













資料庫分片是將資料分割成稱為「分片」的小塊的過程。分片通常是在需要擴展寫入操作時引入的。在一個成功的應用程式生命週期中,資料庫伺服器將會達到其能夠處理或容量的最大寫入數量。將資料切割成多個分片——每個分片位於其自己的資料庫伺服器上——減輕了每個單獨節點的壓力,有效地提高了整體資料庫的寫入容量。這就是資料庫分片的作用。
分散式SQL是一種新的方式,用於透過類似分片的策略自動化且對應用程式透明的擴展關聯式資料庫。分散式SQL資料庫從一開始就設計為幾乎線性擴展。在本文中,您將學習分散式SQL的基本知識以及如何開始使用。
資料庫分片的缺點
分片引入了多項挑戰:
- 資料分割:決定如何在多個分片之間分割資料可能是一個挑戰,因為需要在資料接近性和均勻分配資料以避免熱點之間找到平衡。
- 故障處理:如果一個關鍵節點失效,並且沒有足夠的分片來承載負載,您如何在沒有停機的情況下將資料轉移到新節點?
- 查詢複雜度:應用程式碼與資料分片邏輯緊密耦合,需要從多個節點獲取資料的查詢必須重新連接。
- 資料一致性:確保跨多個分片的資料一致性可能是一項挑戰,因為它需要協調跨分片的資料更新。在並發更新時,這可能特別困難,因為可能需要解決不同寫入之間的衝突。
- 彈性擴展性:隨著資料量或查詢數量的增加,可能需要向資料庫添加更多的分片。這可能是一個複雜的過程,伴隨不可避免的停機時間,需要手動過程來均勻地將資料重新分配到所有分片。
這些缺點中的一些可以通過採用多語言持久性(為不同的工作負載使用不同的資料庫)、具有原生分片能力的資料庫存儲引擎或資料庫代理來緩解。然而,儘管有助於應對資料庫分片中的一些挑戰,這些工具也有其限制,並引入了需要持續管理的複雜性。
什麼是分散式SQL?
分散式SQL指的是新一代的關聯式資料庫。簡單來說,分散式SQL資料庫是一種具有透明分片功能的關聯資料庫,對應用程式而言,它看起來就像單一邏輯資料庫。分散式SQL資料庫採用無共享架構及一個能夠擴展讀寫操作的儲存引擎,同時保持真正的ACID合規性和高可用性。這些資料庫擁有2000年代流行的NoSQL資料庫的可擴展性特點,但不犧牲一致性。它們保留了關聯式資料庫的優勢,並增加了與雲端相容的多區域韌性。
