













将您的原始数据转换为有组织且可操作的信息可能听起来很复杂。好消息是,当您拥有快速而高效的解决方案时,一切都变得简单。不用担心!这个适用于初学者的 AWS Glue 教程会帮助您。
在本教程中,您将学到使用 AWS Glue 进行配置和执行数据转换的关键步骤。
探索并简化基于云的分析的数据准备过程!
先决条件
在使用 AWS Glue 之前,请确保您有一个已激活计费的亚马逊网络服务(AWS)帐户。本教程将适用于免费帐户。
为 AWS Glue 创建 IAM 角色
在执行转换作业之前,您必须创建一个身份和访问管理(IAM)角色,该角色授予 AWS Glue 服务在您的AWS帐户中访问哪些类型资源的权限。
要创建 IAM 角色,请按照以下步骤操作:
1. 打开您喜欢的网络浏览器,并登录到AWS 管理控制台。
2. 在结果列表中搜索并选择 IAM,以访问 IAM 控制台。
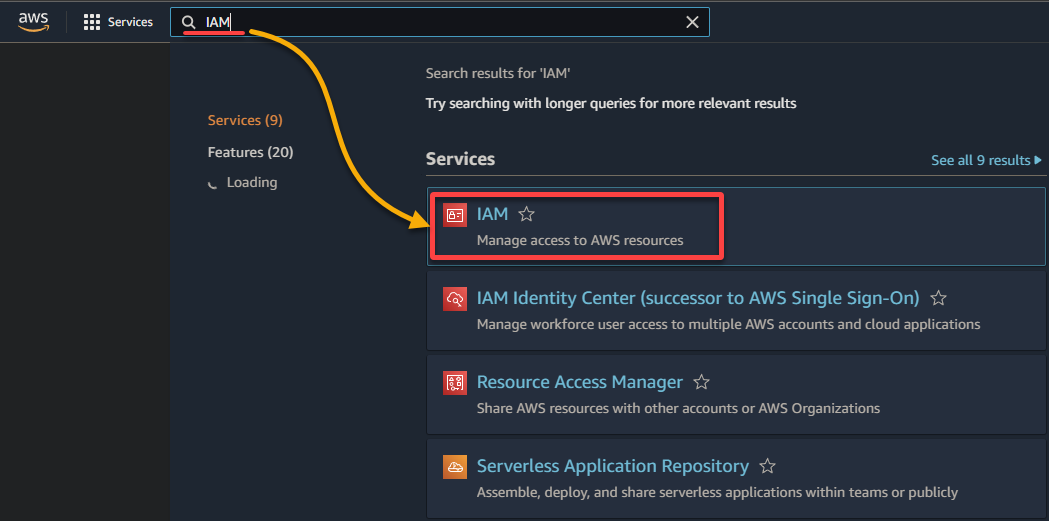
3. 在 IAM 控制台中,导航至 角色(左窗格),然后点击 创建角色(右上角),将您的浏览器重定向到专门用于配置该角色的新页面。

4. 现在,为角色配置以下设置:
- 受信实体类型 – 选择 AWS 服务,使 AWS 服务信任该角色。这样做可以让该服务假定该角色并代表您执行操作。
