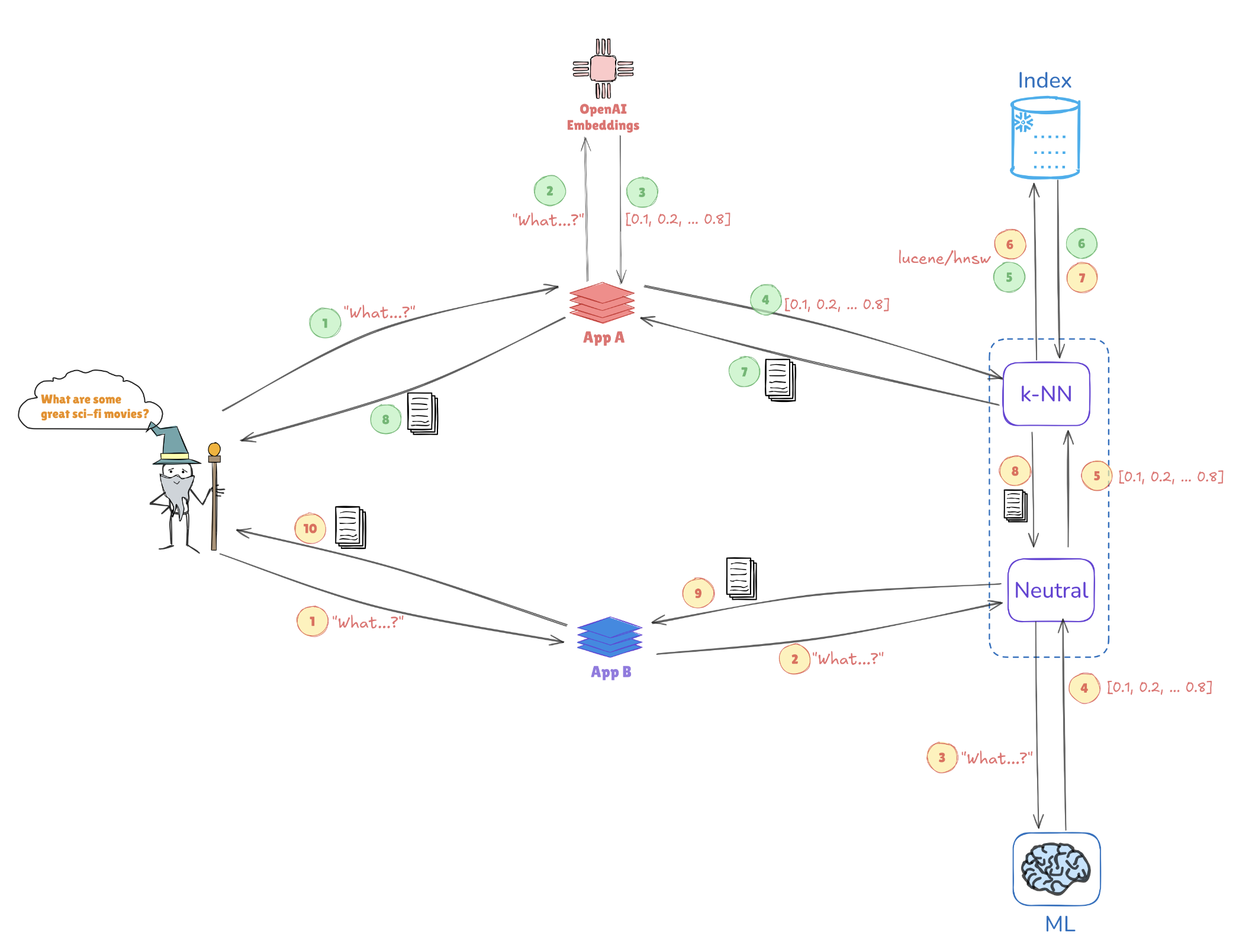
Illustration de la recherche vectorielle
Considérez l’illustration ci-dessous, qui montre comment les représentations vectorielles permettent des recherches de similitude :
- Insertion de requêtes : La requête « Quels sont quelques grands films de science-fiction ? » est convertie en une représentation vectorielle, telle que [0.1, 0.2, …, 0.4].
- Indexation : Ce vecteur est comparé aux vecteurs pré-indexés stockés dans Elasticsearch (par exemple, à partir d’applications telles que AppA et AppB) pour trouver des requêtes ou des points de données similaires.
- Recherche k-NN : En utilisant des algorithmes comme les k plus proches voisins (k-NN), Elasticsearch récupère efficacement les meilleures correspondances à partir des vecteurs indexés, aidant à identifier rapidement les informations les plus pertinentes.
