













数据库分片是将数据分割成称为“分片”的小块的过程。分片通常在需要扩大写入操作时引入。在成功的应用程序生命周期中,数据库服务器将达到其处理或容量级别的最大写入次数。将数据分割成多个分片——每个分片位于自己的数据库服务器上——减轻了每个单独节点的压力,有效地提高了整个数据库的写入容量。这就是数据库分片的含义。
分布式SQL是一种新的关系数据库扩展方式,采用类似分片的策略,完全自动化且对应用程序透明。分布式SQL数据库从基础设计开始就旨在实现几乎线性的扩展。本文中,您将了解分布式SQL的基础知识以及如何开始使用。
数据库分片的缺点
分片引入了若干挑战:
- 数据分区:决定如何在多个分片之间分区数据可能是一个挑战,需要在数据邻近性和均匀分布数据以避免热点之间找到平衡。
- 故障处理:如果关键节点发生故障,且分片数量不足以承担负载,如何在无停机情况下将数据迁移到新节点?
- 查询复杂度: 应用代码与数据分片逻辑紧密耦合,需要从多个节点获取数据的查询必须重新连接。
- 数据一致性: 确保跨多个分片的数据一致性可能是一项挑战,因为它需要协调跨分片的数据更新。特别是在并发更新时,可能需要解决不同写入之间的冲突,这一点尤为困难。
- 弹性可扩展性: 随着数据量或查询数量的增加,可能需要向数据库添加更多分片。这一过程可能复杂且不可避免地会导致停机,需要手动操作将数据均匀地重新分配到所有分片中。
通过采用多语言持久化(针对不同工作负载使用不同数据库)、具有原生分片能力的数据库存储引擎或数据库代理,可以在一定程度上缓解这些问题。然而,尽管这些工具有助于应对数据库分片中的一些挑战,但它们也有局限性,并引入了需要持续管理的复杂性。
什么是分布式SQL?
分布式SQL指的是新一代的关系型数据库。简而言之,分布式SQL数据库是一种具有透明分片特性的关系数据库,对应用程序而言,它表现为一个单一的逻辑数据库。这类数据库采用无共享架构和存储引擎,支持读写扩展,同时保持真正的ACID合规性和高可用性。分布式SQL数据库继承了NoSQL数据库在21世纪初广受欢迎的可扩展性特点,但并未牺牲一致性。它们保留了关系数据库的优势,并增加了与云环境的兼容性,具备多区域韧性。
A different but related term is NewSQL (coined by Matthew Aslett in 2011). This term also describes scalable and performant relational databases. However, NewSQL databases don’t necessarily include horizontal scalability.
分布式SQL是如何工作的?
要理解分布式SQL的工作原理,我们可以以MariaDB Xpand为例——这是一个与开源MariaDB数据库兼容的分布式SQL数据库。Xpand通过在节点间分割数据和索引,并自动执行如数据再平衡和分布式查询执行等任务来运作。查询以并行方式执行,以最小化延迟。数据会自动复制,确保不存在单点故障。当节点发生故障时,Xpand会在剩余节点间重新平衡数据。同样,当添加新节点时也会发生这种情况。一个名为rebalancer的组件确保不存在热点——这是手动数据库分片时面临的挑战,即当一个节点不均匀地处理过多交易,而其他节点可能在某些时候处于闲置状态。
下面我们通过一个例子来具体了解。假设我们有一个数据库实例,其中包含some_table表和若干行数据:
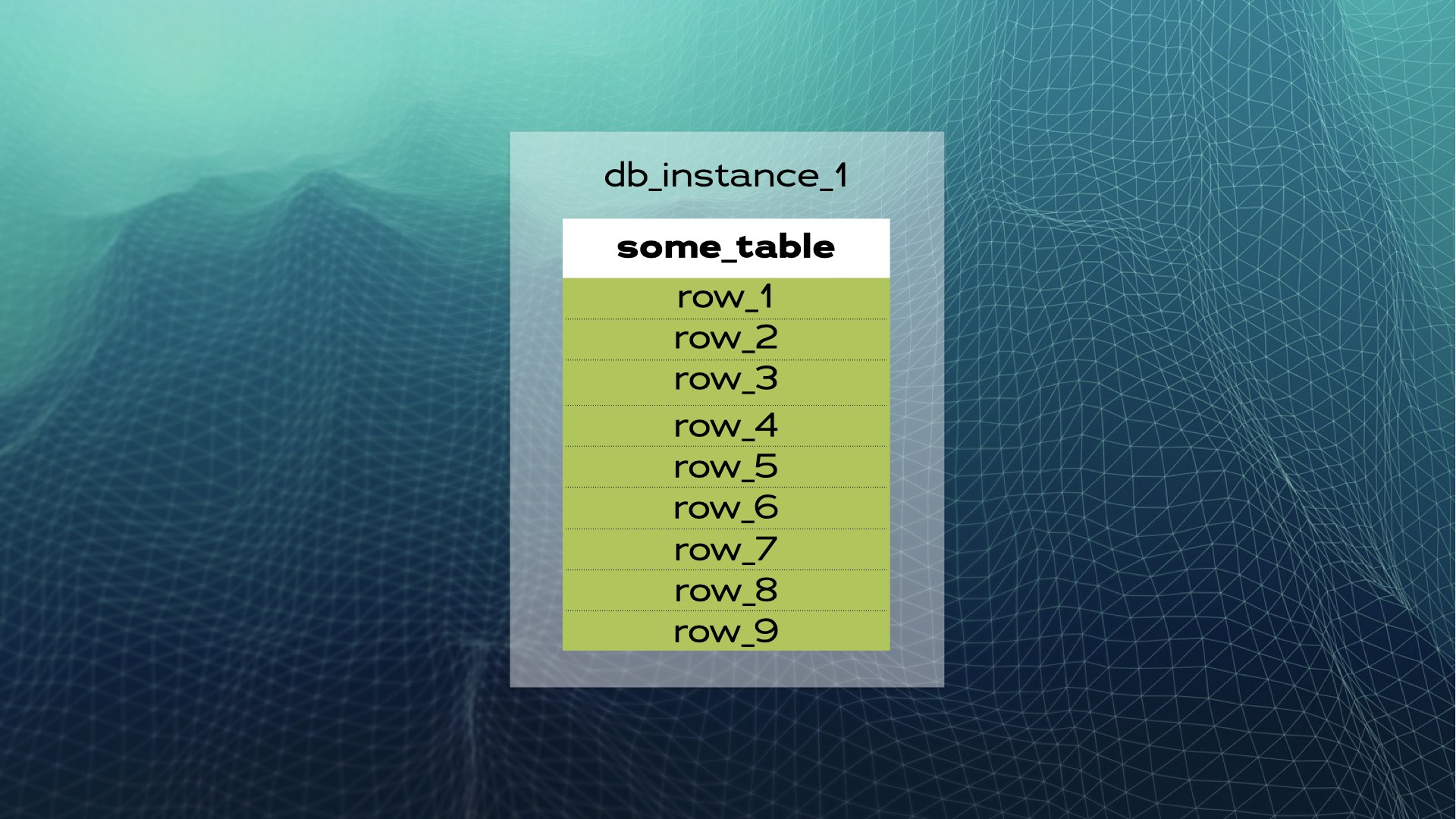
我们可以将数据分为三个片段(分片):

接着,将每个数据片段迁移至单独的数据库实例中:
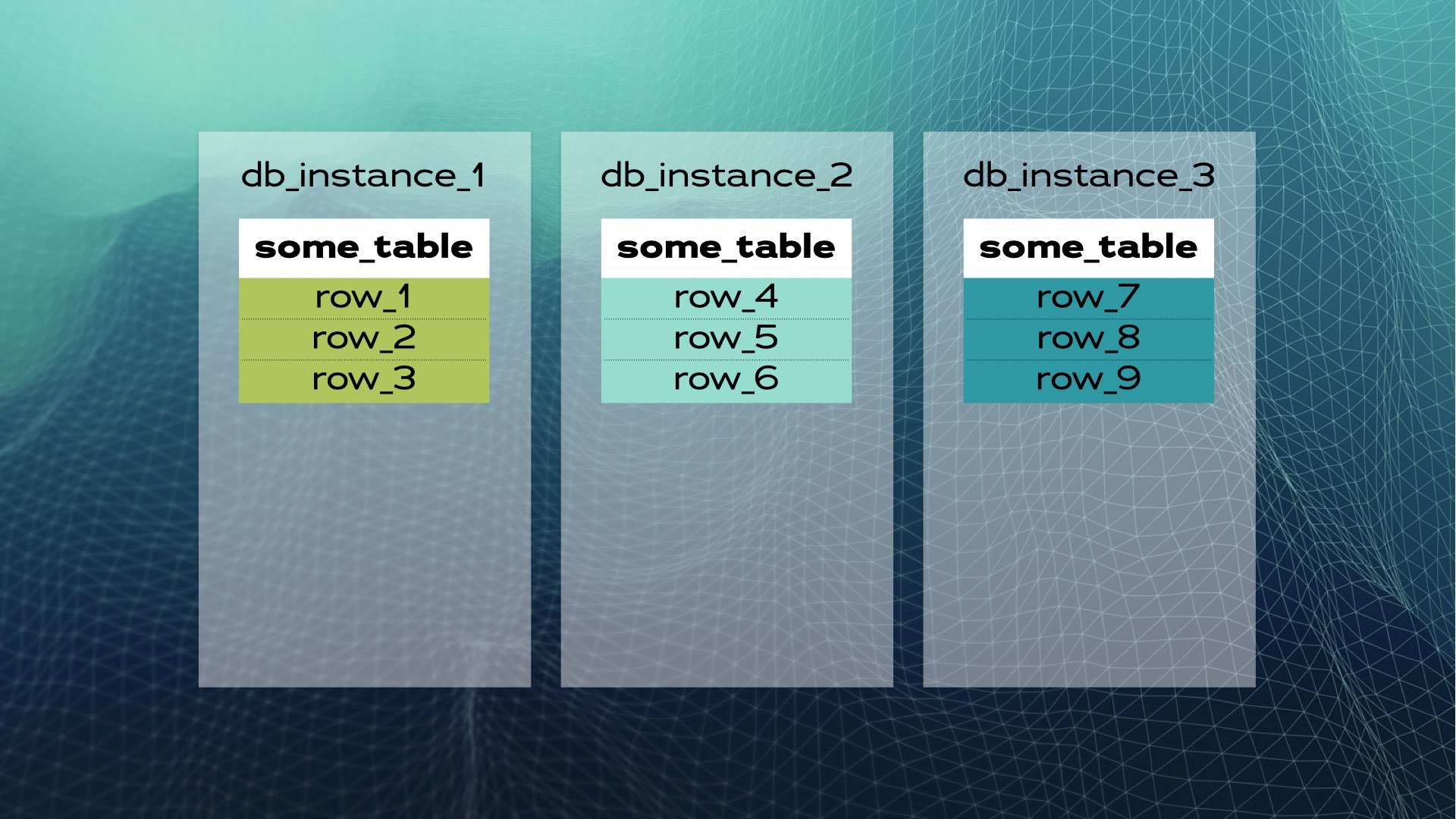
这就是手动数据库共享的情景。而分布式SQL则能自动为你处理这一切。以Xpand为例,每个分片称为一个切片。通过表列子集的哈希值对行进行切片。不仅数据被切片,索引也同样被切片并分布在各个节点(数据库实例)间。此外,为确保高可用性,切片会在其他节点上进行复制(每个节点的副本数可配置)。这一过程也是自动完成的:
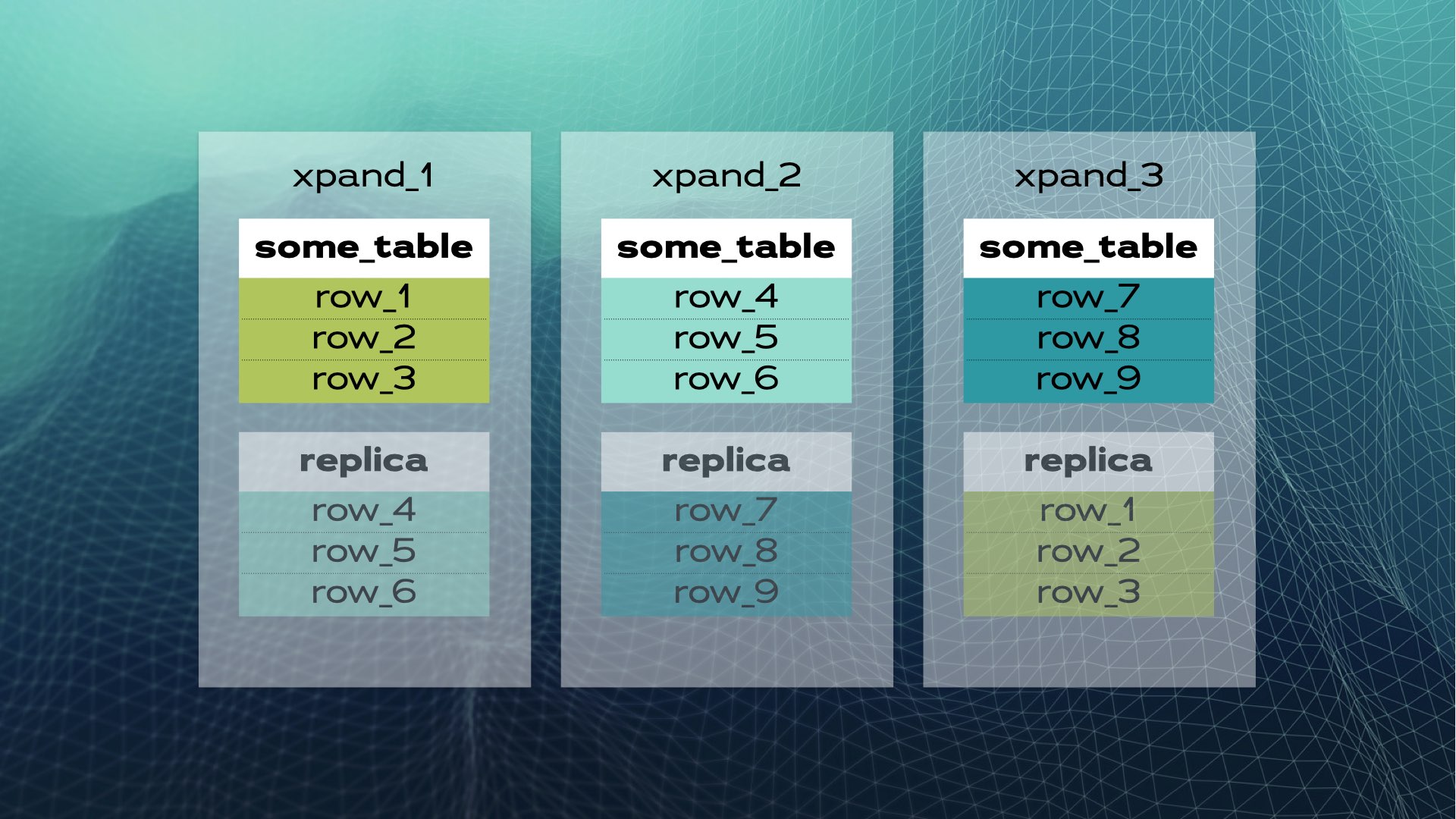
当集群中新增节点或某个节点发生故障时,Xpand会自动重新平衡数据,无需人工干预。以下是当新节点加入原有集群时的情况:

部分行会迁移至新节点,以提升整体系统容量。请注意,虽然图中未展示,但索引及副本也会相应地重新定位和更新。下图展示了一个稍完整(数据迁移略有不同)的集群视图:
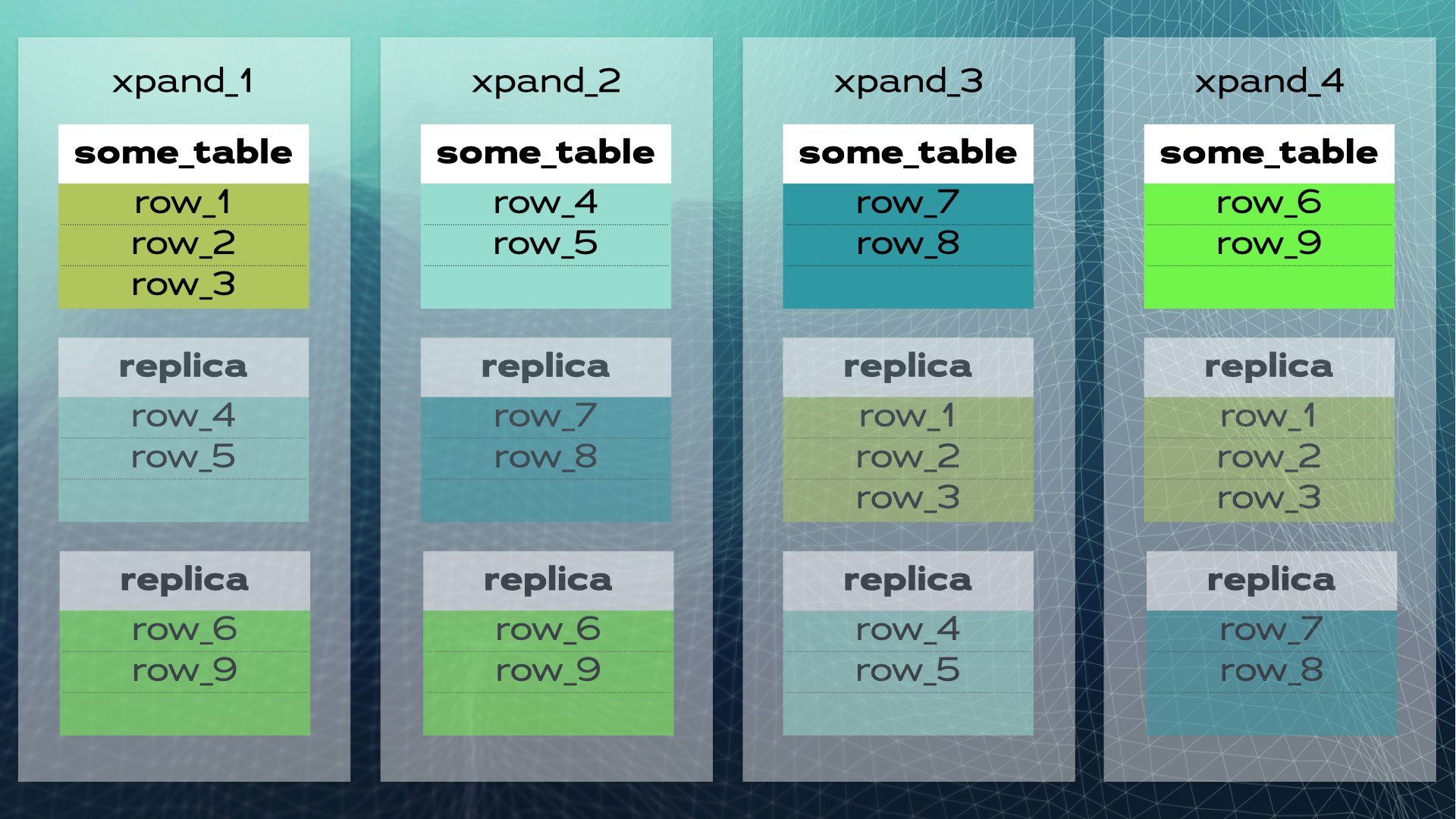
这种架构支持近线性可扩展性,应用层面无需人工干预。对应用而言,集群就像一个单一逻辑数据库。应用通过负载均衡器(MariaDB MaxScale)连接数据库:
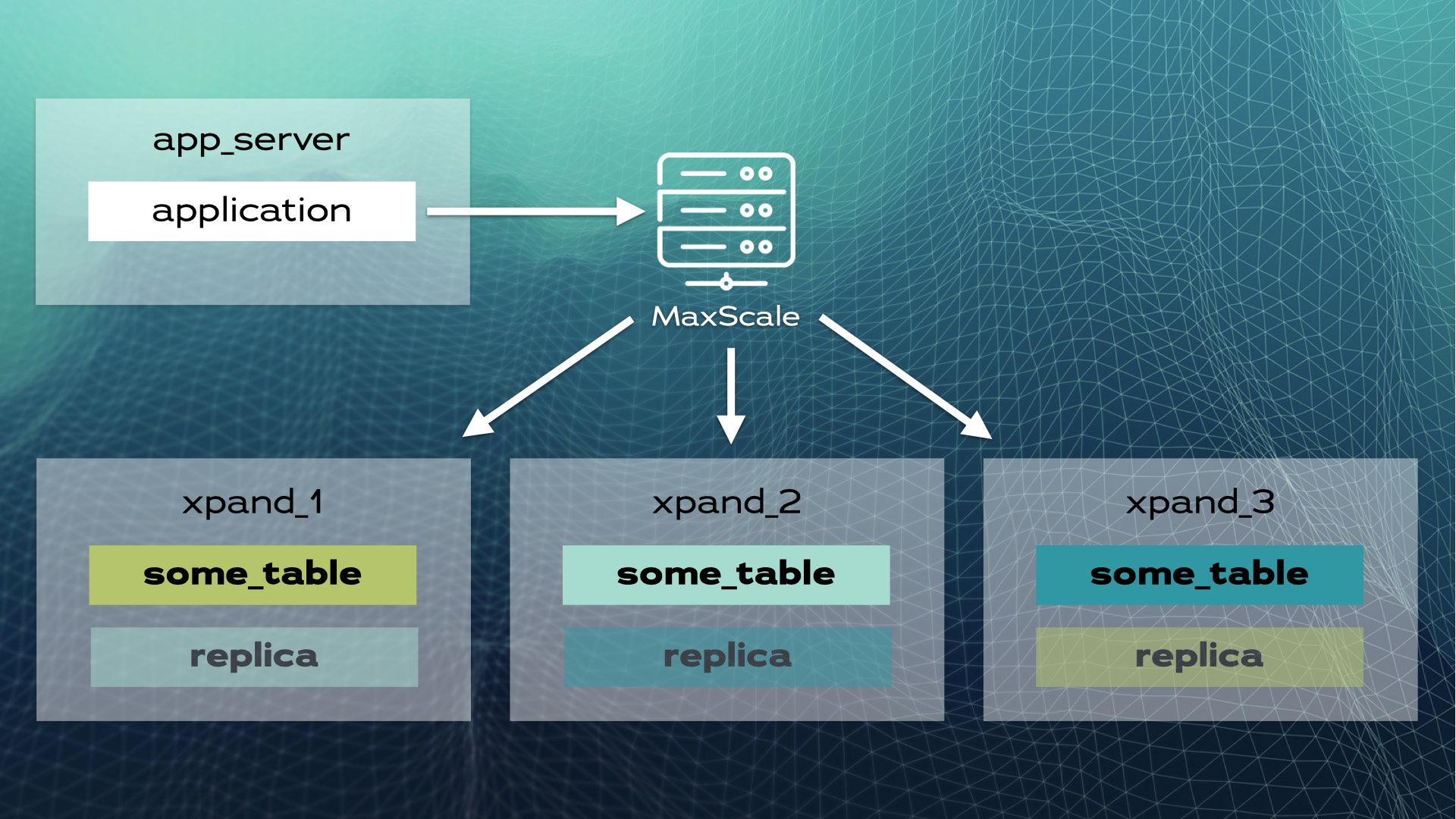
