













数据可视化将复杂信息转化为清晰、可操作的洞察。Seaborn 柱状图通过优雅的统计图形展示分类数据,表现出色。该库结合了 Matplotlib 的灵活性和 pandas 的强大功能,非常适合快速分析和可发布的可视化。
Seaborn 柱状图提供了数据分析的基本功能 – 从基本比较到高级统计表现。它们处理常见任务,比如跨地区比较销售指标,分析调查响应,以及可视化实验结果。
该库直观的语法和内置的统计函数使其对于初学者和经验丰富的数据从业者都非常有价值。

在本文中,我们将介绍 Seaborn 柱状图的基础知识,使用代码示例创建基本图表,通过自定义增强图表,实现高级功能,并探索实际应用。
要了解如何使用Seaborn进行数据可视化,请查看我们的使用Seaborn进行数据可视化入门课程。
Seaborn条形图基础
在深入研究条形图之前,让我们先了解一些Seaborn的基础知识,以及它在条形图中的优势,以及如何设置编码环境。
什么是Seaborn?
Seaborn是一个基于Matplotlib的Python统计数据可视化库。它专注于用最少的代码创建信息丰富且吸引人的统计图形。该库与pandas DataFrame紧密集成,使其在数据分析工作流程中特别有效。
它提供了一个高层接口,可以绘制吸引人的图表,同时自动处理许多样式细节。
该库在三个关键方面表现出色:
- 它与pandas DataFrame无缝集成,使数据操作变得简单直接。
- 它具有内置统计功能,消除了单独计算的需求
- 默认情况下,它应用专业外观的主题和颜色调色板
例如,虽然 Matplotlib 需要多行代码来创建基本的统计可视化,但 Seaborn 只需一次函数调用就可以完成相同的任务。
特别是对于条形图,Seaborn 添加了强大的功能,如自动均值计算、置信区间和高级分类变量处理——这些功能在普通 Matplotlib 中需要大量额外代码才能实现。
为什么使用条形图?
条形图通过垂直或水平的条形展示分类数据,条形的长度表示数值。这使得它们非常适合比较不同组或类别之间的数值。在数据分析中,条形图有助于可视化调查结果、市场份额、绩效指标和销售分布。
主要优势包括:
- 跨类别的数量清晰比较
- 内置统计特征(均值、中位数、置信区间)
- 有效表示分组数据
- 简单而富有信息的视觉元素
- 专业演示的简单自定义选项
快速设置
要开始使用Seaborn创建条形图,我们需要设置Python环境。以下是开始的步骤:
首先,让我们安装所需的软件包,如下所示:
pip install seaborn pandas numpy
现在我们已经准备好所有可视化工具。让我们导入所需的库,如下所示:
# 用于创建统计可视化 import seaborn as sns # 用于数据处理和分析 import pandas as pd # 用于数值运算 import numpy as np
我们可以通过一些样式设置来使我们的图表看起来更好,如下所示:
# 干净的白色样式 sns.set_style("white")
white样式去除了网格线,并且在大多数屏幕上图表看起来都不错。在接下来的部分中,我们将学习如何创建条形图并对其进行增强。
创建基本的Seaborn条形图
条形图非常适合可视化分类和数值变量之间的关系。它通过误差线显示点估计(如均值或中位数)及其周围的不确定性。让我们来看一下seaborn条形图的基本语法。
语法和参数
sns.barplot() 函数在Seaborn中提供了一种简单的方法来创建统计条形图。 .barplot() 函数的基本结构如下所示:
sns.barplot( data=None, # Your DataFrame x=None, # Category variable y=None, # Numeric variable estimator='mean', # Statistical function to estimate errorbar=('ci', 95), # Error bars type and level orient=None # "v" for vertical, "h" for horizontal )
这些参数让我们控制展示数据的内容和方式。参数data接受你的DataFrame,而x和y指定要用于类别和值的列。参数estimator允许你选择应用的统计函数(默认为均值),而errorbar控制不确定性的显示方式。你还可以使用orient参数在垂直和水平方向之间切换。
现在,让我们看看如何利用Seaborn内置的小费数据集创建有效的柱状图,该数据集包含有关餐厅账单和小费的信息。
示例:可视化简单数据集
我们将使用小费数据集查看不同星期几的小费行为。该数据集包含有关餐厅账单的信息,包括星期几、总账单金额、小费金额和其他变量。
# 导入所需的库并加载数据集 import seaborn as sns tips = sns.load_dataset("tips") # 创建一个基本的柱状图,显示每天的平均小费 sns.barplot(data=tips, x="day", y="tip")
输出:
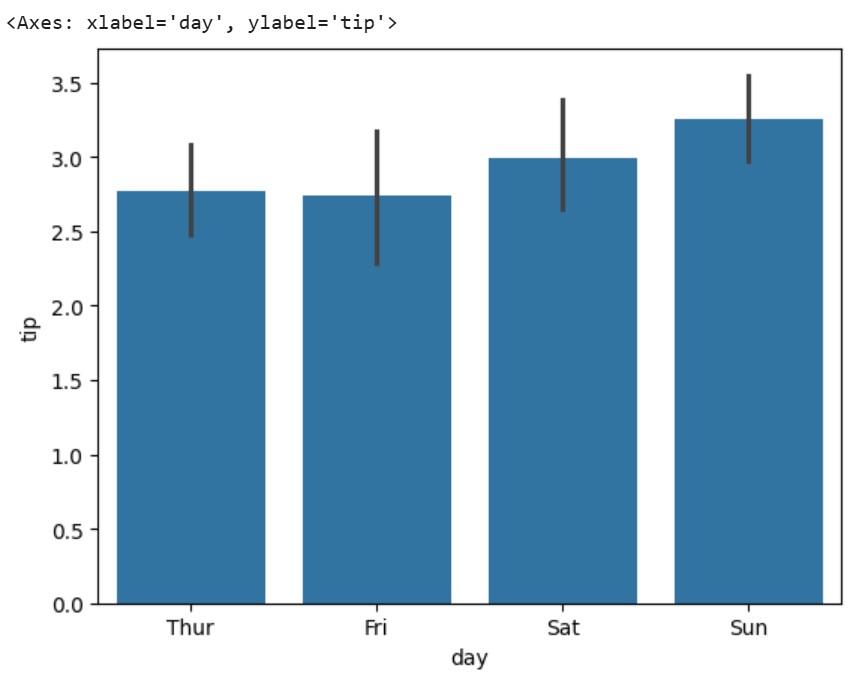
我们的代码创建了上述可视化,其中每个柱代表一周不同天的平均小费金额。每个柱的高度显示了平均小费值,而黑线(误差条)表示95%的置信区间 – 让我们了解典型小费金额以及变化范围。
我们还可以检查不同用餐时间的小费模式:
# 创建一个柱状图,显示每天不同用餐时间的平均小费 sns.barplot(data=tips, x="time", y="tip")
输出:

这个图表展示了午餐和晚餐服务之间小费行为的差异。每个柱的高度代表了该时间段的平均小费金额,误差线显示了小费行为的变化。这种可视化方式使得很容易发现模式并比较不同组别。
这些基本的柱状图为更复杂的可视化提供了基础。在下一部分,我们将看到如何通过颜色、分组和其他定制来增强这些图表,以创建更具信息性和视觉吸引力的可视化效果。
通过定制增强柱状图
为我们的柱状图添加视觉效果有助于使数据更具吸引力和易于理解。让我们看看如何使用小费数据集来定制柱状图。
为柱状图添加颜色
Seaborn提供了几种添加颜色的方式,使得柱状图更具视觉吸引力和信息性。我们可以为所有柱使用单一颜色,或者创建颜色编码的组别。
参数color设置所有柱的单一颜色,而palette允许您在数据有多个组时指定一种颜色方案。Seaborn提供了许多内置的颜色调色板,适用于不同类型的数据。
我们可以使用color参数创建一个单色的条形图,如下所示:
# 如果你还没有加载tips数据集,请先加载 import seaborn as sns tips = sns.load_dataset("tips") # 单色条形图 sns.barplot(data=tips, x="day", y="tip", color="skyblue")
输出:
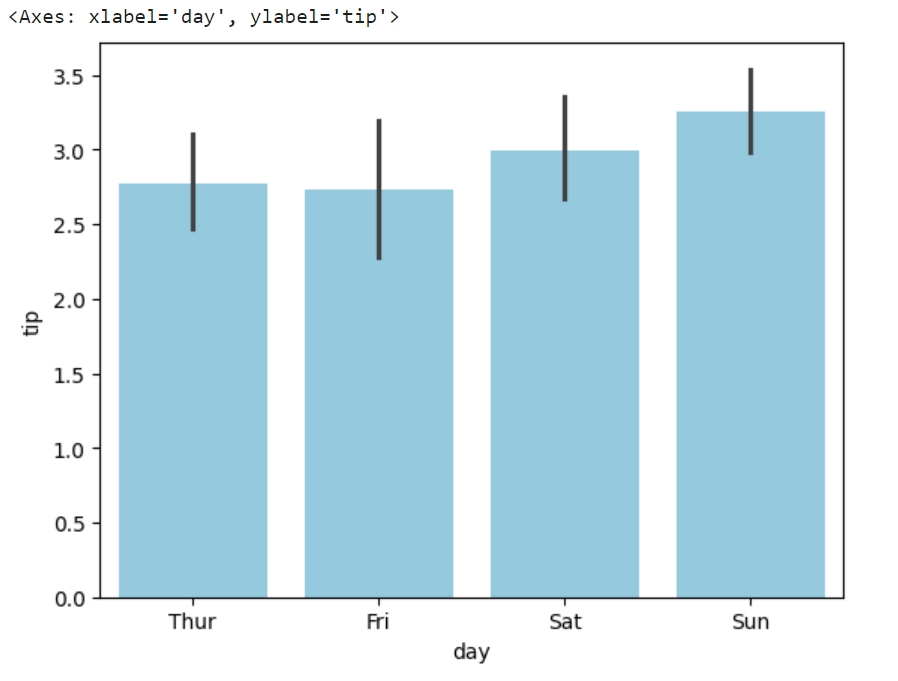
我们可以使用palette参数创建一个多色的条形图,如下所示:
# 如果你还没有加载tips数据集,请先加载 import seaborn as sns tips = sns.load_dataset("tips") # 使用不同的颜色调色板 sns.barplot(data=tips, x="day", y="tip", palette="Set2")
输出:
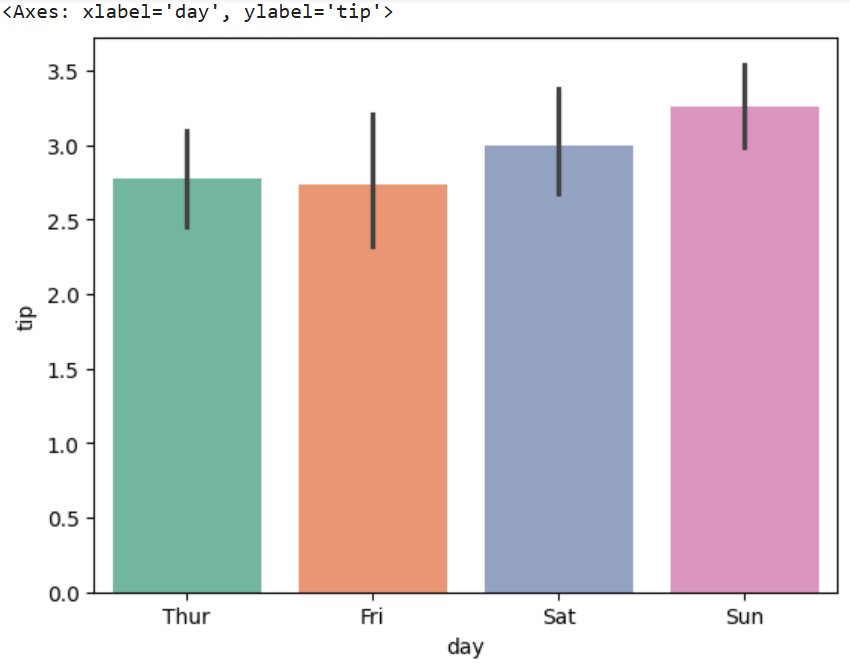
Seaborn多列条形图
Seaborn条形图最强大的功能之一是使用hue参数显示多个变量之间的关系。这会创建分组条形,使比较更容易。
让我们使用hue参数比较两天和不同餐饮时间的小费:
# 如果尚未加载数据集,请加载小费数据集 import seaborn as sns tips = sns.load_dataset("tips") # 创建一个按天和时间分组的分组条形图 sns.barplot( data=tips, x="day", y="tip", hue="time" )
输出:
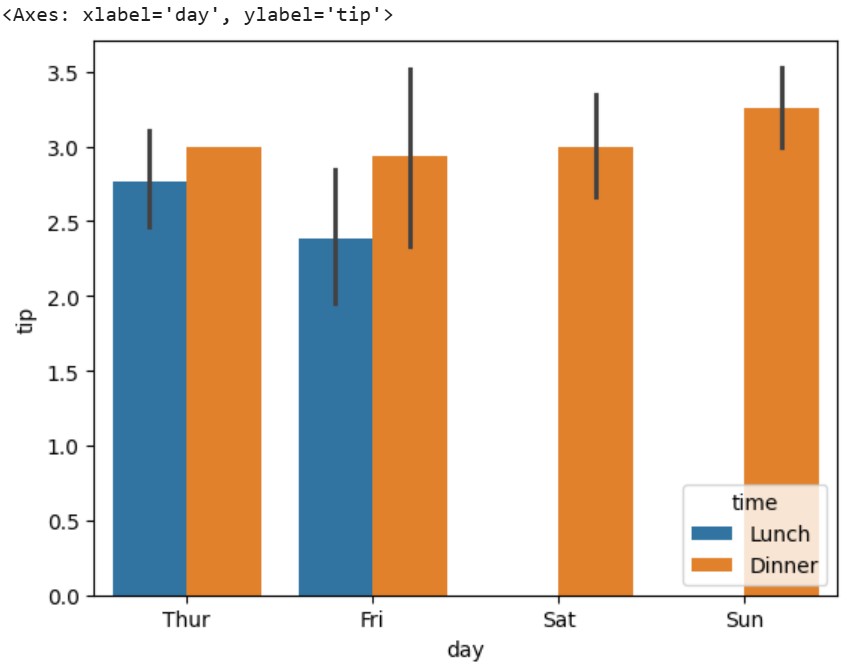
上面的图显示两根条形图 – 一个是午餐,一个是晚餐。这种分组有助于我们不仅看到小费如何随着天数变化,还可以看到它们在不同餐饮时间之间的差异。
创建堆叠的 seaborn 条形图
堆叠的条形图非常适合展示不同类别的组成部分。虽然 Seaborn 没有直接的堆叠条形图功能,但我们可以结合 matplotlib 创建有效的堆叠可视化。
这种方法利用了 Seaborn 的统计功能,同时利用了 matplotlib 的堆叠功能。例如,在小费数据集中,让我们看看小费在吸烟者和非吸烟者之间在不同天数间的分布。
让我们从导入可视化所需的库开始:
# 导入所需的库 import seaborn as sns import matplotlib.pyplot as plt import numpy as np
现在我们将加载包含餐厅小费信息的数据集:
# 加载小费数据集 tips = sns.load_dataset("tips")
我们将创建一个适合我们可视化的图形尺寸:
# 创建图形和坐标轴 plt.figure(figsize=(10, 4))
接下来,我们将计算不同日期吸烟者和非吸烟者的小费平均值:
# 计算堆叠值 # 过滤吸烟者,按天分组并获取平均小费 smoker_means = tips[tips['smoker']=='Yes'].groupby('day')['tip'].mean() # 过滤非吸烟者,按天分组并获取平均小费 non_smoker_means = tips[tips['smoker']=='No'].groupby('day')['tip'].mean()
接下来,我们将设置堆叠条形图的基本参数,如下所示:
# 使用matplotlib绘制堆叠条形图 days = smoker_means.index width = 0.8
现在,我们将为非吸烟者创建堆叠条形图的底层:
# 创建底部条形(非吸烟者) plt.bar(days, non_smoker_means, width, label='Non-smoker', color=sns.color_palette()[0])
我们将为吸烟者的小费添加顶部层:
# 创建顶部条形(吸烟者) plt.bar(days, smoker_means, width, bottom=non_smoker_means, label='Smoker', color=sns.color_palette()[1])
让我们使用seaborn样式设置一个没有网格线的干净风格:
# 添加Seaborn样式 sns.set_style("white")
最后,我们将展示完成的堆叠条形图:
# 显示图表 plt.show()
输出:
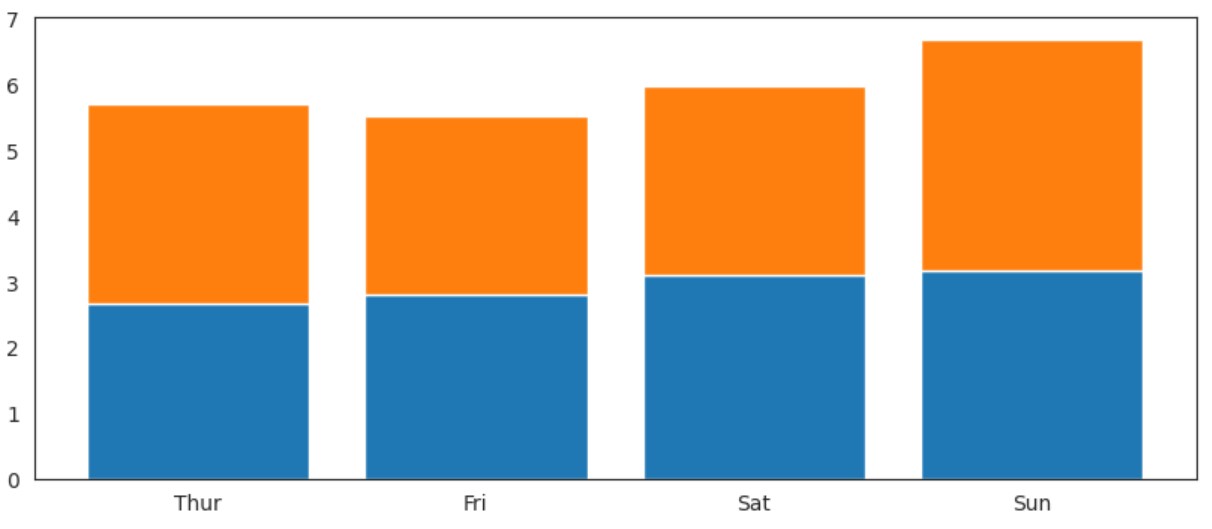
生成的图表显示了每一天吸烟者的小费堆叠在非吸烟者小费之上,方便比较两者的总小费和各组的贡献。
这个变通方法使我们能够:
- 保持Seaborn的吸引人视觉风格
- 堆叠我们的条形以显示组成
- 保持我们可视化的统计特性
- 使用Seaborn的颜色调色板以保持一致性
高级功能和技巧
现在我们已经介绍了基础知识和自定义内容,让我们看看一些高级功能,这些功能可以使我们的柱状图更具信息性和专业性。我们将继续使用“小费”数据集来演示这些高级技术。
注释柱状图
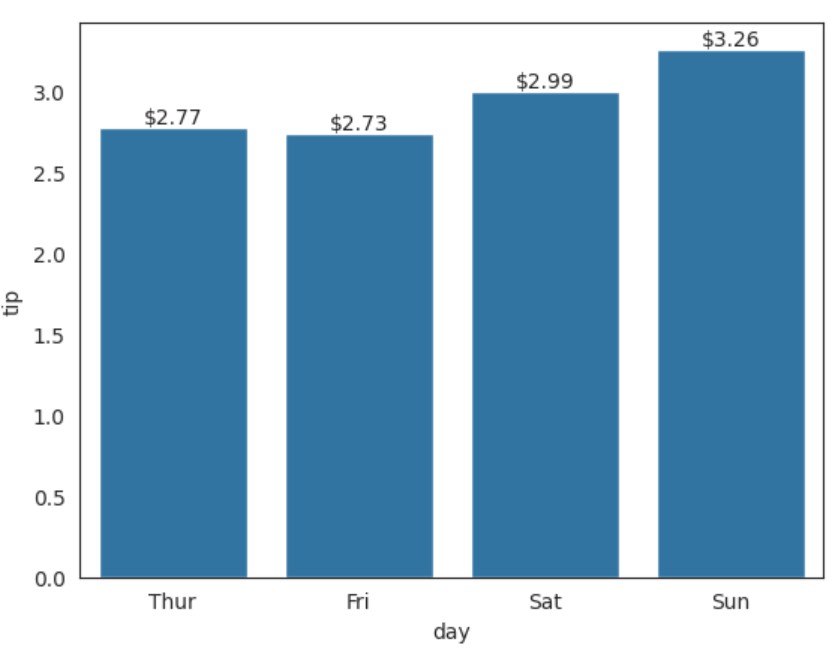
向柱状图添加数值标签可以使您的可视化更准确和更具信息性。让我们创建一个柱状图,显示每个柱子上方的确切小费数值。
首先,让我们导入所需的库并准备好我们的数据:
# 导入所需的库 import seaborn as sns import matplotlib.pyplot as plt # 加载并准备小费数据集 tips = sns.load_dataset("tips")
使用统计值创建我们的柱状图:
# 创建基本柱状图 ax = sns.barplot(data=tips, x="day", y="tip”, errorbar=None) # Create barplot and store the axes object for annotations
接下来,我们将在每个柱子顶部添加数值标签,如下所示:
# 获取每个柱子的高度 bars = ax.containers[0] # Get the bar container object heights = [bar.get_height() for bar in bars] # Extract height of each bar # 在每个柱子顶部添加文本注释 for bar, height in zip(bars, heights): # Loop through bars and heights together ax.text( bar.get_x() + bar.get_width()/2., # X position (center of bar) height, # Y position (top of bar) f'${height:.2f}', # Text (format as currency) ha='center', # Horizontal alignment va='bottom' # Vertical alignment )
输出:
管理坐标轴和刻度
在创建柱状图时,调整坐标轴可以使您的数据更易读和更具影响力。让我们看看如何使用Seaborn的函数自定义坐标轴限制、标签和刻度。
首先,我们将导入我们的库并加载我们可视化所需的数据集:
# 导入所需的库 import seaborn as sns # 加载并准备小费数据集 tips = sns.load_dataset("tips")
我们可以创建一个带有自定义标签和日期顺序的条形图。order参数允许我们精确指定希望在 x 轴上如何排列日期:
# 创建带有轴标签的条形图 ax = sns.barplot( data=tips, x="day", y="tip", order=['Thur', 'Sat', ‘Fri', 'Sun'] # Set custom order for days )
为了使我们的图表更具信息性,我们可以使用set方法为两个轴添加描述性标签:
# 设置描述性轴标签 ax.set( xlabel='Day of Week', ylabel='Average Tip ($)' )
为了微调我们的可视化,我们可以设置特定的范围和刻度。ylim参数控制 y 轴的范围,而xticks和yticks允许我们精确定义刻度线出现的位置:
# 自定义轴限制和刻度 ax.set( ylim=(0, 5), # Set y-axis range from 0 to 5 xticks=range(4), # Set x-axis tick positions yticks=[0, 1, 2, 3, 4, 5] # Set specific y-axis tick values )
要在图表中整合所有这些更改,我们需要一次性运行它们,而不是逐个运行。整个代码如下:
# 导入所需的库 import seaborn as sns # 加载并准备小费数据集 tips = sns.load_dataset("tips") # 创建带有轴标签的条形图 ax = sns.barplot( data=tips, x="day", y="tip", order=['Thur', 'Sat', 'Fri', 'Sun'] # Set custom order for days ) # 设置描述性轴标签 ax.set( xlabel='Day of Week', ylabel='Average Tip ($)' ) # 自定义轴限和刻度 ax.set( ylim=(0, 5), # Set y-axis range from 0 to 5 xticks=range(4), # Set x-axis tick positions yticks=[0, 1, 2, 3, 4, 5] # Set specific y-axis tick values )
输出:
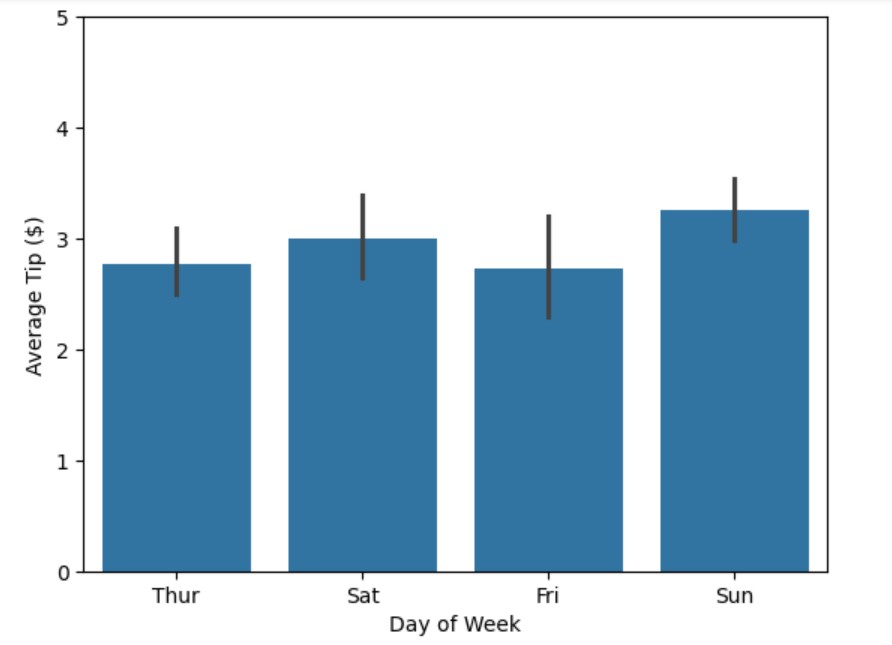
生成的图表显示了每天的小费情况,标签清晰,比例适当,刻度标记清晰,使数据易于阅读和解释。
整合误差线
误差线有助于可视化数据的不确定性或变异性。Seaborn提供了几种选项来向条形图添加误差线,包括置信区间和标准偏差。
首先,我们将导入我们的库并加载我们可视化所需的数据集:
# 导入所需的库 import seaborn as sns # 加载并准备好要使用的数据集 tips = sns.load_dataset("tips")
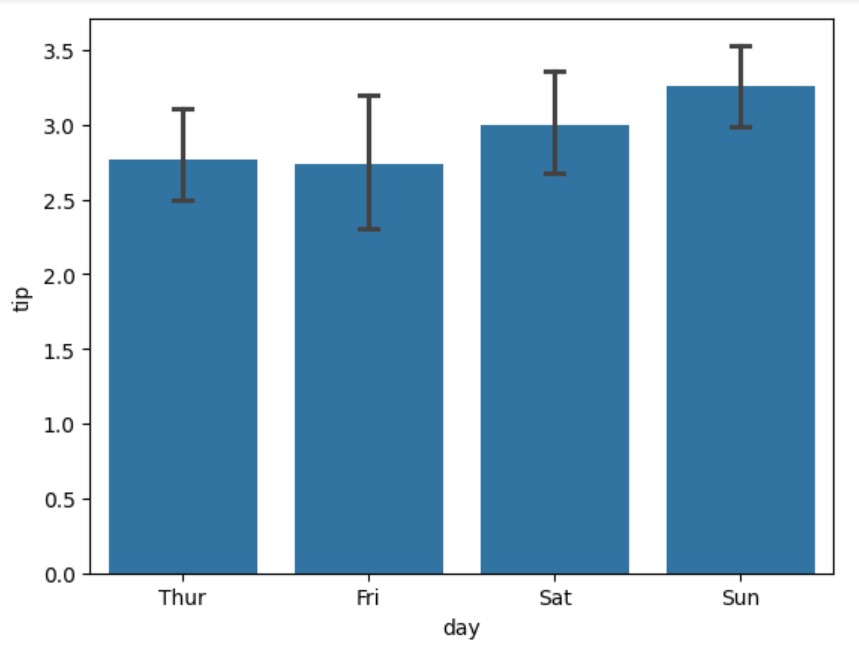
默认情况下,Seaborn 显示 95% 的置信区间。我们可以使用 ‘errorbar’ 参数来展示不同类型的统计估计:
# 创建带置信区间的条形图 ax = sns.barplot( data=tips, x="day", y="tip", errorbar="ci", # Show confidence interval capsize=0.1 # Add small caps to error bars )
输出:
我们也可以显示标准差而不是置信区间,这有助于可视化我们数据的分布情况:
# 切换为标准差 ax = sns.barplot( data=tips, x="day", y="tip", errorbar="sd", # Show standard deviation capsize=0.1 # Add small caps to error bars )
输出:
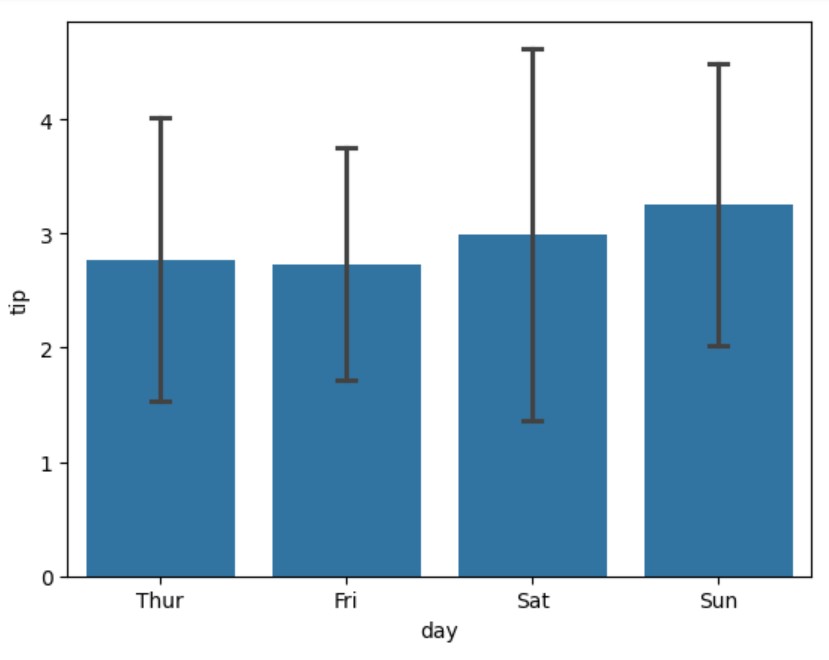
有时,我们可能希望完全去除误差条,以获得更整洁的外观:
# 创建没有误差条的条形图 ax = sns.barplot( data=tips, x="day", y="tip", errorbar=None # Remove error bars )
输出:
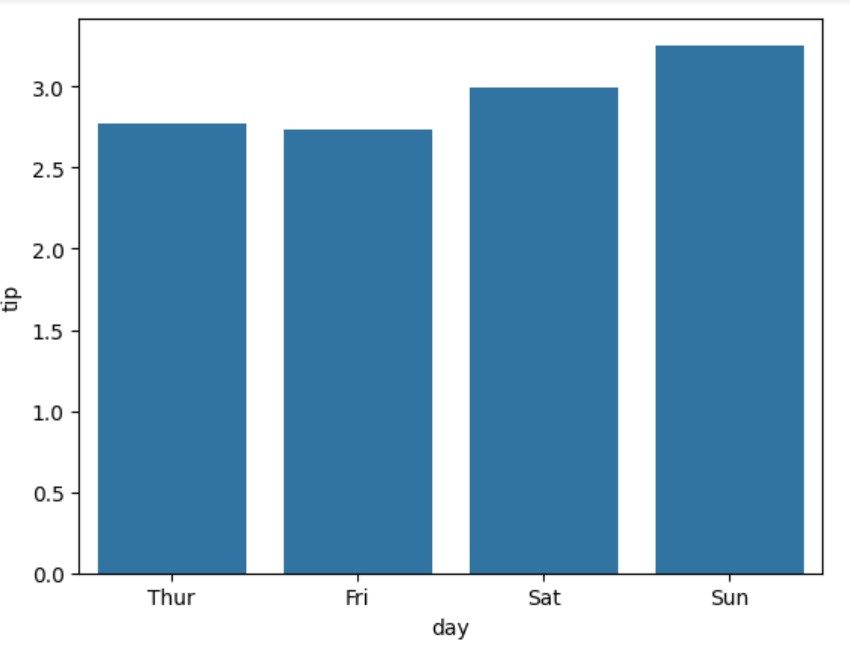
生成的图表显示了不同类型的误差条如何帮助我们理解不同星期天的提示数据的变异性。
Seaborn条形图的实际应用
条形图是数据可视化的多功能工具,特别适用于需要比较不同类别之间的值或同时分析多个变量的情况。让我们看两个Seaborn条形图表现突出的常见应用。
可视化分类数据趋势
Seaborn的条形图擅长展示分类数据中的模式,特别是在分析不同组之间的指标时。通过显示中心趋势和不确定性,条形图有助于识别不同类别之间的显著差异。
这使它们非常适合分析客户行为、产品性能或调查反馈等需要跨不同组比较数值的情况。
比较多个变量
当我们的分析涉及多个因素时,Seaborn的条形图可以突出数据中的复杂关系。使用分组(hue)或堆叠等功能有助于同时比较不同变量,更容易发现数据不同方面之间的模式和交互作用。
结论
Seaborn柱状图在简单性和统计洞察之间取得了合适的平衡。该库直观的语法结合强大的统计特性,使其成为数据可视化的必备工具。从基本类别比较到高级分组可视化,柱状图有助于有效地揭示和传达数据模式。
准备提升您的数据可视化技能了吗?以下是下一步探索的内容:
- 需要快速参考指南吗?查看我们的 Python Seaborn备忘单
- 在我们的Seaborn折线图教程中,接下来探索线图
- 学会可视化相关性,阅读 Seaborn热力图教程
- 通过我们的指南掌握主数据分布如何制作Seaborn直方图
想要提升你的Seaborn技能吗?报名参加 中级数据可视化与Seaborn课程。