- 用例 – 在其他 AWS 服务部分的用例中选择 Glue,因为您将专门为 AWS Glue 创建 IAM 角色,然后点击下一步。
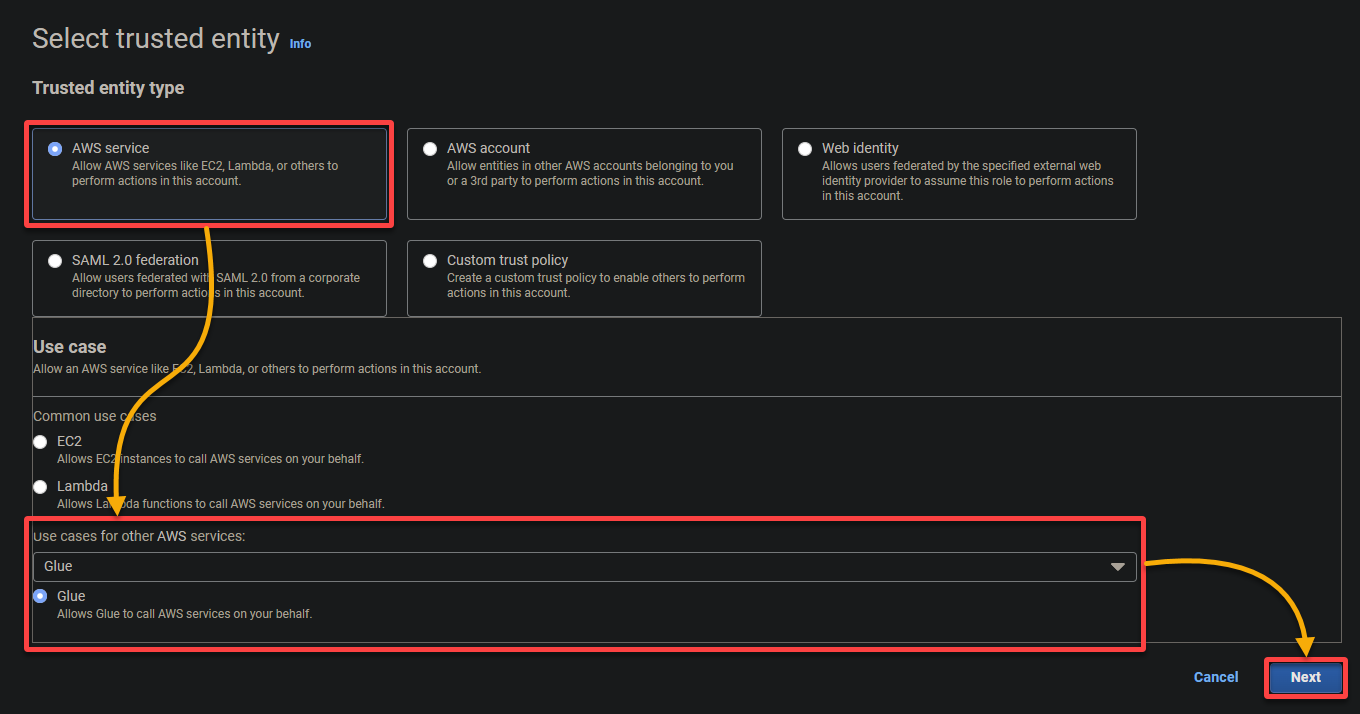
5. 搜索并选择以下策略,然后点击 下一步。
- AWSGlueServiceRole – 授予 AWS Glue 服务执行其操作所需的权限。
- S3FullAccess – 授予对 S3 资源的完全访问权限,允许 AWS Glue 从 S3 存储桶中读取和写入。
AWS Glue 需要对 S3 存储桶进行广泛的读取和写入权限,以有效执行其数据提取、转换和加载(ETL)任务。
? 避免授予不必要的过度权限,因为它们可能带来安全风险。
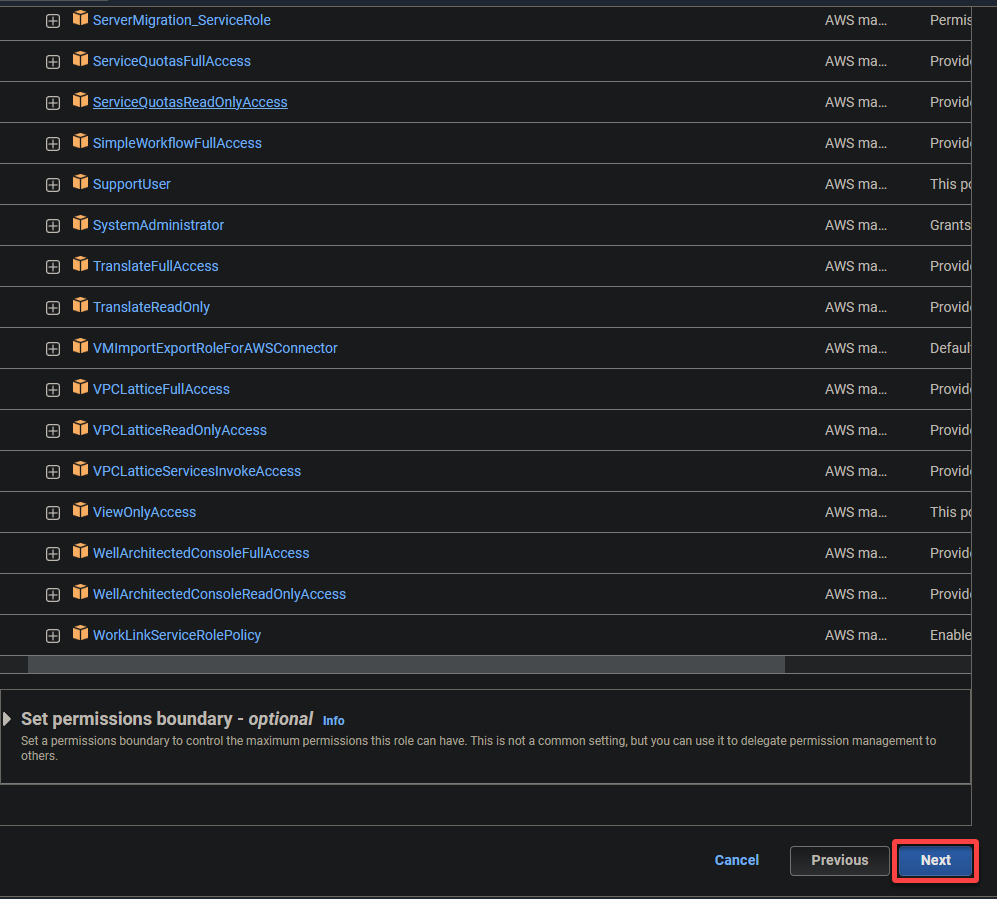
6. 为该角色提供一个描述性名称(例如,glue_role)和描述。
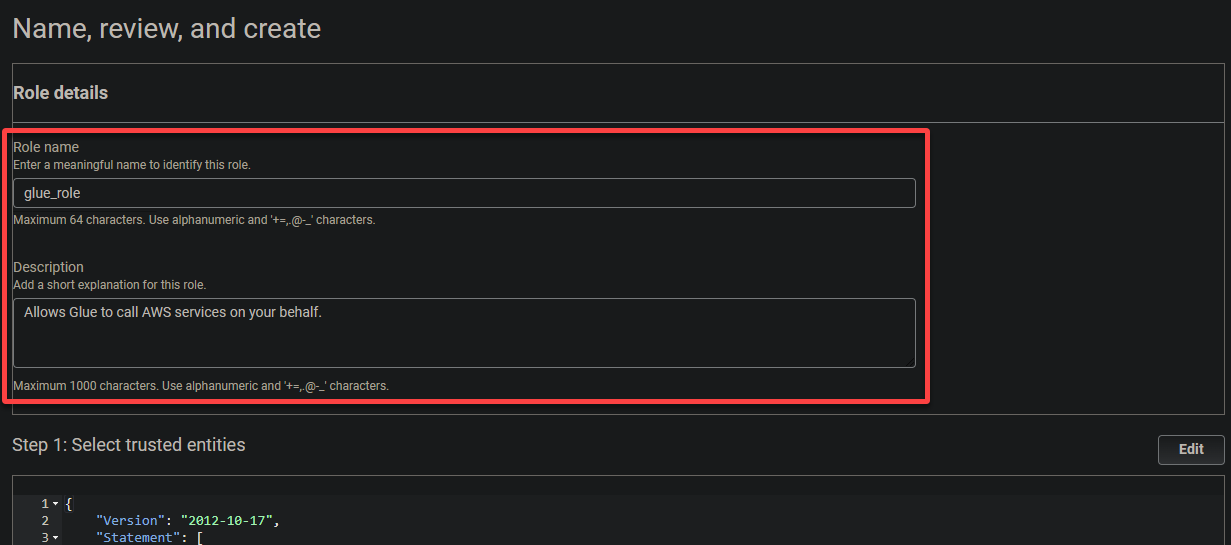
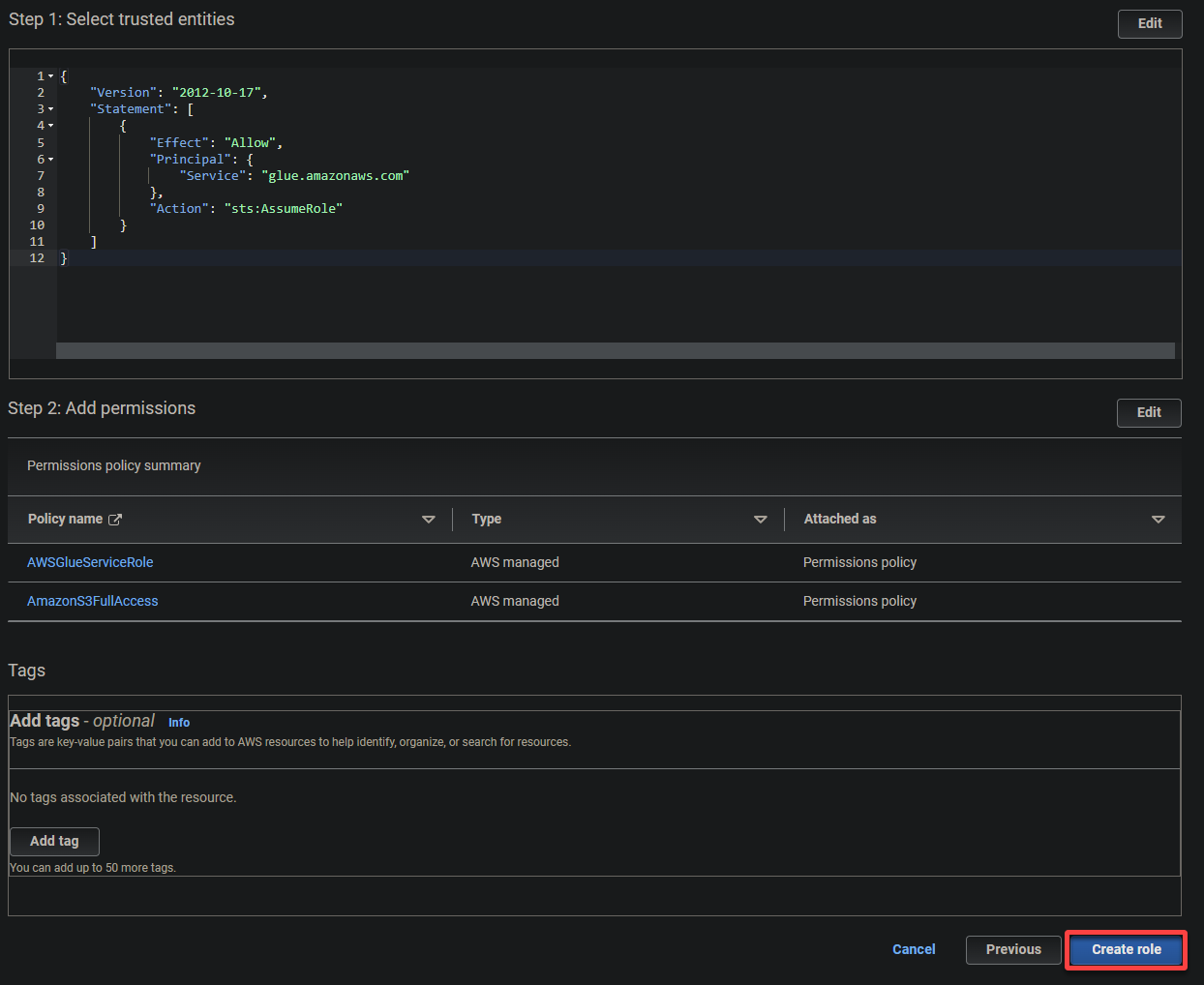
最后,向下滚动,检查您的设置,然后单击创建角色(右下角)来完成角色的创建。
创建S3 Bucket并上传示例文件