当应用发送写操作(如INSERT或UPDATE)时,会计算哈希值并将其发送到正确的切片。多个写操作会并行发送到多个节点。
何时不宜使用分布式SQL
数据库分片虽能提升性能,但同时也增加了节点间通信的额外开销。若数据库配置不当或查询路由器未优化,可能导致性能下降。对于每秒查询次数少于10K或每秒事务数少于5K的应用,分布式SQL可能并非最佳选择。此外,若数据库主要由众多小型表组成,则单体数据库可能表现更佳。
分布式SQL入门指南
由于分布式SQL数据库对应用程序呈现为单一逻辑数据库,因此上手简单。所需工具如下:
借助Docker,第二步变得简单。例如,MariaDB提供的mariadb/xpand-single Docker镜像,可用于快速搭建单节点Xpand数据库,供评估、测试和开发使用。
启动Xpand容器的命令如下:
docker run --name xpand \
-d \
-p 3306:3306 \
--ulimit memlock=-1 \
mariadb/xpand-single \
--user "用户名" \
--passwd "密码"详细信息请参阅Docker镜像文档。
注意:撰写本文时,mariadb/xpand-single Docker镜像在ARM架构上不可用。对于这些架构(例如搭载M1处理器的苹果设备),可使用UTM创建虚拟机(VM),并安装例如Debian操作系统。配置主机名后,通过SSH连接至VM以安装Docker并创建MariaDB Xpand容器。
数据库连接
连接到Xpand数据库与连接MariaDB 社区版或企业版服务器相同。若已安装mariadb命令行工具,只需执行以下命令:
mariadb -h 127.0.0.1 -u user -p您可以通过SQL数据库的GUI工具如DBeaver、DataGrip或您IDE中的SQL扩展(例如此扩展适用于VS Code)来连接数据库。我们将使用一款名为DbGate的免费开源SQL客户端。您可以下载DbGate并作为桌面应用程序运行,或者如果您正在使用Docker,可以将其部署为可通过任何地方的网络浏览器访问的Web应用程序(类似于流行的phpMyAdmin)。只需运行以下命令:
docker run -d --name dbgate -p 3000:3000 dbgate/dbgate容器启动后,将浏览器指向http://localhost:3000/。填写连接详情:
点击测试,确认连接成功:

点击保存,然后在左侧面板中右键点击连接并选择创建数据库来新建数据库。尝试创建表或导入SQL脚本。如果您只想尝试一下,Nation或Sakila都是不错的示例数据库。
从Java、JavaScript、Python和C++连接
要从应用程序连接到Xpand,可使用MariaDB连接器。存在多种编程语言与持久化框架的组合方式。本文不涉及这些内容,但若您希望快速上手并看到实际操作,请查看此快速入门页面,其中包含Java、JavaScript、Python和C++的代码示例。
分布式SQL的真正实力
本文中,我们学习了如何为开发和测试目的启动单节点Xpand,而非生产负载。然而,分布式SQL数据库的真正力量在于其不仅能像传统数据库分片那样扩展读取操作,还能通过简单地增加节点并让再平衡器优化地重新定位数据来扩展写入操作。尽管可以部署多节点拓扑的Xpand,但在生产中最简便的使用方式是通过SkySQL。
若您想深入了解分布式SQL及MariaDB Xpand,以下是一些有用资源:
Source:
https://dzone.com/articles/distributed-sql-an-alternative-to-sharding