Ce mécanisme permet à Elasticsearch de se démarquer dans des cas d’utilisation tels que les systèmes de recommandation, les recherches d’images et le traitement du langage naturel, où la compréhension du contexte et de la similitude est essentielle.
Avantages clés de la recherche vectorielle avec Elasticsearch
Prise en charge de la haute dimensionnalité
Elasticsearch excelle dans la gestion de structures de données complexes, essentielles pour les applications d’IA et apprentissage automatique. Cette capacité est cruciale lorsqu’il s’agit de traiter des types de données multifacettes, tels que des images ou des données textuelles.
Scalabilité
Son architecture supporte l’évolutivité horizontale, permettant aux organisations de gérer des ensembles de données en constante expansion sans sacrifier les performances. Cela est vital alors que les volumes de données continuent de croître.
Intégration
Elasticsearch fonctionne de manière transparente avec la pile Elastic, offrant une solution complète pour l’ingestion, l’analyse et la visualisation des données. Cette intégration garantit que les ingénieurs en données peuvent tirer parti d’une plateforme unifiée pour diverses tâches de traitement des données.
Meilleures pratiques pour optimiser les performances de recherche vectorielle
1. Réduire les dimensions des vecteurs
Réduire la dimensionnalité de vos vecteurs peut considérablement améliorer les performances de recherche. Des techniques comme PCA (Analyse en Composantes Principales) ou UMAP (Approximation et Projection de Variété Uniforme) aident à maintenir les caractéristiques essentielles tout en simplifiant la structure des données.
Exemple : Réduction de dimensionnalité avec PCA
Voici comment implémenter PCA en Python en utilisant Scikit-learn :
from sklearn.decomposition import PCA
import numpy as np
# Sample high-dimensional data
data = np.random.rand(1000, 50) # 1000 samples, 50 features
# Apply PCA to reduce to 10 dimensions
pca = PCA(n_components=10)
reduced_data = pca.fit_transform(data)
print(reduced_data.shape) # Output: (1000, 10)
2. Indexer efficacement
Tirer parti des algorithmes de Plus Proche Voisin Approximatif (ANN) peut considérablement accélérer les temps de recherche. Envisagez d’utiliser :
- HNSW (Hierarchical Navigable Small World) : Connu pour son équilibre entre performance et précision.
- FAISS (Facebook AI Similarity Search) : Optimisé pour les grands ensembles de données et capable d’utiliser l’accélération GPU.
Exemple : Implémentation de HNSW dans Elasticsearch
Vous pouvez définir les paramètres de votre index dans Elasticsearch pour utiliser HNSW comme suit :
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.space_type": "l2",
"knn.algo": "hnsw"
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10 // Adjust based on your data
}
}
}
}
3. Requêtes groupées
Pour améliorer l’efficacité, le traitement par lots de plusieurs requêtes dans une seule demande réduit les frais généraux. Cela est particulièrement utile pour les applications à fort trafic utilisateur.
Exemple : Traitement par lots dans Elasticsearch
Vous pouvez utiliser l’endpoint _msearch pour les requêtes groupées :
POST /_msearch
{ "index": "my_vector_index" }
{ "query": { "match_all": {} } }
{ "index": "my_vector_index" }
{ "query": { "match": { "category": "sci-fi" } } }
4. Utilisation du cache
Implémentez des stratégies de mise en cache pour les requêtes fréquemment accédées afin de réduire la charge de calcul et améliorer les temps de réponse.
5. Surveillance des performances
Analyser régulièrement les métriques de performance est crucial pour identifier les goulots d’étranglement. Des outils comme Kibana peuvent aider à visualiser ces données, permettant ainsi des ajustements informés de votre configuration Elasticsearch.
Ajustement des paramètres de HNSW pour des performances améliorées
L’optimisation de HNSW implique d’ajuster certains paramètres pour obtenir de meilleures performances sur de grands ensembles de données :
M(nombre maximum de connexions) : Augmenter cette valeur améliore le rappel mais peut nécessiter plus de mémoire.EfConstruction(taille de liste dynamique pendant la construction) : Une valeur plus élevée conduit à un graphe plus précis mais peut augmenter le temps d’indexation.EfSearch(taille de liste dynamique pendant la recherche) : Ajuster ceci affecte le compromis vitesse-précision ; une valeur plus grande donne de meilleurs rappels mais prend plus de temps à calculer.