现在您已经为AWS Glue创建了IAM角色,您需要一个地方来存储您的数据,具体来说,是一个S3存储桶。S3存储桶为存储AWS Glue将处理的数据提供了一个集中的位置。
在此示例中,AWS Glue将使用AWS S3作为各种操作的数据存储,例如数据提取、转换和加载(ETL)任务。
要创建一个S3存储桶并上传示例文件,请按照以下步骤操作:
1. 下载样本数据文件(例如每个政客数据集)到您的本地计算机。该文件包含一组非结构化的记录,用作AWS Glue转换作业的输入。
2. 搜索并选择S3服务以访问S3控制台。
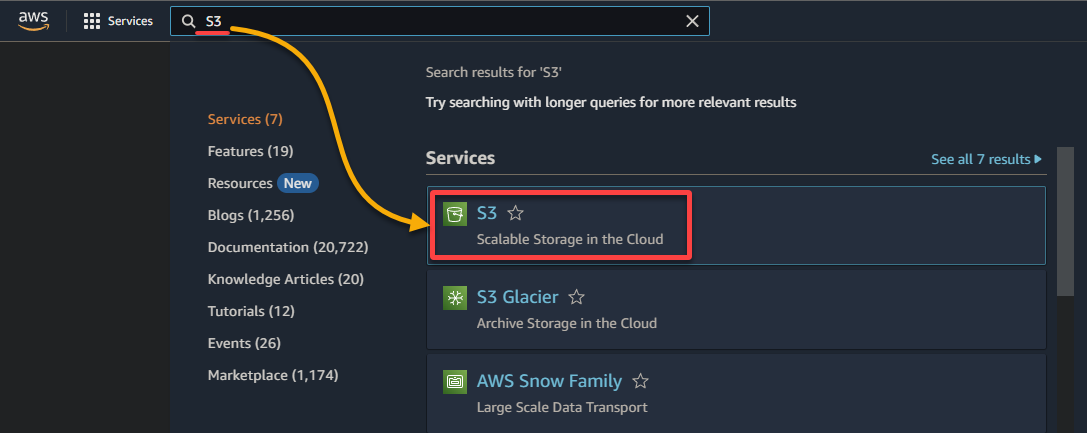
3. 单击创建存储桶以开始创建新的S3存储桶。

4. 现在,为您的存储桶提供一个唯一的名称(例如sampledata54675)并选择存储桶应位于的区域。
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
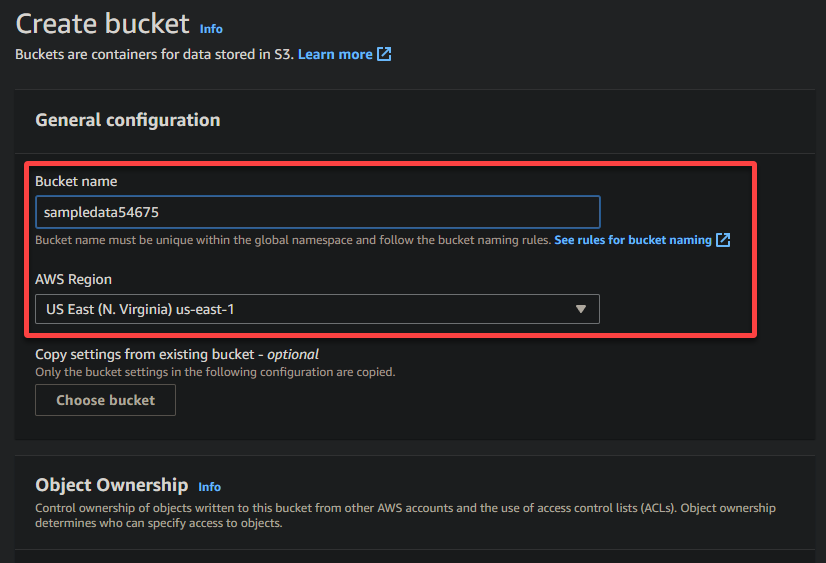
5. 向下滚动,保持其他选项不变,然后单击创建存储桶以创建存储桶。

6. 创建完毕后,单击新创建的S3存储桶的超链接以导航至存储桶。

7. 单击上传并找到您想要上传的示例文件。
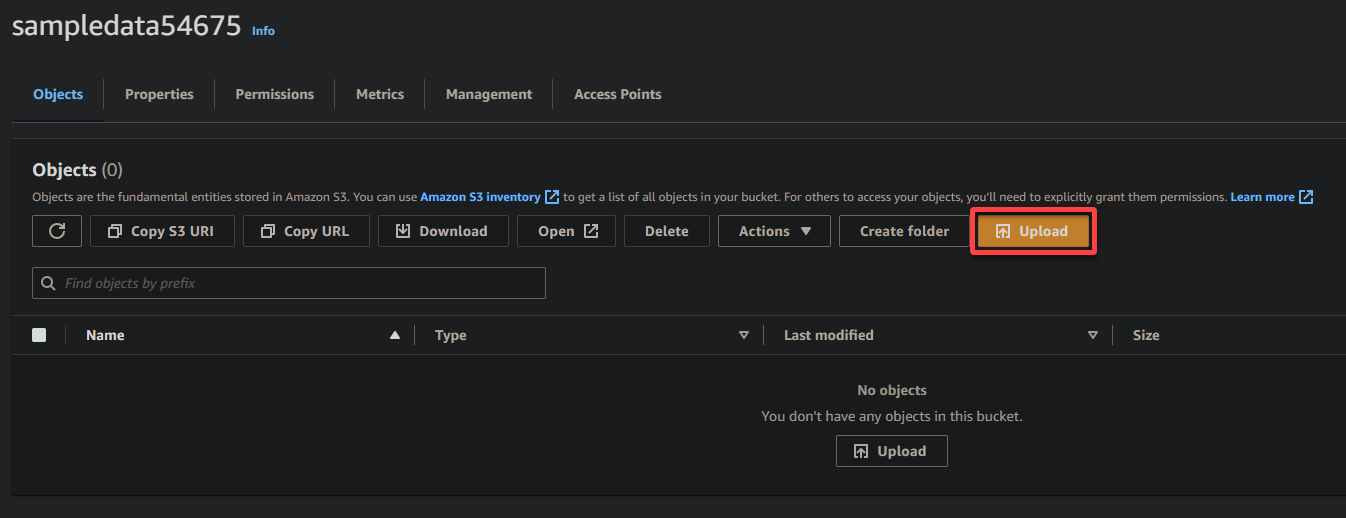
最后,保持其他设置不变,然后单击上传以将示例文件上传到新创建的存储桶。
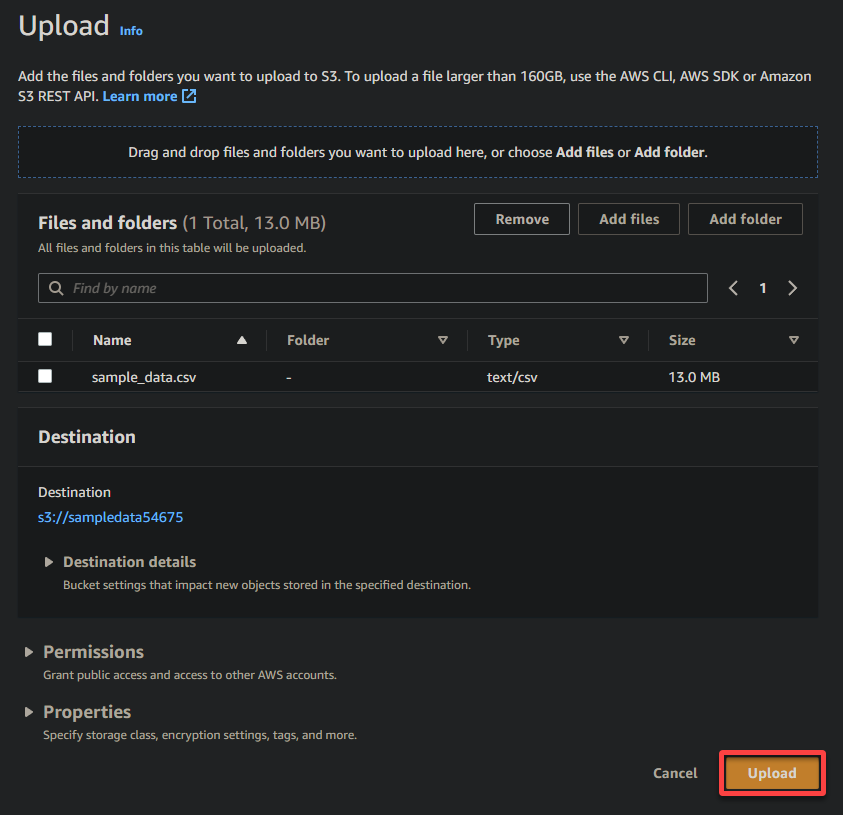
如果成功,您将在存储桶中看到您新上传的文件,如下所示。
创建一个Glue爬虫来扫描和编目数据
您刚刚将示例数据上传到您的S3存储桶,但由于目前它是非结构化的,您需要一种方法来读取数据并构建元数据目录。如何做?通过创建一个Glue爬虫,它会自动扫描和编目数据。
要创建一个Glue爬虫,请按照以下步骤进行:
1.通过AWS管理控制台导航到AWS Glue控制台,如下所示。
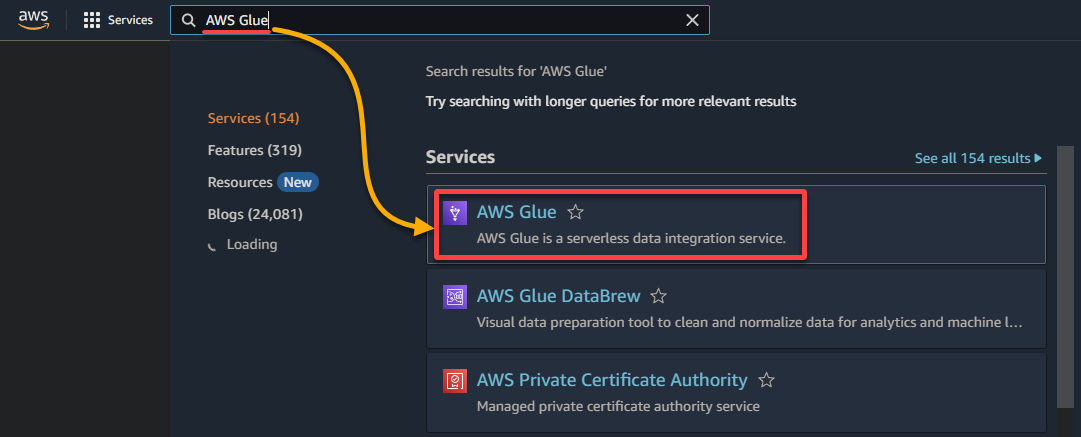
2.接下来,导航到爬虫(左侧窗格)并单击添加爬虫(右上角)以初始化创建一个新的Glue爬虫。
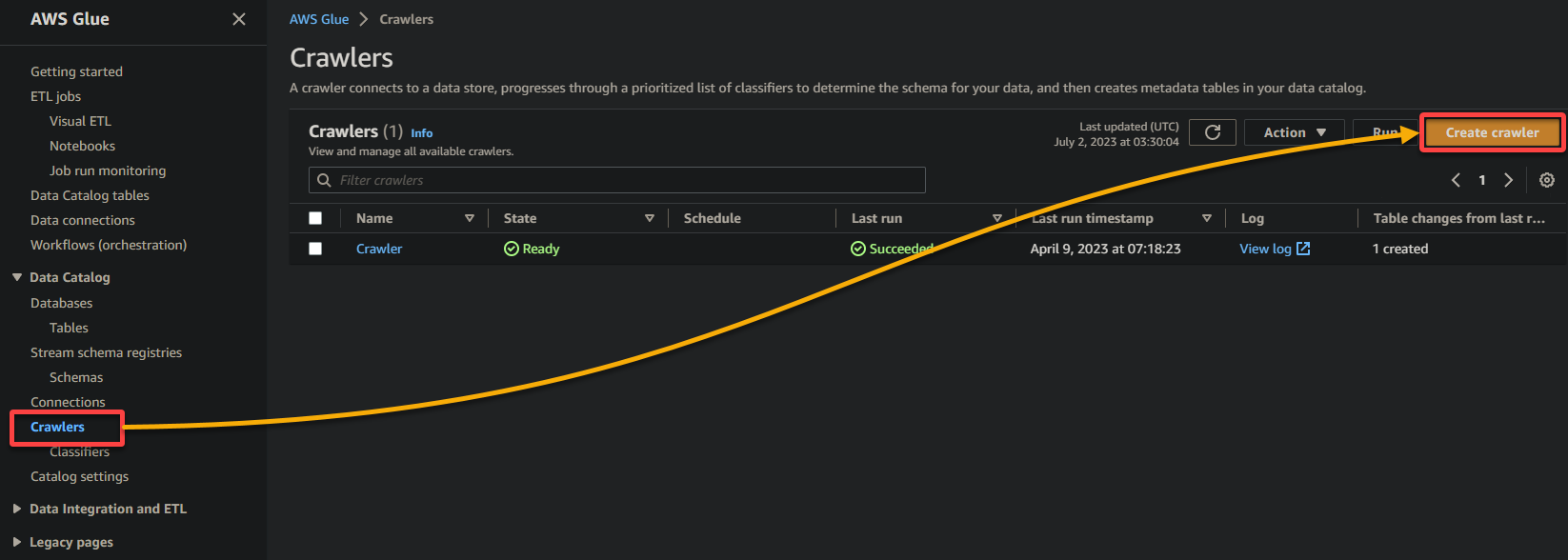
3.提供一个描述性名称(例如,glue_crawler)和爬虫的描述,保持其他设置不变,然后单击下一步。
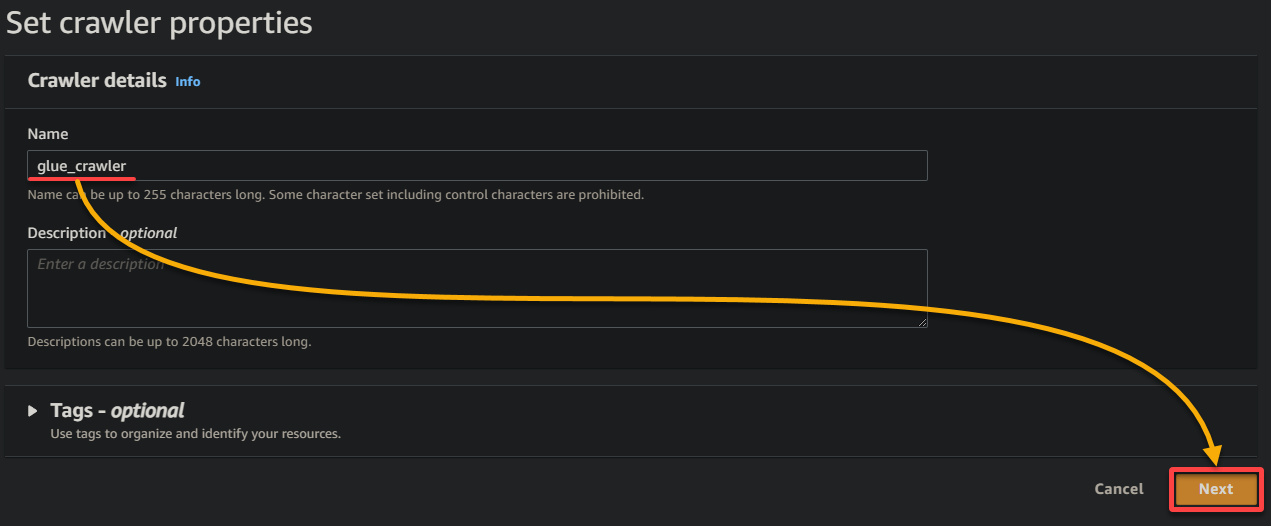
4.现在,单击添加数据源在数据源下以初始化向爬虫添加新数据源。
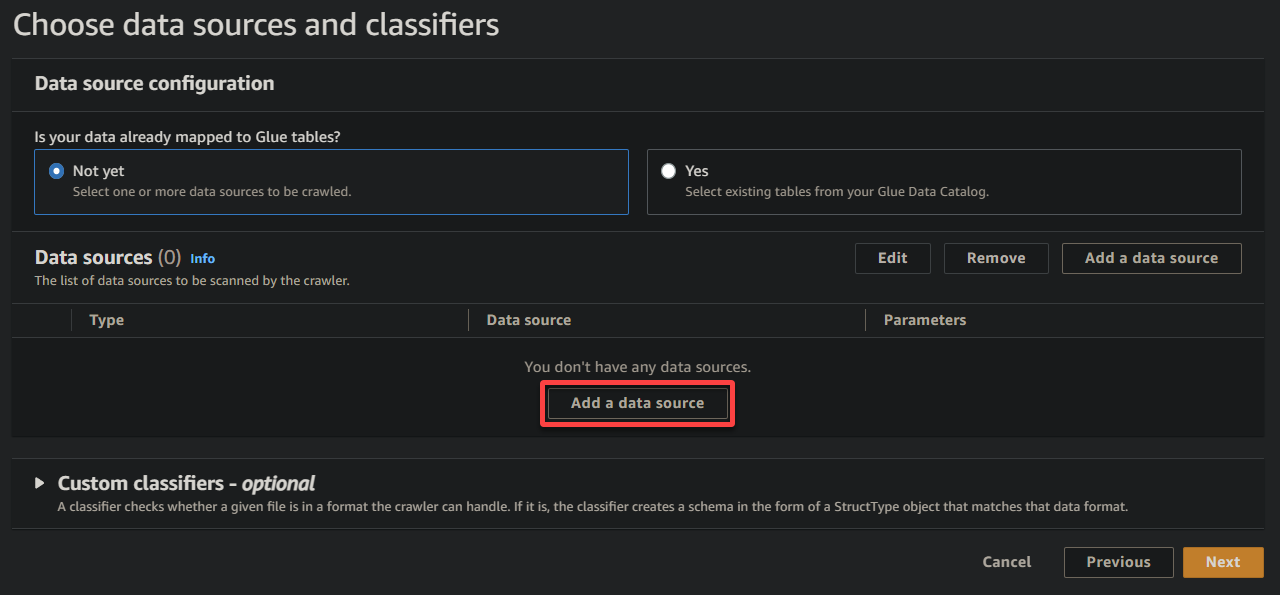
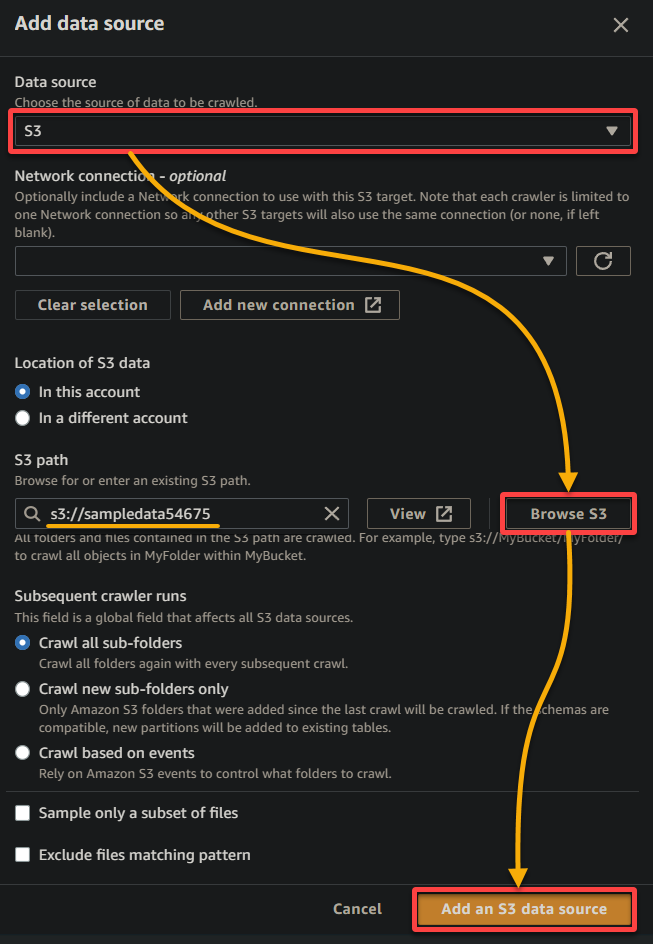
5.在弹出窗口上,配置数据源如下:
- 数据源 – 选择S3,因为您的数据在S3存储桶中。
- S3路径 – 点击浏览 S3,选择包含您上传的示例数据(sampledata54675)的存储桶。
- 将其他设置保持不变,然后点击添加 S3 数据源将示例数据添加到爬虫中。
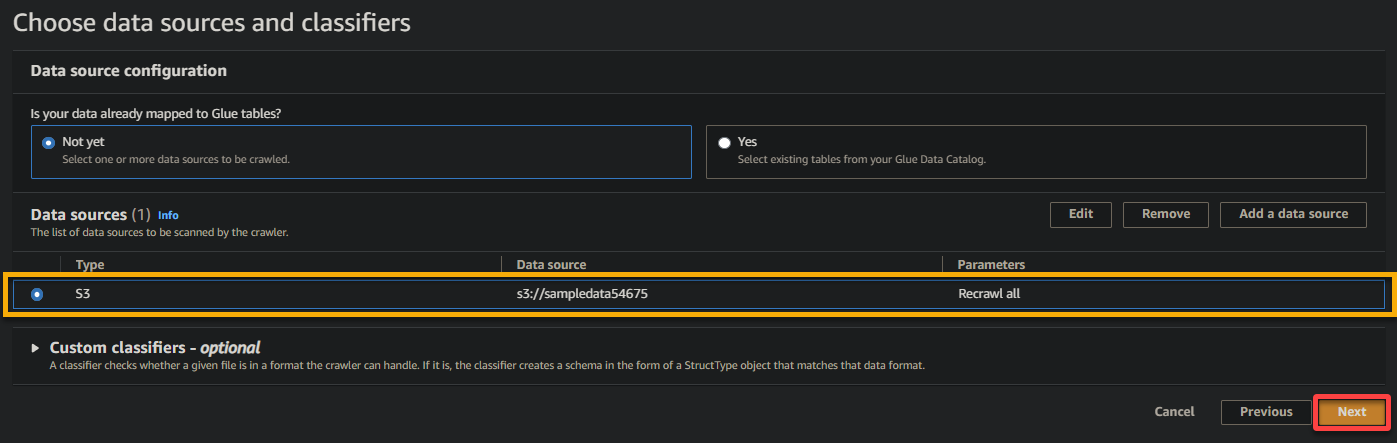
6. 配置完成后,请验证数据源,如下图所示,并点击下一步继续。
7. 在下一个屏幕上,选择您之前创建的 IAM 角色(glue_role),将其他设置保持不变,然后点击下一步。
8. 在输出和调度下,点击添加数据库以开始添加新数据库以存储您的 glue 爬虫生成的处理数据和元数据。此操作会打开一个新的浏览器选项卡,在那里您将配置数据库详细信息(第八步)。
此数据库提供了数据的结构化表示,用于查询和分析。
9. 在新的浏览器选项卡上,提供一个描述性的数据库名称(即,glue_database),然后点击创建数据库创建数据库。
10. 切换到之前的浏览器选项卡,从下拉菜单中选择新创建的数据库(glue_database),将其他设置保持不变,然后点击下一步。
11. 最后,在最终屏幕上审查您的设置以确保准确性,然后点击创建爬虫(右下角)创建新爬虫。
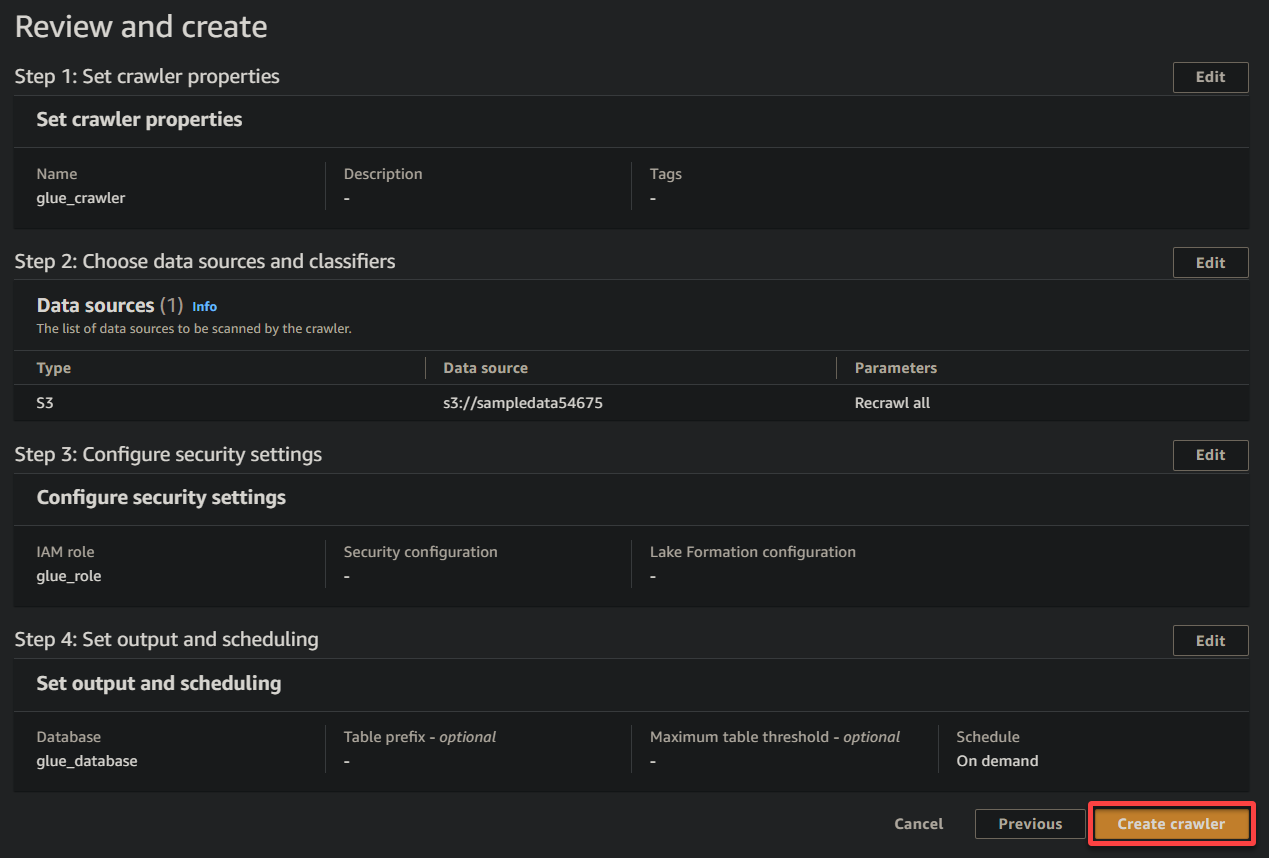
如果一切顺利,您将看到一个屏幕,确认爬虫成功创建。暂时不要关闭此屏幕;您将在下一节中运行此爬虫。
运行Glue爬虫构建元数据目录
有了新的爬虫工具,运行爬虫是开始扫描和编目过程的关键步骤。您的Glue爬虫将构建一个元数据目录,为查询和分析提供了您数据的结构化表示。
要运行您新创建的Glue爬虫:
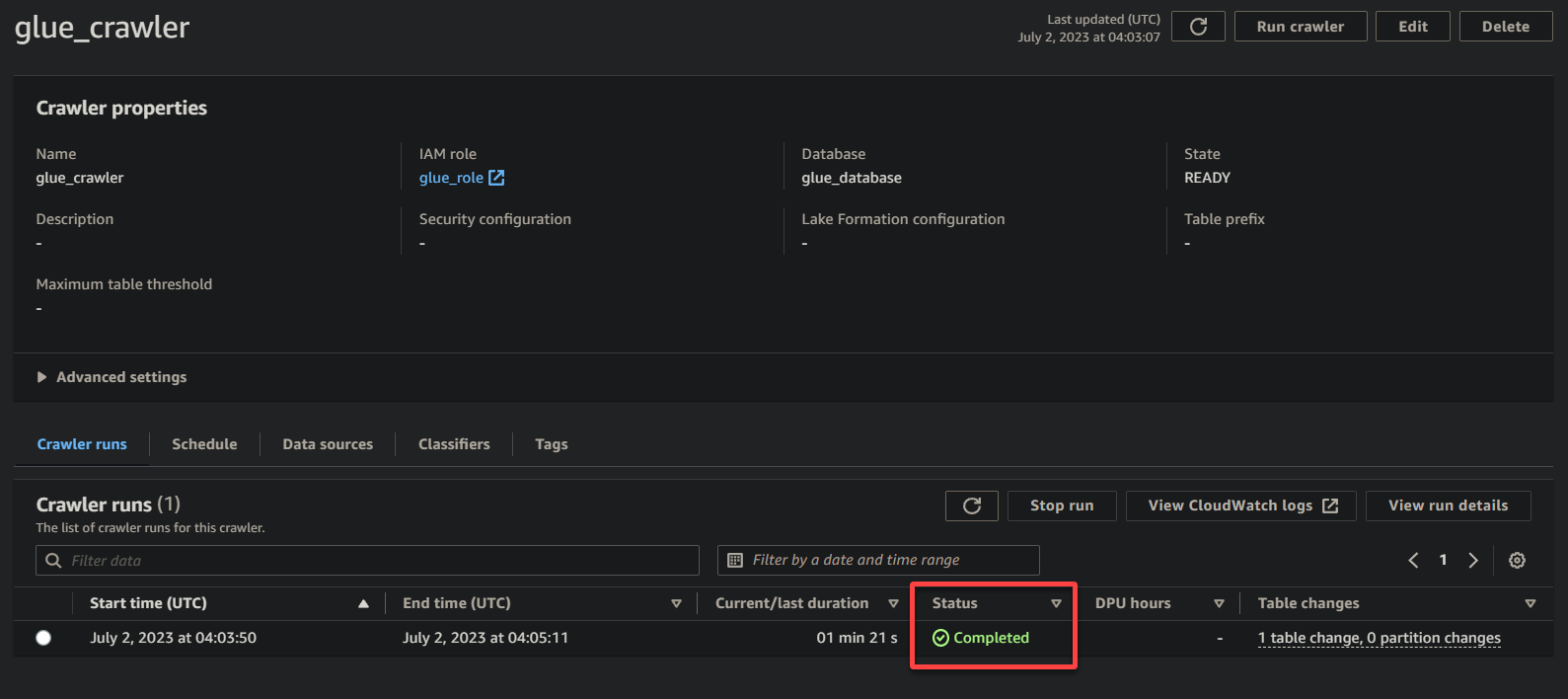
1. 在爬虫详情页面,单击运行爬虫选项卡下的爬虫运行以启动爬虫的执行。
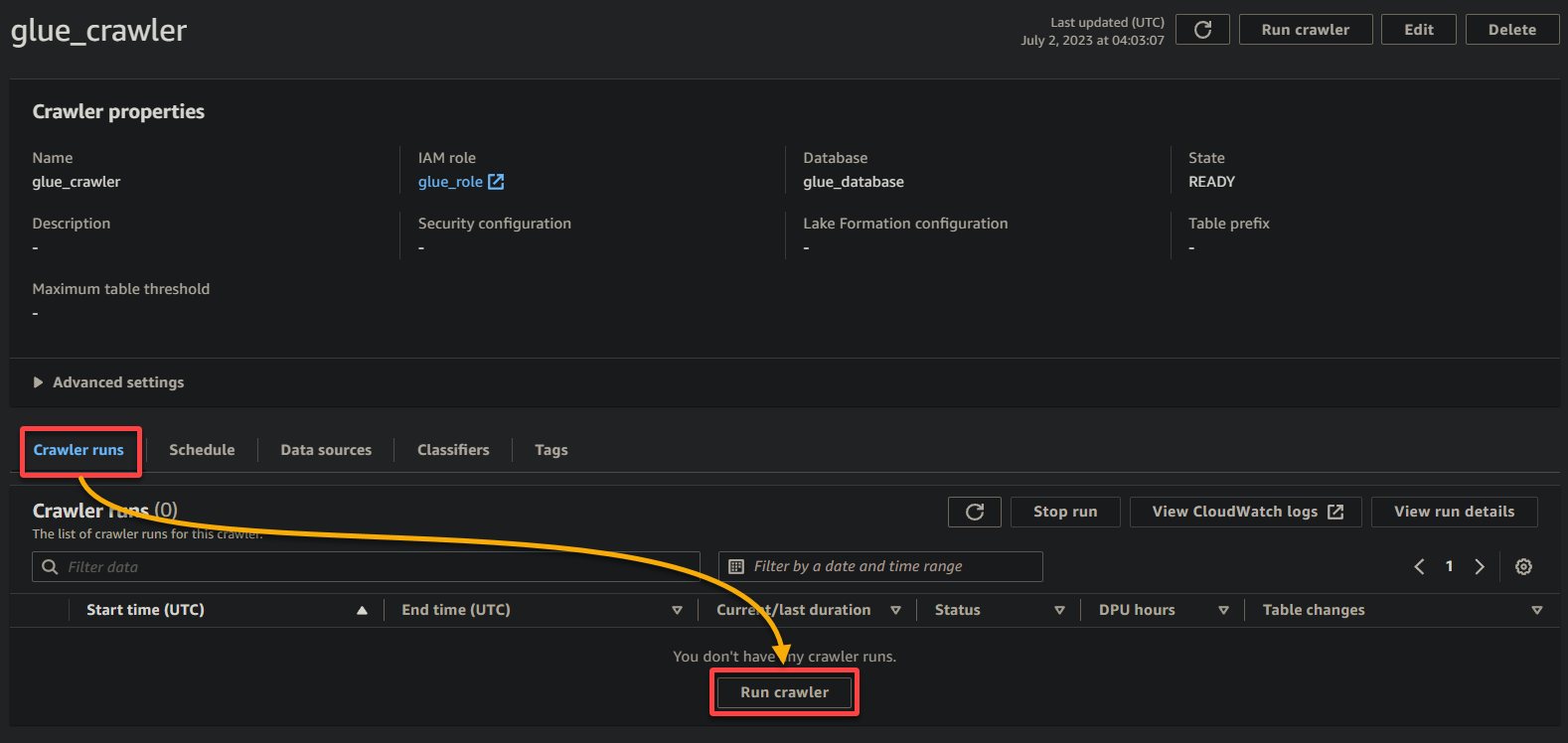
一旦爬虫开始运行,您将在爬虫详情页面上看到其状态和进度。
根据您数据的大小和复杂性,爬虫可能需要一些时间来完成执行。您可以定期刷新页面以查看爬虫的最新状态。
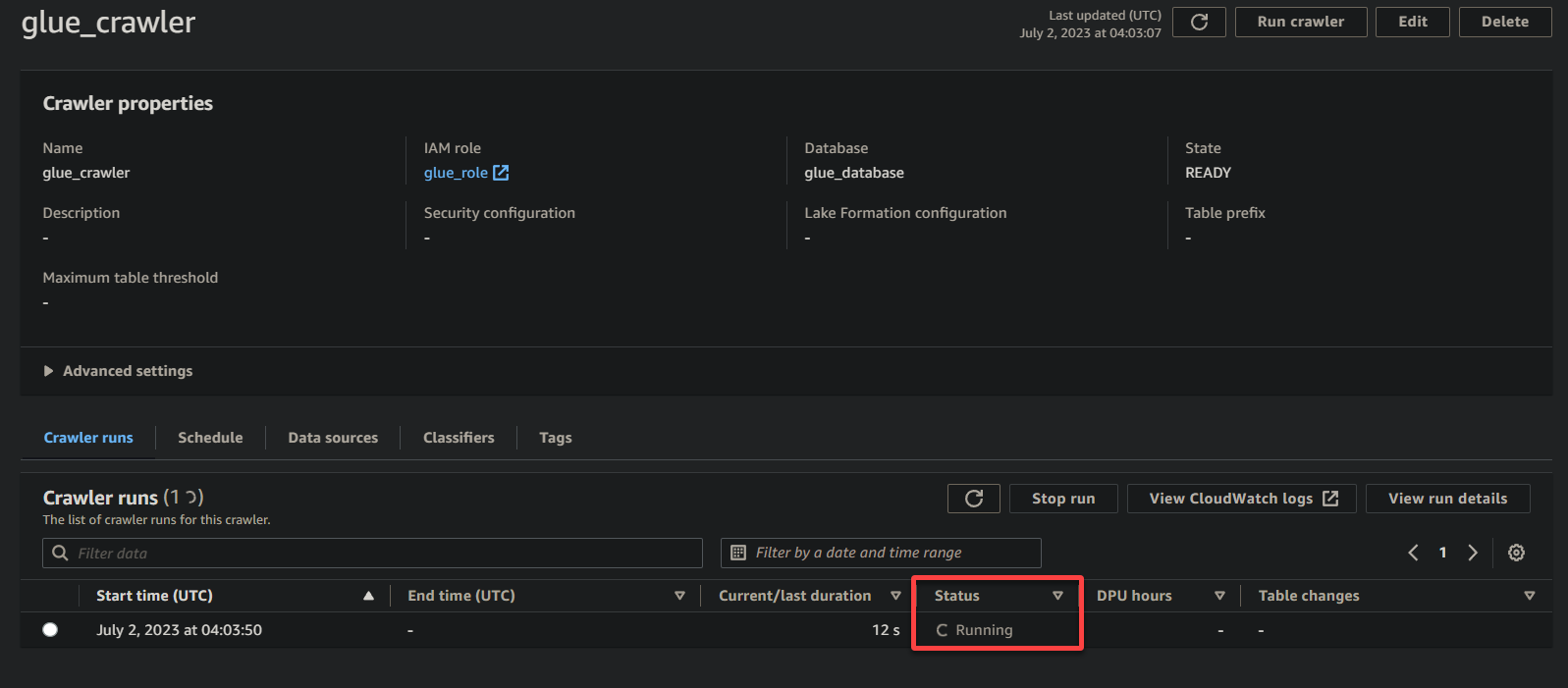
一旦爬虫完成执行,状态将变为已完成,如下所示。此时,您可以继续查询您的数据。
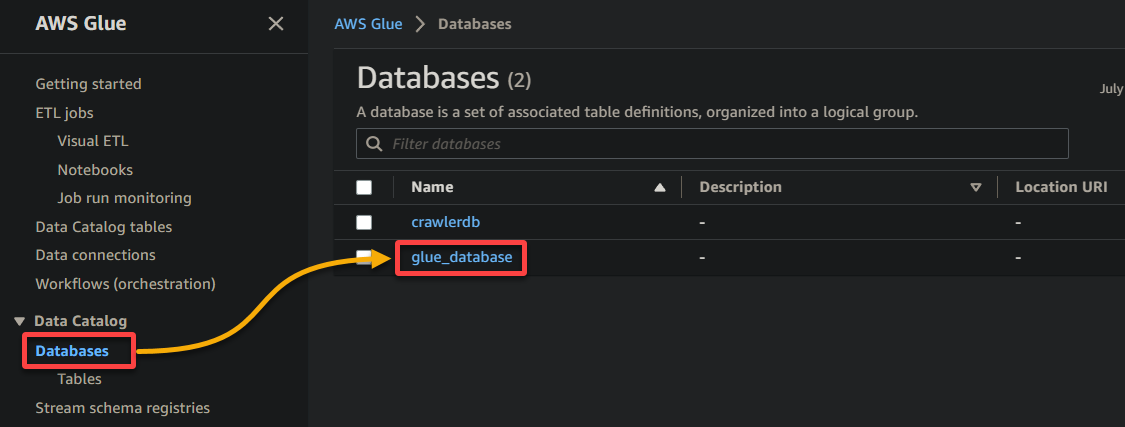
2. 接下来,导航到数据库(左侧窗格),然后单击您的数据库以访问其属性和表。
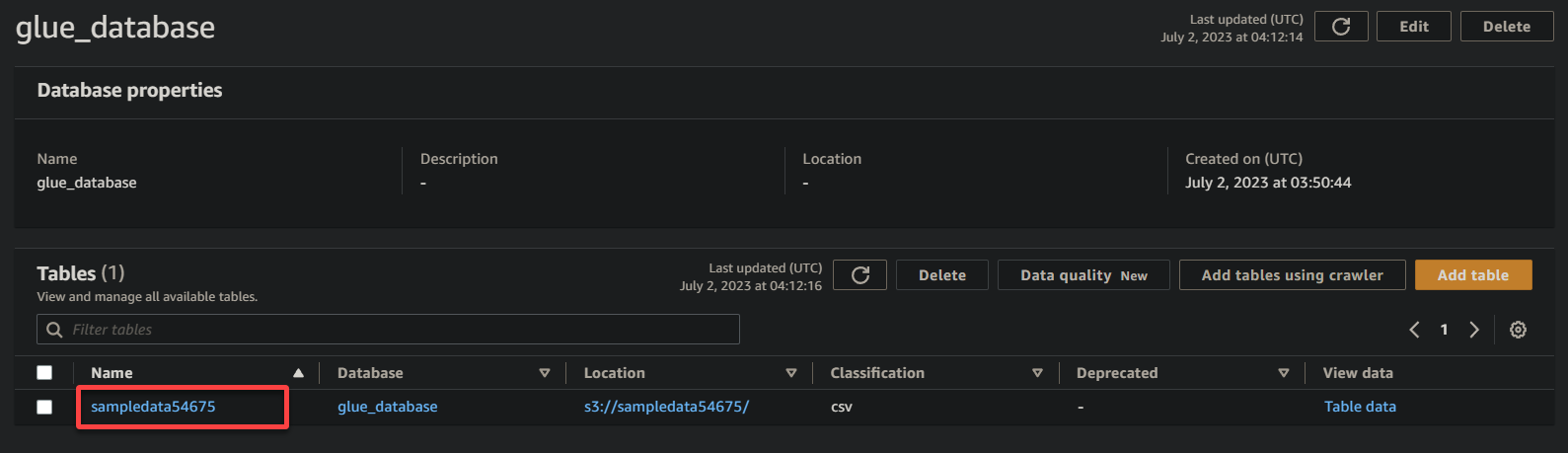
3. 最后,单击您的存储桶名称(sampledata54675),现在是一个表,以查看其存储的数据。
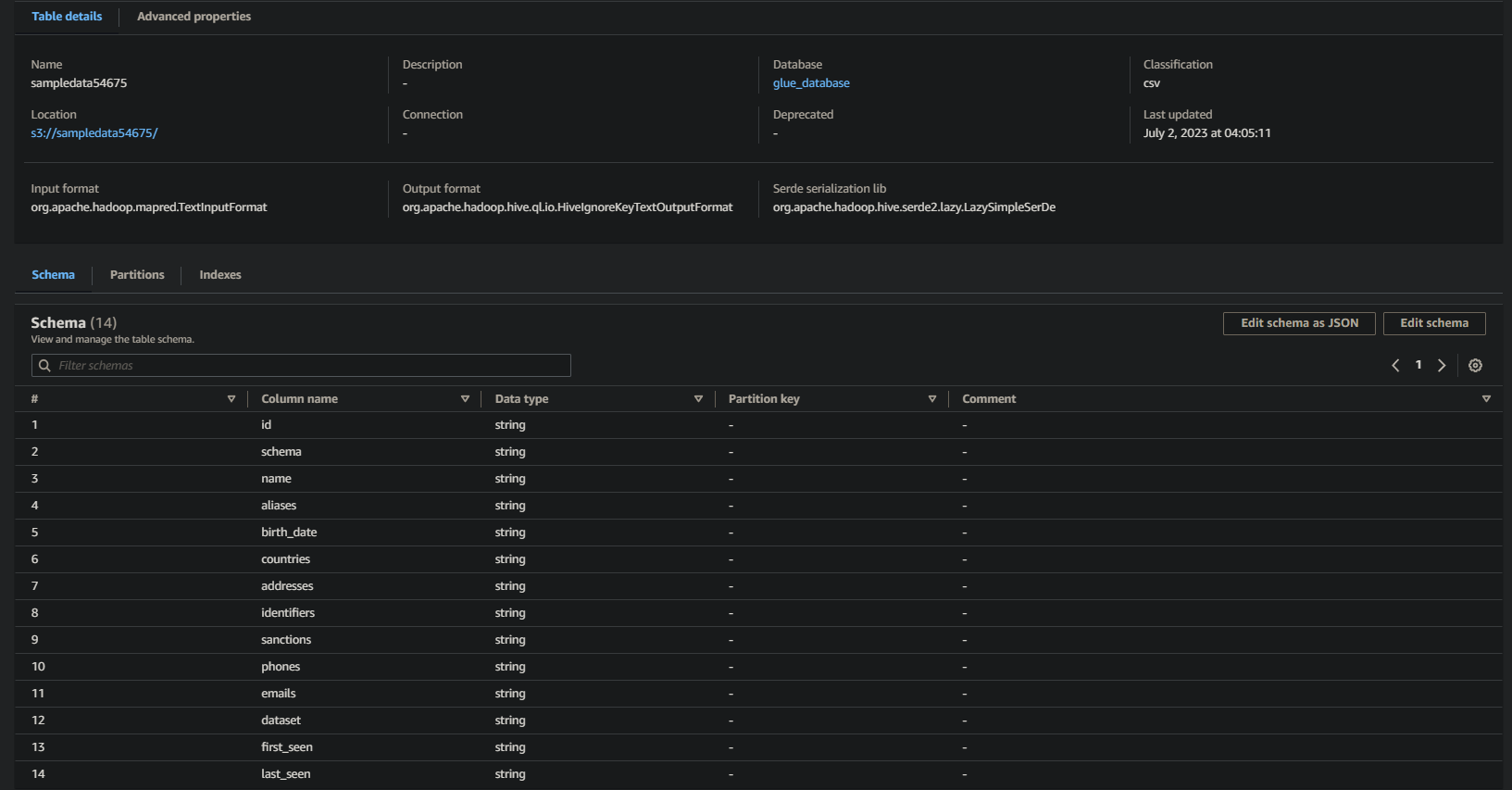
如果成功,您将看到类似以下的信息。此信息确认数据已成功转换为数据库表,提供了宝贵的细节。
通过AWS Athena查询编目的数据
现在,您的数据已经在AWS Glue数据目录中可用,您可以使用各种工具来查询和分析您的数据。其中一种工具是AWS Athena,这是一种交互式查询服务,使您能够使用标准SQL在云中分析数据。
要使用AWS Athena查询数据,请按照以下步骤操作:
1.搜索并访问Athena控制台。
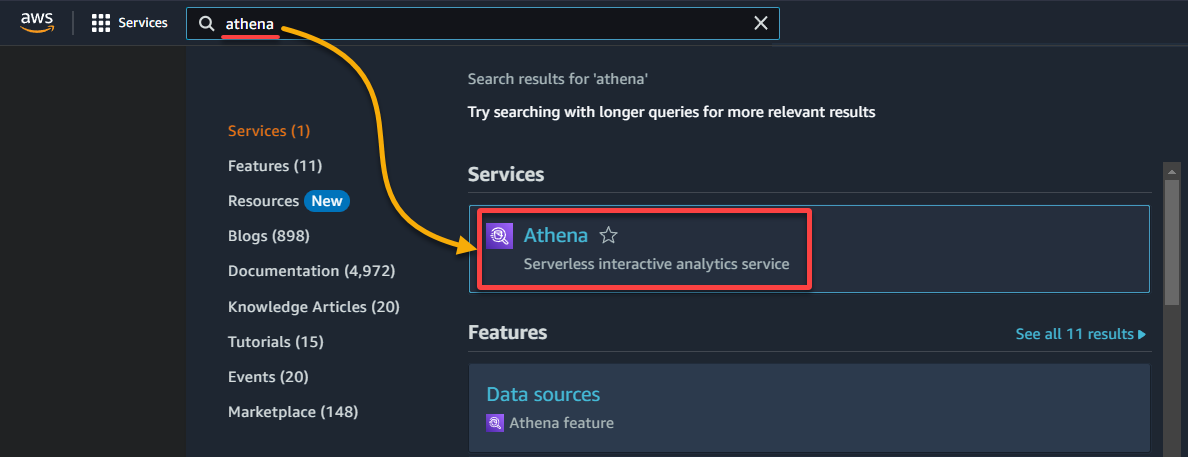
2.在数据部分下,选择您的数据目录所在的数据库,如下所示:
- 数据源 – 选择AwsDataCatalog以指示您想查询AWS Glue中目录化的数据。
- 数据库 – 从下拉菜单中选择适当的数据库(即glue_database)。
?如果您在下拉菜单中找不到所需的数据库,请确保爬虫已完成执行并目录化了数据。
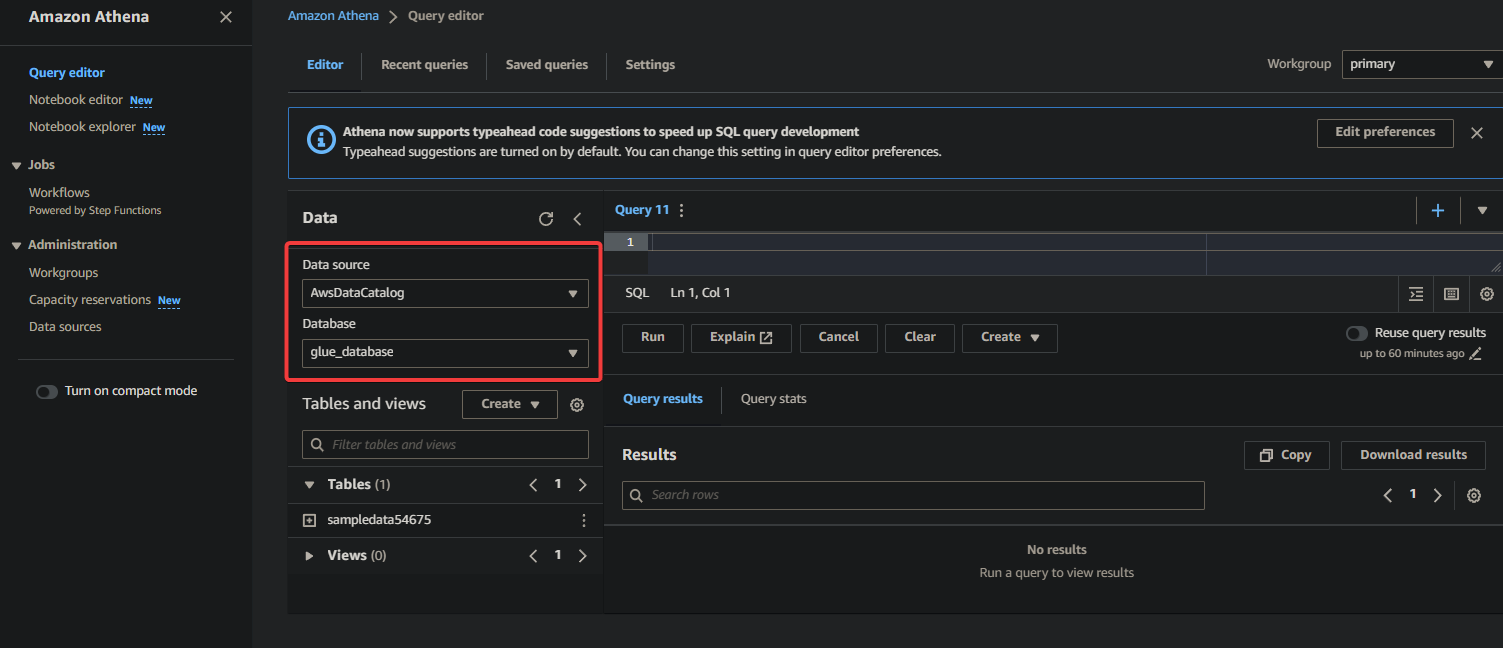
3.最后,在右侧的查询编辑器中填写并运行以下查询。
此查询将返回glue_database数据库中sampledata54675表的前10行数据。随意修改查询以满足您的特定需求。
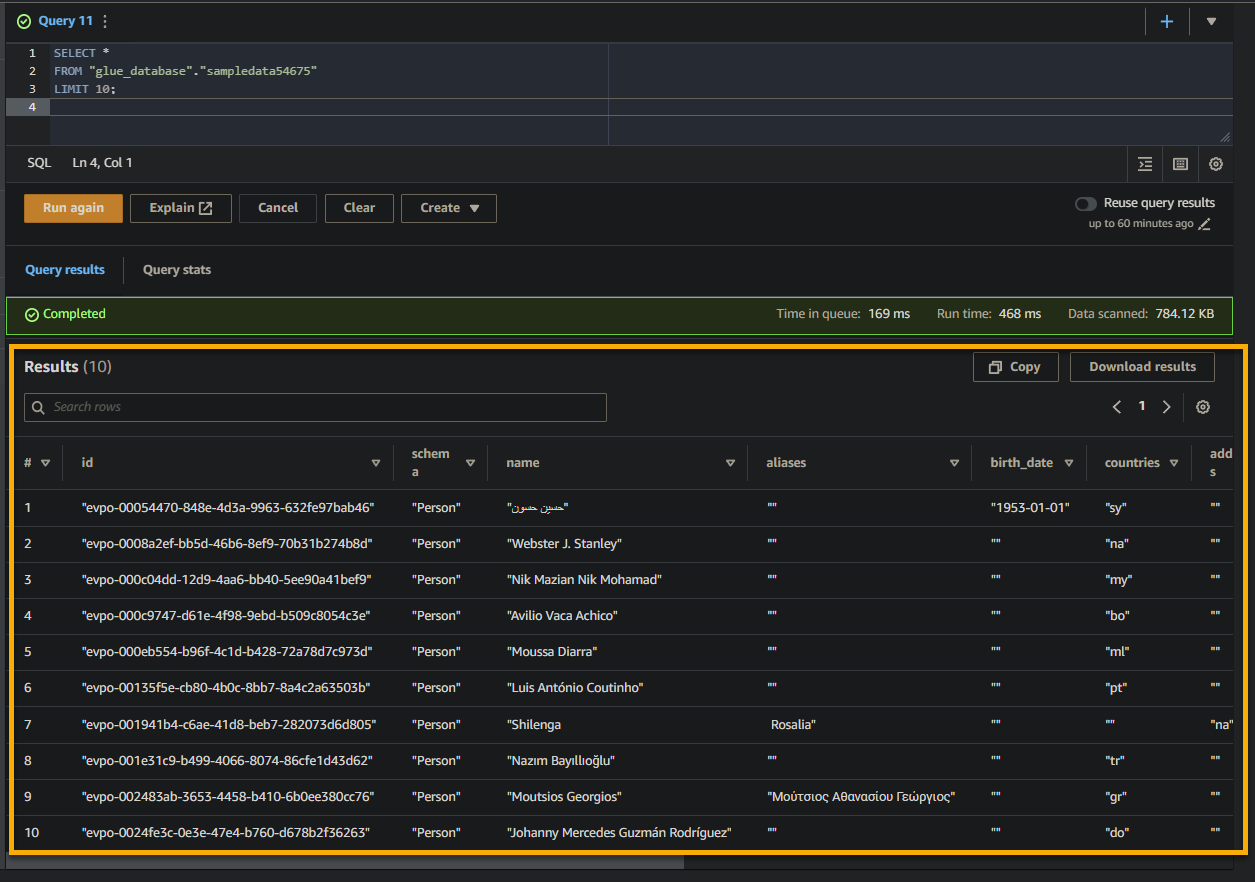
如果查询成功,您将在下面的结果窗格中看到结果。结果包含了根据您的SQL查询在表中存储的记录信息。
请注意列名、数据类型和结果集中返回的值。这些信息有助于您理解查询数据的结构和内容。
结论
在本教程中,您已经学习了使用AWS Glue创建Glue爬虫、编目您的数据以及使用AWS Athena查询数据的基础知识。数据准备和分析对于任何数据驱动的应用程序都是必不可少的。而像AWS Glue这样的工具提供了一种快速将数据从各种来源提取、转换和加载(ETL)到数据库表中的方式。
通过AWS Glue,您现在可以快速管理和组织数据,让您更专注于分析和从数据中获取见解。但是您所看到的只是冰山一角。探索AWS Glue可以提供的广泛功能和功能!
为什么不利用AWS Glue连接与其他AWS服务(如Amazon RDS或Amazon Redshift)无缝集成呢?这种集成使您能够构建复杂的ETL管道,并实现更强大的数据分析能力。