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
分散式SQL是如何運作的?
要理解分散式SQL的運作方式,我們以MariaDB Xpand為例——這是一個與開源MariaDB資料庫相容的分散式SQL資料庫。Xpand透過將資料和索引分散在各節點上,並自動執行資料再平衡和分散式查詢執行等任務。查詢以平行方式執行,以最小化延遲。資料會自動複製,確保沒有單一故障點。當節點失效時,Xpand會在剩餘節點間重新平衡資料。同樣地,當新增節點時也會發生這種情況。名為rebalancer的元件確保不會出現熱點——這是手動資料庫分片常見的挑戰,即一個節點不均勻地處理過多交易,而其他節點有時則閒置。
我們來看一個例子。假設我們有一個資料庫實例,其中包含some_table和若干行資料:
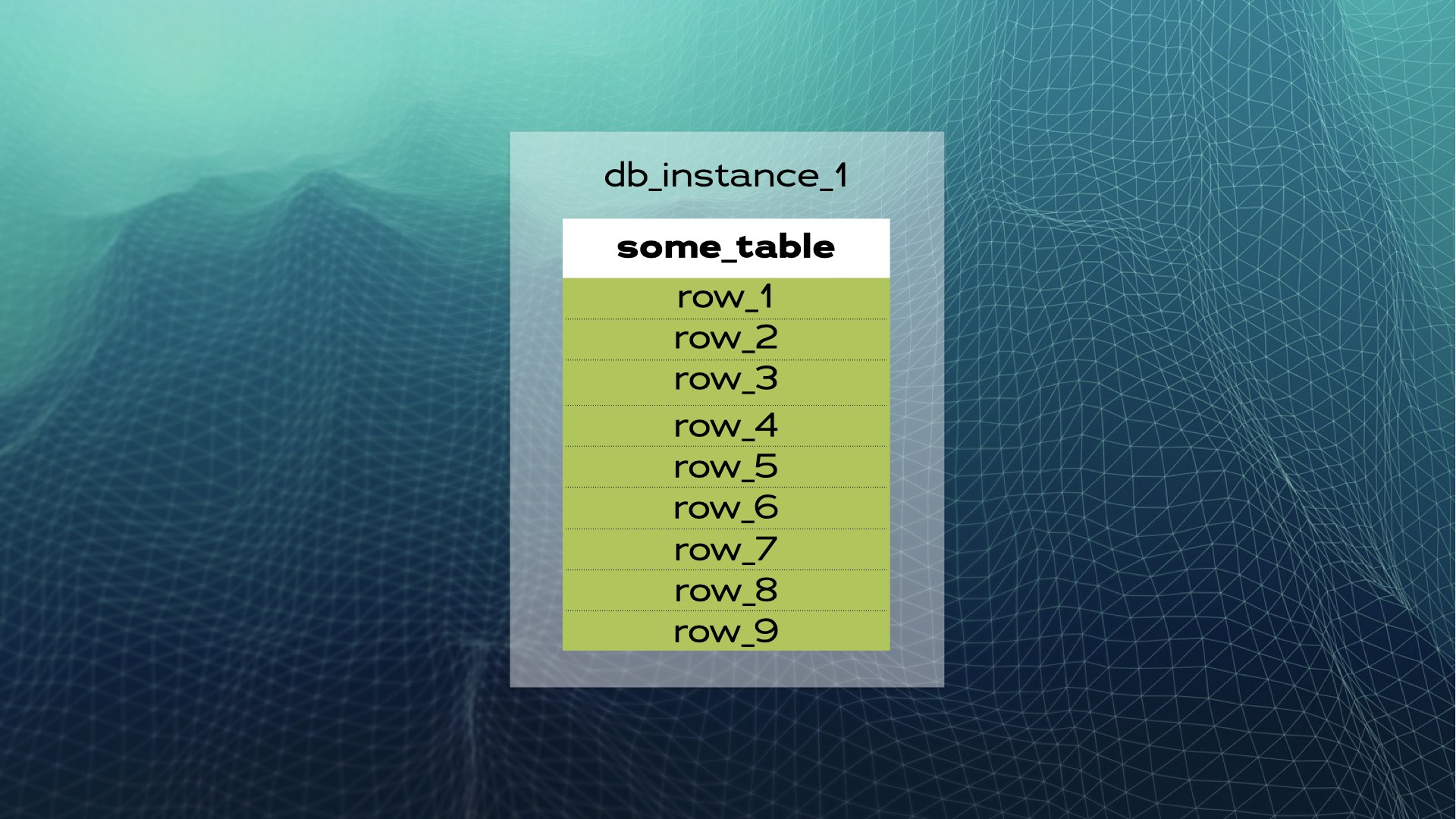
我們可以將資料分成三個區塊(分片):

然後將每個資料區塊移至單獨的資料庫實例中:
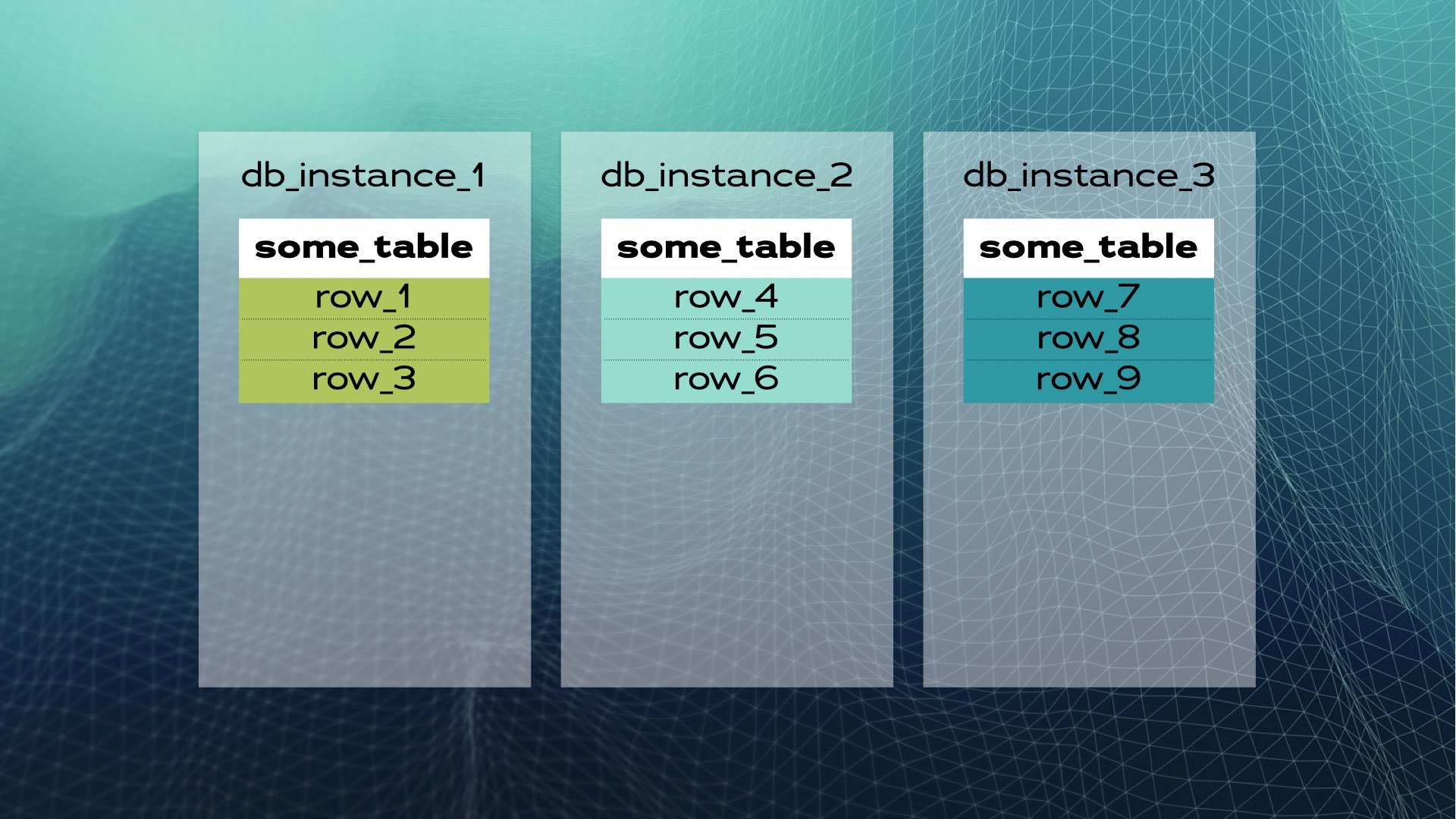
這就是手動資料庫共享的樣貌。分散式SQL會自動為您處理這一切。以Xpand為例,每個分片稱為一個切片。行資料透過表格部分欄位的雜湊值進行切片。不僅資料被切片,索引也同樣被切片並分佈於各節點(資料庫實例)之間。此外,為了維持高可用性,切片會在其他節點上進行複製(每節點的複製數量可配置)。這一過程同樣是自動進行的:
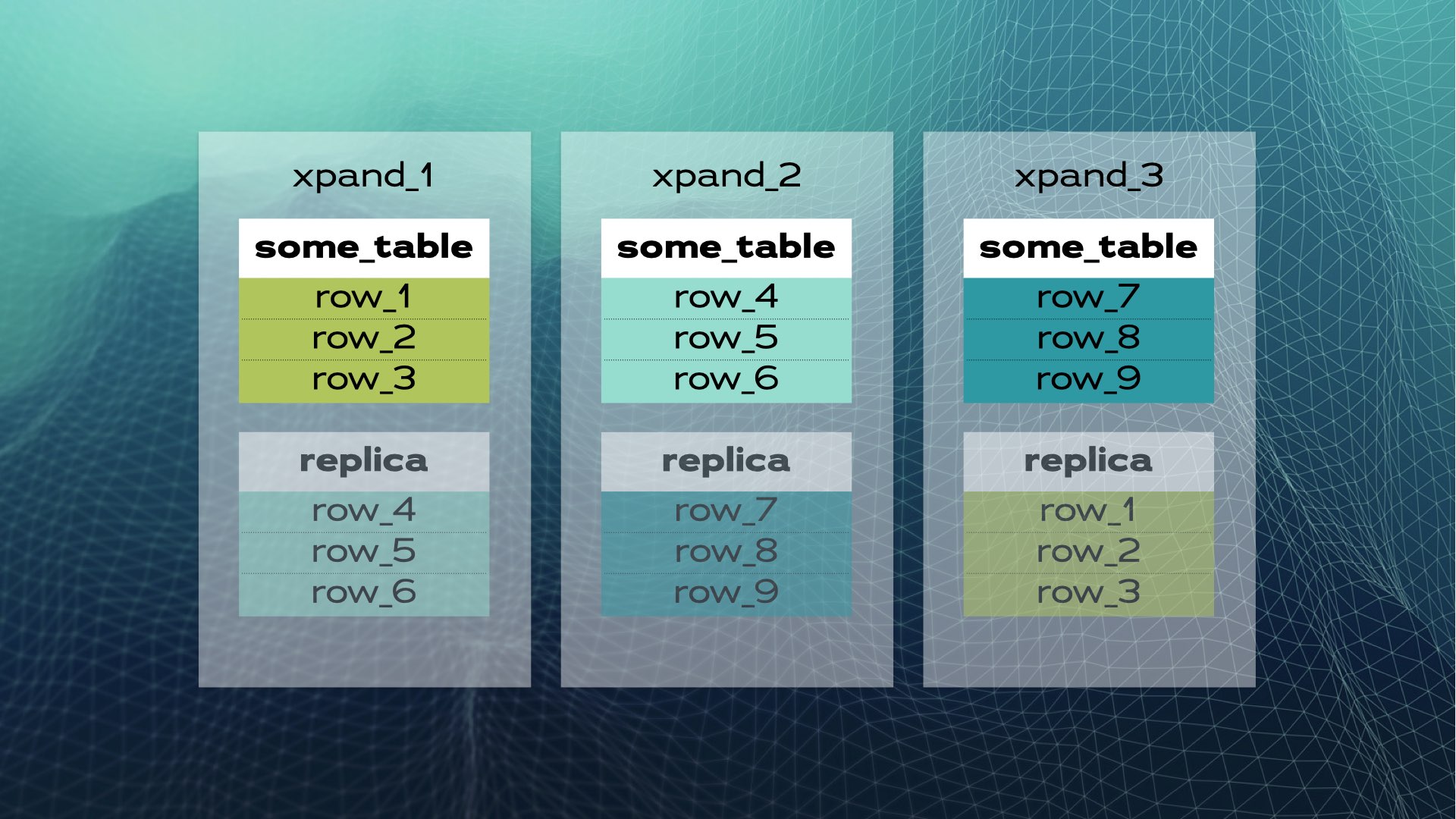
當集群中新增節點或某節點失效時,Xpand會自動重新平衡數據,無需人工介入。以下是新增節點至既有集群時的情況:

部分行資料會被移至新節點,以提升整體系統容量。需注意,雖未在圖中展示,但索引及副本也會相應地重新定位與更新。此圖展示了稍完整的集群視圖(資料重新分配略有不同):