Exemple : Ajustement des paramètres HNSW
Vous pouvez ajuster les paramètres HNSW lors de la création de votre index de cette manière :
PUT /my_vector_index
{
"settings": {
"index": {
"knn": true,
"knn.algo": "hnsw",
"knn.hnsw.m": 16, // More connections
"knn.hnsw.ef_construction": 200, // Higher accuracy
"knn.hnsw.ef_search": 100 // Adjust for search accuracy
}
},
"mappings": {
"properties": {
"my_vector": {
"type": "knn_vector",
"dimension": 10
}
}
}
}
Étude de cas : Impact de la réduction de la dimensionalité sur les performances HNSW dans les applications de données client
Recherche d’images pour le marketing personnalisé
Les techniques de réduction de la dimensionalité jouent un rôle crucial dans l’optimisation des systèmes de recherche d’images au sein des applications de données client. Dans une étude, des chercheurs ont appliqué l’Analyse en composantes principales (PCA) pour réduire la dimensionalité avant d’indexer des images avec des réseaux HNSW (Hierarchical Navigable Small World). PCA a fourni un coup de pouce notable à la vitesse de récupération — vital pour les applications traitant de gros volumes de données client — bien que cela se soit accompagné d’une légère perte de précision due à la réduction d’informations. Pour pallier cela, les chercheurs ont également examiné l’Approximation et Projection Uniforme de la Manifold (UMAP) comme alternative. UMAP a préservé de manière plus efficace les structures de données locales, maintenant les détails complexes nécessaires pour les recommandations de marketing personnalisé. Alors que UMAP nécessitait une puissance de calcul plus importante que PCA, il équilibrait la vitesse de recherche avec une haute précision, en en faisant un choix viable pour les tâches critiques en termes de précision.
Analyse de texte pour le regroupement de sentiments des clients
Dans le domaine de l’analyse de la sentiment client, une étude différente a constaté que UMAP surpassait le PCA dans le regroupement de données textuelles similaires. UMAP a permis au modèle HNSW de regrouper les sentiments des clients avec une précision plus élevée, offrant un avantage pour comprendre les retours des clients et fournir des réponses plus personnalisées. L’utilisation de UMAP a facilité l’obtention de valeurs plus petites de EfSearch dans HNSW, améliorant la vitesse et la précision de la recherche. Cette efficacité de regroupement améliorée a permis d’identifier plus rapidement les sentiments des clients pertinents, renforçant les efforts de marketing ciblé et la segmentation des clients basée sur les sentiments.
Intégration de techniques d’optimisation automatisées
L’optimisation de la réduction de la dimensionnalité et des paramètres HNSW est essentielle pour maximiser les performances des systèmes de données clients. Les techniques d’optimisation automatisées simplifient ce processus d’ajustement, garantissant que les configurations sélectionnées sont efficaces dans diverses applications :
- Recherche en grille et aléatoire : Ces méthodes offrent une exploration large et systématique des paramètres, identifiant efficacement des configurations adaptées.
- Optimisation bayésienne : Cette technique se concentre sur les paramètres optimaux avec moins d’évaluations, préservant les ressources computationnelles.
- Validation croisée : La validation croisée aide à valider les paramètres sur différents ensembles de données, garantissant leur généralisation à différents contextes de données clients.
Adresse des défis de l’automatisation
L’intégration de l’automatisation dans les processus de réduction de dimensionnalité et HNSW peut introduire des défis, notamment en matière de gestion des demandes computationnelles et d’évitement du surapprentissage. Les stratégies pour surmonter ces défis incluent :
- Réduction des coûts computationnels : L’utilisation du traitement parallèle pour répartir la charge de travail réduit le temps d’optimisation, améliorant ainsi l’efficacité du flux de travail.
- Intégration modulaire : Une approche modulaire facilite l’intégration sans heurts des systèmes automatisés dans les flux de travail existants, réduisant la complexité.
- Prévention du surapprentissage : Une validation robuste par validation croisée garantit que les paramètres optimisés fonctionnent de manière cohérente à travers les ensembles de données, minimisant le surapprentissage et améliorant l’évolutivité dans les applications de données clients.
Conclusion
Pour exploiter pleinement la performance de recherche vectorielle dans Elasticsearch, il est essentiel d’adopter une stratégie qui combine la réduction de dimensionnalité, l’indexation efficace et le réglage réfléchi des paramètres. En intégrant ces techniques, les ingénieurs des données peuvent créer un système de récupération de données hautement réactif et précis. Les méthodes d’optimisation automatisée élèvent encore ce processus, permettant un raffinement continu des paramètres de recherche et des stratégies d’indexation. À mesure que les organisations s’appuient de plus en plus sur des informations en temps réel provenant d’énormes ensembles de données, ces optimisations peuvent considérablement améliorer les capacités de prise de décision, offrant des résultats de recherche plus rapides et plus pertinents. Adopter cette approche prépare le terrain pour une évolutivité future et une réactivité améliorée, alignant les capacités de recherche avec l’évolution des exigences commerciales et la croissance des données.
Source:
https://dzone.com/articles/optimizing-vector-search-performance-with-elasticsearch