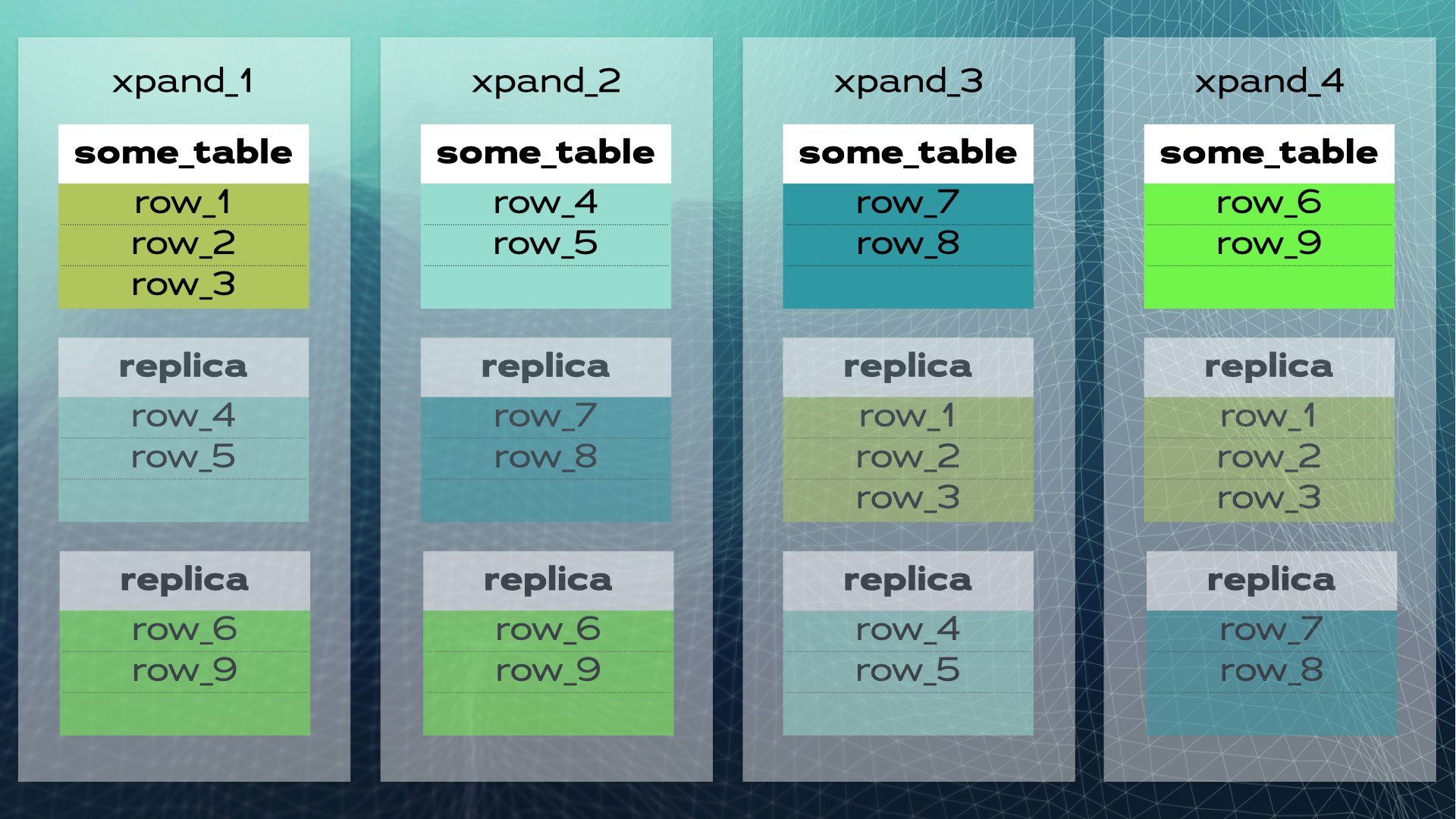
此架構實現了近乎線性的擴展性。應用層無需手動干預。對應用而言,集群看似單一邏輯資料庫。應用僅需透過負載均衡器(MariaDB MaxScale)連接至資料庫:
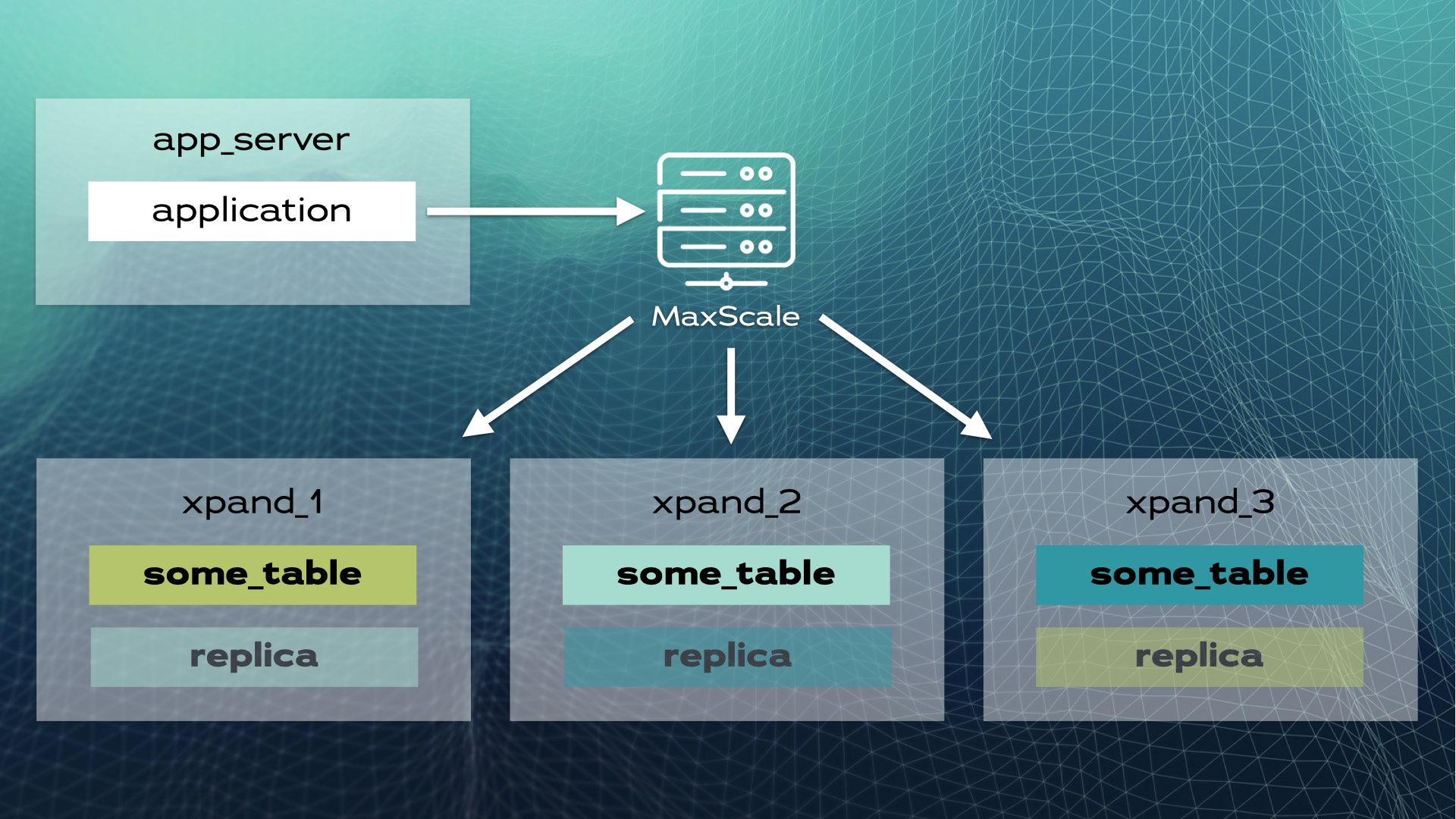
當應用發送寫入操作(例如,INSERT或UPDATE)時,會計算雜湊值並發送至正確的切片。多個寫入操作會平行發送至多個節點。
何時不宜使用分散式SQL
將資料庫進行分片雖能提升效能,但也會在節點間的通訊層面引入額外開銷。若資料庫配置不當或查詢路由器未經最佳化,可能導致效能下降。對於每秒查詢次數低於10K或每秒交易次數低於5K的應用,分散式SQL可能不是最佳選擇。此外,若您的資料庫主要由眾多小型表組成,那麼單體資料庫的表現可能更佳。
開始使用分散式SQL
由於分散式SQL資料庫對應用程式而言如同單一邏輯資料庫,因此起步相當直接。您只需以下幾項:
Docker使第二部分變得簡單。例如,MariaDB發布了mariadb/xpand-single Docker映像,允許您快速啟動單節點Xpand資料庫以供評估、測試和開發。
要啟動Xpand容器,請運行以下命令:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "user" \
--passwd "password"詳情請參閱Docker映像文件。
注意:本文撰寫時,mariadb/xpand-single Docker映像在ARM架構上尚不可用。對於這些架構(例如配備M1處理器的Apple機器),請使用UTM創建虛擬機(VM)並安裝,例如,Debian。分配主機名並使用SSH連接到VM以安裝Docker並創建MariaDB Xpand容器。
連接到資料庫
連接到Xpand資料庫的方式與連接到MariaDB 社群版或企業版伺服器相同。如果您已安裝mariadb CLI工具,只需執行以下命令:
mariadb -h 127.0.0.1 -u user -p您可以透過如DBeaver、DataGrip等SQL資料庫的GUI進行連接,或是使用IDE的SQL擴充功能(例如此擴充適用於VS Code)。我們將使用一款名為DbGate的免費開源SQL客戶端。您可以下載DbGate並作為桌面應用程式運行,或者如果您使用Docker,則可以將其部署為網路應用程式,透過網路瀏覽器從任何地方存取(類似於流行的phpMyAdmin)。只需運行以下命令:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgate一旦容器啟動,將您的瀏覽器指向http://localhost:3000/。填寫連接詳細資訊:
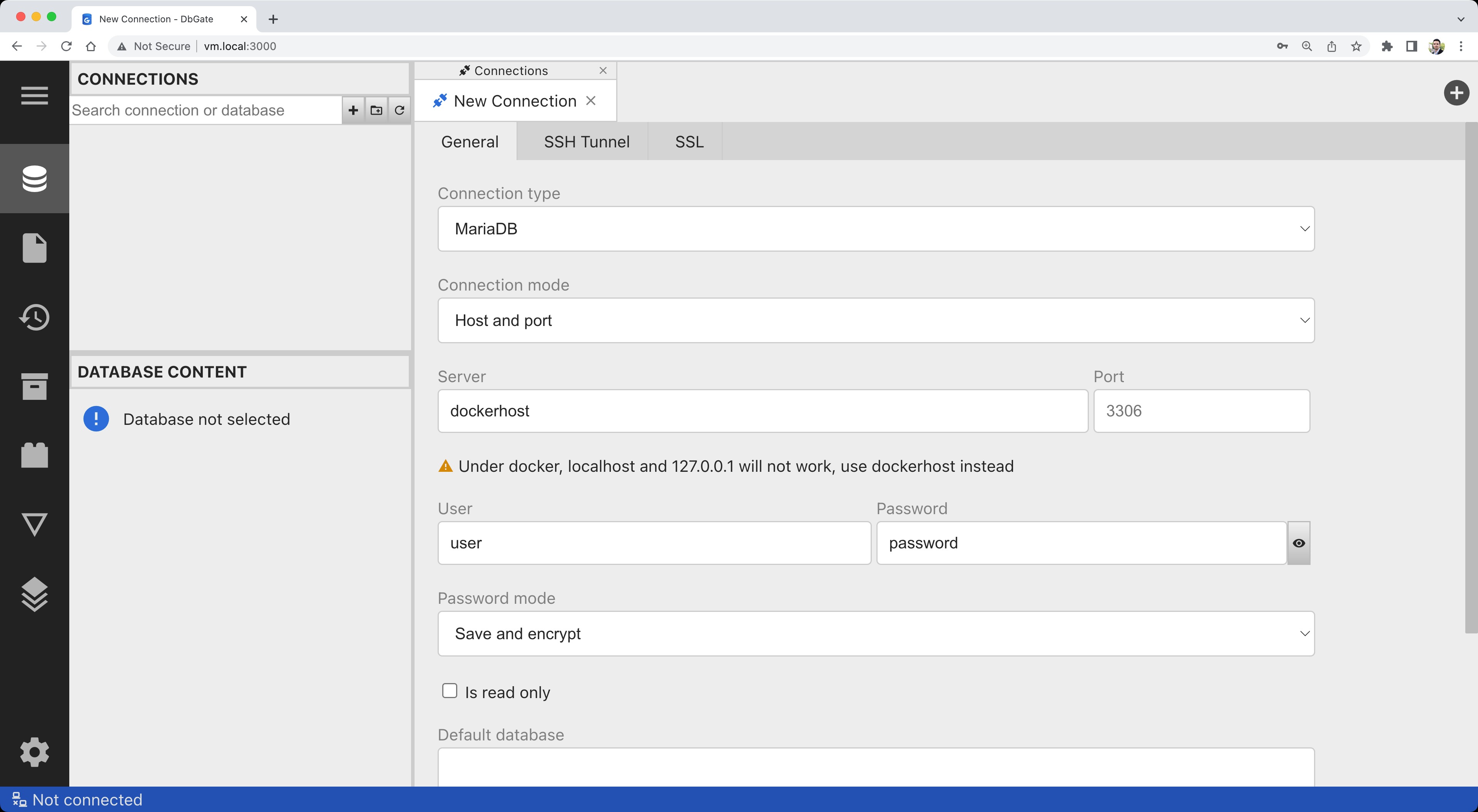
點擊測試並確認連接成功:

點擊保存,並在左側面板中右鍵點擊連接選擇創建資料庫來新建資料庫。嘗試創建表格或導入SQL腳本。如果您只想嘗試一下,Nation或Sakila都是不錯的範例資料庫。
從 Java、JavaScript、Python 及 C++ 連接
若要從應用程式連接到 Xpand,您可以使用MariaDB 連接器。有許多程式語言與持久性框架的組合可能。涵蓋這些內容超出了本文範疇,但若您想快速入門並看到實際操作,請查看此快速入門頁面,其中包含Java、JavaScript、Python及C++的程式碼範例。
分散式 SQL 的真正威力
在本文中,我們學習了如何為開發和測試目的啟動單節點 Xpand,而非用於生產工作負載。然而,分散式 SQL 資料庫的真正威力在於其不僅能夠擴展讀取(如同經典資料庫分片),還能通過簡單地添加更多節點並讓再平衡器最佳地重新定位數據來擴展寫入。雖然可以部署多節點拓撲的 Xpand,但在生產中最簡單的使用方式是通過SkySQL。
若您想深入了解分散式 SQL 和 MariaDB Xpand,以下是一些有用的資源列表:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding